- The paper introduces a six-level taxonomy for data agents inspired by SAE J3016, clarifying transitions from manual operations to full autonomy.
- It identifies the L2-to-L3 transition as a critical challenge, emphasizing the need for breakthroughs in strategic reasoning and dynamic tool evolution.
- The study outlines practical implications for risk mitigation, regulatory compliance, and the deployment of advanced data agents in real-world applications.
A Hierarchical Taxonomy and Critical Analysis of Data Agents
The paper "A Survey of Data Agents: Emerging Paradigm or Overstated Hype?" (2510.23587) presents a comprehensive and systematic taxonomy for data agents, addressing the terminological ambiguity and inconsistent adoption that currently pervades both academic and industrial discourse. By introducing a six-level hierarchy inspired by the SAE J3016 standard for driving automation, the authors delineate progressive shifts in autonomy, responsibility, and capability boundaries for data agents, ranging from manual operations (L0) to fully autonomous, generative systems (L5). This essay provides a technical summary and critical analysis of the taxonomy, the evolutionary leaps between levels, the current state-of-the-art, and the implications for future research and deployment.
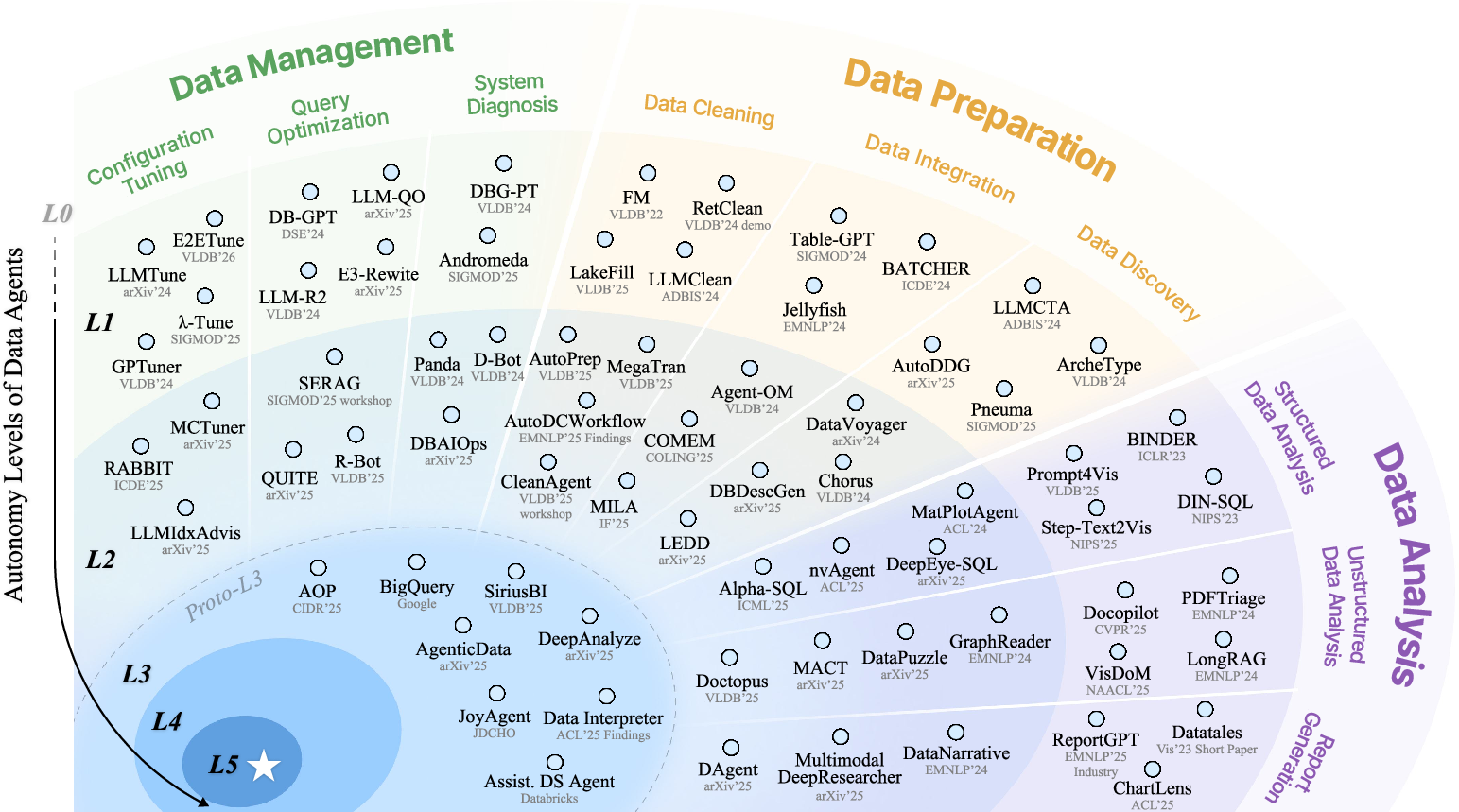
Figure 1: Representative Data Agents Across Different Levels.
Hierarchical Taxonomy: L0–L5 Levels of Data Agent Autonomy
The taxonomy defines six levels of autonomy:
- L0 (Manual): No agent involvement; all data tasks are human-driven.
- L1 (Assistance): Stateless, prompt-response agents that provide atomic assistance (e.g., code snippets, advice) but lack environmental perception.
- L2 (Partial Autonomy): Agents gain environmental perception and tool invocation, executing task-specific procedures within human-orchestrated pipelines.
- L3 (Conditional Autonomy): Agents autonomously orchestrate and optimize pipelines for diverse, comprehensive data tasks under human supervision.
- L4 (High Autonomy): Agents proactively discover and address tasks, achieving self-governance without human supervision.
- L5 (Full Autonomy): Agents invent novel solutions and paradigms, functioning as expert data scientists with generative capabilities.
This taxonomy clarifies capability boundaries and responsibility allocation, mitigating risks of expectation mismatch, accountability ambiguity, and industry stagnation.
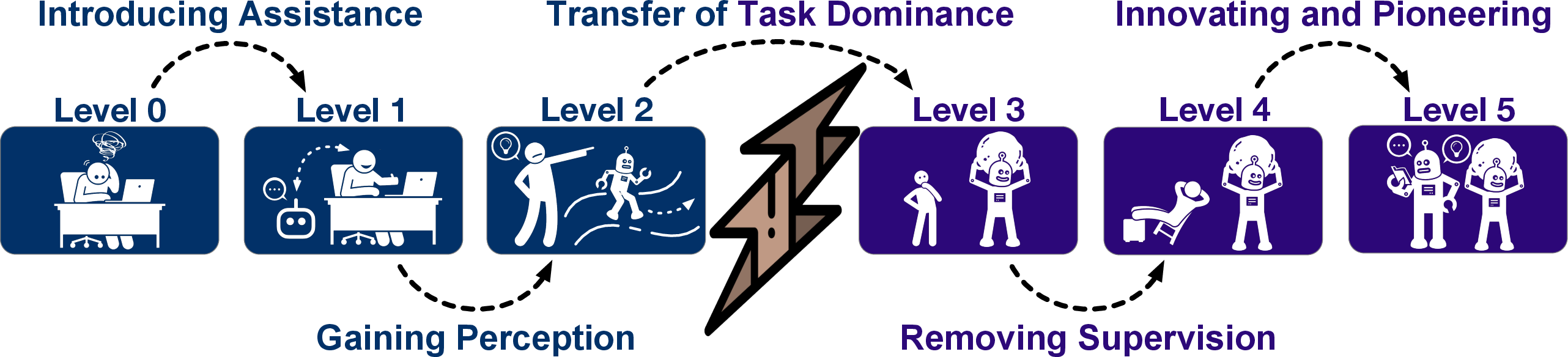
Figure 2: Evolutionary Leaps Between Data Agent Levels.
Evolutionary Leaps and Technical Bottlenecks
Each transition between levels represents a qualitative leap in agent intelligence and autonomy:
- L0→L1: Introduction of intelligent assistance, shifting humans from solo practitioners to users of query-responsive assistants.
- L1→L2: Agents gain perception and interaction, evolving into procedural executors within human-defined workflows.
- L2→L3: Transfer of task dominance; agents orchestrate end-to-end pipelines, interpreting high-level user intent and managing diverse tasks.
- L3→L4: Removal of supervision; agents achieve proactive, unsupervised operation, continuously monitoring and acting within data ecosystems.
- L4→L5: Generative innovation; agents pioneer new methodologies and paradigms, advancing the state-of-the-art without human involvement.
The most critical current bottleneck is the L2-to-L3 leap, where agents must transition from executing predefined procedures to autonomously orchestrating complex, cross-domain workflows. This requires advances in strategic reasoning, dynamic toolset evolution, and holistic lifecycle coverage.
State-of-the-Art: Literature Review by Autonomy Level
L1: Prompt-Based Assistance
L1 agents are prevalent in data management (configuration tuning, query optimization, system diagnosis), data preparation (cleaning, integration, discovery), and data analysis (TableQA, NL2SQL, NL2VIS, unstructured analysis, report generation). They leverage LLMs for code generation, advice, and atomic task support but lack adaptive feedback mechanisms. Their outputs require manual integration and validation, limiting autonomy and scalability.

Figure 3: L1 Data Agents (Assistance).
L2 agents interact with databases, code interpreters, APIs, and external tools, enabling iterative refinement and feedback-driven optimization. Examples include feedback loops for configuration tuning, execution-driven query optimization, and multi-agent frameworks for diagnosis and cleaning. However, they remain confined to human-defined pipelines and task-specific architectures, lacking the ability to generalize or self-orchestrate across the data lifecycle.
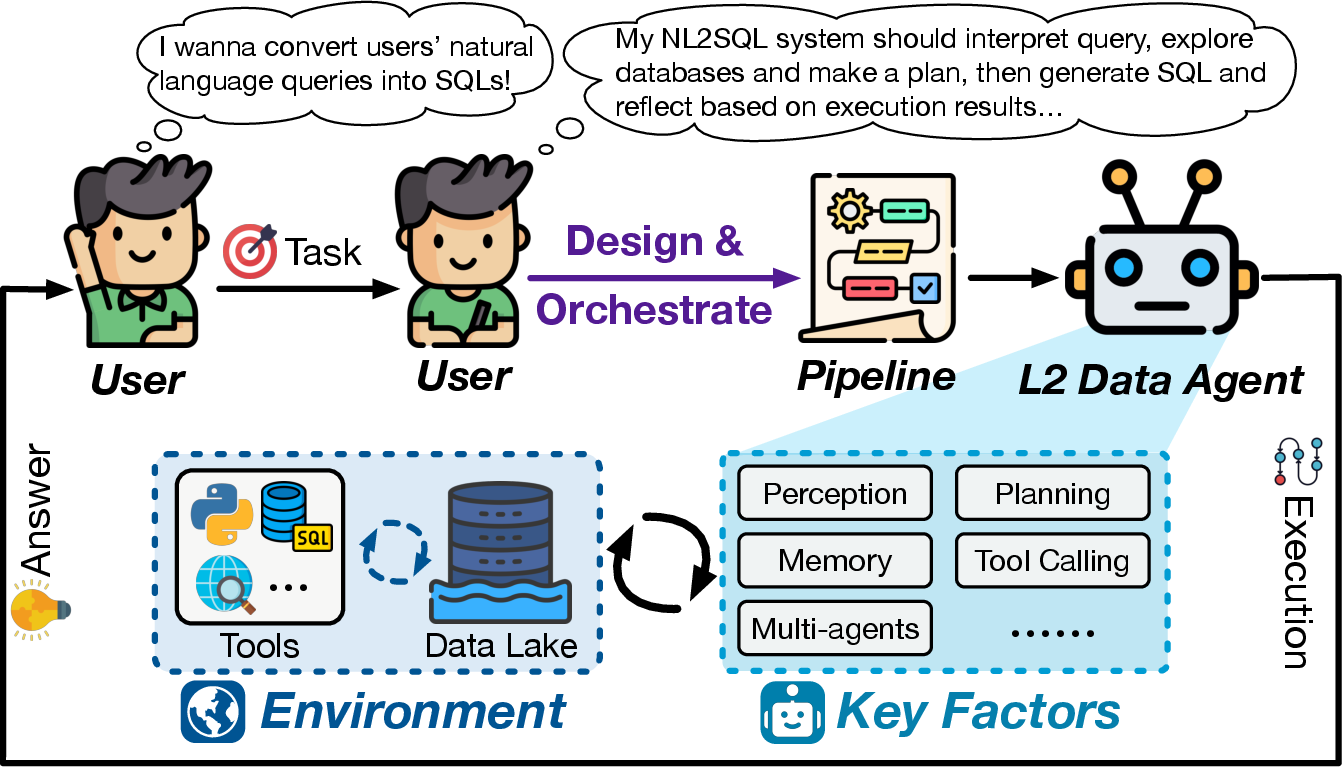
Figure 4: L2 Data Agents (Partial Autonomy).
L3: Autonomous Orchestration under Supervision
Proto-L3 systems (e.g., AgenticData, JoyAgent, Data Interpreter, iDataLake, AOP) begin to address autonomous pipeline orchestration and dynamic toolset evolution. They demonstrate nascent capabilities in decomposing high-level objectives, dynamic operator creation, and multi-agent collaboration. However, they are still limited by reliance on predefined operators, incomplete lifecycle coverage, and tactical rather than strategic reasoning. No system yet achieves full L3 autonomy.
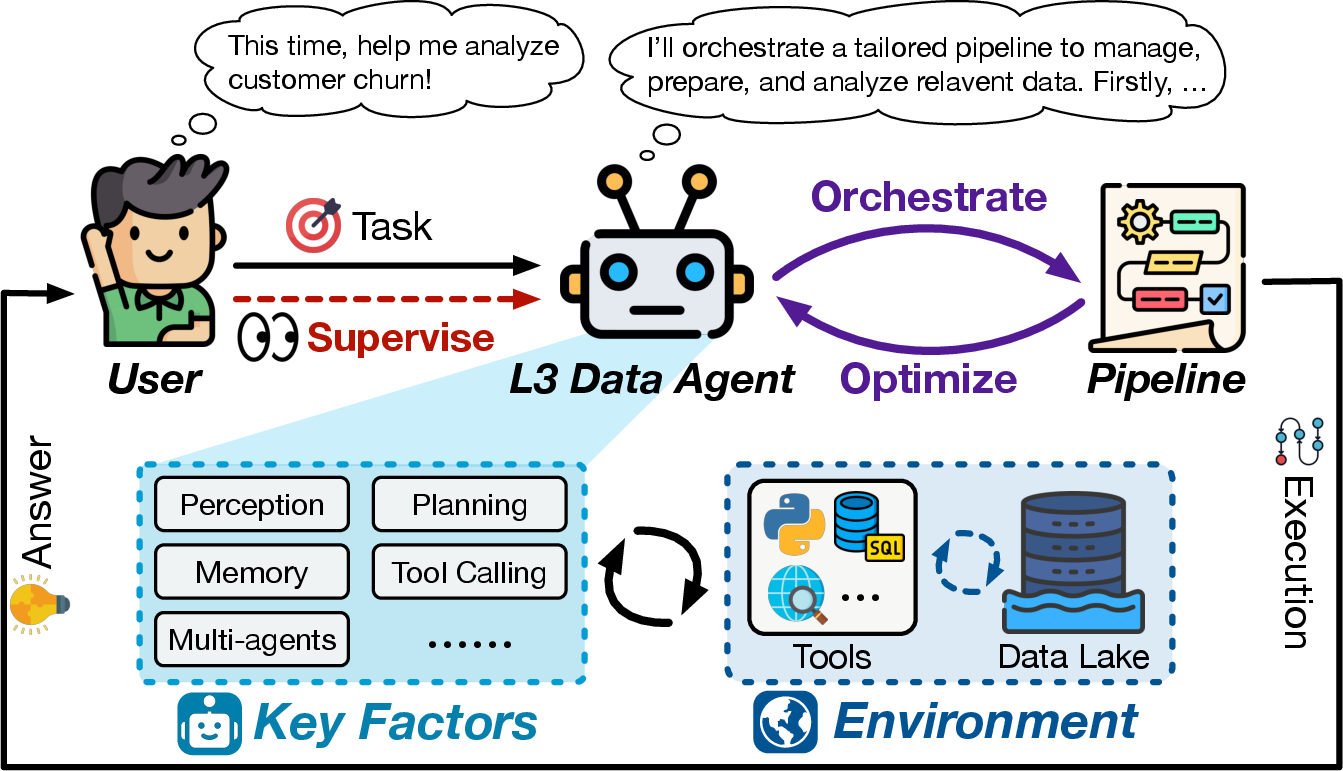
Figure 5: L3 Data Agents (Conditional Autonomy).
L4–L5: Vision of Proactive and Generative Agents
L4 agents are envisioned as proactive, self-governing systems capable of autonomous problem discovery, long-horizon planning, and holistic lifecycle management. L5 agents transcend application of existing methods, inventing new theories and paradigms, and functioning as generative, expert data scientists. These levels remain aspirational, with key challenges in intrinsic motivation, strategic reasoning, and robust safety guarantees.
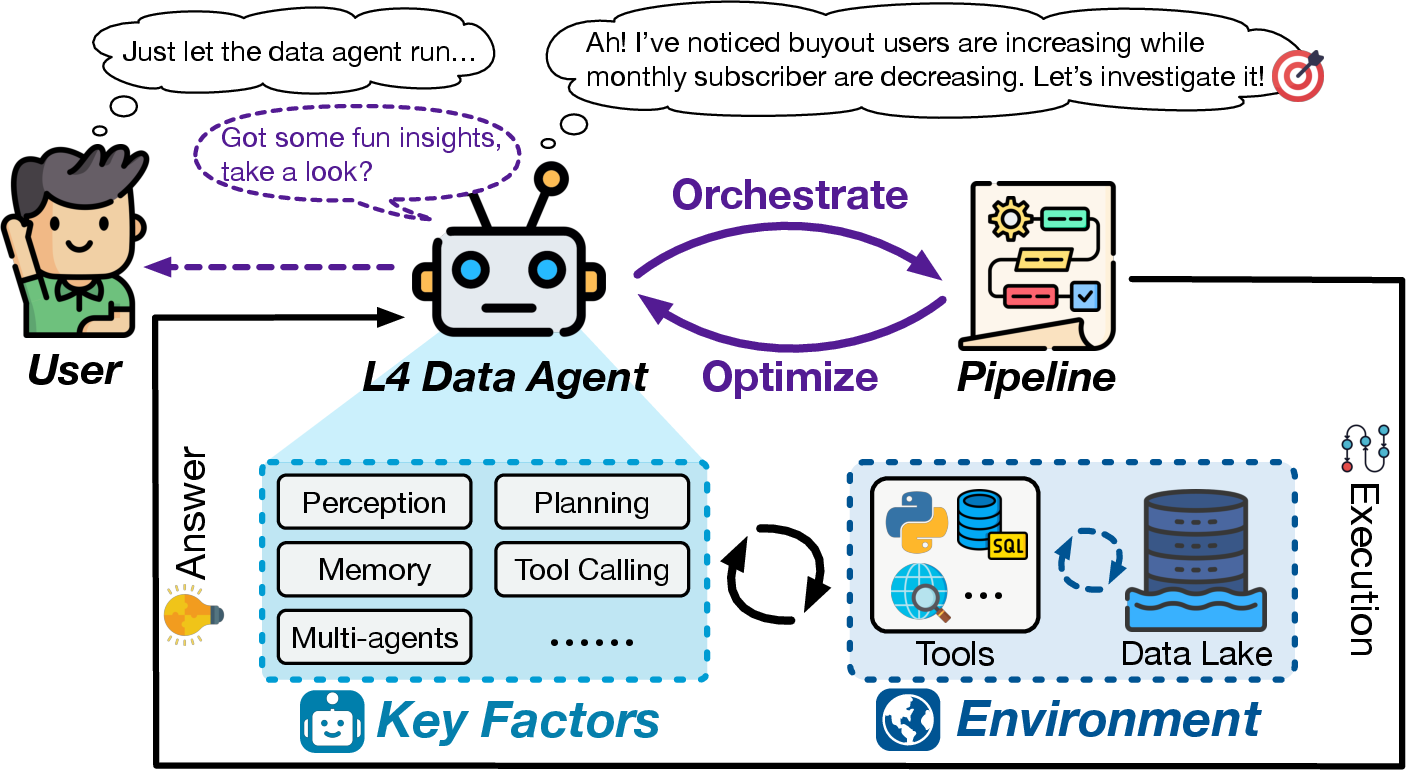
Figure 6: L4 Data Agents (High Autonomy).
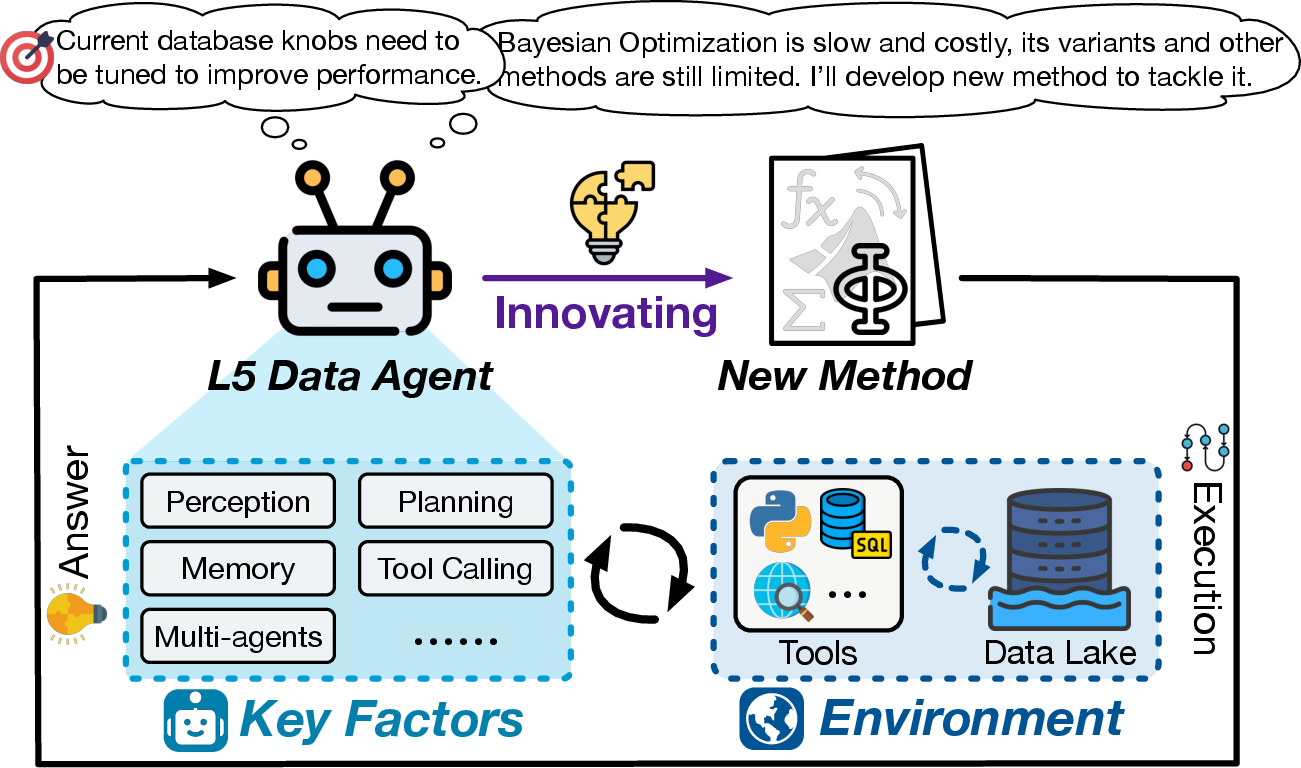
Figure 7: L5 Data Agents (Full Autonomy).
Implications and Future Directions
Practical Implications
- Taxonomy Adoption: The hierarchical framework provides a common language for system comparison, governance, and accountability, essential for industry adoption and regulatory compliance.
- Deployment Strategy: Current deployments should clearly communicate agent autonomy levels to users, aligning expectations and intervention protocols.
- Risk Mitigation: Explicit capability boundaries reduce the risk of over-reliance, erroneous outputs, and cascading failures in data-centric workflows.
Theoretical Implications
- Research Bottlenecks: The L2-to-L3 transition is the most pressing research frontier, requiring breakthroughs in autonomous orchestration, dynamic skill/tool evolution, and cross-lifecycle reasoning.
- Evaluation Protocols: Future benchmarks should assess agents on holistic, long-horizon tasks, dynamic environments, and their ability to self-evolve and innovate.
- Safety and Trust: As agents approach L4/L5 autonomy, robust mechanisms for self-governance, safety, and ethical compliance become paramount.
Speculation on Future Developments
- Agentic Reinforcement Learning: Integration of agentic RL and curriculum learning will be critical for evolving agent capabilities beyond static, heuristic modules.
- Skill Discovery and Evolution: Automatic data-skill discovery and dynamic toolset enrichment will enable agents to transcend fixed operator sets.
- Holistic Data Ecosystem Management: Agents will increasingly manage, prepare, and analyze data across heterogeneous, multimodal environments, supporting end-to-end, cross-domain workflows.
- Generative Innovation: L5 agents may eventually pioneer new analytical paradigms, visualization grammars, and data management theories, fundamentally transforming the field.
Conclusion
This survey establishes a rigorous, hierarchical taxonomy for data agents, clarifying the landscape and guiding both research and deployment. By analyzing evolutionary leaps, technical gaps, and current state-of-the-art systems, it identifies the critical challenges and opportunities for advancing agent autonomy. The roadmap toward L4 and L5 agents—proactive, generative, and fully autonomous—remains a long-term vision, but the systematic framework and structured review provided here lay the foundation for future breakthroughs in data-centric AI.