- The paper introduces a pipeline that combines sparse autoencoders with steerable LLM interventions to isolate latent textual treatments.
- It demonstrates that adaptive steering and dimension-by-dimension residualization effectively reduce bias and RMSE in causal effect estimation.
- Empirical validation on multiple datasets confirms the method’s robustness and its potential for hypothesis-driven experiments in diverse fields.
Causal Effect Estimation with Latent Textual Treatments: A Technical Essay
Motivation and Problem Statement
Quantifying the causal effects of text-based interventions is foundational across domains that depend on language, such as political science, marketing, and behavioral economics. However, experimental pipelines for causal inference with text face two core obstacles: generating controlled, readable textual variation and ensuring downstream causal identification by properly separating intended interventions from nuisance contextual features. Naïve approaches confound treatment and covariate information—especially when leveraging modern LLMs, whose representations entangle semantic and contextual information. This paper presents a comprehensive pipeline to overcome these obstacles, built around sparse autoencoders (SAEs), steerable LLM interventions, and a theoretically principled residualization methodology for causal effect estimation (2602.15730).
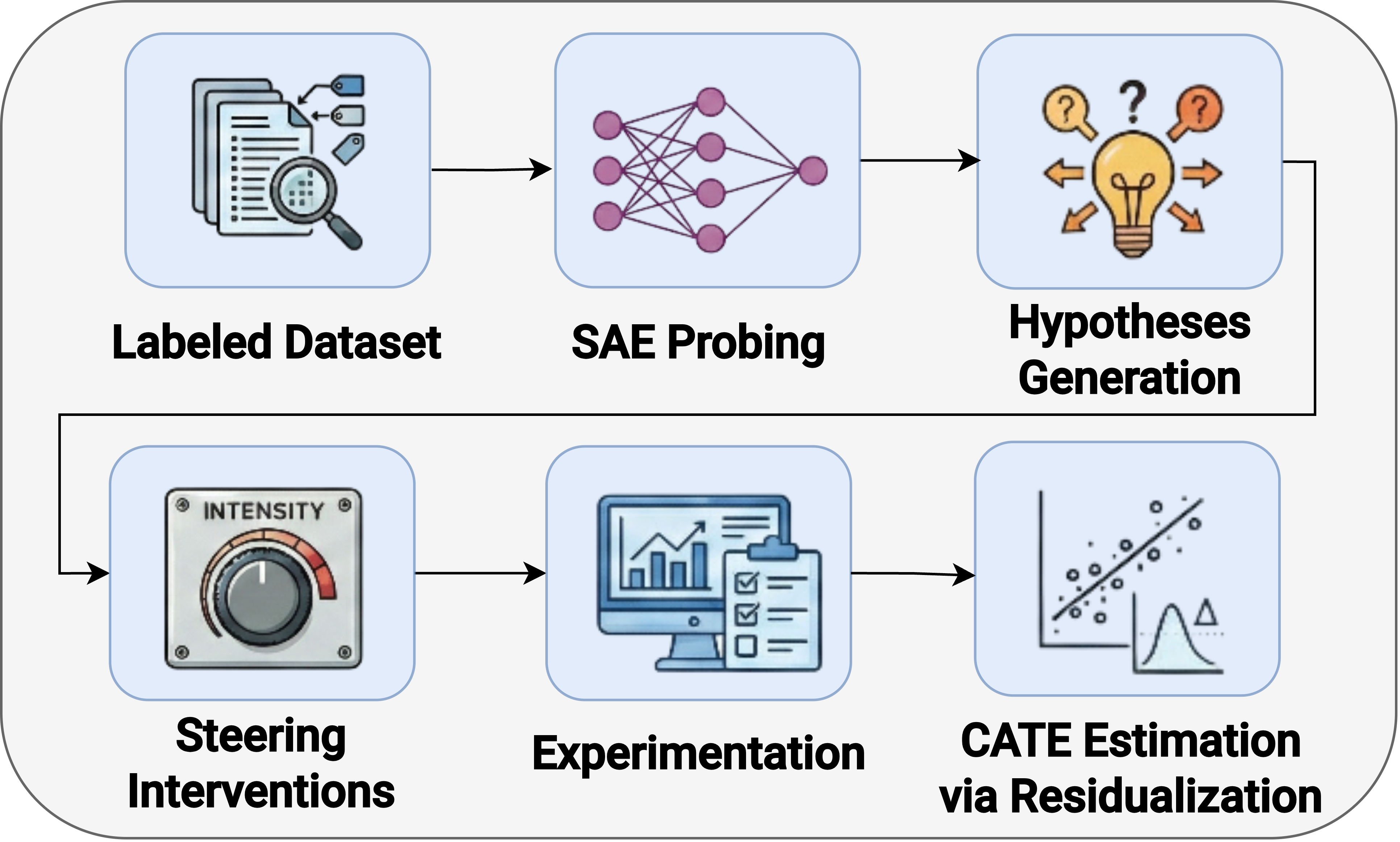
Figure 1: Schematic overview showing the pipeline from labeled text, SAE probing, feature steering, quasi-counterfactual generation, to downstream causal estimation with residualization.
SAE-Based Feature Discovery and Steering
The pipeline begins with hypothesis generation using SAE representations extracted from LLMs. SAE latents are filtered to retain semantically relevant features. Sparse linear probes (with L1 regularization and cross-validation) identify monosemantic SAE features highly predictive of target concepts (e.g., civility, political affiliation). To systematize the search, the paper introduces an IC score combining steering intensity (mean token-level cosine similarity against decoder columns) and output coherence, allowing for robust selection of candidate interventions across LLM architectures and layer positions.
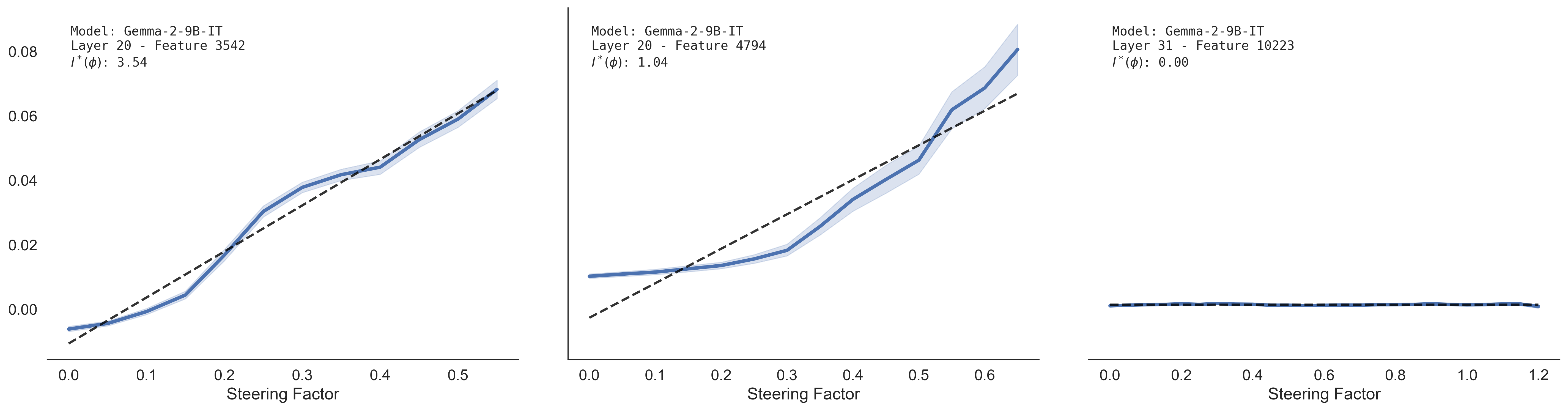
Figure 2: Concept intensity profiles illustrating feature effectiveness for steering—high, medium, and low candidates—based on the response slope and saturation with increasing interventions.
Steering is implemented via adaptive scaling: for selected SAE features, LLM activations are modified by an additive steering factor proportional to the L2 norm of the residual stream, maintaining contextual magnitude and preserving model fluency. This approach facilitates granular interventions and quasi-counterfactual text generation even across varied contexts and datasets.
Quantitative Evaluation of Steering and Treatment Isolation
Candidate features are evaluated post-intervention for robustness: features with low IC scores exhibit inconsistent intensity response, fail to generate coherent text, or introduce correlated confounders. In contrast, features with high, linear intensity profiles allow multi-valued treatments, mitigate off-target effects, and ease downstream causal estimation. Coherence is assessed using an LLM-as-judge protocol, ensuring that generated texts are structurally valid without confounding the evaluation by tone or sentiment.
Residualization: Addressing Bias and Positivity Violations
Textual treatments are inherently entangled in high-dimensional embeddings—naïve controls via powerful text embeddings violate the positivity assumption, fully predicting treatment assignment and resulting in degenerate propensity scores. The paper rigorously characterizes this bias and develops control strategies based on theoretical bounds: controlling for nuisance features orthogonal to treatment ensures identification, but only if embeddings are appropriately residualized.
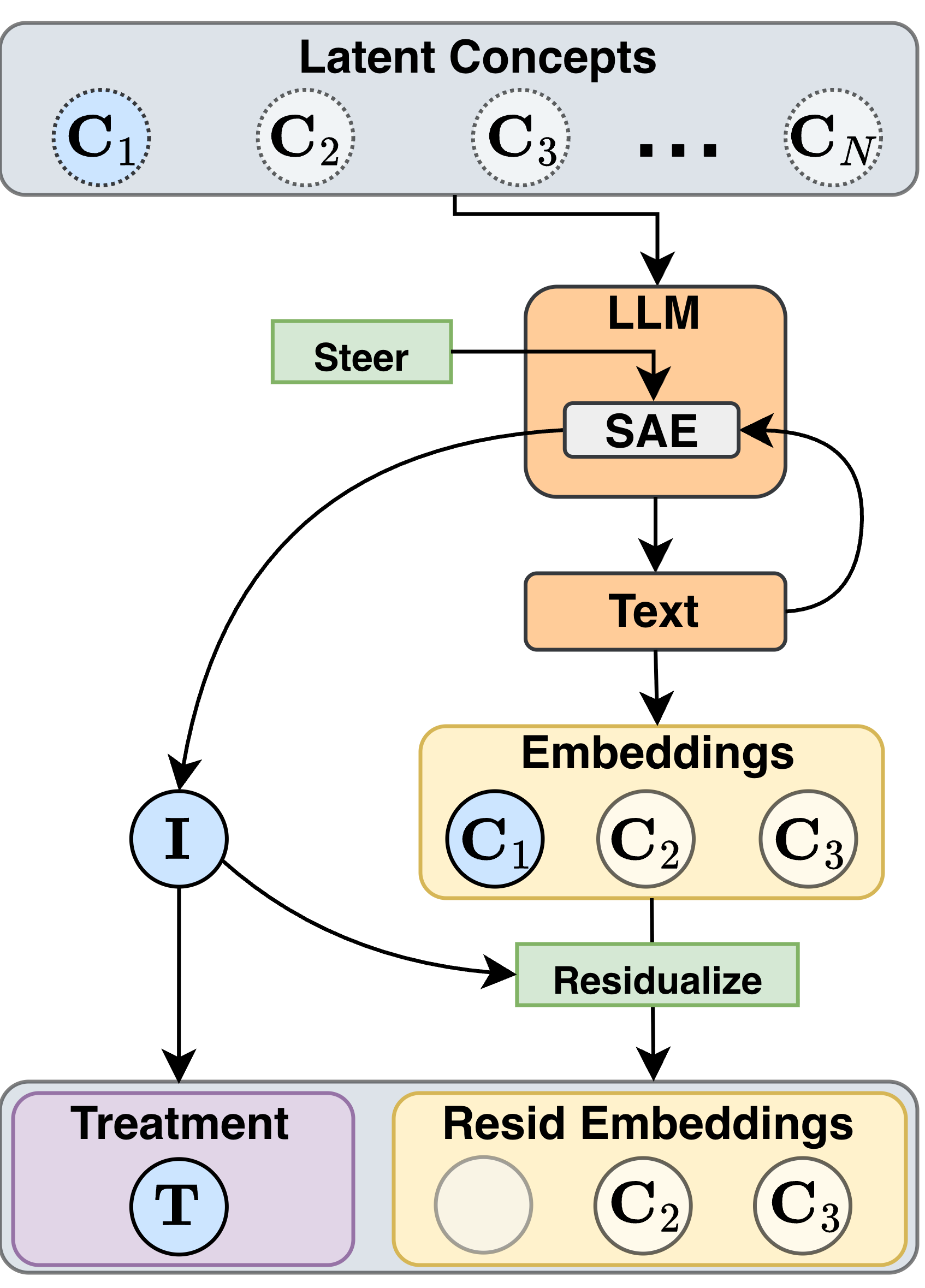
Figure 3: Residualization pipeline emphasizing separation of treatment intensity from contextual embedding controls for valid downstream CATE estimation.
Two residualization techniques are introduced:
- Dimension-by-Dimension Residualization: Each embedding dimension is orthogonalized to treatment via out-of-fold predictions and subtraction, removing direct treatment information.
- Principal Component Drop: The dominant axis of treatment-related variance is removed by dropping the first principal component.
Empirical analysis demonstrates that treatment information is highly concentrated in the first principal component when steering is effective, and the dimension-by-dimension strategy yields substantial bias reduction across features and architectures.
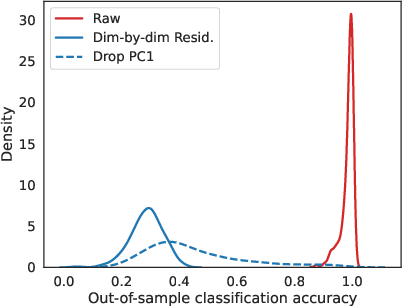
Figure 4: Distributions of treatment predictive accuracy for raw vs. residualized embeddings, showing effective reduction of treatment predictability post-residualization.
Robust Causal Estimation via Machine Learning
The ex-post causal estimation leverages robust causal ML techniques, specifically the R-learner framework for CATEs, cross-fitting nuisance functions, and regularized regression. The theoretical results provide bounds on estimation bias (∣τ(x~)−τ~(x~)∣≤2Lδ) under limited sensitivity and residual treatment variation, confirming the efficacy of residualized embeddings for valid causal identification.
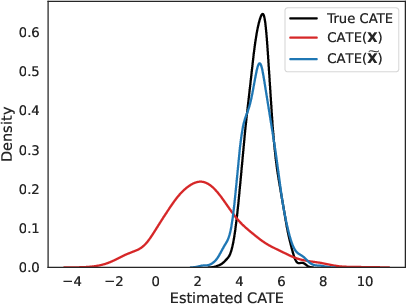
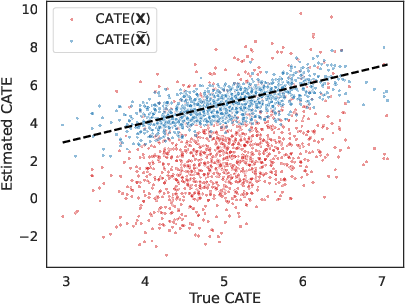
Figure 5: Simulated CATE distributions showing alignment of estimated effects (blue) with ground truth using residualization; raw controls (red) exhibit large bias.
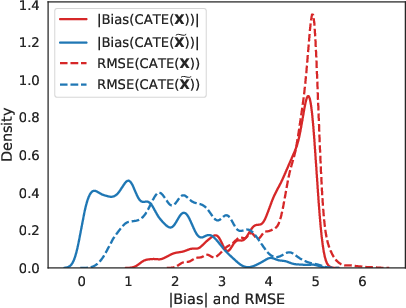
Figure 6: Distribution of bias and RMSE across DGP specifications for raw and residualized covariates; residualization yields substantial bias and RMSE reduction.
Empirical Validation and Robustness
Three labeled datasets—Local Government Speech, Political Ads, and Us Vs. Them—are used for semi-synthetic simulations. SAE features with high IC scores produce steered text with reliable treatment separation; coherence filtering eliminates degraded samples; robust causal estimation with residualization systematically reduces bias and RMSE compared to raw controls, as demonstrated through large-scale aggregation across LLMs, embedding models, and datasets. The hierarchical evaluation confirms the generalizability and stability of the pipeline.
Practical and Theoretical Implications
This methodology advances causal experimentation in text-as-treatment settings by enabling controlled latent interventions and resolving longstanding identification issues. Practically, it allows for rigorous downstream studies in social sciences, marketing, or political communication, facilitating hypothesis-driven experiments with quasi-counterfactual generations. Theoretically, it contributes novel residualization-based identification strategies—extensible to other modalities—anchored by provable guarantees.
Future Directions
Extending the pipeline to multi-modal data, fine-grained continuous treatments, and compositional interventions is a promising avenue. Further, optimizing residualization for non-linear embeddings and improving steering reliability across LLM architectures can enhance generalizability. Benchmarking against other concept erasure and causal representation learning frameworks (e.g., (Imai et al., 2024, Fan et al., 1 Jul 2025)) will contextualize efficacy and inspire refinement.
Conclusion
This paper addresses fundamental challenges in causal inference with text, introducing a rigorous SAE-based pipeline for feature hypothesis generation, controlled steering for quasi-counterfactuals, and robust causal estimation via residualized nuisance embeddings. The approach is theoretically sound, empirically validated, and widely applicable, establishing a new standard for experimentation with latent textual treatments (2602.15730).