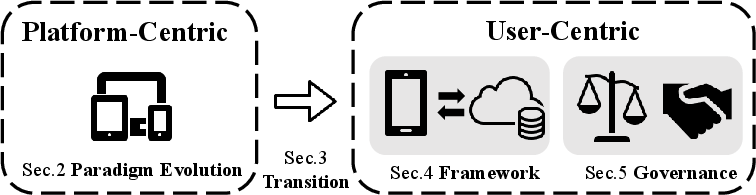
The Next Paradigm Is User-Centric Agent, Not Platform-Centric Service
Abstract: Modern digital services have evolved into indispensable tools, driving the present large-scale information systems. Yet, the prevailing platform-centric model, where services are optimized for platform-driven metrics such as engagement and conversion, often fails to align with users' true needs. While platform technologies have advanced significantly-especially with the integration of LLMs-we argue that improvements in platform service quality do not necessarily translate to genuine user benefit. Instead, platform-centric services prioritize provider objectives over user welfare, resulting in conflicts against user interests. This paper argues that the future of digital services should shift from a platform-centric to a user-centric agent. These user-centric agents prioritize privacy, align with user-defined goals, and grant users control over their preferences and actions. With advancements in LLMs and on-device intelligence, the realization of this vision is now feasible. This paper explores the opportunities and challenges in transitioning to user-centric intelligence, presents a practical device-cloud pipeline for its implementation, and discusses the necessary governance and ecosystem structures for its adoption.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
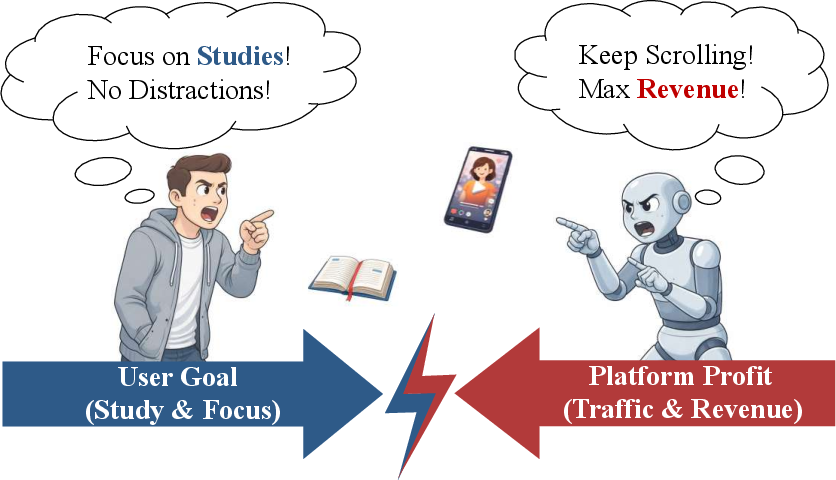
This paper argues that the way many apps and websites work today puts the company’s goals first, not the user’s. Most platforms try to keep you clicking, watching, or buying because that helps their business. The authors say it’s time to flip this around: build “user‑centric agents”—smart assistants that live with you (for example, on your phone), protect your privacy, understand your goals, and act on your behalf across different apps and services.
They explain why this shift matters, how new AI and on-device technology make it possible, how to build it in practice, and what rules and agreements are needed so everyone plays fair.
What questions does the paper try to answer?
The paper focuses on three simple questions:
- Do better platform features really help users, or do they mostly help the platform?
- What would a truly user‑first assistant look like, and how could it work across many apps and services?
- What technology, rules, and partnerships are needed so user‑centric agents can work safely, privately, and at scale?
How did the authors approach it?
This is a “position paper,” which means the authors build a clear argument and a design plan instead of running lab experiments. They do four main things:
- They analyze today’s platform‑centric world
- Today’s services watch what you do inside one app, predict the next thing you’ll click, and optimize for “platform metrics” like clicks, time spent, and purchases.
- Even though the tech has gotten stronger—especially with LLMs—the main goal is still engagement, not your long‑term benefit.
- They identify three big problems with platform‑centric services, using everyday ideas:
- Fragmented context: Each app only sees a slice of your life. It’s like five friends giving you advice without talking to each other—they miss the full picture.
- Limited execution: A single app can’t finish multi-step tasks across other apps (like planning travel, changing subscriptions, or rebooking flights end-to-end).
- Misaligned incentives: Platforms are rewarded when you stay longer, not necessarily when you finish your task quickly and well.
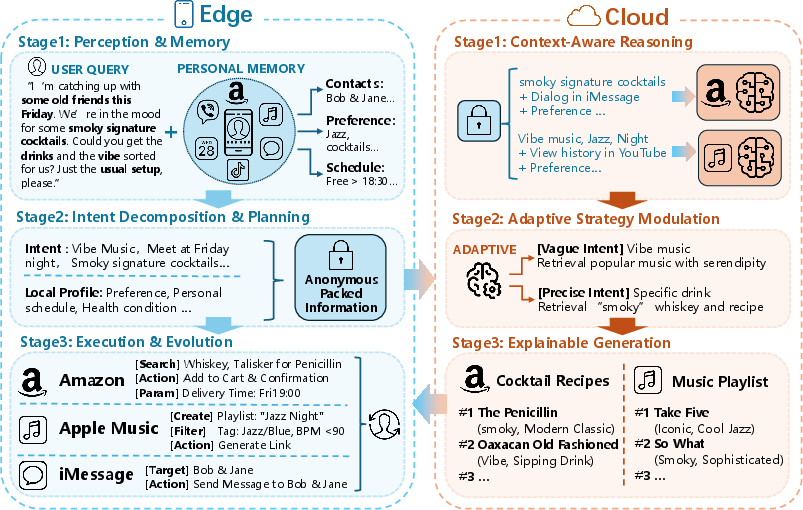
- They propose a practical “edge–cloud” design for user‑centric agents Think of it as teamwork between your device and the internet:
- On-device (the “edge”): Your personal agent runs on your phone or laptop, where your private info stays. It understands your needs, follows your rules, and makes final decisions.
- In the cloud: Online services provide big catalogs (like flights, drivers, items) and tools (like booking or payment). They respond to your agent’s requests with options and explanations, but they don’t see your whole private life.
They describe the on-device agent as a simple sense–think–act loop:
- Perception and memory: The agent notices what you’re doing (time, calendar, notifications) and remembers your preferences. It compresses this into a small, useful “state” so it doesn’t waste storage or leak data.
- Planning: It turns your goal into steps, checks your constraints (budget, time, privacy), and decides what it must ask the cloud for. If the goal is unclear, it asks you quick questions.
- Execution and learning: It gets options from the cloud, checks them against your rules, asks for your OK on sensitive actions, then executes. Afterwards, it learns from what happened to do better next time—without uploading your private details.
They also explain how the cloud should evolve:
- Reason with context: Understand the request and constraints your device sends (not your raw data).
- Adapt strategies: Be precise for urgent tasks; explore more for discovery tasks—always aligned with your current goal.
- Be explainable: Return options with clear reasons and machine-readable tags so your device can verify them locally.
- They discuss governance and ecosystem rules
- Who provides the agent? If one company controls it, we might just get a new “gatekeeper.” The agent must be user-governed: you can inspect preferences, set limits, and switch providers without losing your personal memory.
- How do agents and platforms work together? Platforms own inventories (drivers, flights, items). Agents bring qualified intent (clear goals). The paper proposes a trade: Authority for Intent. Platforms offer standardized, reliable APIs; agents send structured requests with only the minimum info needed. There should be standards for formats, auditing, and fair revenue sharing—so cooperation is sustainable and privacy is protected.
What are the main takeaways and why do they matter?
Here are the core conclusions:
- Smarter platforms ≠ better for users by default. If a system is rewarded for keeping you engaged, making it smarter only makes it better at that—sometimes at the cost of your goals.
- A user‑centric agent solves three structural problems:
- It builds a full picture by using your device’s context privately, instead of piecing together scattered app logs.
- It focuses on finishing your intent (what you want done), not just showing you the next click.
- It aligns decisions with your rules and goals, not the platform’s profit targets.
- Why now? Two trends make this real:
- LLMs can understand natural language and follow instructions, not just match IDs or clicks.
- On-device AI is fast and compact enough to run on phones and laptops, keeping sensitive info local.
- A practical blueprint exists: a device-first agent that reasons locally and uses the cloud for inventories and tools—always with transparent, verifiable options.
- Technology alone isn’t enough. Clear rules, standards, and fair economics are needed so the agent stays user‑first and platforms still have reasons to participate.
What could this change?
If this vision is adopted:
- Everyday tasks could get simpler and safer. Your agent could plan a trip across multiple apps, schedule around your calendar, respect your budget, ask for approval on payments, and finish the whole job—without spamming you or selling your attention.
- You gain more control and privacy. Your preferences and constraints live with you. The agent shares only what’s needed to complete a task.
- Platforms may shift from chasing clicks to delivering verified results, because the agent cares about your outcomes, not engagement time.
- New standards will likely appear: common intent formats, APIs for safe execution, ways to audit actions, and methods to share value fairly.
There are challenges: building trust, agreeing on standards, making the economics work for everyone, and ensuring the agent never becomes a new gatekeeper. But the payoff is a digital world that works more like a loyal assistant than a set of apps fighting for your attention.
In short
The paper’s message is simple: The future should be about your goals, your privacy, and your control. With modern AI and on-device computing, a user‑centric agent is now possible. It needs careful engineering and honest rules—but if done right, it can turn the internet from a place that keeps you scrolling into a partner that helps you get things done.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the key gaps and unresolved issues that future research should address to make the proposed user-centric agent paradigm actionable.
- Formalizing “user utility”: precise definitions, measurement frameworks, and benchmarks that capture both short-term satisfaction and long-term welfare, including trade-off policies when goals conflict.
- Empirical validation: controlled studies comparing user-centric agents to platform-centric services on real tasks (beyond engagement/CTR), with outcome metrics (task completion, cost, time, satisfaction, privacy risk).
- Cross-app, end-to-end benchmarks: publicly available, privacy-preserving datasets and task suites for multi-step, multi-service intents (e.g., travel rebooking, refunds, scheduling), with standardized evaluation protocols.
- Device–cloud pipeline specifics: concrete protocols for request/response schemas, latency budgets, caching, retries, offline/degraded modes, and failover strategies when cloud endpoints are unavailable or untrustworthy.
- Privacy threat models and guarantees: formal analysis of adversaries (malicious apps, OS-level compromises, cloud leakage), and enforceable privacy techniques (local differential privacy, secure enclaves, confidential computing).
- Verifiable compliance: cryptographic and logging mechanisms to prove constraints were applied (e.g., signed constraint tags, audit trails, zero-knowledge proofs), including feasibility and performance overhead.
- Standardized intent/constraint schemas: domain coverage, versioning, extensibility, backward compatibility, and who governs these standards to avoid fragmentation or vendor capture.
- Economic settlement and attribution: concrete revenue-sharing models, attribution measurement for conversions via agents, fraud prevention, and dispute resolution for multi-party workflows.
- Tool orchestration reliability: policies for handling tool errors/timeouts, partial observability, transactional integrity across steps (e.g., reservation+payment+cancel), and compensating actions.
- Runtime safety and policy enforcement: a policy language for user constraints (syntax, semantics), static/dynamic checks, formal verification where applicable, emergency stops, and consent UX for sensitive actions.
- Memory architecture design: algorithms for consolidation, forgetting, summarization, bias control, privacy-preserving storage, and a portable memory format enabling vendor switching without state loss.
- Preference/policy learning: methods to infer and update user constraints/preferences (active elicitation vs passive observation), resolve rule conflicts, and avoid manipulative shaping of preferences.
- Multi-user scenarios: handling shared devices, household/team intents, identity separation, group preference aggregation, and conflict resolution among stakeholders.
- Scalability on diverse devices: model sizes, quantization strategies, scheduling, energy/battery impact, and guarantees for acceptable performance on low-end hardware.
- On-device security: permission models, sandboxing, secure inter-app access, secure storage/key management, and defenses against malicious apps or OS-level adversaries.
- Governance mechanisms to prevent new gatekeeping: concrete portability requirements, open interoperability standards, certification schemes, and separation of the user decision layer from vendor commercial objectives.
- Platform incentives to expose intent-level APIs: migration paths, cost/benefit analyses, pilot program designs, and the role of regulation vs market mechanisms in making cooperation viable.
- Regulatory compliance: GDPR/CPRA alignment (consent, data minimization, right to explanation), data localization, audit obligations, and cross-jurisdictional compatibility.
- Fairness, bias, and accessibility: ensuring equitable outcomes across demographics, preventing discriminatory constraint handling, and designing accessible UX for diverse user needs and abilities.
- Explainability and rationale quality: structured, machine-verifiable metadata schemas; evaluation methods for correctness vs hallucination in justifications; and alignment between rationales and actual actions.
- Conflict handling with platform policies: procedures when user constraints contradict service terms or legal requirements, including escalation, alternatives, and transparent user communication.
- Adversarial robustness: defenses against providers manipulating agent rankings (dark patterns, adversarial content), adversarial testing suites, and monitoring for systematic bias or gaming.
- Model update process: strategies for on-device/federated learning that avoid privacy leakage, manage catastrophic forgetting, and schedule updates safely without degrading user experience.
- Comparative studies of paradigms: rigorous, scenario-based comparisons among system-level, service-level, user-centric, and hybrid approaches to identify conditions under which each is superior.
- Cold-start onboarding: practical methods to initialize memory and preferences with minimal user burden while preserving autonomy and avoiding prescriptive defaults.
- Cost and budgeting: transparent pricing models for cloud calls, enforcing user-defined budget constraints, and strategies to minimize operational costs without degrading utility.
- Offline and degraded operation: capability boundaries when network/cloud access is limited, fallback planning, local-only alternatives, and user notification policies.
- Reversibility and dispute resolution: standard APIs and protocols for verifying actions, cancellations, refunds, and handling disputes across heterogeneous providers.
- Long-term welfare optimization: methods to balance immediate gratification against long-term goals (e.g., health, finance), avoiding paternalism and giving users fine-grained control over such trade-offs.
- Environmental impact: measurement and optimization of energy use for widespread on-device inference, including scheduling and model compression impacts on sustainability.
- Interoperability with OS/app store policies: handling policy conflicts (anti-steering, API access limits), vendor acceptance criteria, and strategies to avoid ecosystem lockout or fragmentation.
- Data mixture for user-centric adaptation: principled approaches to blend general LLM capabilities with private on-device context without leakage, including safe co-training and catastrophic forgetting mitigation.
Practical Applications
Practical Applications Derived from the Paper
Below are actionable, real-world applications that stem directly from the paper’s findings and proposed device–cloud pipeline (on-device perception–planning–execution paired with cloud-side context-aware reasoning and explainable, constraint-tagged responses), together with its governance and ecosystem contracts (authority-for-intent exchange, standardized schemas, auditability).
Immediate Applications
These can be prototyped or deployed with current LLMs, existing APIs, and on-device intelligence.
- Bold attention management and notification triage
- What: Personal agent performs on-device triage of alerts, notifications, and interruptions using local context (calendar, focus state, location, current app) and user rules.
- Sectors: Mobile OS, productivity, healthcare (reducing alert fatigue).
- Tools/products/workflows: On-device LLM, OS-level instrumentation (Android Intents, iOS Intents/Focus modes), local “policy DSL” for constraints (quiet hours, urgency thresholds).
- Assumptions/dependencies: OS permissions for cross-app signals, compact on-device models, user-consent UI.
- Client-side re-ranking and filtering of platform results
- What: Agent re-ranks search, recommendations, and offers locally to optimize for user-defined utility (budget, time, sustainability), applying “minimal disclosure” by default.
- Sectors: E-commerce, media/streaming, travel, finance.
- Tools/products/workflows: Browser extensions/app SDKs for re-ranking; local preference models; “explainable generation” metadata from platforms (price, constraints, provenance).
- Assumptions/dependencies: Platforms expose enough structured metadata; client-side re-ranking allowed by app/browser policies.
- Cross-service task orchestration using existing APIs
- What: End-to-end services (e.g., rebooking travel; meeting coordination; subscription/bill optimization; returns/refunds) planned on-device, executed via cloud-accessible APIs.
- Sectors: Travel, calendar/productivity, fintech, e-commerce, customer support.
- Tools/products/workflows: OAuth-based connectors (Gmail/Calendar, airlines, rideshare, banks), Zapier/IFTTT-like adapters; on-device planning with runtime checks; “dry-run” confirmation for irreversible actions.
- Assumptions/dependencies: API availability and rate limits; token management; user approvals; idempotent endpoints.
- Enterprise privacy-preserving copilots
- What: Employee assistants that coordinate across SaaS (tickets, CRM, docs) with local policies (PII handling, data residency); on-device or VDI-local reasoning; cloud-only for public inventories.
- Sectors: Enterprise software, IT/security, customer support.
- Tools/products/workflows: EMM/MDM integration, SCIM/OIDC identity; local memory vault; runtime action firewall with approval gates.
- Assumptions/dependencies: Admin policies and logging, access controls, security reviews.
- Runtime action guardrails and execution firewalls
- What: Enforce user-defined constraints (budgets, confirmation for payments, calendar feasibility) before execution; require structured rationales to be verified on-device.
- Sectors: Security, compliance, fintech, healthcare.
- Tools/products/workflows: Rule engines, “agent spec” policies, action simulators; structured rationale formats (JSON with constraint tags).
- Assumptions/dependencies: Clear policy surfaces; reliable action simulation/dry-run capability; auditable logs.
- “Agent-ready” APIs for platforms
- What: Platforms expose standardized, intent-level endpoints with machine-verifiable metadata (price, availability, constraints satisfied) and explanations.
- Sectors: Travel, commerce, media, utilities, government services.
- Tools/products/workflows: JSON schemas for intents/constraints; attribution fields; SLA for determinism and idempotency; sandbox test suites.
- Assumptions/dependencies: Low-lift adapters around existing services; legal review for new disclosures; developer documentation.
- Research benchmarks and evaluation for user utility
- What: Academic benchmarks for device–cloud agent loops (latency, privacy leakage, constraint satisfaction, end-to-end task completion); memory consolidation and runtime enforcement studies.
- Sectors: Academia, ML systems, HCI.
- Tools/products/workflows: Synthetic/private datasets; reproducible device–cloud scaffolds; user studies; new metrics beyond engagement (utility, regret, override rate).
- Assumptions/dependencies: IRB approvals; standardized schemas; open baselines.
- Policy and procurement pilots for minimal disclosure and portability
- What: Pilot guidelines that prefer on-device reasoning; mandate data minimization, consent granularity, and user state portability between agents/providers.
- Sectors: Public sector, regulators, standards bodies.
- Tools/products/workflows: Model governance profiles; portability specs; conformance testing.
- Assumptions/dependencies: Political will; alignment with GDPR/CCPA, open banking/open data frameworks.
- Everyday “agent-as-concierge” setups with current tooling
- What: Budget-aware shopping helper; calendar-conscious media diet; focus-mode gating of apps; travel day-of logistics planning.
- Sectors: Consumer apps, personal finance, lifestyle.
- Tools/products/workflows: Shortcuts/Android Automations + local LLM; API keys for common services; lightweight local memory of preferences.
- Assumptions/dependencies: User setup effort; API/auth management; transparent fail-safes.
Long-Term Applications
These require further research, scaling, standardization, ecosystem incentives, and/or legal frameworks.
- User-governed “Agent OS” with portable memory vaults
- What: A sovereign personal agent that users can switch across providers without losing memory/state; clear, enforceable override controls.
- Sectors: OS vendors, consumer software, identity.
- Tools/products/workflows: Agent profile and memory portability standards; end-to-end encryption; secure enclaves/TEE; interoperability tests.
- Assumptions/dependencies: Cross-vendor standardization; robust on-device models; user trust UX.
- Standardized intent/constraint schemas and verifiable compliance
- What: Ecosystem-wide schemas for intents and constraints; cryptographic attestations and zero-knowledge proofs that providers satisfied constraints without learning private details.
- Sectors: Standards, fintech, healthcare, travel, gov.
- Tools/products/workflows: Schema registries; ZK proof libraries; compliance attestations; audit trails.
- Assumptions/dependencies: Industry coordination; performance-acceptable crypto; legal acceptance of cryptographic evidence.
- Economic settlement and attribution between agents and platforms
- What: Protocols to share value when agents route high-intent traffic; privacy-preserving conversion attribution; “authority-for-intent” contracts.
- Sectors: Ads/commerce, marketplaces, payments.
- Tools/products/workflows: Privacy-preserving attribution (aggregated or ZK-based); standardized receipts of constraint satisfaction; revenue-share clearinghouses.
- Assumptions/dependencies: Bilateral/multilateral agreements; competition law considerations; fraud prevention.
- On-device continual learning and federated personalization
- What: Safe, local model updates from user outcomes; periodic federated optimization without exporting raw context.
- Sectors: Mobile, edge AI, enterprise IT.
- Tools/products/workflows: Federated learning frameworks; differential privacy; drift detection; rollback-safe updates.
- Assumptions/dependencies: Efficient training on-device; robust safety evaluation; energy/latency budgets.
- Healthcare personal care agent
- What: Agent coordinates appointments, medications, prior authorizations, and insurance constraints; respects clinical policies and privacy.
- Sectors: Healthcare, insurance.
- Tools/products/workflows: FHIR-based APIs; payer portals; medication knowledge bases; runtime medical safety constraints.
- Assumptions/dependencies: API access to EHRs/insurers; clinician-in-the-loop; HIPAA/GDPR compliance; liability frameworks.
- Finance copilot under guardrails
- What: Executes bill payment, savings, and portfolio rebalancing according to user policies and risk thresholds; produces auditable, explainable decisions.
- Sectors: Banking, wealth management, payments.
- Tools/products/workflows: Open banking APIs; broker APIs; policy DSLs for risk; explainability reports; staged approvals.
- Assumptions/dependencies: Regulatory authorization; capital and fraud controls; kill-switches and limits.
- Smart home and energy optimization agent
- What: Orchestrates devices and tariffs to minimize cost/carbon under comfort/safety constraints; schedules EV charging and appliances.
- Sectors: Energy, IoT, utilities.
- Tools/products/workflows: Matter/Thread/HomeKit integrations; utility rate APIs; local safety interlocks; outage handling.
- Assumptions/dependencies: Device interoperability; robust local control; safety certification.
- Education learning coach
- What: Multi-platform study planner that sequences content across apps; enforces focus and aligns to curricular goals and deadlines.
- Sectors: EdTech, K–12, higher ed.
- Tools/products/workflows: LMS/LTI integrations; progress-tracking schemas; parental/teacher guardrails; content rationales.
- Assumptions/dependencies: School/parent adoption; data-sharing agreements; cheating/ethics safeguards.
- Robotics and embodied execution via agent orchestration
- What: The agent plans and delegates tasks to home/service robots under household policies and safety rules; reconciles digital and physical execution.
- Sectors: Robotics, smart home, logistics.
- Tools/products/workflows: ROS2, Home OS connectors; execution firewall for physical actions; perception–planning feedback loops.
- Assumptions/dependencies: Reliable APIs and sensors; safety and liability regimes; fail-safe designs.
- Legal frameworks for agent fiduciary duty and certification
- What: Statutes defining agent fiduciary obligations to users, liability allocation, certification and audit of agent providers.
- Sectors: Policy, consumer protection, standards.
- Tools/products/workflows: Certification programs; transparency reports; red-teaming standards; incident reporting.
- Assumptions/dependencies: Legislative processes; international harmonization; enforcement capability.
- Marketplace of explainable agent services
- What: Cloud-side “agent services” that respond to structured intent with constraint-tagged, explainable candidates; discoverable via registries.
- Sectors: SaaS, travel/commerce/media platforms.
- Tools/products/workflows: Service registries; SLA-backed explainability; conformance tests; versioned schemas.
- Assumptions/dependencies: Network effects; fair access rules; anti-steering commitments.
- Cross-platform identity, consent, and provenance
- What: Standard, user-facing consent and provenance infrastructure for when and how private context is summarized and shared; immutable logs for dispute resolution.
- Sectors: Identity, privacy tech, compliance.
- Tools/products/workflows: User consent wallets; signed data receipts; provenance chains; revocation and expiry controls.
- Assumptions/dependencies: Interoperable identity standards; public-key infrastructure; UX that avoids consent fatigue.
These applications, taken together, operationalize the paper’s core contributions: moving from platform-centric optimization to user-centric utility; anchoring reasoning and control on-device; relegating cloud providers to explainable, verifiable service endpoints; and establishing governance contracts (schemas, auditability, settlement) that make a user-first ecosystem economically sustainable.
Glossary
- Adaptive computation: Techniques that dynamically adjust inference compute based on workload or input complexity to improve efficiency. "resource efficiency is maximized through adaptive computation"
- Agent safety: Methods and frameworks that ensure an AI agent’s actions adhere to user-defined safety rules and constraints. "agent safety and runtime enforcement frameworks"
- Agentic service layer: A cloud layer designed to assist on-device agents by providing tools, inventories, and structured responses rather than engagement-optimized rankings. "the cloud must evolve from a passive ranking endpoint to an agentic service layer"
- Autoregressive sequence generation: A decoding approach that generates each token conditioned on previously generated tokens. "autoregressive sequence generation"
- Beam search: A heuristic search algorithm that keeps multiple top candidate sequences at each decoding step to improve generation quality. "beam search"
- Cascade routing: A strategy that routes requests through progressively more capable (and expensive) models only when needed. "cascade routing"
- Catastrophic forgetting: Degradation of previously learned capabilities when fine-tuning on new task data. "catastrophic forgetting"
- Chain-of-Thought supervision: Training signals that include explicit step-by-step reasoning to teach models to reason. "Chain-of-Thought supervision"
- Cold-start: The difficulty of recommending or modeling new users/items with little or no historical data. "cold-start"
- Conflict-aware mixture: Data mixing strategies that adjust domain weights based on training signals to avoid performance conflicts across domains. "conflict-aware mixture strategies"
- Context-Aware Reasoning: Reasoning that incorporates compact task goals, preferences, and constraints to maintain coherent multi-turn state. "Context-Aware Reasoning"
- Data distillation: Creating compact summaries or synthetic datasets that preserve performance while reducing training cost. "data distillation"
- Deliberative planning frameworks: Planning methods that explore multiple reasoning trajectories and evaluate alternative plans under constraints. "deliberative planning frameworks"
- Device-cloud pipeline: An architecture where a user-controlled on-device agent reasons and decides, while the cloud provides external inventories and tools. "device-cloud pipeline"
- Distribution matching: Generative techniques that synthesize data by matching the distribution of target datasets. "distribution matching"
- Discrete diffusion models: Generative models that iteratively refine discrete tokens via a diffusion process to sample from complex distributions. "discrete diffusion models"
- Dynamic sparsity: Mechanisms that reduce computation by dropping tokens or operations during inference in a data-dependent way. "dynamic sparsity"
- Episodic traces: Short-term memory records of recent outcomes that inform future decisions. "episodic traces"
- Fiduciary: An agent role that prioritizes the user’s interests and utility over platform objectives. "fiduciary"
- Flow matching networks: Generative models that learn transport maps between distributions to enable efficient sampling. "flow matching networks"
- Foundation models: Large pretrained models with broad knowledge and generalization capabilities across tasks. "foundation models"
- Graph constraints: Structured constraints applied during decoding to ensure generated outputs meet validity rules. "graph constraints"
- Hierarchical indexing: Multi-level item indexing structures used to alleviate semantic sparsity or cold-start issues. "hierarchical indexing"
- Influence Functions: Techniques for estimating how individual training samples affect model parameters and performance. "Influence Functions"
- Intent-level APIs: Standardized interfaces that accept structured intents and constraints to execute actions across platforms. "intent-level APIs"
- Item Tokenization: Encoding items as sequences of discrete tokens (often using metadata) to replace large embedding tables. "Item Tokenization"
- KV cache compression: Techniques to reduce memory footprint by compressing key-value caches during generation. "KV cache compression"
- LLM-as-Rec: A paradigm that uses LLMs to perform recommendation via intent-level reasoning over semantic context. "LLM-as-Rec"
- Minimax objective: An optimization objective that balances domain performance by minimizing worst-case loss across domains. "minimax objective"
- Mixed-precision quantization: Quantizing model weights/activations to different precisions to save memory and compute while preserving quality. "mixed-precision quantization"
- Modality Alignment: Methods to bridge differences between collaborative signals and natural-language representations. "Modality Alignment"
- Model distillation: Transferring knowledge from a large teacher model to a smaller student to reduce latency and cost. "model distillation"
- Multi-Objective Alignment: Training models to simultaneously optimize for multiple goals (e.g., accuracy, diversity, novelty). "Multi-Objective Alignment"
- Non-autoregressive mechanisms: Decoding approaches that predict multiple tokens simultaneously without strict left-to-right dependency. "non-autoregressive mechanisms"
- On-device intelligence: Running compact, high-performance models locally on user hardware to preserve privacy and reduce latency. "on-device intelligence"
- Open-ended instruction following: A generation paradigm focused on following user instructions with explicit logic rather than implicit matching. "open-ended instruction following"
- OS-level instrumentation: Operating system hooks that capture cross-app activity and device context for the on-device agent. "OS-level instrumentation"
- Partial observability: Situations where the agent operates with incomplete information about the environment or task. "partial observability"
- Perplexity: A measure of uncertainty in LLMs, often used to assess sample quality or filtering. "perplexity-based heuristics"
- Prefill Optimization: Techniques that reduce first-token latency by compressing or sparsifying inputs before decoding. "Prefill Optimization"
- Prefix trees: Tree data structures used to constrain generation by locking valid identifier branches step-wise. "prefix trees"
- RL-based post-training: Reinforcement learning procedures applied after pretraining to enhance reasoning or alignment. "RL-based post-training"
- Scaling laws: Empirical relationships linking model/data scale to downstream performance. "scaling laws"
- Search space pruning: Restricting the set of valid outputs during decoding to ensure identifier validity and reduce latency. "search space pruning paradigms"
- Semantic bridge: A mechanism (e.g., tokenizers) that connects collaborative signals to textual modality. "semantic bridge"
- Semantic compression: Reducing input length by pruning redundant context or aggregating behavior segments. "semantic compression"
- Semantic grounding: Training that ties implicit behaviors to explicit meanings or reasoning so models understand intent. "semantic grounding"
- Semantic tokens: Tokens representing item semantics that enable open, transferable modeling across platforms. "universal semantic tokens"
- Shapley values: Cooperative game-theoretic attribution used to estimate marginal utility of data subsets. "Shapley values"
- Speculative decoding: A fast decoding method that verifies multiple drafted tokens using auxiliary models in parallel. "speculative and parallel decoding"
- State-Space Models (SSMs): Sequence models that replace Transformers with state-space formulations for efficiency. "State-Space Models (SSMs)"
- Test-time scaling: Increasing inference-time compute or techniques to improve generation quality. "test-time scaling"
- Two-sided market: A market structure where the agent mediates value exchange between users and platforms with shared rules. "two-sided market"
- Walled garden effect: A closed platform ecosystem that traps user attention and restricts cross-service workflows. "“walled garden” effect"
Collections
Sign up for free to add this paper to one or more collections.

