- The paper introduces WarpRec, a unified framework that integrates academic rigor with industrial-scale deployment for recommender systems.
- It employs modular pipelines, backend-agnostic design, automated hyperparameter optimization, and a comprehensive evaluation suite featuring 40 metrics.
- Empirical results demonstrate WarpRec's scalability, efficient energy consumption, and agentic interoperability, supporting both research and production needs.
WarpRec: A Unified Architecture for Responsible, Scalable, and Rigorous Recommender System Research
Motivation and Problem Statement
Recommender system (RS) development remains divided along the lines of academic investigation and industrial-scale deployment. Academic pipelines, typically single-node and in-memory, offer flexibility and fast prototyping but falter in scaling to production workloads. Conversely, industrial frameworks optimize for parallelism, resource utilization, and operational throughput but lack the rigor, customizability, and transparent evaluation protocols required for scientific progress.
The paper "WarpRec: Unifying Academic Rigor and Industrial Scale for Responsible, Reproducible, and Efficient Recommendation" (2602.17442) introduces WarpRec, a comprehensive framework specifically designed to unify these divergent requirements. WarpRec is positioned as a backend-agnostic, high-throughput, and scientifically rigorous infrastructure for recommender research and industrial adoption, emphasizing reproducibility, agentic interoperability, and ecological accountability.
Architectural Design Principles
WarpRec is architected for strict modularity, separating concerns across all key phases of the RS pipeline: data ingestion, processing, model training, evaluation, and serving. The modularization allows WarpRec to support both flexible academic workflows and robust industrial deployments, ensuring code reusability across research, prototyping, and production.
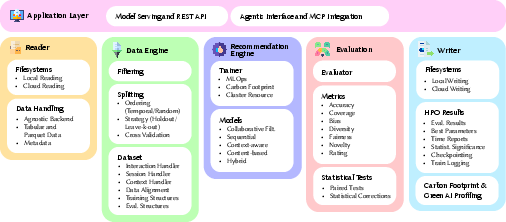
Figure 1: The modular architecture of WarpRec, illustrating decoupled modules for data management, training, evaluation, and agent-serving abstraction.
Central to the architecture is deep backend-agnosticism, inherited from the Narwhals compatibility layer, supporting eager and distributed execution backends (e.g., Pandas, Spark, Polars). Models and pipelines, once specified, can be seamlessly executed locally or distributed on cluster resources (e.g., multi-node Ray orchestration), enforcing the "write-once, run-anywhere" paradigm.
Pipelines, Extensibility, and Customization
WarpRec exposes three standardized pipelines: training (with automated HPO), design (rapid prototyping), and evaluation (post-hoc analysis), each controlled via declarative configuration. Modular pipelines and an event-driven callback interface enable arbitrary composition and the injection of custom hooks, empowering advanced experimentation and industrial integration without modifying core logic.
The Reader module abstracts ingestion, supporting both local and cloud storage, facilitating data management in both research and production environments. The Data Engine provides fine-grained filtering (13 strategies, including k-core and cold-start heuristics), advanced splitting (random, temporal, k-fold CV), and metadata alignment, all secured by deterministic protocols for reproducibility.
Model and Training Support
WarpRec includes a curated suite of 55 state-of-the-art models covering unpersonalized, content-based, collaborative filtering, context-aware, sequential, and hybrid architectures. This includes canonical baselines (UserKNN, ItemKNN, SLIM, BPRMF), autoencoders (EASER, MultiVAE), graph-based (LightGCN, DGCF, LightCCF), sequential (Caser, GRU4Rec, BERT4Rec, SASRec), and recent advances (LightGCN++, MixRec, LinRec, etc.) drawn from contemporary literature. The design ensures strict decoupling of models from data and evaluation components, supporting fast model addition and cross-modal experimentation.
The Trainer abstracts optimization and experiment tracking, supporting distributed, multi-GPU, and Ray-based parallel execution. Built-in HPO includes grid/random search, Bayesian methods (HyperOpt, Optuna, BoHB), and efficient scheduling (ASHA), with robust checkpointing for experiment resumption. Observability is ensured through integration with TensorBoard, Weights&Biases, and MLflow.
Evaluation, Reproducibility, and Scientific Rigor
To directly address the absence of rigorous, reproducible evaluation in industrial-scale frameworks, WarpRec incorporates a comprehensive evaluation module:
- Metrics Suite: 40 metrics across accuracy, rating, coverage, novelty, diversity, bias, and fairness dimensions. Notably, WarpRec uniquely supports GPU-accelerated, multi-objective metric computation, enabling Pareto optimization in beyond-accuracy spaces.
- Statistical Testing: Automated hypothesis testing includes paired (Student's t-test, Wilcoxon) and independent-group (Mann-Whitney U) tests. Multiple comparison (Type I error) correction via Bonferroni and FDR is enforced by default, mitigating p-hacking and ensuring robust significance reporting.
- Artifact Logging: All results, including per-user metrics, HPO results, model weights, recommendation lists, and detailed execution metadata, are checkpointed to local/cloud storage. Emphasis is placed on full reproducibility, with strict random-seed management and energy profiling.
Ecological Responsibility: Green AI by Default
WarpRec directly incorporates sustainability analytics. CodeCarbon is adopted for real-time energy and carbon emission profiling during all phases of the pipeline. Empirical analysis on NetflixPrize-100M demonstrates that shallow models (e.g., EASER) achieve competitive performance with orders-of-magnitude lower carbon footprint compared to deep/graph-based architectures, supporting the Green AI research mandate (2602.17442).
Agentic AI Readiness and Model Serving
Anticipating the agentification of AI workflows, WarpRec natively supports the Model Context Protocol (MCP), enabling standard API access for LLM-driven tools and autonomous agentic pipelines. The Application Layer enables instant exposure of libraries via both RESTful APIs and MCP server interfaces, allowing recommenders to function as callable, interactive modules in agentic decision processes.
(Figure 1) (first reference justification: this is the first technical description of the architecture.)
Empirical Results and Numerical Evidence
Across datasets (MovieLens-1M, MovieLens-32M, NetflixPrize-100M), WarpRec achieves strong wall-time and resource utilization results. Notably:
- Robustness to scale: Competing frameworks exhaust memory or exceed timeouts on million-scale and above; WarpRec completes all benchmarks end-to-end and enables concurrent execution via Ray.
- EASER throughput: WarpRec outperforms all competitors for this industrially relevant model across all scales, highlighting effective dense matrix handling and pipeline optimization.
- Green AI metrics: For NetflixPrize-100M, LightGCN consumes 2.42 kWh (0.0095 kg CO2eq), whereas EASER remains below 0.115 kWh. Energy consumption is shown to be primarily a function of training duration rather than instantaneous power.
The system further demonstrates seamless agentic inference, where LLM agents interactively call WarpRec for sequential recommendations and receive context-aware, semantically enriched outputs.
Practical and Theoretical Implications
Practically, WarpRec enables academia-industry translation with literal production-readiness, empowering rapid prototyping, rigorous comparison, and zero-rewrite deployment. Laboratories can now evaluate algorithms at industrial scale, subject results to robust statistical scrutiny, and log resource/energy impacts transparently. Agent interoperability connects traditional RS research with emerging LLM-powered multi-agent ecosystems.
Theoretically, WarpRec's focus on multi-objective metric optimization, significance corrections, and environmental monitoring lays the foundation for responsible, scientifically credible advancement in RS research. Integration of agentic protocols positions the framework for upcoming shifts toward tool-augmented, LLM-centric RS workflows.
Conclusion
WarpRec establishes itself as an end-to-end, unified framework that operationalizes the convergence of academic rigor, industrial scale, energy responsibility, and agentic interoperability for recommender systems. It defines a new standard for scientific reproducibility, transparent benchmarking, and rapid translation of research advances into deployable technology, while supporting the agent-driven, multi-objective, and sustainable future of intelligent recommendation.