Back to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning
Abstract: A recurring challenge in preference fine-tuning (PFT) is handling $\textit{intransitive}$ (i.e., cyclic) preferences. Intransitive preferences often stem from either $\textit{(i)}$ inconsistent rankings along a single objective or $\textit{(ii)}$ scalarizing multiple objectives into a single metric. Regardless of their source, the downstream implication of intransitive preferences is the same: there is no well-defined optimal policy, breaking a core assumption of the standard PFT pipeline. In response, we propose a novel, game-theoretic solution concept -- the $\textit{Maximum Entropy Blackwell Winner}$ ($\textit{MaxEntBW}$) -- that is well-defined under multi-objective intransitive preferences. To enable computing MaxEntBWs at scale, we derive $\texttt{PROSPER}$: a provably efficient PFT algorithm. Unlike prior self-play techniques, $\texttt{PROSPER}$ directly handles multiple objectives without requiring scalarization. We then apply $\texttt{PROSPER}$ to the problem of fine-tuning LLMs from multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges), a setting where both sources of intransitivity arise. We find that $\texttt{PROSPER}$ outperforms all baselines considered across both instruction following and general chat benchmarks, releasing trained model checkpoints at the 7B and 3B parameter scales.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Back to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning”
1) What is this paper about?
This paper is about teaching LLMs to give better answers when “judges” (often another LLM) compare two responses and say which one is better. The tricky part is that judges can be inconsistent, especially when they are asked to consider many goals at once (like helpfulness, accuracy, safety, tone). The authors propose a new way to handle these inconsistencies and improve training. They introduce a new idea called the Maximum Entropy Blackwell Winner (MaxEntBW) and a practical training method called PROSPER to fine-tune LLMs using multi-goal (multi-objective) feedback.
2) What questions are they trying to answer?
The paper focuses on three main goals:
- How can we train an LLM when the judge’s preferences are sometimes inconsistent or “cyclic” (like rock-paper-scissors, where no single choice is best against all others)?
- Can we define a fair and sensible target for “doing well” when the model is judged on many goals at once?
- Can we turn that target into a simple, scalable training algorithm that works on modern LLMs and actually improves real-world performance?
3) How did they approach the problem?
The authors use ideas from game theory (the math of decision-making and competition) and simplify them so training stays practical at LLM scale.
Key ideas explained in everyday language:
- Intransitive preferences: Sometimes the judge prefers Answer A over B, B over C, but then C over A. That’s a cycle (like rock-paper-scissors). In such cases, there’s no single “best” answer in a simple ranking.
- Multiple goals: Judges often score answers on several checklist items (for example, correctness, clarity, safety). Squashing these into one number (“scalarization”) can create weird or unfair results.
- MaxEntBW (Maximum Entropy Blackwell Winner): Think of this as finding a policy (an LLM’s way of answering) that performs well across all goals, especially against nearby competitors, even when preferences are messy. “Maximum entropy” keeps the opponent from being overly extreme—it gently penalizes them for straying too far from a reasonable “reference” policy.
- PROSPER (PReference-based Optimization with a Single Player over Entire Rubrics): This is the training algorithm. Instead of playing a full-blown adversarial game between two models (which is expensive and unstable), PROSPER cleverly: 1) Finds the “weakest” checklist item for each prompt (the goal where the model is most vulnerable). 2) Builds a soft, local competitor that stays close to a chosen reference model (so training doesn’t go off the rails). 3) Updates the model using a simple regression step (think: finding the best-fit adjustment), which is cheaper and more stable than adversarial training.
In short: PROSPER turns a complicated multi-goal, possibly inconsistent judging process into a single, efficient “learn from the toughest goal” update that the model can handle at scale.
4) What did they find, and why does it matter?
Main findings:
- Inconsistency is real: Even when you split a rubric into separate checklist items, judges still show intransitive preferences sometimes. Splitting helps, but it doesn’t fix the problem completely.
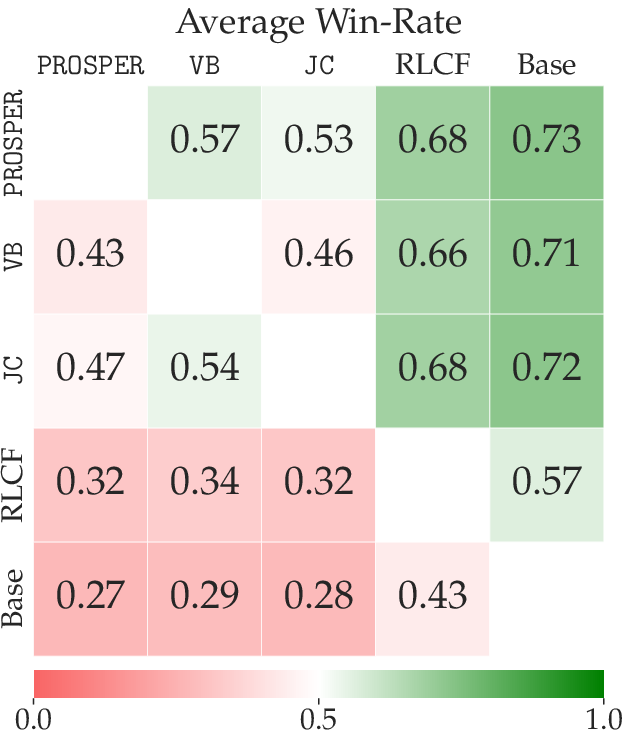
- PROSPER beats baselines: The authors fine-tuned open models (Qwen2.5-3B and Qwen2.5-7B) with PROSPER and compared them to a strong existing method (RLCF: RL from Checklist Feedback) and two simplified versions of their own method. PROSPER consistently won more head-to-head comparisons judged by an LLM and scored higher on key benchmarks:
- General chat (Arena-Hard): PROSPER improved win rates over the base and RLCF models.
- Instruction following (AlpacaEval 2.0): PROSPER achieved higher scores than baselines.
- No major trade-offs: PROSPER did not significantly hurt performance on unrelated tasks like multiple-choice knowledge tests (MMLU, ARC), common sense (HellaSwag), or truthfulness (TruthfulQA). That’s a good sign the training is robust, not overly specialized.
- Practical impact: They released trained checkpoints at 3B and 7B scale, showing this method works at sizes people actually use.
Why it matters:
- It provides a way to train LLMs using real-world, multi-goal judge feedback, even when that feedback is messy.
- It avoids collapsing all goals into one number, which can hide useful details and create unintended behaviors.
- It’s efficient and scalable because it reduces a complex game to a single-player update using regression, rather than running costly adversarial training loops.
5) What are the implications?
- Better multi-goal training: As we ask AI to meet many goals at once (be helpful, accurate, safe, and respectful), we need training methods that respect all goals without forcing them into a single score. PROSPER is designed for that.
- More robust to judge noise: Judges (including LLM judges) aren’t perfect. PROSPER’s approach handles inconsistency by focusing training where the model is weakest and keeping opponents near a sensible reference.
- Practical and open: The released models show this isn’t just theory—it works in practice. This could help developers build more reliable chatbots and assistants that balance multiple expectations.
- Caution and future work: The quality of results still depends on the judge and rubric. If the judge is biased or the rubric is poorly designed, you can train to the wrong target. Future work might focus on making judges more reliable and rubrics more comprehensive, while keeping training robust.
Overall takeaway: The paper gives a principled, scalable way to fine-tune LLMs from multi-objective, sometimes inconsistent preferences. By introducing the MaxEntBW concept and the PROSPER algorithm, the authors show how to turn messy real-world judging into stable, effective learning—improving instruction following and chat quality without sacrificing broader abilities.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several concrete gaps and open questions that future work could address:
- Formal properties of MaxEntBW: prove existence and uniqueness; characterize when MaxEntBW coincides with Blackwell Winners or von Neumann Winners; analyze limiting behavior as β→0 (strong adversary) and β→∞ (fixed comparator).
- Sensitivity to KL regularization strength (β): provide principled tuning guidelines, schedules, or meta-learning strategies; quantify how β trades off adversary strength, stability, and empirical performance.
- Dependence on the reference policy (πref): analyze how the concentrability coefficient C{πref→π*} affects the bound and performance; study strategies to choose, mix, or update π_ref to improve coverage; design exploration mechanisms that reduce C{π_ref→π*}.
- Sample complexity and variance: derive bounds for estimating Zk, k*(x), and gradients with finite M (e.g., M=2 used); quantify estimator bias/variance and how M impacts convergence and performance; develop adaptive sampling to control variance.
- Robustness of worst-case objective selection: evaluate the stability of selecting k*(x) via argmin under noisy judge scores; compare soft-min or entropy-regularized mixtures over objectives to hard min; analyze trade-offs between worst-case and average-case performance across objectives.
- Generalization beyond in-distribution regression: characterize ε in Assumption 1 empirically and theoretically; analyze out-of-distribution behavior and error propagation when training or deployment distributions shift.
- Computational complexity and efficiency: report end-to-end training costs (judge calls, compute, wall-clock) and scaling behavior; compare to DPO/RLHF baselines in cost-per-improvement; provide complexity analysis per iteration.
- Failure mode analysis: investigate cases where PROSPER underperforms (e.g., length-controlled AlpacaEval close second); diagnose length bias, objective weighting effects, or judge idiosyncrasies; propose corrective mechanisms.
- Baseline breadth: compare against additional multi-objective methods (e.g., multi-objective DPO, distributional reward modeling, constrained RL, adapted min-max approaches) to strengthen empirical claims.
- Cross-judge and cross-rubric robustness: assess overfitting to the training judge (Qwen3-14B) by evaluating with diverse judges (GPT-4/5, Claude, Llama) and human raters; test transfer across rubric generators and checklist styles.
- Judge calibration: validate the mapping from 5-point Likert scores to [0,1] probabilities; apply calibration techniques (e.g., isotonic, Platt scaling) and measure impact on the exponential weighting and gradient estimates.
- Safety and alignment metrics: include toxicity, jailbreak susceptibility, hallucination, and helpful-harmless trade-offs to verify multi-objective robustness does not hide safety regressions.
- Rubric quality and bias: quantify noise, coverage, and bias in LLM-generated checklists; compare to expert-designed rubrics; study how rubric granularity and item selection affect intransitivity and training outcomes.
- Per-objective performance tracking: report improvements and regressions per checklist item to reveal trade-offs introduced by worst-case weighting; ensure non-dominated improvements across objectives.
- Sensitivity to number and heterogeneity of objectives (m(x)): analyze how increasing objectives and varying per-prompt criteria affect stability of k*(x), convergence, and performance; identify practical limits.
- Extension to multi-turn dialogues: adapt MaxEntBW and PROSPER to sequential settings with context-dependent objectives; evaluate on multi-turn conversation datasets.
- Conditions for vertex solutions in w(x): formally prove when the min over w lies at simplex vertices; identify cases where mixed w(x) is optimal and the impact on algorithm design.
- Alternative adversary regularizations: compare KL to other f-divergences or entropy schedules; analyze theoretical guarantees and empirical stability differences.
- Adaptive β and w(x): learn β and/or objective mixtures dynamically (e.g., via meta-gradients or Bayesian treatments); provide stability and performance guarantees.
- Hybrid human+AI feedback: design aggregation schemes for combining human and LLM judges under multi-objective intransitivity; evaluate whether MaxEntBW remains robust with mixed feedback sources.
- Exploration to improve πref coverage: propose curricula or mixtures of reference policies to reduce C{π_ref→π*}; empirically measure how improved coverage tightens bounds and boosts performance.
- Heuristic data filtering impacts: quantify bias introduced by selecting pairs with largest gradient gaps; compare to uncertainty-aware sampling or importance weighting; provide theoretical justification or ablations.
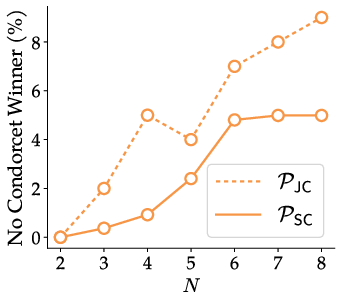
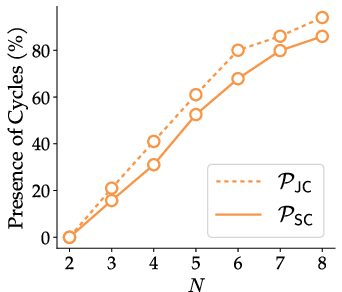
- Behavior under severe intransitivity: characterize regimes (e.g., high cycle prevalence, no Condorcet winners) where MaxEntBW offers clear advantages; develop diagnostic metrics for such regimes.
- Applicability beyond LLMs: demonstrate PROSPER in other multi-objective, intransitive domains (robotics, recommender systems, game playing) to validate generality.
- Reproducibility details: report training-time, judge-query budget, and hyperparameter sensitivity to enable fair comparison and adoption; include seed variance analyses.
- Approachability connections: formalize links to Blackwell approachability (e.g., target sets, order-of-play effects); clarify theoretical implications of breaking minimax while retaining concavity.
- Stability across seeds and initializations: quantify variance in learned policies; study methods (e.g., ensembling, regularization) to reduce instability without sacrificing robustness.
Practical Applications
Overview
This paper introduces a new solution concept—Maximum Entropy Blackwell Winner (MaxEntBW)—and a scalable algorithm—PROSPER—for preference fine-tuning (PFT) of LLMs when preferences are multi-objective and intransitive (i.e., cyclic). The core innovations are:
- Handling multiple objectives without scalarization.
- Avoiding adversarial two-player training via KL-regularized local competitor modeling.
- Reducing policy optimization to a single-player regression-based mirror descent.
- Demonstrating improved performance on instruction-following and general chat benchmarks with released 3B/7B checkpoints.
Below are practical applications of these findings, grouped by deployment timeframe. Each item notes sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
The following applications are deployable now, using PROSPER and the released checkpoints or by adapting the provided training pipeline.
- Robust rubric-based LLM post-training for product teams
- Sectors: software, consumer AI, enterprise AI
- What: Replace scalarized RLHF/RLCF with PROSPER to fine-tune assistants on multi-objective rubrics (e.g., correctness, tone, safety, adherence-to-instructions), improving instruction following and conversational quality while mitigating judge inconsistency.
- Tools/Workflows:
- Rubric-to-judge pipeline (prompt templates, per-item pairwise scoring).
- PROSPER trainer (gradient regression via REBEL-style updates; worst-case objective selection per prompt).
- Win-rate matrix dashboard for model comparisons.
- Assumptions/Dependencies: Reliable LLM-as-a-judge capable of per-criterion evaluation; high-quality rubrics; sufficient compute; coverage between reference and target policy (concentrability); careful β (KL regularization strength) selection.
- Enterprise compliance and policy-constrained assistants
- Sectors: finance, healthcare (non-diagnostic), legal, public sector
- What: Fine-tune assistants to satisfy checklists of compliance criteria (disclosures, privacy, non-solicitation, tone, jurisdictional constraints) without collapsing into a single score, ensuring local robustness to intransitive criteria.
- Tools/Workflows:
- Compliance checklist authoring studio (domain experts encode policies as rubric items).
- PROSPER-based post-training pipeline with multi-objective judges.
- Local robustness evaluation via MaxEntBW-style worst-case objective assessment.
- Assumptions/Dependencies: Human oversight; domain-specific validation; strong judge models; guardrails for high-stakes use; legal review.
- Safer constitutional AI with per-criterion dynamic emphasis
- Sectors: AI safety, platform moderation
- What: Use PROSPER to dynamically target where the model is weakest across safety-related rubric items (e.g., harmfulness, misinformation, privacy) and avoid aggregate scalarization that induces cycles or blind spots.
- Tools/Workflows:
- Multi-criteria safety judge orchestration.
- Gradient-gap filtering (train on pairs with largest judge confidence gaps).
- Worst-case objective selection per prompt (min over objectives).
- Assumptions/Dependencies: High-quality safety rubrics and judge prompts; monitoring for false positives/negatives; periodic adversarial testing.
- Education: Multi-objective tutoring assistants
- Sectors: education, edtech
- What: Fine-tune tutors on rubrics spanning correctness, scaffolding, engagement, inclusiveness, and reading level, preserving nuanced trade-offs instead of collapsing to a single “quality” score.
- Tools/Workflows:
- Curriculum-aligned rubric design (per-topic objectives).
- PROSPER training cycles with per-item judge feedback (Likert → [0,1] normalization).
- Benchmark monitoring (e.g., IFEval) to avoid regression in reasoning skills.
- Assumptions/Dependencies: Age-appropriate safety checks; instructor oversight; judge agreement with instructional standards.
- Software engineering assistants with multi-criterion code quality
- Sectors: software
- What: Fine-tune code assistants on rubrics for correctness, security, performance, style, documentation; handle conflicting preferences (e.g., performance vs readability).
- Tools/Workflows:
- Pairwise code judge with per-criterion outputs.
- PROSPER training on repo/task-specific datasets.
- Win-rate matrices across internal baselines for deployment gating.
- Assumptions/Dependencies: Reliable code judges (possibly ensemble with static analysis); domain-specific rubrics; test suite validation.
- Open-source model deployment and benchmarking
- Sectors: research, startups, builders
- What: Use the released Qwen2.5-3B/7B PROSPER checkpoints directly as improved instruction-following/chat baselines and integrate the training pipeline to adapt to your domain rubrics.
- Tools/Workflows:
- Hugging Face integration for inference and fine-tuning.
- PROSPER recipes for multi-objective judge collection and training.
- Assumptions/Dependencies: Domain transfer may require re-tuning; judge availability; compute resources.
- Evaluation modernization: Intransitivity-aware assessment
- Sectors: academia, industry evaluation teams
- What: Adopt multi-objective evaluation protocols (joint vs single-check) and report Condorcet/no-winner rates and cycles, reflecting realistic judge inconsistency.
- Tools/Workflows:
- Intransitivity analyzer (computes cycle frequency and Condorcet absence per dataset).
- Report per-objective win-rates and minima (worst-case objective).
- Assumptions/Dependencies: Access to judge models; diverse prompt sets; robust statistic tracking.
Long-Term Applications
The following applications require further research, scaling, or development to become reliable and widely adopted.
- Multi-objective RL for embodied agents and robotics
- Sectors: robotics, autonomous systems
- What: Extend MaxEntBW and PROSPER-style training to multi-objective RL with non-text action spaces (safety, efficiency, comfort, task success), confronting intransitive preferences from human feedback and environment-induced conflicts.
- Tools/Workflows:
- Preference collection interfaces for physical tasks (pairwise demos; multi-criterion ratings).
- Entropy-regularized competitor modeling in continuous action spaces.
- Regression-based mirror descent adapted to trajectory policies.
- Assumptions/Dependencies: Sample efficiency; safe exploration; judge fidelity in physical domains; theoretical guarantees under dynamics.
- Multi-judge orchestration and fairness-aware training
- Sectors: AI safety, policy, platform governance
- What: Combine multiple judges (LLMs, human panels, specialized auditors) and incorporate fairness constraints (e.g., demographic parity across objectives) while handling inter-judge inconsistency and intransitivity.
- Tools/Workflows:
- Judge ensemble management (weighting/consistency checks).
- Constraint-aware MaxEntBW variants (fairness regularizers).
- Auditing dashboards for objective-level disparities.
- Assumptions/Dependencies: Access to diverse judges; fairness metrics; policy/legal standards; careful calibration to avoid overfitting to auditors.
- Standards and certification for multi-objective AI evaluation
- Sectors: policy, regulation, industry consortia
- What: Develop audit frameworks that recognize intransitivity, require multi-objective reporting, and accept MaxEntBW-like local robustness guarantees over scalarized scores in AI procurement and certification.
- Tools/Workflows:
- Standardized rubric templates per domain (health, finance, education).
- Benchmarks with cycle prevalence reporting.
- Certification criteria emphasizing worst-case objective performance.
- Assumptions/Dependencies: Regulator buy-in; consensus on rubrics/objectives; clarity on acceptable risk thresholds.
- Personalized assistants with live objective reweighting
- Sectors: consumer AI, accessibility
- What: Real-time adaptation of assistant behavior to user-specific objectives (privacy, tone, formality, brevity, citations) while guarding against cycles and instability using MaxEntBW-style local optimality.
- Tools/Workflows:
- User-facing “objective controls” UI linked to per-criterion judges.
- Streaming PROSPER updates or fast re-ranking strategies.
- Stability monitors to prevent overreacting to transient preferences.
- Assumptions/Dependencies: On-device or low-latency judge inference; personalization safety; robust UX for multi-objective control.
- Decision-support systems under conflicting policies and regulations
- Sectors: healthcare (clinical decision support), finance (advice), public sector (procurement)
- What: Assist professionals where policies/regulations conflict, providing locally robust recommendations that transparently balance objectives and highlight trade-offs.
- Tools/Workflows:
- Multi-criteria decision explanation modules (objective-level rationales).
- Scenario testing with intransitivity detection and mitigation.
- Simulation of policy changes and their impact on recommendations.
- Assumptions/Dependencies: Human-in-the-loop oversight; traceability; secure data; strong domain judges; formal risk management.
- Content ranking, moderation, and recommender systems with robust multi-objective optimization
- Sectors: social platforms, media
- What: Apply MaxEntBW-like concepts to ranking/recommendation where objectives conflict (engagement, quality, safety, diversity), reducing brittleness when preferences are cyclic or noisy.
- Tools/Workflows:
- Multi-objective pairwise ranking engines with entropy-regularized competitor modeling.
- Objective-wise caps/constraints and worst-case performance tracking.
- Assumptions/Dependencies: Adaptation from policy optimization to ranking objectives; scalable judge feedback; guardrails for manipulation and polarization.
- Provenance-aware judge training and continual improvement loops
- Sectors: AI research, platform governance
- What: Co-evolve judges and policies: improve judge consistency by training on intransitivity cases, while maintaining MaxEntBW-style robustness in the policy.
- Tools/Workflows:
- Intransitivity case mining and judge fine-tuning datasets.
- Continuous evaluation harnesses that track cycles and Condorcet absence over time.
- Assumptions/Dependencies: Avoid judge-model collapse; prevent feedback loops; careful separation between target and judge models.
- Cross-modal multi-objective learning (text + speech + vision)
- Sectors: multimodal AI, accessibility, media
- What: Extend PROSPER to multimodal assistants that must balance objectives across modalities (clarity, accuracy, timing, visual safety), with intransitive trade-offs (e.g., brevity vs completeness).
- Tools/Workflows:
- Multimodal pairwise judges with per-modality criteria.
- Regression-based mirror descent for multimodal policies.
- Assumptions/Dependencies: Reliable multimodal judges; dataset availability; efficient multimodal gradient estimation.
Notes on Key Assumptions and Dependencies
- Quality and reliability of LLM-as-a-judge: The method presumes access to judges that can provide per-criterion pairwise evaluations (e.g., Qwen3-14B), mitigated for positional bias and variance via prompt design and repeated queries.
- Rubric design: The expressiveness and correctness of per-item rubrics are critical; splitting checklists into single-item evaluations reduces (but doesn’t eliminate) intransitivity.
- Reference policy coverage: Performance guarantees depend on the concentrability coefficient; the reference policy must adequately cover the target’s support.
- Hyperparameter choice and compute: β (KL regularization), step sizes, and sample sizes (e.g., M=2 for gradient estimation) affect stability and convergence; sufficient compute is necessary.
- Domain shift and safety: While the paper observes minimal regression on QA/reasoning benchmarks, high-stakes domains (healthcare/finance) require additional validation, human oversight, and compliance checks.
- Data governance: Judge prompts and rubrics must align with legal, ethical, and organizational standards; multi-judge orchestration and fairness constraints may be needed in regulated settings.
Glossary
- Adversarial training: A training setup where a learner and an adversary optimize against each other in a game-like interaction. "Observe that this optimization problem does not require adversarial training between a pair of policies to solve."
- Blackwell Winner: A multi-objective extension of the von Neumann winner that uses Blackwell’s approachability to define robustness across objectives. "A Blackwell Winner~\cite{bhatia2020preference} is the natural extension of the von Neumann Winner to the multi-objective setting, drawing on Blackwell's notion of a target set \citep{Blackwell1956Approachability}."
- Bregman Divergence: A generalized divergence used in mirror-descent-style optimization; KL divergence is a common instance. "and use Online Mirror Descent (in particular, with KL as the Bregman Divergence) for policy optimization."
- Condorcet Winner: An option that beats every other option in pairwise comparisons; it may not exist under intransitive preferences. "there is often no well-defined optimal policy (more formally, no Condorcet Winner, \citet{brandt2016handbook}), as every response loses to some other response ."
- Concentrability coefficient: A coverage measure quantifying how well a reference policy covers a target policy via a worst-case density ratio. "we denote the concentrability coefficient as \citep{kakade2002approximately}, which quantifies how well the reference policy covers ."
- Constitutional AI: An alignment paradigm that uses a written set of principles (a “constitution”) to guide AI feedback and training. "similar to the ``constitutional AI'' paradigm used by frontier labs \citep{bai2022constitutional}."
- Direct Preference Optimization (DPO): A direct loss for optimizing policies from pairwise preference data without training a separate reward model. "the use of DPO \citep{rafailov2024directpreferenceoptimizationlanguage} on the highest and lowest scoring responses for a prompt rather than gap size-sensitive REBEL \citep{gao2024rebel} for policy optimization"
- Entropy regularization: Adding an entropy-based term (often via KL) to stabilize or localize the optimization against an adversary. "Key Step #1: Entropy Regularization Ensures a Closed-Solution for ."
- Kullback–Leibler (KL) divergence: A measure of discrepancy between probability distributions, widely used in regularization and mirror descent. "and use Online Mirror Descent (in particular, with KL as the Bregman Divergence) for policy optimization."
- KL regularization: Penalizing deviation (via KL divergence) from a reference distribution to control adversarial strength or stabilize learning. "Beyond being perhaps the natural choice, the use of KL regularization on the adversary will allow us to elide adversarial training, as we discuss in greater detail below."
- L-infinity (ℓ∞) distance: A max-norm distance used for worst-case (coordinate-wise) guarantees in vector-valued settings. "For vector and set , define the distance function as"
- LLM-as-a-Judge: Using a LLM to score or rank responses, often along multiple rubric items. "multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges)"
- Maximum Entropy Blackwell Winner (MaxEntBW): The paper’s solution concept: a policy robust to local comparisons across multiple objectives with an entropy-regularized adversary. "the Maximum Entropy Blackwell Winner (MaxEntBW) -- that is well-defined under multi-objective intransitive preferences."
- Maximal Lottery: A randomized choice rule (lottery) that maximizes worst-case pairwise preference in single-objective settings. "a popular choice is the Maximal Lottery \citep{kreweras1965aggregation, fishburn1984probabilistic} or von Neumann Winner \citep{dudik2015contextual}"
- Minimax Theorem: A foundational result equating max–min and min–max in zero-sum games; it can fail in multi-objective settings considered here. "the Minimax Theorem \citep{vonneumann1928} no longer holds, as famously observed by \citet{Blackwell1956Approachability}."
- Minimax Winner: A single-objective solution concept optimizing against the worst-case comparator. "In contrast to classical solution concepts like the Minimax Winner that are only catered to single objectives \citep{kreweras1965aggregation, fishburn1984probabilistic, dudik2015contextual}, MaxEntBWs are well-defined under multiple objectives."
- Nash Equilibrium: A strategy profile where no player can improve unilaterally; used here to define the von Neumann winner. "a von Neumann Winner is a Nash Equilibrium of the zero-sum game with as the payoff matrix."
- Online convex optimization: An online learning framework for sequentially minimizing convex losses with theoretical guarantees. "We can therefore reduce this problem to online convex optimization \citep{hazan2023introductiononlineconvexoptimization} and use Online Mirror Descent (in particular, with KL as the Bregman Divergence) for policy optimization."
- Online Mirror Descent: An iterative optimization method using Bregman divergences to perform updates in dual geometry. "and use Online Mirror Descent (in particular, with KL as the Bregman Divergence) for policy optimization."
- Partition function: The normalizing constant of an exponentiated-weight distribution ensuring probabilities sum to one. "is the partition function that ensures the above sums to 1 across ."
- Preference fine-tuning (PFT): Post-training models using preference data (e.g., pairwise comparisons) instead of explicit rewards. "A recurring challenge in preference fine-tuning (PFT) is handling intransitive (i.e., cyclic) preferences."
- REBEL: A regression-based method for preference optimization that approximates mirror descent with supervised learning. "gap size-sensitive REBEL \citep{gao2024rebel} for policy optimization"
- Scalarization: Converting multiple objectives into a single scalar score, which can induce intransitivity or distort trade-offs. "scalarizing multiple objectives into a single metric."
- Self-play: Training by playing against one’s own (possibly evolving) policy to find equilibria in games. "Due to the symmetry of the payoff matrix, simple self-play is provably efficient for computing such equilibria \citep{swamy2024minimaximalist}."
- Social choice theory: The study of aggregating individual preferences; provides tools to handle intransitive collective judgments. "Drawing on ideas from social choice theory, several authors have pointed out that care is required when learning from intransitive, aggregate preferences"
- Target set (Blackwell): A set of desired vector outcomes that an agent seeks to approach in the sense of Blackwell’s approachability. "drawing on Blackwell's notion of a target set \citep{Blackwell1956Approachability}."
- Variational bound: A relaxation technique that replaces a hard objective with a tractable upper/lower bound for optimization. "This corresponds to taking or a variational bound on our full objective \citep{gupta2025mitigating}."
- Variational relaxation: Using variational bounds to derive scalable approximations for otherwise intractable objectives. "deriving a scalable algorithm via the use of a variational relaxation."
- von Neumann Winner: A single-objective equilibrium policy (maximal lottery) that optimizes worst-case pairwise preferences. "a popular choice is the Maximal Lottery \citep{kreweras1965aggregation, fishburn1984probabilistic} or von Neumann Winner \citep{dudik2015contextual}"
- Zero-sum game: A game where one player’s gain equals the other’s loss; equilibria correspond to robust policies under adversarial evaluation. "a von Neumann Winner is a Nash Equilibrium of the zero-sum game with as the payoff matrix."
Collections
Sign up for free to add this paper to one or more collections.