- The paper introduces a merged pipeline framework that clusters NN layers to balance computational loads and reduce network-on-package communication overhead.
- It employs input-shared and weight-shared partitioning with a dynamic programming search to efficiently map clusters onto chiplets.
- Empirical results demonstrate up to a 1.73x throughput improvement on deep networks like ResNet152 compared to segmented pipeline schemes.
Scope: A Scalable Merged Pipeline Framework for Multi-Chip-Module NN Accelerators
Introduction and Motivation
The paper "Scope: A Scalable Merged Pipeline Framework for Multi-Chip-Module NN Accelerators" (2602.14393) presents a significant advance in orchestrating neural network (NN) inference across multi-chip-module (MCM) architectures. MCMs, which integrate numerous chiplets onto a package substrate, offer enhanced hardware scalability and cost efficiency relative to monolithic chips. However, as chiplet counts rise, two primary bottlenecks intensify: network-on-package (NoP) communication overhead and resource underutilization due to suboptimal layer partitioning. Existing parallelization schemes, such as intra-layer parallelism and conventional segmented pipelines, demonstrate severe limitations in exploiting computational resources and minimizing communication, particularly for deep NNs.
The authors identify a striking gap in prior work: layers are scheduled individually without consideration for joint execution, resulting in mismatches between hardware allocation and layer computation requirements. This motivates the Scope framework, which introduces a "cluster" dimension—merging layers to form clusters with balanced computational loads, thereby enabling superior hardware utilization and alleviating pipeline mismatches.
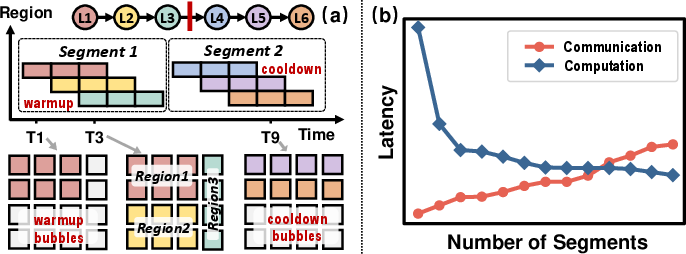
Figure 1: (a) Segmented pipeline execution. (b) Segment count tradeoff: communication vs. pipeline bubble overhead.
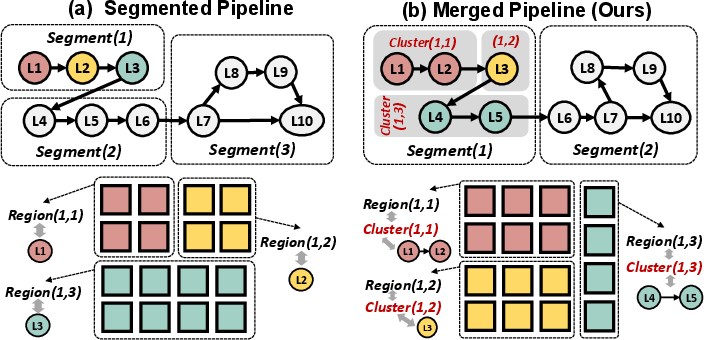
Figure 2: Scope unlocks multi-to-multi layer-to-chiplet mapping, enhancing allocation flexibility over segmented pipelines.
Scope Framework: Architecture and Execution Model
MCM Structure and Chiplet Microarchitecture
The paper details a modular MCM structure adopting a 2D-mesh topology, with chiplets comprising global buffers, PE arrays, and hierarchical memory, facilitating scalable computation. Chiplet-to-chiplet communication over NoP is less efficient than on-chip links, necessitating advanced scheduling.
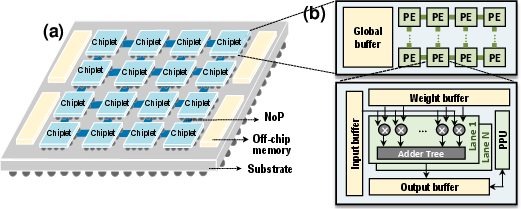
Figure 3: (a) Overview of MCM structure. (b) Chiplet micro-architecture with hierarchical memory and compute.
Scope’s operational backbone is its merged pipeline. Layers are grouped into clusters, each mapped onto a specific region of chiplets. This multi-layer cluster formation eases stage matching and circumvents the bottlenecks inherent in naïve segmented pipelines. Two intra-layer partition schemes—input-shared (ISP) and weight-shared (WSP)—are used to trade off activation communication and weight memory footprint.
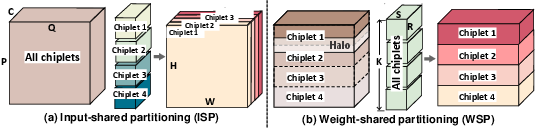
Figure 4: Intra-layer partitioning schemes implemented across four chiplets.
Within each segment, clusters act as pipeline stages. Execution time per segment is dictated by the slowest cluster; thus, forming clusters with balanced computational loads is crucial for maximizing throughput. Scope overlaps computation and communication phases, effectively masking NoP latency.
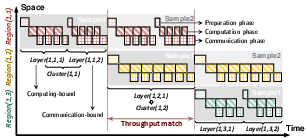
Figure 5: Scope’s segment execution decomposed into pipelined clusters, overlapping computation and communication for reduced latency.
Design Space Exploration and Algorithmic Strategy
Scope introduces a vastly larger design space due to cluster formation and flexible partitioning. For L layers and C chiplets, configurations scale as O(2L∑Q(i;L,C)). To address the exponential complexity, the authors develop a dynamic programming (DP) based search algorithm that leverages layer parallelism and heuristic chiplet allocation strategies:
- Cluster Formation: DP merges adjacent layers with similar parallelizable dimensions, tracking candidate cluster divisions.
- Region Assignment: Chiplets are proportionally allocated to clusters based on computational demand, with iterative refinement to minimize latency.
- Partition Scheme: Partitioning transitions from WSP in shallow layers (for minimized activation communication) to ISP in deeper layers (for reduced weight footprint), with a single transition point to optimize complexity.
This approach efficiently finds schedules in the top 0.05% of the full space with linear complexity.
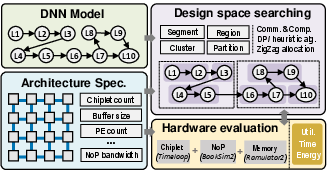
Figure 6: Scope framework overview with design variables extracted from DP-heuristic DSE.
Empirical Evaluation and Analysis
Search Methodology Validation
Comprehensive evaluation on a simulator-based MCM platform demonstrates the efficacy of Scope’s search strategy. In small-scale exhaustive searches, Scope’s algorithm attains solutions in the top 0.05% of throughput distributions.
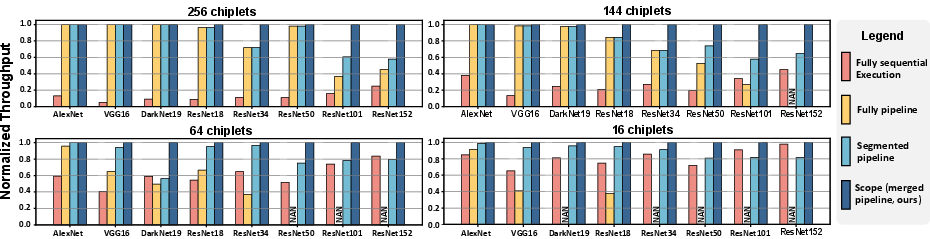
Figure 7: Processing time distribution for all valid schedules; Scope algorithm outputs top-performing solutions.
Throughput and Scalability
Scope consistently outperforms fully-sequential, fully-pipelined, and segmented pipeline baselines, especially as network depth and chiplet count increase. Maximum normalized throughput improvement is observed in large-scale experiments (ResNet152 on 256-chiplet MCM), showing up to 1.73x speedup over previous SOTA.
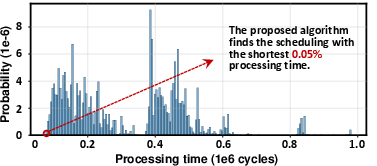
Figure 8: Normalized throughput across NNs and MCM scales; Scope delivers superior performance in large-scale regimes.
Scalability tests with increasing chiplets demonstrate that Scope’s throughput growth is robust, while segmented pipelines plateau and sequential execution degrades due to communication bottlenecks.
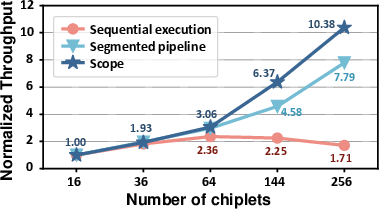
Figure 9: Normalized throughput versus chiplet count; Scope exhibits best scaling behavior.
Case Study: Cluster Versus Layer-Level Scheduling
A detailed case study with ResNet152 deployed on 256 chiplets contrasts segmented pipeline and Scope. Scope achieves balanced cluster workloads with significantly lower variance, ensuring efficient stage matching and pipeline utilization. Scope and segmented pipelines consume comparable energy, but Scope's improved utilization translates to higher throughput.
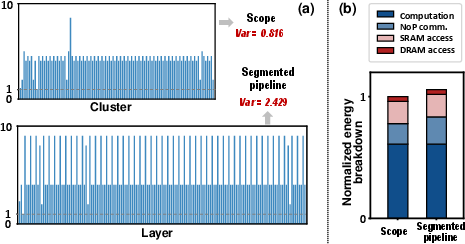
Figure 10: (a) Normalized computation across clusters/layers; Scope delivers balanced distribution. (b) Energy breakdown for Scope and segmented pipeline.
Practical and Theoretical Implications
Scope’s merged pipeline architecture facilitates highly scalable and efficient NN inference on MCMs, circumventing the underutilization and NoP overheads endemic to prior schemes. The DP-heuristic DSE advances automated scheduling for complex hardware-software co-design, demonstrating feasibility for real-world deployments with hundreds of chiplets.
Practically, Scope enables inference of very deep NNs (e.g., ResNet152) with near-linear scaling, efficient hardware utilization, and minimal energy penalty. The distributed weight buffering mechanism is crucial for ensuring that buffer constraints do not become a bottleneck, especially in WSP-heavy cluster formations.
Theoretically, Scope generalizes the segmented pipeline paradigm, providing a framework for cluster-level pipeline stage matching and multi-to-multi layer-to-chiplet mapping. The approach represents a stride towards abstraction-driven NN accelerator design, opening avenues for further research in adaptive clustering, hierarchical partitioning, and reinforcement learning-based scheduling.
Future Directions
Potential future developments include:
- Extension of cluster abstraction to heterogeneous chiplet networks or hybrid memory hierarchies.
- Integration of Scope scheduling with runtime dynamic optimization or adaptive inference.
- Exploration of Scope’s applicability in training workloads, not solely inference.
- Combining Scope with quantization and model compression techniques for deeper energy/area efficiency.
Conclusion
Scope introduces a scalable merged pipeline framework exploiting a multi-layer cluster dimension for NN scheduling on MCM architectures. With dynamic programming guided DSE, flexible layer partitioning, and distributed weight management, Scope achieves substantial throughput gains and superior scalability, uniquely bridging theoretical peak and achievable performance for large-scale chiplet-based NN inference. The framework is poised to influence both accelerator architecture and automated scheduling methodologies for deep learning at scale.