- The paper demonstrates that SAE-Tuning efficiently extracts and transfers reasoning abilities by training a novel SAE on CoT-free datasets.
- The methodology integrates an SAE into a target model through a two-stage process, replicating RL-trained performance with lower computational costs.
- Empirical results confirm that the approach generalizes across datasets and models while providing transparent reasoning feature extraction for improved interpretability.
Resa: Transparent Reasoning Models via SAEs
This paper introduces Resa, a family of 1.5B reasoning models trained using a novel SAE-Tuning procedure. The core idea is to leverage SAEs to extract and instill reasoning abilities from a source model into a target model. This approach aims to address the limitations of existing methods like RL and SFT, which often operate as "black boxes" and require substantial computational resources or high-quality CoT data. The paper emphasizes the efficiency, generality, modularity, and transparency of the proposed method.
SAE-Tuning Methodology
The SAE-Tuning procedure consists of two key stages as shown in (Figure 1): SAE training (reasoning ability extraction) and SAE-guided SFT (reasoning ability elicitation). In the first stage, an SAE is trained to reconstruct the activations from a specific layer of a source model using a trigger dataset of verified CoT-free question-answer pairs. The SAE learns to capture latent features that correspond to the source model's internal reasoning processes. In the second stage, the trained SAE is integrated into a target model's architecture, and the target model is fine-tuned using an elicitation dataset (typically the same as the trigger dataset). By exposing the target model to the feature representations captured by the SAE, the SFT process is guided to develop internal pathways that elicit reasoning abilities.
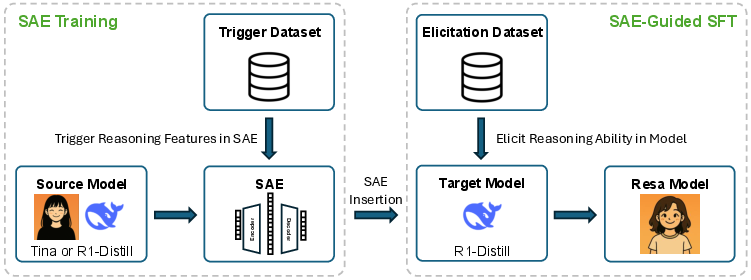
Figure 1: Two-Stage Pipeline of SAE-Tuning; The procedure begins with SAE training where an SAE is trained to capture reasoning features from a source model with a trigger dataset, then the trained SAE is frozen and inserted into a target model, and an elicitation dataset is used to guide a SFT process.
The SAE-Tuning procedure involves five key components: source model, target model, trigger dataset, elicitation dataset, and SAE training mode. The paper explores three distinct SAE training modes: pre-trained, fine-tuned, and trained-from-scratch. The paper formalizes the two stages of the SAE-Tuning procedure using equations to describe the SAE training process and the SAE-guided SFT process, including the loss function used to train the low-rank adapters. The authors provide two perspectives to build intuition for the SAE-Tuning procedure: knowledge distillation, where the SAE acts as a "knowledge bottleneck," and alternating optimization, where the SAE acts as a bridge between the two models.
Efficient Reasoning Ability Elicitation
The paper empirically validates the effectiveness of SAE-Tuning in three key aspects: reasoning ability replication, end-to-end reasoning ability elicitation, and transparency. The paper demonstrates that SAE-Tuning can successfully replicate the performance of models fully trained with RL, using the Tina models as source models. The results show that the Resa models achieve performance on par with or exceeding their Tina counterparts. An algorithm ablation demonstrates the necessity of using SAEs, as standard SFT on the same CoT-free data fails to elicit any meaningful reasoning. The paper establishes that SAE-Tuning remains effective with the base R1-Distill model as the source model, bypassing the need for expensive further RL. This simplification involves using models ranging from the base R1-Distill model to well-trained Tina checkpoints. The results demonstrate that the simplified, end-to-end SAE-Tuning procedure can replace the RL fine-tuning stage with no significant loss in reasoning performance.
Generalizable and Modular Reasoning Ability
The paper tests the hypothesis that the reasoning ability captured by SAE-Tuning is generalizable and modular. Out-of-distribution generalization is assessed by training the SAE on the STILL dataset and applying it to different elicitation datasets with varying degrees of overlap. The results show that the Resa-STILL2X models consistently achieve performance on par with models trained end-to-end via RL on the new dataset. To test whether the extracted reasoning ability can be treated as a modular "adapter," SAE-Tuning is performed on models like Qwen-Math and Qwen to produce a set of adapters. At test time, these adapters are attached to R1-Distill, and the results show that the adapter achieves competitive performance compared to models where the entire SAE-Tuning process was performed directly on R1-Distill.
The paper introduces a novel prompt-only reasoning feature extraction method to identify and quantify "reasoning features" and test if their distribution predicts the final performance of a Resa model. The method involves passing the standard DeepSeek-R1 system prompt containing > and </think> tokens through a model equipped with trained SAEs inserted after each layer. Reasoning features are defined as those SAE features that are exclusively and simultaneously activated at the <think> and tokens and not by other parts of the prompt. The layer-wise count of these reasoning features exhibits a tri-modal distribution. A large-scale study is conducted to create different Resa-STILL models, each generated by applying SAE-Tuning to a different layer of Tina-STILL. The results confirm that the choice of SAE hookpoint is critical, and a 3-GMM is fitted to both the a priori reasoning feature counts and the final reasoning scores to reveal a structural alignment between the two distributions.
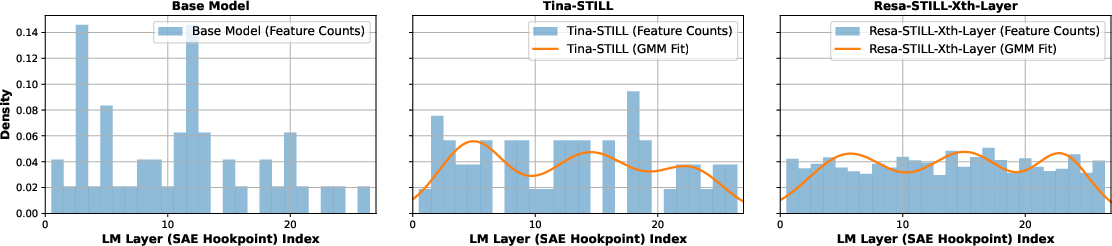
Figure 2: Reasoning Feature Extraction; This shows the layer-wise feature counts of the base R1-Distill model, the layer-wise feature counts of the Tina-STILL model, and the reasoning performance of the trained Resa models with different layer-wise SAEs when Tina-STILL is the source model.
The paper discusses related work in three main areas: RL for reasoning ability elicitation, SAEs, and model steering. The authors note that recent work suggests that RL primarily elicits and amplifies reasoning capabilities already embedded within pretrained models. Recent advances in SAEs have enabled new approaches for analyzing and steering neural network computations. The use of SAEs for model steering builds on earlier work in activation editing, and the paper's proposed procedure, SAE-Tuning, fully leverages sparse autoencoders to identify, extract, and elicit latent reasoning abilities.
Conclusion
The paper concludes by highlighting the contributions of the work in addressing the challenge of eliciting reasoning abilities from LLMs in an effective, efficient, and transparent manner. The authors introduce SAE-Tuning, a novel procedure that leverages SAEs to identify, extract, and elicit latent reasoning abilities using only CoT-free data. The experiments validate the approach on three key fronts: performance and practicality, generality and modularity, and transparency.

