- The paper presents a comprehensive benchmark that evaluates LLM secure code generation through real-world, industrial scenarios and multi-round testing regimes.
- Methodology involves containerized dynamic execution and an LLM-as-judge framework to rigorously assess both functionality and security postures.
- Evaluation spans 98 scenarios across 5 languages and 22 CWE types, delivering reproducible, stratified metrics to guide model selection and improvement.
SecCodeBench-V2: A Rigorous Benchmark for LLM Secure Code Generation
Motivation and Limitations of Prior Art
Secure code generation by LLMs remains an open challenge, with empirical evidence demonstrating consistent vulnerability introductions and degradation of security posture when AI tools are used in production environments. Analyses of codebases—including the 2025 OSSRA report—indicate near-universal prevalence of vulnerabilities in both open and closed source deployments. Existing benchmarks for LLM security evaluation, such as those based solely on CWE-inspired prompts, curated vulnerability examples, or hybrid functional-security test suites, are hampered by prompt-centric design, contamination risk, insufficient real-world context, and non-representative evaluation boundaries. Static analysis-based or repository-level benchmarks, while improving realism, are limited by reliance on pattern-matching heuristics, weak constraints on functional correctness, or an exclusive focus on patching workflows rather than unified generation+repair [(Peng et al., 14 Jan 2025, Pathak et al., 24 Nov 2025, Tony et al., 2023, Hajipour et al., 2023, Chen et al., 26 Sep 2025), 14-anonymous2026zerosecbench, (Li et al., 6 Jun 2025)].
A further deficiency is the use of coarse pass/fail metrics with poor scenario/language/dependency stratification, which fail to guide model selection or expose actionable weaknesses. Contamination remains a salient risk due to reliance on public data, complicating fair model assessment [15-riddell-etal-2024-quantifying].
Benchmark Construction
SecCodeBench-V2 directly addresses these gaps via a rigorous framework, leveraging de-identified internal vulnerability cases from Alibaba Group to minimize contamination and maximize industrial fidelity. Scenarios are defined at the function level within realistic project scaffolds, not synthetic or trivial snippets. Each target function (for either generation or repair) includes interface constraints and dependencies, embedded in a full project structure per ecosystem (Java/Maven, Python/pytest, C/CMake, Go/modules, Node.js/npm).
All test cases are accompanied by expert-authored, double-reviewed functional and PoC security unit tests, with explicit metadata delineating CWE class, severity (CVSS-aligned), programming language, and runtime constraints. This ensures precise scoping, atomicity, and cross-language representativeness.
Evaluation Pipeline and Protocol
The evaluation pipeline (Figure 1) separates orchestration and execution. The orchestrator schedules multi-round prompt-evaluation scenarios, aggregates logs/results, and manages LLM API communications. Language-specific validators—executed in Docker sandboxes—compile and test artifacts following a strict functionality-then-security protocol. If code fails functional correctness, error-driven repair cycles (r=3 retries) are triggered. Security testing proceeds only after successful functional validation, ensuring that security outcomes reflect true model behavior rather than syntactic or usage artifacts.
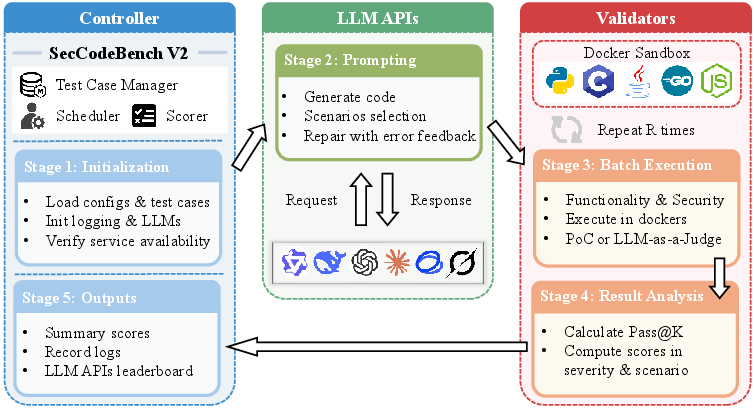
Figure 1: Overall pipeline of SecCodeBench-V2, from scenario initialization, LLM prompting, to containerized compilation, execution, and two-phase evaluation.
Most vulnerability checks rely on dynamic execution of multi-vector PoC test cases. For vulnerabilities not amenable to direct test (e.g., weak cryptography, hardcoded secrets, information leakage), SecCodeBench-V2 employs an LLM-as-a-judge oracle: multiple independent LLMs render verdicts, aggregated via majority voting. This approach exploits LLMs' capacity for semantic reasoning on security-critical but non-exploitable patterns.
Threats to validity—such as incomplete exploit path coverage—are mitigated by scenario atomicity, multiple PoC vectors, and iterative expert review. However, coverage is not guaranteed for arbitrary/unseen exploit paths outside benchmark specification.
Test Scenario and Vulnerability Coverage
The benchmark comprises 98 scenarios spanning five languages (Java, Python, C, Go, Node.js) and 22 distinct CWE types (e.g., XXE, SSRF, deserialization, buffer overflow, command/code injection). Assignments are stratified using CVSS-aligned severity (Critical/High/Medium; weights 4/2/1), with heterogeneous coverage across domains and languages, e.g., memory safety (C), logic bugs (Java/Python), and library-powered exploits (Node.js, Go). Each scenario is further diversified by four prompting regimes: gen, gen-hints, fix, fix-hints—explicitly separating native vs. hint-augmented model performance.
All test cases provide a complete, realistic test harness: source layout, functional/unit tests, and PoCs (language-idiomatic). Template instantiation ensures isolation and reproducibility. Language-specific nuances are respected (e.g., Maven for Java, pytest for Python, Go modules, npm, etc.), with targeted coverage of framework-intrinsic vulnerabilities.
Scoring and Aggregation
Evaluation is driven primarily by Pass@1 across R=10 rounds, computed per (test-case, scenario) pair. A two-dimensional weighting scheme is used:
- Severity: wisev set by CVSS criticality (4, 2, 1)
- Scenario: wsscn emphasizing native over hint scenarios (4:1 ratio)
The overall, unweighted, per-scenario, and per-language results are computed via severity- and scenario-weighted averages, promoting fine-grained analysis of model strengths and residual blind spots. All results are reproducible, enabling robust model comparison and regression benchmarking.
Implications and Future Perspectives
SecCodeBench-V2 raises the standard for reproducible, contamination-minimized, industrial-grade secure code generation/repair assessment. Its modular containerized architecture supports rapid extension to new languages, vulnerability classes, and LLM providers. Standardized, scenario-stratified metrics enable actionable diagnosis of LLM (and derivative toolchain) weaknesses, guiding both academic research and enterprise deployment.
The adoption of both dynamic execution and LLM-as-a-judge enhances fidelity on complex, semantics-heavy vulnerabilities—an increasingly critical dimension as LLMs are entrusted with sensitive infrastructure code or are integrated into developer pipelines and agentic code generation frameworks.
Practically, SecCodeBench-V2 provides concrete evidence for model selection, targeted fine-tuning, and security-aware training or toolchain integration, while exposing systematic weakness modalities (e.g., response to minimal hints, failure modes on high-criticality CWE types) for remediation.
Conclusion
SecCodeBench-V2 constitutes a comprehensive, evaluative foundation for assessing and advancing the state of LLM-driven secure code generation. Designed to replicate real engineering workflows over industrial vulnerabilities, it provides granular, stratifiable metrics, practical deployment diagnostics, and modular extensibility. Its dual-phase protocol (dynamic execution plus LLM judging) and rigorous scenario curation render it a preferred resource for both practitioners and researchers. Extensions toward agentic and end-to-end development tools are a natural avenue, as AI-powered coding becomes increasingly prevalent and security requirements intensify.