- The paper introduces a GPU-accelerated MPZCH algorithm that eliminates embedding collisions using a novel linear probing mechanism with explicit ID retirement.
- The paper demonstrates that modest over-provisioning and configurable eviction policies achieve zero collisions while maintaining high throughput and improved prediction accuracy.
- The paper integrates MPZCH with TorchRec, offering stable, fine-grained control over embedding freshness to adapt rapidly to evolving user-item interactions.
Multi-Probe Zero Collision Hash (MPZCH): Embedding Collision Mitigation and Freshness for Large-Scale Recommenders
Introduction
A central bottleneck in modern large-scale recommender systems is the management of high-cardinality embedding tables, where billions of unique user, item, and feature IDs must be mapped to dense vectors under stringent memory constraints. Canonical approaches leverage static-size hash-based tables, which inevitably introduce collisions: distinct IDs mapped to the same row interfere, conflating semantic information and sabotaging personalization quality. Furthermore, the inability of standard hash tables to retire obsolete IDs leads to stale embedding inheritance, impeding adaptation to evolving distributions. These deficiencies are acute for both user and rapidly-turning item embeddings and necessitate more sophisticated, scalable mechanisms.
Previous efforts to control collision rates and embedding staleness fall broadly into three paradigms: collisionless hashing, advanced probabilistic mechanisms, and semantically informed collision tolerance. Cuckoo hashing and dynamic expiration (e.g., Monolith [liu2022monolith]) guarantee per-ID uniqueness for frequent entities, but exhibit severe scalability constraints due to memory requirements. Other methods—mixed-dimension embeddings [ginart2021mixed], QR-based and Tensor Train-based factorizations [shi2020compositional, yin2021ttrec]—target memory efficiency but introduce computational overhead. In contrast, approaches like Multiplexed Embeddings [huan2023multiplexed] and frequency-based double hashing [zhang2020frequency] sacrifice precision for tail items. Recent lines have also embedded collision resolution into the learning process (e.g., DHE [kang2020dhe], Learning to Collide [ghaemmaghami2022collide], Semantic IDs [kulkarni2024semantic]), but these generally require heavy preprocessing and can induce oversmoothing.
The MPZCH Algorithm
MPZCH introduces a practical, GPU-accelerated alternative that unifies collision mitigation with embedding freshness in production-scale settings. The core is a high-performance CUDA kernel implementing linear probing, augmented with auxiliary tensors for explicit per-slot ID management and metadata, enabling configurable eviction strategies.
The system stores, for each embedding slot, both the ID presently mapped and auxiliary metadata (such as TTL). Insertions scan deterministically for existing or empty slots, only evicting stale entries when strictly necessary and never overwriting live embeddings. The two-pass probing guarantees no duplicate ID assignments and prevents inadvertent premature evictions induced by transient activity patterns (see the simplified probing and collision logic in (Figure 1)).
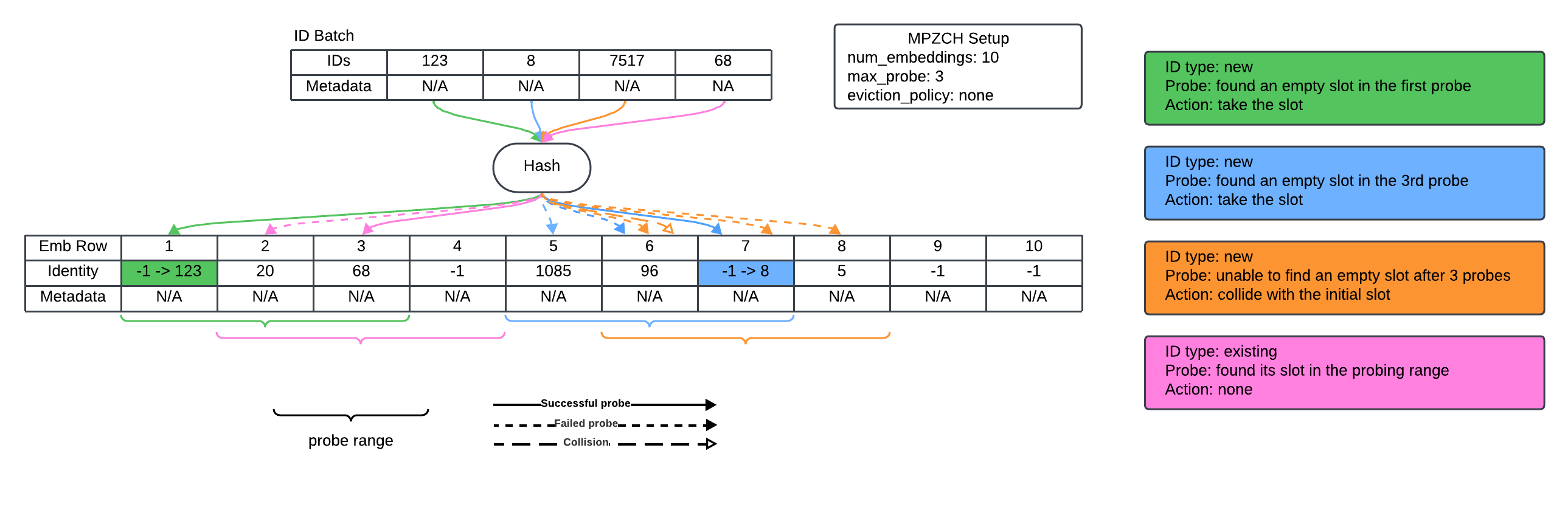
Figure 1: A simplified example of ID insertion, lookup, and collision handling.
Throughout, auxiliary identity and metadata tensors allow the embedding table to explicitly retire obsolete or infrequent IDs, resetting both weights and optimizer state upon reassignment to avoid negative transfer. This preserves the semantic isolation between different IDs, in stark contrast to standard hash tables, where collisions promote uninformative, noisy representations. The eviction mechanism, primarily utilizing TTL but supporting LRU and per-feature tuning, enables fine-grained control over the temporal relevance of stored embeddings (demonstrated in (Figure 2) and (Figure 3)).
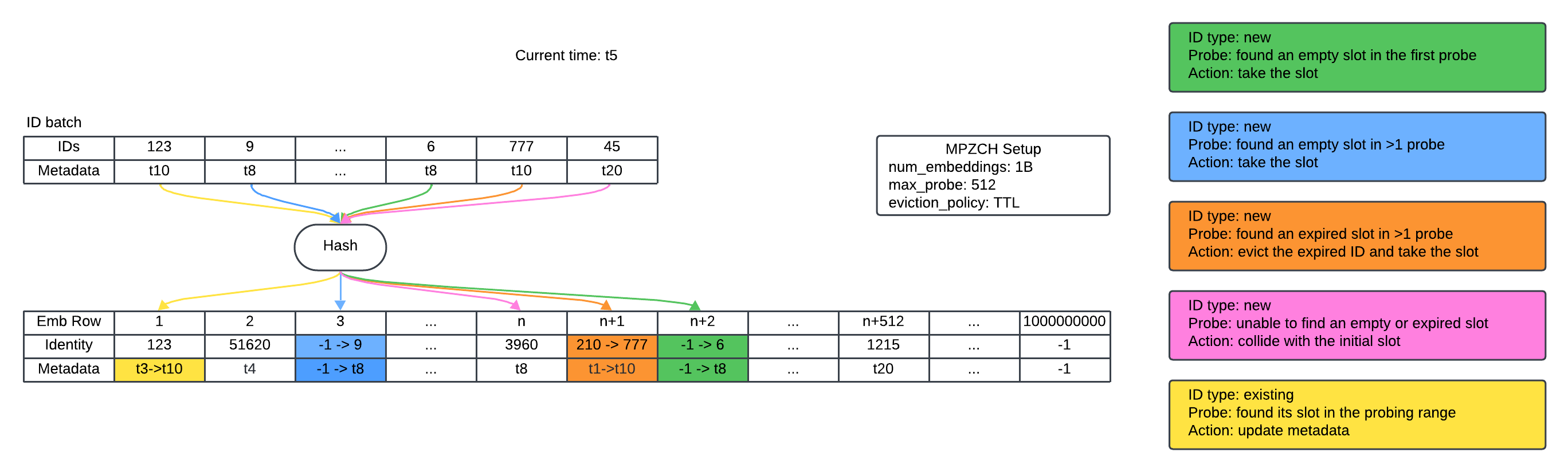
Figure 2: An example of kernel execution with TTL eviction policy—expired slots are evicted lazily upon new allocations.

Figure 3: An example of kernel execution with LRU eviction policy, evicting the oldest entry within the probe range.
The implementation is tightly integrated with TorchRec for sharded, distributed training. Shard-local identities and metadata ensure all operations are parallel, obviating cross-rank synchronization and preserving high throughput (visualized in (Figure 4)).
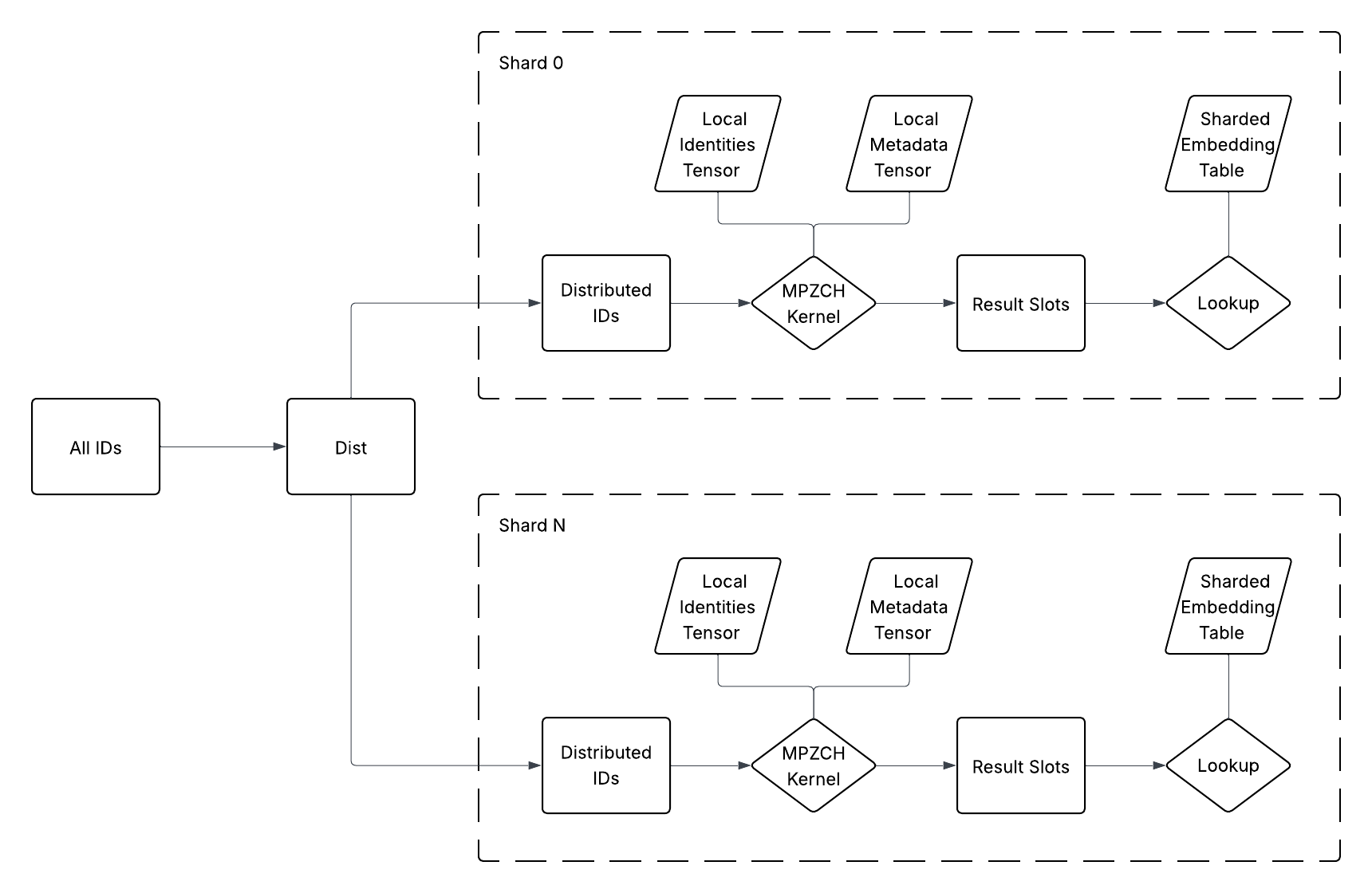
Figure 4: The MPZCH module is co-sharded with the associated embedding table, ensuring that operations are executed locally within each shard.
Empirical Findings
Collision Elimination and Throughput Maintenance
MPZCH empirically demonstrates that with embedding table sizes modestly exceeding ID cardinality (e.g., 1.33×), and moderate probe depth, collision rates can be driven to zero—a feat unattainable with Sigrid hashes, even when over-provisioned by 3× (see results cited in the original work). Notably, such collision-freedom is achievable at negligible inference/training latency cost due to the highly efficient, batched CUDA kernel design—even at large probe depths—preserving system QPS constraints critical to industrial deployment.
User Embeddings: Prediction Accuracy Gains
In production deployment with 4B user IDs (capacity/usage ≈1.33×), MPZCH eliminated user embedding collisions completely. This architectural guarantee translates to statistically significant gains in normalized entropy for 14 of 17 user prediction tasks, with neutral impact in the remainder. These uplifts, realized in models already subjected to exhaustive tuning, underscore the persistent harm of embedding collisions in mature pipelines.
Item Embeddings: Cold-Start and Freshness Enhancement
For volatile item embeddings, the benefits are twofold: (1) proactive eviction reclaims memory from inactive items, guaranteeing fresher, contextually relevant table allocation; (2) explicit reset-on-evict prevents transfer from stale embeddings, accelerating convergence for new entries. Empirical AB tests in video retrieval yield a 0.83% increase in impressions for new content and measurable boosts in semantic clustering of embeddings—new videos from the same creator cluster more tightly under MPZCH, facilitating improved semantic retrieval (visualized in (Figure 5)).
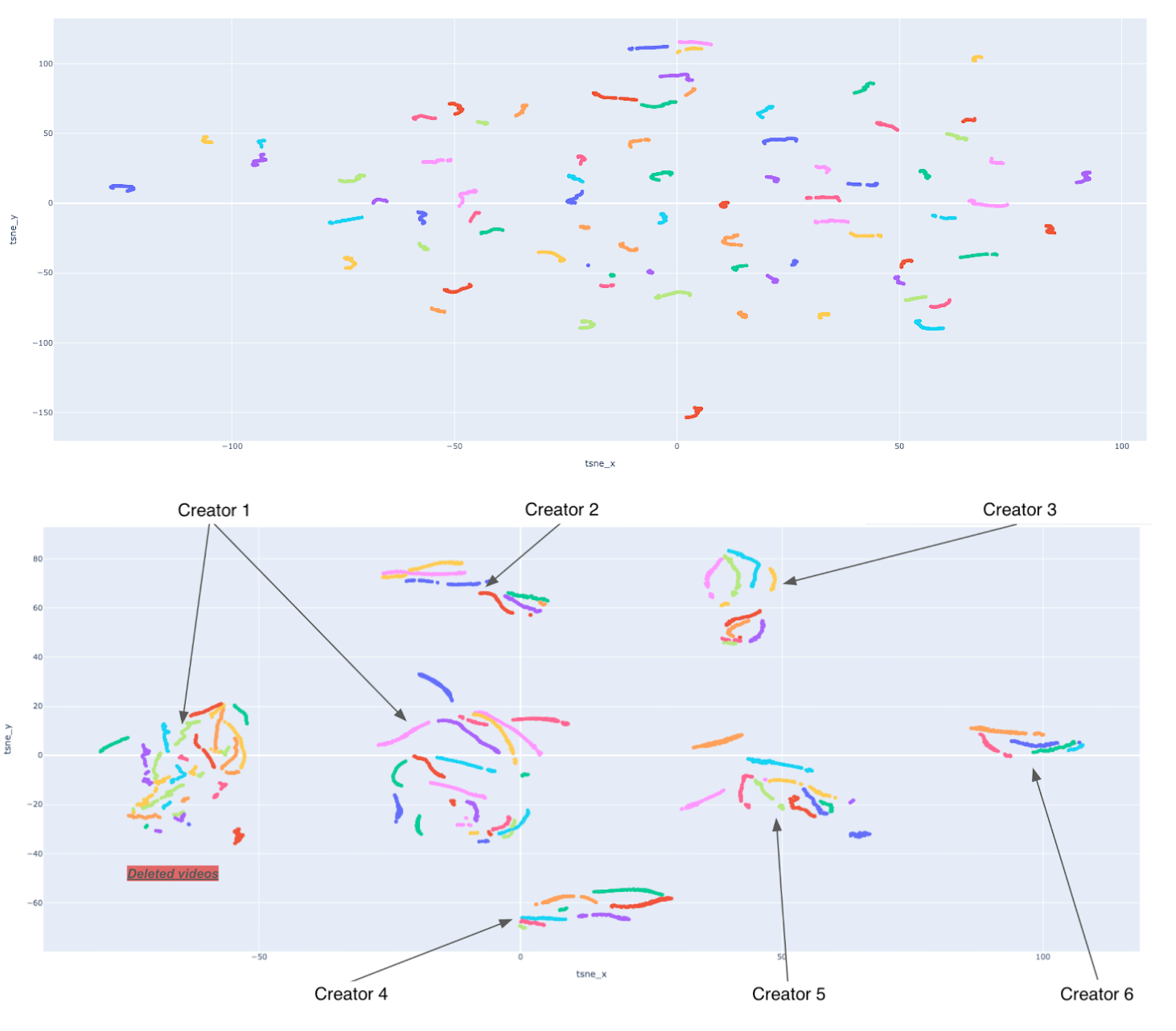
Figure 5: Embedding space before and after MPZCH—for select creators, same-owner embeddings show much tighter clustering post-MPZCH.
Furthermore, learning dynamics are stabilized: rather than abrupt, uncorrelated shifts induced by collision-driven updates, embedding trajectories converge smoothly under MPZCH, supporting faster, high-fidelity training (demonstrated in (Figure 6)).
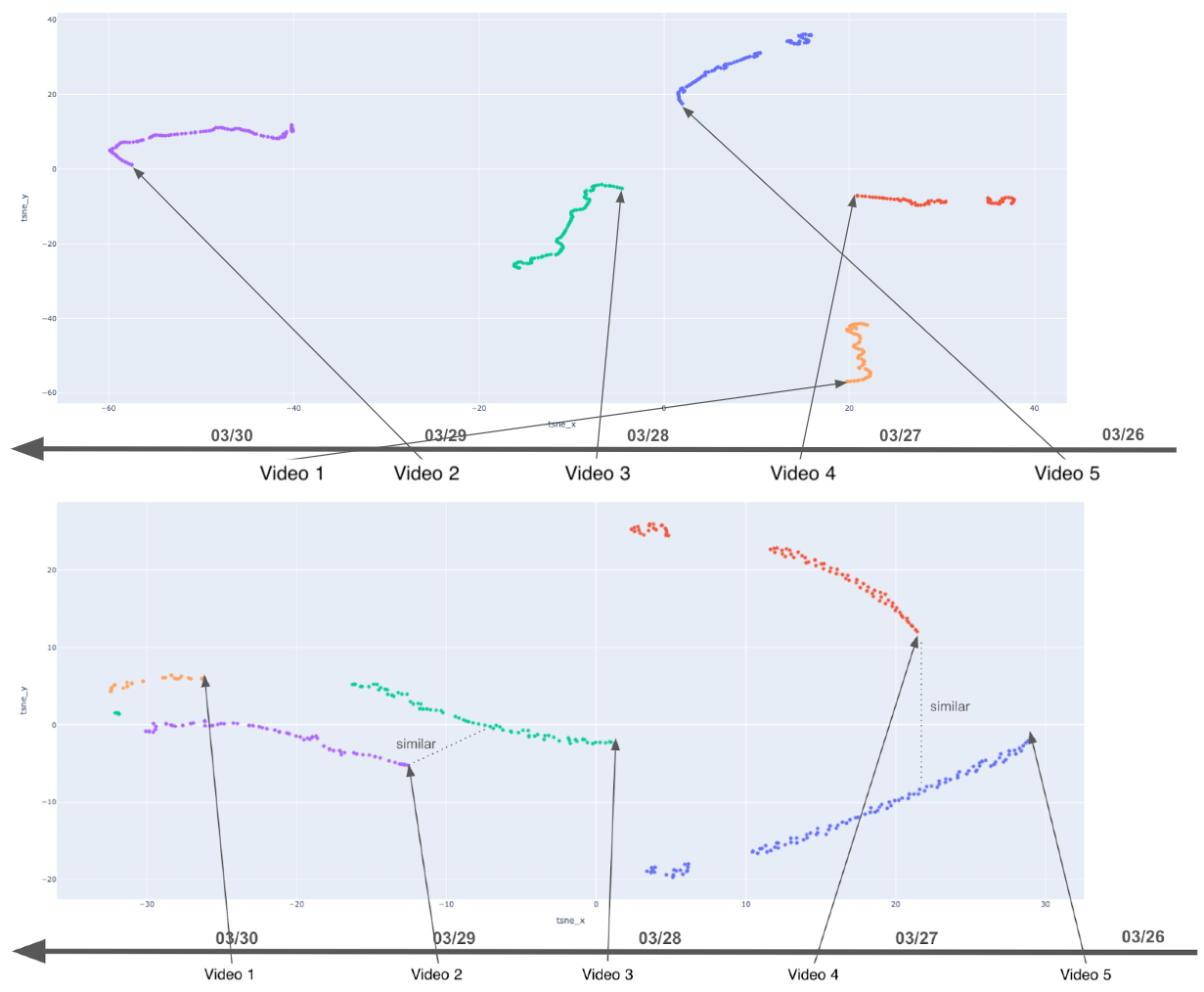
Figure 6: Embedding learning trajectories—MPZCH yields stable, smooth updates compared to noisy fluctuations under standard hashing.
Theoretical and Practical Implications
MPZCH demonstrates that, with modest over-provisioning and aggressive parallelism, deterministic, collision-free embedding assignment is feasible at scale for high-frequency ID classes. It eliminates the tradeoff between cacheability, memory budget, and embedding fidelity, and paves the way for systems where online and streaming updates do not degrade representational quality over time.
Practically, MPZCH’s explicit ID retirement and modular eviction policy allow operators to precisely tune the model’s temporal sensitivity to new/obsolete content, offering avenues for more agile adjustment to emergent behavioral shifts in the underlying interaction graph. Its integration into TorchRec further democratizes adoption and simplifies migration for teams relying on PyTorch-based recommender workflows.
Future Directions
Open avenues include the exploration of adaptive, learnable eviction strategies that dynamically optimize retention based on downstream performance or item relevance, hybrid approaches combining compositional and collisionless lookup for tail entities, and theoretical analysis of probe depth tradeoffs for non-uniform ID popularity distributions. Further, extending MPZCH’s principles to sequence modeling and multi-modal embedding architectures could unlock analogous fidelity and freshness improvements in settings beyond recommendation.
Conclusion
MPZCH establishes a robust, production-ready paradigm for collision-free and fresh embedding management in industrial-scale recommenders. By combining deterministic identity tracking, parallelized probing, and configurable per-slot retirement, it addresses longstanding limitations of standard hash tables and enables appreciable, quantifiable improvements in both model accuracy and responsiveness to real-time content churn, as validated in large-scale AB testing and qualitative embedding analysis (2602.17050).