B$^3$-Seg: Camera-Free, Training-Free 3DGS Segmentation via Analytic EIG and Beta-Bernoulli Bayesian Updates
Abstract: Interactive 3D Gaussian Splatting (3DGS) segmentation is essential for real-time editing of pre-reconstructed assets in film and game production. However, existing methods rely on predefined camera viewpoints, ground-truth labels, or costly retraining, making them impractical for low-latency use. We propose B$3$-Seg (Beta-Bernoulli Bayesian Segmentation for 3DGS), a fast and theoretically grounded method for open-vocabulary 3DGS segmentation under camera-free and training-free conditions. Our approach reformulates segmentation as sequential Beta-Bernoulli Bayesian updates and actively selects the next view via analytic Expected Information Gain (EIG). This Bayesian formulation guarantees the adaptive monotonicity and submodularity of EIG, which produces a greedy $(1{-}1/e)$ approximation to the optimal view sampling policy. Experiments on multiple datasets show that B$3$-Seg achieves competitive results to high-cost supervised methods while operating end-to-end segmentation within a few seconds. The results demonstrate that B$3$-Seg enables practical, interactive 3DGS segmentation with provable information efficiency.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
B³‑Seg in Plain Language
What is this paper about?
This paper introduces B³‑Seg, a fast way to pick out (segment) a specific object from a 3D scene so artists and game developers can edit it. The 3D scene is stored in a popular format called 3D Gaussian Splatting (think of a scene built from thousands of tiny, fuzzy dots). B³‑Seg lets you type what you want (like “red mug”), and it finds that object in 3D without needing special training, original camera photos, or long wait times. It usually finishes in just a few seconds.
What questions were they trying to answer?
The authors wanted to know:
- Can we select objects in a 3D scene quickly without retraining a model or needing the original camera viewpoints?
- Can we do this for any word or phrase (open‑vocabulary), like “stuffed bear” or “green chair”?
- Can we choose the next camera angle smartly so each view teaches us as much as possible?
- Can we back up the method with theory, showing it makes steady, efficient progress?
How does the method work? (Simple explanation with analogies)
First, a few friendly definitions:
- 3D Gaussian Splatting (3DGS): A way to store a 3D scene as many fuzzy blobs (Gaussians) that render very fast.
- Segmentation: Picking which blobs belong to the object you care about.
- Open‑vocabulary: You can describe the object with any text you like.
- Beta–Bernoulli updates: A simple way to keep track of confidence using “yes/no” counts (like beads in two jars: one for “belongs to the object,” one for “doesn’t”).
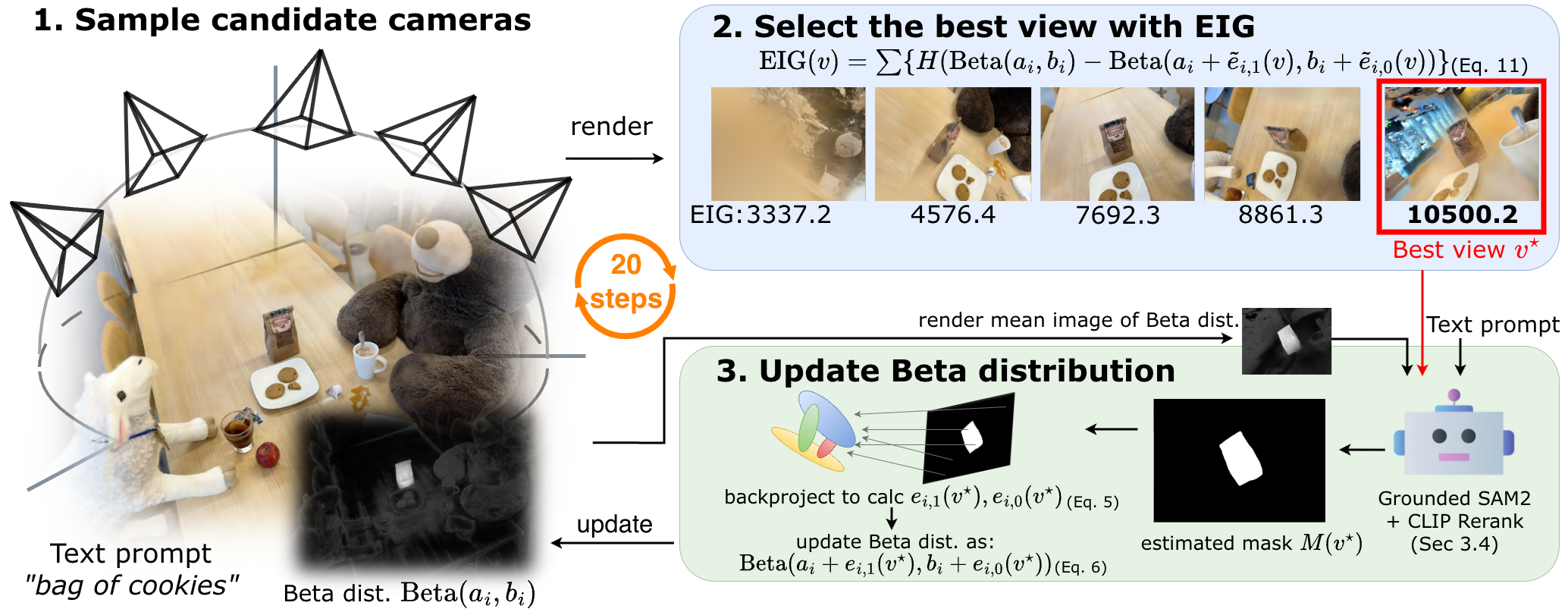
B³‑Seg runs in short, smart loops. Here’s the idea:
- Start with a fair guess
- Imagine every blob has a 50/50 chance of being part of your object. That’s your starting belief.
- Pick the next best view to look from
- The system quickly samples several possible camera angles around the object.
- For each angle, it estimates how much you would learn if you looked from there. This “learning score” is called Expected Information Gain (EIG).
- Intuition: it prefers angles where the object would be big and clear, not tiny or hidden.
- Look once, then get a 2D mask from that view
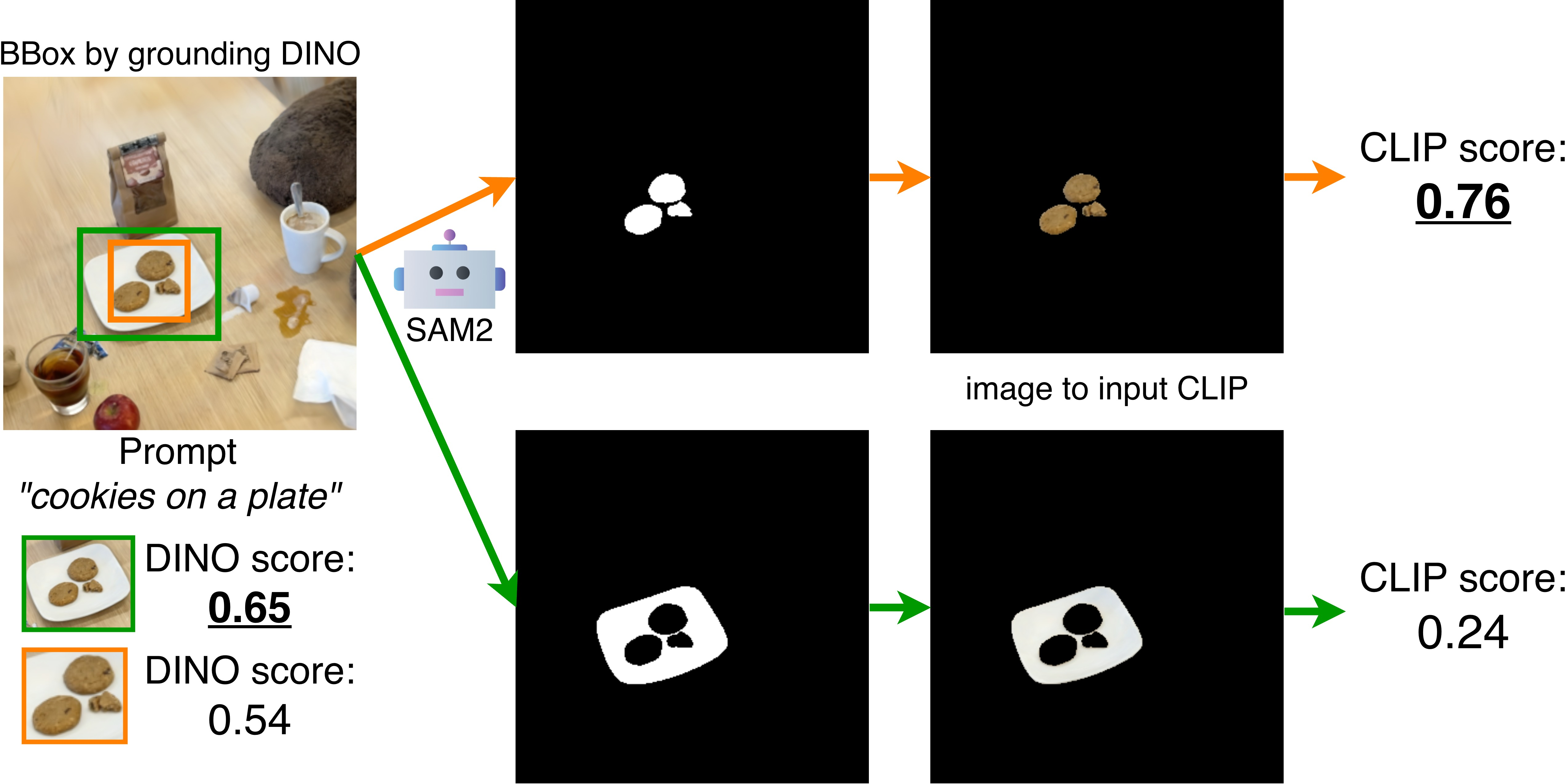
- From the chosen angle, the system renders an image and asks light‑weight tools to draw a 2D outline (mask) of the object:
- Grounding DINO suggests likely regions for your text (e.g., “bear”).
- SAM2 draws precise mask shapes.
- CLIP scores which mask best matches your text. The best one is kept.
- Update your confidence per blob (the “two jars” trick)
- If a blob contributes to pixels inside the mask, add “yes” counts. If it contributes outside, add “no” counts.
- This is the Beta–Bernoulli update: more yes/no evidence moves a blob’s probability up or down. It’s like filling the “yes” or “no” jar with beads to show confidence.
- Repeat a few times
- Repeat steps 2–4 about 20 times. Because each view is chosen to be informative, you learn fast.
- At the end, blobs with more “yes” than “no” are your object in 3D.
Why this is fast:
- The heavy segmentation tools (SAM2/CLIP) are run only on the single best camera view each round, not on all candidates.
- The “which view is best?” step uses a quick prediction (EIG) based on your current beliefs, so it avoids expensive operations on every candidate view.
What did they find, and why is it important?
Main results:
- Speed: The whole process finishes in a few seconds (about 20 views), which is great for interactive editing.
- No training or camera data needed: It works with just the 3DGS asset and your text prompt. No retraining, no ground‑truth labels, no original reconstruction cameras.
- Competitive quality: On common benchmarks, it matches or beats other fast, sampling‑based methods and comes close to much slower methods that depend on extra data and training.
- Theoretical guarantees: The math shows two good properties:
- Each chosen view never hurts and usually helps reduce uncertainty (non‑negativity).
- The “benefit per extra view” naturally decreases over time (diminishing returns).
- Because of these, a simple greedy strategy (always pick the current best view) is provably near‑optimal: it achieves at least about 63% of the best possible strategy you could get with perfect foresight.
Why it matters:
- Artists and level designers can select, move, or delete objects in 3D scenes quickly and confidently.
- Studios can share just the 3DGS asset between teams; no need to pass around the original image set or retrain large models.
What could this lead to next?
- Larger, more complex scenes: The same idea could be extended with smarter camera exploration for big indoor/outdoor spaces.
- Multiple objects: Today’s version targets one object vs. background. The same “counts in jars” idea can naturally extend to many objects using a multi‑class version.
- Even faster workflows: Since the view‑selection step is already light, future improvements could focus on making the 2D masking stage faster.
Takeaway
B³‑Seg is like an efficient detective for 3D scenes: it asks the most useful next question (best camera view), uses a quick mask to gather evidence, and updates its beliefs with simple, reliable counts. In just a few steps, it isolates the object you asked for—fast, training‑free, and with solid theory to back it up.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future work.
Modeling and theoretical assumptions
- Lack of noise-aware observation model: The Beta–Bernoulli updates assume binary, independent observations from masks. There is no explicit modeling of segmentation noise (false positives/negatives from Grounding DINO/SAM2/CLIP), nor a mechanism to learn or calibrate per-view/error rates. Future work: incorporate a noisy-channel model (e.g., Beta–Bernoulli with estimated FP/FN rates or hierarchical priors) and evaluate its effect on calibration and robustness.
- Independence and double-counting assumptions: The method treats per-pixel responsibilities as independent Bernoulli trials and aggregates them into fractional pseudo-counts, potentially overcounting correlated evidence across pixels and views. Future work: introduce dependency-aware priors or downweighting schemes (e.g., per-Gaussian evidence normalization or variance-scaled updates) and measure calibration.
- Resolution and scale sensitivity: Pseudo-counts scale with image resolution and rendering density (via summed responsibilities). The paper does not analyze how changing image resolution, FOV, or splat density affects posterior concentration and accuracy. Future work: derive resolution-invariant normalization, report calibration curves across resolutions, and provide guidelines or adaptive scaling.
- Binary-only formulation: The presented model handles a single foreground vs. background. While a Dirichlet–Categorical extension is mentioned, it is not developed nor evaluated (e.g., EIG for multi-class, multi-object). Future work: implement Dirichlet–Categorical updates, derive/query-aware EIG for multi-class/instance settings, and test on multi-object scenes with overlapping instances.
- Spatial priors and 3D consistency: The updates treat Gaussians independently and do not enforce spatial coherence (e.g., via CRF/Laplacian smoothing on the Gaussian graph). Future work: add spatial regularization and quantify trade-offs between boundary fidelity and stability.
EIG approximation and view planning
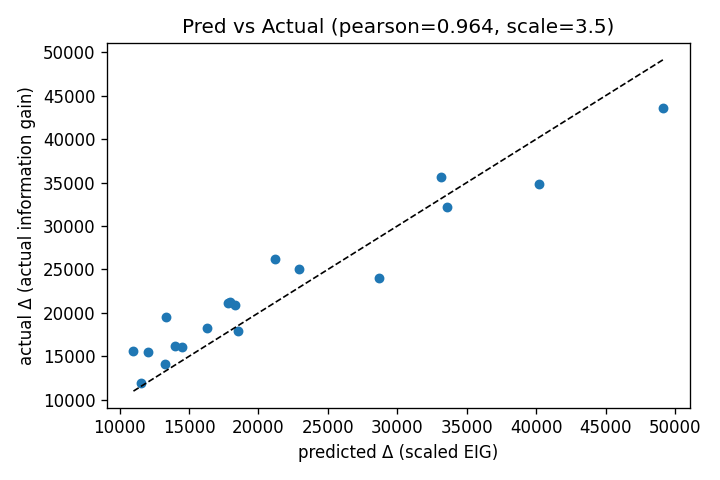
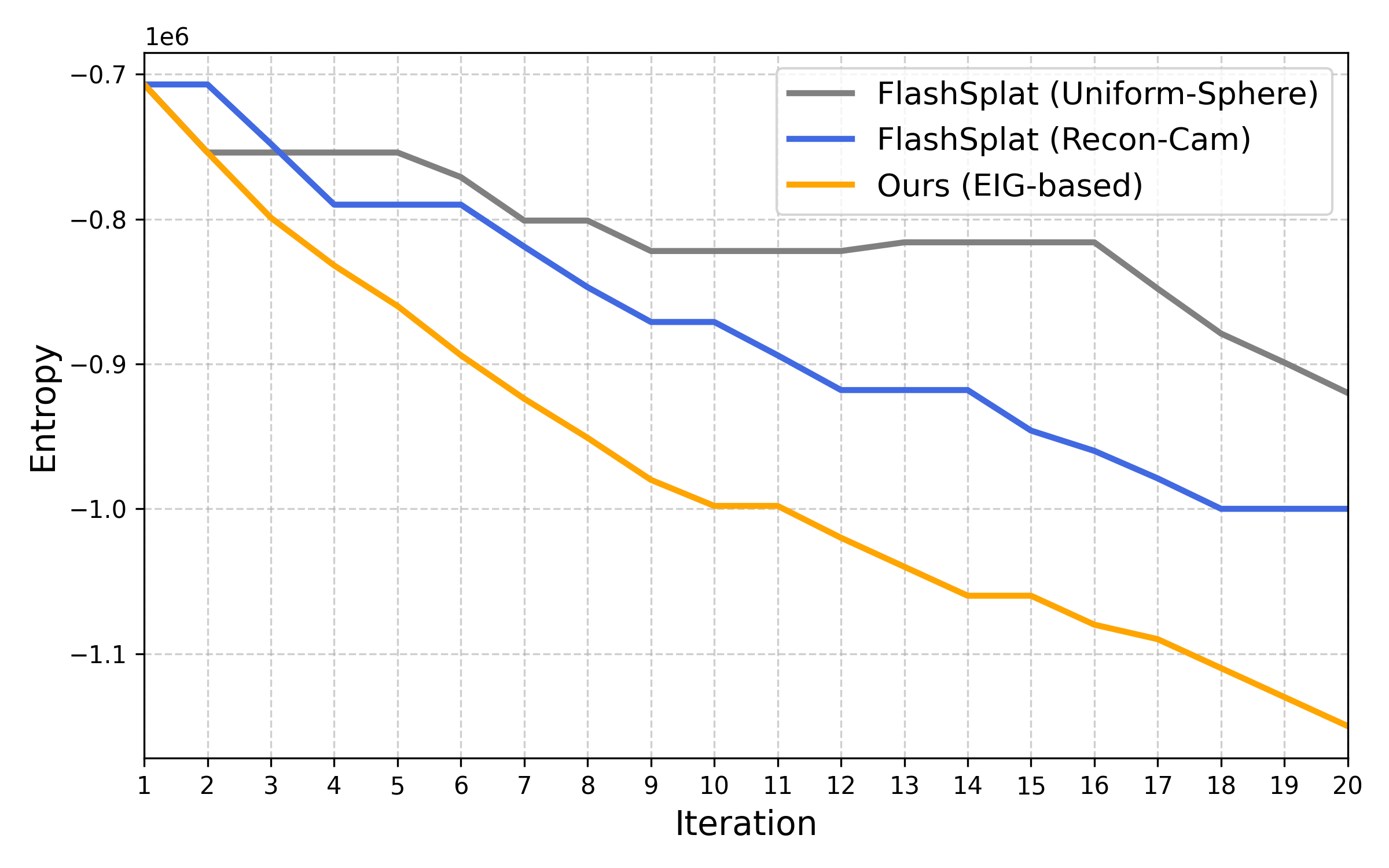
- No theoretical error bounds for EIG vs. true IG: The EIG replaces unknown mask outcomes with expectations using the posterior mean , but the paper only provides empirical correlation. Future work: derive bounds on ranking errors or regret when using EIG instead of IG, and characterize worst-case cases (e.g., high-entropy ).
- Objective mismatch in guarantees: The guarantee holds for the approximate EIG objective, not for the true information gain that depends on actual mask outcomes. The effect of this mismatch is unquantified. Future work: analyze performance guarantees under approximation error (e.g., using adaptive submodularity with approximate oracles) and report empirical regret relative to IG.
- Query-agnostic EIG: The EIG is driven by geometry/visibility and posterior means, not by how discriminative a view is for the text prompt (e.g., attributes like “red mug”). Future work: define a text-aware or CLIP-aware EIG that estimates the mutual information between view appearance and the query, and assess gains on ambiguous/compositional queries.
- Myopic planning and exploration: The method uses greedy, single-step selection; non-myopic planning and exploration–exploitation trade-offs are unaddressed. Future work: evaluate batched/lookahead planning (e.g., rollout policies or submodular maximization with batch constraints) and compare against greedy under tight view budgets.
- Candidate-view generation limitations: Viewpoints are uniformly sampled on a sphere around an estimated object center. There is no integration of scene geometry or occlusion-aware heuristics to bias candidates, nor coverage guarantees in large spaces. Future work: add coverage metrics, RRT- or visibility-graph-based exploration, and multi-scale sampling; evaluate on large indoor/outdoor scans.
Dependence on 2D open-vocabulary segmenters
- Sensitivity to 2D segmenter failures: The approach relies on Grounding DINO proposals, SAM2 masks, and CLIP re-ranking. Failure modes (small/transparent/reflective objects, heavy occlusion, domain shift, ambiguous prompts) and their impact on the Bayesian updates are not analyzed. Future work: stress tests on challenging categories, per-module ablations, and robust alternatives (e.g., soft mask confidences in updates, prompt augmentation).
- Confirmation bias from SAM2 mask-input: Feeding the posterior-derived prior () into SAM2 may amplify early mistakes. There is no mechanism to detect or correct self-reinforcing errors. Future work: introduce uncertainty-triggered resets, diversity-promoting priors, or cross-view consistency checks to prevent drift.
- Lack of uncertainty propagation from 2D models: The updates use binary masks rather than soft/confidence-weighted masks (available from many segmenters), ignoring uncertainty at the pixel level. Future work: integrate per-pixel probabilities in and assess calibration and robustness.
- CLIP ranking biases: CLIP is known to have prompt and dataset biases. The method lacks prompt-robustness analysis (synonyms, multi-lingual queries, compositional prompts) and failure recovery strategies. Future work: prompt-ensemble strategies, robustness benchmarks, and alternative VLMs.
Scalability and scene complexity
- Large-scale and cluttered environments: The method is evaluated on object-centric scenes; behavior in wide indoor spaces or outdoor scans is untested. Future work: scalability studies on large scenes (with many Gaussians and heavy occlusions), memory/runtime profiling, and hierarchical/cluster-based EIG computation.
- Dynamic scenes and non-rigid objects: The approach assumes static 3DGS assets; performance with moving objects (dynamic splats) or time-varying scenes is unknown. Future work: extend to time-indexed posteriors and view planning over time; evaluate on dynamic 3DGS datasets.
- Thin structures and boundary precision: There is no boundary-aware mechanism (e.g., Gaussian splitting, as in COB-GS). Future work: integrate boundary refinement (e.g., adaptive splitting or edge-aware priors) and measure improvements on thin/complex structures.
Initialization, stopping, and robustness
- Dependence on the initial view and mask: Although some robustness to center shifts is shown, the method still relies on a canonical initial view and a correct first mask. The “cold start” case with no reliable initial mask is not addressed. Future work: evaluate random or auto-discovered initial views, provide safeguards for bad starts (e.g., multi-hypothesis priors), and quantify sensitivity to initial segmentation errors.
- No principled stopping criterion: Fixed iteration budget () is used. There is no confidence-based stopping rule tied to posterior entropy or marginal EIG. Future work: implement adaptive stopping based on posterior entropy thresholds, marginal EIG plateaus, or IoU proxies; analyze budget–accuracy trade-offs.
Evaluation scope and reporting
- Limited benchmarks and categories: Evaluation is confined to LERF-Mask and 3D-OVS. Generalization to broader, more diverse datasets (e.g., multi-room indoor scans, outdoor scenes, industry assets) is not established. Future work: benchmark on larger, diverse corpora with standardized open-vocabulary protocols.
- Missing stress tests and ablations: The paper lacks systematic tests for prompt ambiguity, class rarity, small/transparent objects, severe occlusion, and heavy clutter. Future work: construct targeted test suites and report failure modes with qualitative/quantitative analyses.
- Runtime variability and hardware: Only one GPU and scene-size regime are reported. Scalability across hardware tiers and scene sizes (e.g., memory footprints, candidate-view scaling) is not quantified. Future work: provide complexity analyses and runtime/accuracy scaling curves across scene sizes and devices.
Functionality and extensions
- Multi-object and instance segmentation: The framework currently returns a single binary object mask; workflows for multiple objects, instance differentiation, and overlapping instances are not presented. Future work: implement Dirichlet–Categorical or nonparametric (e.g., CRP) priors for multi-instance labeling, define instance-aware EIG, and validate on multi-object datasets.
- Query-aware editing and compositional queries: The system does not handle conjunctions/disjunctions (“red mug on the left”), negation, or attribute-based disambiguation during view planning. Future work: integrate compositional semantics into mask scoring and EIG (e.g., via text-conditioned mutual information) and evaluate user-centric editing tasks.
- Any-time and interactive controls: There is no user-in-the-loop mechanism for correcting masks or guiding view selection in real time. Future work: add interactive corrections (scribbles, clicks) fused into Bayesian updates and study human-in-the-loop gains.
Practical considerations
- Robustness to imperfect 3DGS assets: The impact of poorly reconstructed splats (noise, misregistration, view-dependent artifacts) on pseudo-counts and EIG is not analyzed. Future work: add quality-aware weighting (e.g., opacity/covariance filters), outlier rejection, and tests on degraded assets.
- Codecs and memory constraints: Entropy computation over all Gaussians for each candidate may be costly in very large assets; memory/time trade-offs are not fully explored. Future work: investigate sparse/clustered EIG computation, streaming renderers, and caching strategies for real-time pipelines.
Glossary
- 3D Gaussian Splatting (3DGS): A 3D scene representation that uses anisotropic Gaussians to enable real-time, high-fidelity rendering. "Recently, 3D Gaussian Splatting (3DGS) \cite{3dgs} has rapidly gained attention as a 3D representation that combines real-time rendering with high visual fidelity."
- Active view selection: The process of choosing camera viewpoints to maximize information gained about a scene for tasks like reconstruction or segmentation. "Active view selection has been widely studied for 3D reconstruction."
- Adaptive monotonicity: A property of sequential decision problems where the expected benefit of adding an observation is non-negative. "confirming adaptive monotonicity and adaptive submodularity, leading to greedy approximation."
- Adaptive submodularity: A diminishing-returns property for expected gains in adaptive policies, underpinning performance guarantees for greedy strategies. "confirming adaptive monotonicity and adaptive submodularity, leading to greedy approximation."
- Bayes-optimal: A decision rule that maximizes expected utility under the posterior distribution. "In this symmetric case, the Bayes-optimal label reduces to selecting the class with the larger accumulated pseudo-counts, which exactly recovers the decision rule of Eq.~\eqref{eq:fs-solve}:"
- Beta entropy: The entropy (uncertainty) of a Beta distribution; used here to quantify uncertainty over Bernoulli parameters. "The Beta entropy is non-increasing in for "
- Beta function: A special function, B(a,b), appearing in the normalization of the Beta distribution. "we define as a Beta function"
- Beta–Bernoulli Bayesian updates: Conjugate updates for a Bernoulli likelihood with a Beta prior, yielding closed-form posterior parameter updates. "sequential Beta--Bernoulli Bayesian updates"
- Bernoulli distribution: A probability distribution over binary outcomes. "y_i\mid p_i\sim \mathrm{Bernoulli}(p_i), \qquad p_i\sim\mathrm{Beta}(a_i,b_i)."
- CLIP: A vision–LLM used to score alignment between masked image crops and text queries. "with CLIP \cite{clip} re-ranking"
- Conjugacy: The relationship where the prior and posterior belong to the same family, enabling simple closed-form updates. "By Beta-Bernoulli conjugacy, the posterior updates are"
- Digamma function: The derivative of the logarithm of the gamma function; appears in the analytic expression for Beta entropy. "where is the digamma function."
- Dirichlet–Categorical model: A conjugate Bayesian model for multi-class categorical outcomes (generalizes Beta–Bernoulli to more than two classes). "The framework naturally generalizes to a DirichletâCategorical model."
- Diminishing returns: The phenomenon where the marginal gain from additional observations decreases as more data is collected. "we prove the non-negativity and diminishing returns of EIG"
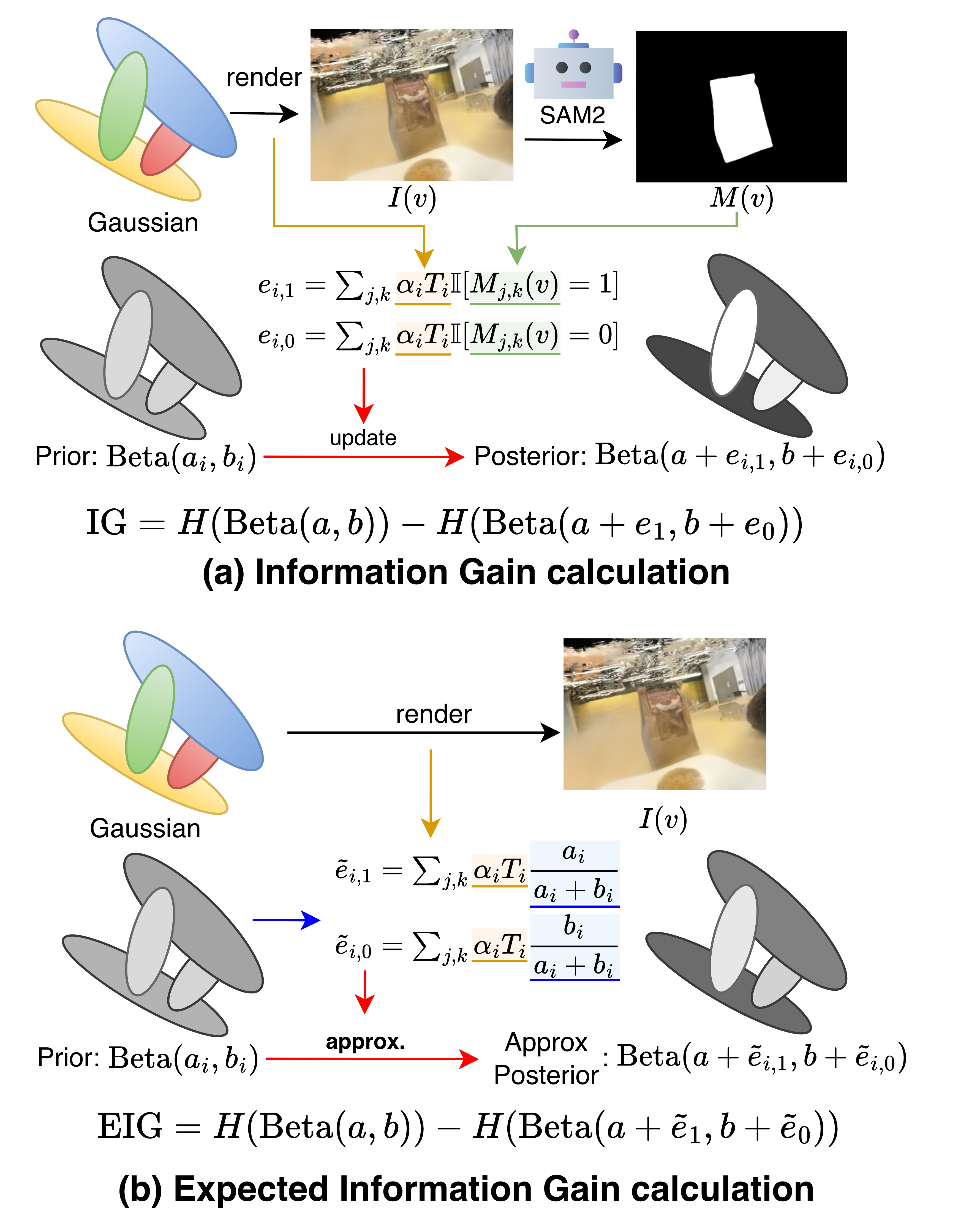
- Entropy: An information-theoretic measure of uncertainty; here, used to define information gain over Beta posteriors. "the information gain is the difference in entropy before and after adding that view:"
- Expected Information Gain (EIG): The expected reduction in uncertainty from a potential observation, computed analytically without running segmentation for every candidate view. "select the next view via analytic Expected Information Gain (EIG)."
- Fisher information: A measure of the amount of information that an observable variable carries about an unknown parameter. "FisherRF \cite{fisherrf} formulates the next-best view using Fisher information."
- Greedy (1−1/e) approximation: A classical performance guarantee that greedy selection achieves at least a (1−1/e) fraction of the optimal value for (adaptive) submodular maximization. "leading to greedy approximation."
- Grounding DINO: An open-set, text-conditioned object detector that proposes candidate regions aligned with a user prompt. "Grounding DINO~\cite{grounding-dino} generates candidate bounding boxes that indicate possible object regions."
- Information gain (IG): The reduction in entropy between a prior and posterior after observing data. "the information gain is the difference in entropy before and after adding that view:"
- Linear program: An optimization problem with a linear objective and linear constraints; used here to solve mask–label consistency. "FlashSplat casts the consistency between 2D masks and 3D labels as a linear program,"
- MAP decision: Maximum a posteriori decision rule that selects the most probable hypothesis under the posterior. "FlashSplatâs label-selection rule appears as the MAP decision within our Bayesian formulation."
- mBIoU: Mean boundary Intersection-over-Union, a segmentation metric focusing on boundary alignment. "Accuracy (mIoU / mBIoU)"
- mIoU: Mean Intersection-over-Union, a standard segmentation accuracy metric averaged across classes or instances. "Accuracy (mIoU / mBIoU)"
- NeRF: Neural Radiance Field, a neural scene representation for view synthesis. "LERF \cite{lerf} integrates CLIP features into a NeRF by optimizing a dense language field across views, enabling flexible text queries but requiring access to multi-view images and extended scene optimization."
- Open-vocabulary segmentation: Segmenting objects using flexible text prompts rather than a fixed label set. "We achieve open-vocabulary 3DGS segmentation in a few seconds without camera viewpoints, ground-truth labels, or retraining."
- Opacity: The per-Gaussian alpha value that controls how much a point attenuates light along a ray in rendering. "Each Gaussian has mean , covariance , opacity , and color ."
- Posterior mean: The expected value of a parameter under its posterior distribution. "the posterior mean becomes ."
- Pseudo-counts: Effective counts that summarize observed evidence in conjugate Bayesian models. "We estimate per-view pseudo-counts from one render and choose the next view using analytic EIG."
- RRT-based camera sampling: Using Rapidly-exploring Random Trees to explore and sample informative camera viewpoints. "Integrating methods like RRT-based camera sampling or multi-scale candidate generation"
- SAM2: A segmentation model used here to produce masks for candidate regions, optionally guided by a prior mask input. "SAM2~\cite{sam2} for segmentation masks."
- Transmittance: The cumulative transparency along a ray that modulates each Gaussian’s contribution during rendering. "where denotes the transmittance along the ray in view ."
- Visibility voting: Aggregating visibility evidence from multiple views to decide object membership. "It uses visibility voting from multiple views based on empirically designed camera trajectories."
Practical Applications
Overview
Based on the paper’s contributions—camera‑free, training‑free, open‑vocabulary 3D Gaussian Splatting (3DGS) segmentation with analytic Expected Information Gain (EIG), fast sequential Beta–Bernoulli Bayesian updates, and greedy selection with a provable (1−1/e) approximation—below are practical applications and workflows across industry, academia, policy, and daily life. Each item notes sector alignment, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed now using current 3DGS assets, standard GPUs, and off‑the‑shelf models (Grounding DINO, SAM2, CLIP).
- Interactive object selection and editing for film/VFX and games
- Sectors: Media & Entertainment, Gaming, Software tools
- What it enables: Few‑second, open‑vocabulary selection, removal, or editing of objects in pre‑reconstructed 3DGS assets—without retraining, pre‑defined camera paths, or ground‑truth labels.
- Tools/workflows:
- Plugin for 3DGS editors (e.g., SuperSplat) to “lasso by text” and isolate objects for compositing, retexturing, relighting, or replacement.
- Extension to Nerfstudio-like viewers: EIG-driven “next best view” button for rapid refinement of object masks.
- Assumptions/dependencies:
- High‑quality 3DGS asset available; initial canonical/seed view for bootstrapping the Beta prior; a GPU for fast inference; reliance on Grounding DINO + SAM2 + CLIP for 2D masks and text matching.
- Rapid 3D asset QA and cleanup in production pipelines
- Sectors: Media & Entertainment, Software/Tools
- What it enables: Quick validation of object completeness, de‑occlusion via informative views, and automated artifact removal (e.g., clutter, stray splats) in shared assets.
- Tools/workflows:
- “EIG Inspector” that guides reviewers to views with largest expected uncertainty reduction.
- Batch script that runs B³‑Seg to flag low‑confidence regions for manual review.
- Assumptions/dependencies:
- Asset is in 3DGS format; the uncertainty proxy (Beta entropy) correlates with mask quality; CLIP text prompts are relevant and precise.
- Open‑vocabulary 3D object cropping for e‑commerce and digital twins
- Sectors: Retail/e‑commerce, Digital Twins, Content Production
- What it enables: Text‑guided isolation of products (e.g., “red chair”) from scanned showrooms for web deployment or AR previews.
- Tools/workflows:
- Web service/API that takes a 3DGS and a text query, returns a clean per‑object 3D mask and cropped asset.
- Pipeline to auto‑catalog SKUs by segmenting products from multi‑item scans.
- Assumptions/dependencies:
- CLIP text alignment is sufficient for the product vocabulary; scans capture products distinctly enough for 2D segmenters.
- Consumer AR/VR: in‑app 3D object removal and replacement
- Sectors: AR/VR, Consumer Apps, Real Estate/Interior Design
- What it enables: Users capture a room as a 3DGS and immediately remove or recolor objects via text prompts (e.g., “remove the coffee table”).
- Tools/workflows:
- Mobile or desktop AR app feature that leverages EIG to suggest a couple of additional views to improve selection quality.
- Assumptions/dependencies:
- On‑device or edge GPU acceleration; acceptable latency (~seconds); robust object detection by Grounding DINO/SAM2 from user-captured images.
- Dataset bootstrapping and 3D annotation for research/ML
- Sectors: Academia/Research, Software/ML toolchains
- What it enables: Fast generation of 3D object labels from object‑centric scenes without manual multi‑view annotation.
- Tools/workflows:
- “3DGS Auto‑Labeler” that exports per‑Gaussian labels and propagates them to point clouds or meshes.
- EIG‑guided active annotation to minimize human clicks by focusing on most informative views.
- Assumptions/dependencies:
- Binary segmentation suffices or class‑by‑class pass is acceptable; downstream conversion from Gaussian labels to other formats is available.
- Privacy and compliance redaction for shared 3D captures
- Sectors: Policy/Compliance, Enterprise IT, Facilities
- What it enables: Remove/obscure personally identifiable objects (e.g., “face,” “license plate,” “documents”) in 3D scans before sharing.
- Tools/workflows:
- Policy‑driven presets (e.g., “Redact people”) using text prompts; EIG to ensure views capture sensitive content reliably.
- Assumptions/dependencies:
- Open‑vocabulary detectors correctly identify sensitive categories; legal/compliance approval of automated redaction workflows.
- Robotics scanning and digital asset creation (offline planning)
- Sectors: Robotics, Mapping, AEC (Architecture/Engineering/Construction)
- What it enables: After an initial 3DGS build, plan a short set of additional views that maximally clarify object boundaries for accurate semantic maps.
- Tools/workflows:
- “NBV for semantics” module that proposes robot camera poses to reduce segmentation uncertainty.
- Assumptions/dependencies:
- Robot can execute suggested views; environment is relatively static; initial 3DGS exists or can be built quickly.
Long‑Term Applications
These require further research, scaling, or engineering beyond the paper’s current scope (e.g., multi‑class extensions, very large environments, dynamic scenes, or broader hardware support).
- Multi‑class and instance‑rich 3D editing and compositing
- Sectors: Media & Entertainment, Gaming, Software tools
- What it could enable: Simultaneous segmentation of many objects/categories (e.g., scene‑wide instance maps) using Dirichlet–Categorical generalization.
- Tools/products:
- “Scene Atlas” that outputs an instance‑segmented 3DGS for downstream editing and physics‑aware simulations.
- Assumptions/dependencies:
- Stable multi‑class open‑vocabulary masks across many categories; scalable memory and compute for multi‑label posteriors.
- City‑scale or campus‑scale active semantic mapping
- Sectors: Robotics, Smart Cities, Infrastructure, AEC
- What it could enable: EIG‑driven active camera planning across large outdoor/indoor spaces to converge faster to reliable 3D semantics.
- Tools/products:
- Hierarchical EIG planners (multi‑scale spheres, RRT‑style exploration) integrated into SLAM/mapping stacks.
- Assumptions/dependencies:
- Efficient candidate sampling and rendering over huge scenes; robust handling of dynamic objects and occlusions; streaming 3DGS builds.
- Real‑time AR glasses workflows with uncertainty guidance
- Sectors: AR/VR, Wearables, Consumer/Enterprise
- What it could enable: On‑device or edge‑assisted view suggestions that reduce uncertainty for live object selection in MR experiences.
- Tools/products:
- “Informative View” HUD that prompts users to move slightly to better segment a target object.
- Assumptions/dependencies:
- Low‑power accelerators/GPU; compressed 3DGS representations; low‑latency 2D segmenters on wearable hardware.
- 3D content moderation and safety tools for UGC platforms
- Sectors: Policy/Compliance, Platforms/Social, E‑commerce marketplaces
- What it could enable: Open‑vocabulary detection and masking of prohibited objects in user‑uploaded 3D scans (e.g., weapons, logos).
- Tools/products:
- Automated moderation pipeline that flags high‑uncertainty regions for human review using Beta entropy thresholds.
- Assumptions/dependencies:
- Highly reliable category detection across broad vocabularies; auditable logs of uncertainty and view selection decisions.
- Foundation‑model training data curation and active acquisition
- Sectors: AI/ML, Data Operations
- What it could enable: EIG‑guided selection of additional views or scenes to maximize information per acquisition for 3D‑aware foundation models.
- Tools/products:
- “Active Capturer” that recommends additional camera paths to enrich semantics where the model is least certain.
- Assumptions/dependencies:
- Feedback loop from model uncertainty to acquisition; coordination between capture teams and training pipelines.
- Cross‑representation 3D editing (NeRFs, meshes, point clouds)
- Sectors: Software tools, AEC, Digital Twins
- What it could enable: Transfer B³‑Seg’s labels from 3DGS to other formats for universal 3D editing, simulation, and CAD workflows.
- Tools/products:
- Converters that propagate per‑Gaussian posteriors to per‑vertex/point labels; hybrid viewers supporting multiple representations.
- Assumptions/dependencies:
- Accurate mapping between 3DGS and target geometry; consistent visibility/responsibility modeling.
- Dynamic scene understanding and temporal segmentation
- Sectors: Robotics, Autonomous Systems, Sports/Events
- What it could enable: Extend EIG and Bayesian updates to time‑varying scenes with moving objects and streaming reconstructions.
- Tools/products:
- Spatiotemporal EIG policies, temporal priors for Beta/Dirichlet posteriors, and motion‑aware mask inputs.
- Assumptions/dependencies:
- Real‑time 3DGS updates; robust tracking and temporal consistency in 2D segmenters.
Key Cross‑Cutting Assumptions and Dependencies
- Input representation and quality:
- A reasonably clean 3DGS asset must exist; segmentation quality depends on reconstruction fidelity and coverage.
- External models:
- Performance hinges on 2D open‑vocabulary detectors/segmenters (Grounding DINO, SAM2) and CLIP text‑image alignment; domain shifts can degrade results.
- Compute and latency:
- Few‑second runtimes were reported on a high‑end GPU; edge/mobile deployment may require optimization or offloading.
- Problem scope:
- Current pipeline is binary (foreground/background) per run; multi‑object scenes may need repeated passes or a multi‑class extension.
- Scene scale:
- Method is validated on object‑centric scenes; large‑scale environments may need advanced candidate‑view exploration (e.g., multi‑scale sampling).
- Initialization:
- A seed/canonical view is used to initialize the prior; poor initial masks can be mitigated by EIG‑guided iterations but still affect early steps.
- Theoretical guarantees:
- The (1−1/e) greedy bound holds for the analytic EIG under Beta entropy assumptions and the approximated pseudo‑counts; practical gains depend on correlation between EIG and true IG (empirically shown but still an approximation).
Collections
Sign up for free to add this paper to one or more collections.

