SkillRater: Untangling Capabilities in Multimodal Data
Abstract: Data curation methods typically assign samples a single quality score. We argue this scalar framing is fundamentally limited: when training requires multiple distinct capabilities, a monolithic scorer cannot maximize useful signals for all of them simultaneously. Quality is better understood as multidimensional, with each dimension corresponding to a capability the model must acquire. We introduce SkillRater, a framework that decomposes data filtering into specialized raters - one per capability, each trained via meta-learning on a disjoint validation objective - and composes their scores through a progressive selection rule: at each training stage, a sample is retained if any rater ranks it above a threshold that tightens over time, preserving diversity early while concentrating on high-value samples late. We validate this approach on vision LLMs, decomposing quality into three capability dimensions: visual understanding, OCR, and STEM reasoning. At 2B parameters, SkillRater improves over unfiltered baselines by 5.63% on visual understanding, 2.00% on OCR, and 3.53% on STEM on held out benchmarks. The learned rater signals are near orthogonal, confirming that the decomposition captures genuinely independent quality dimensions and explaining why it outperforms both unfiltered training and monolithic learned filtering.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
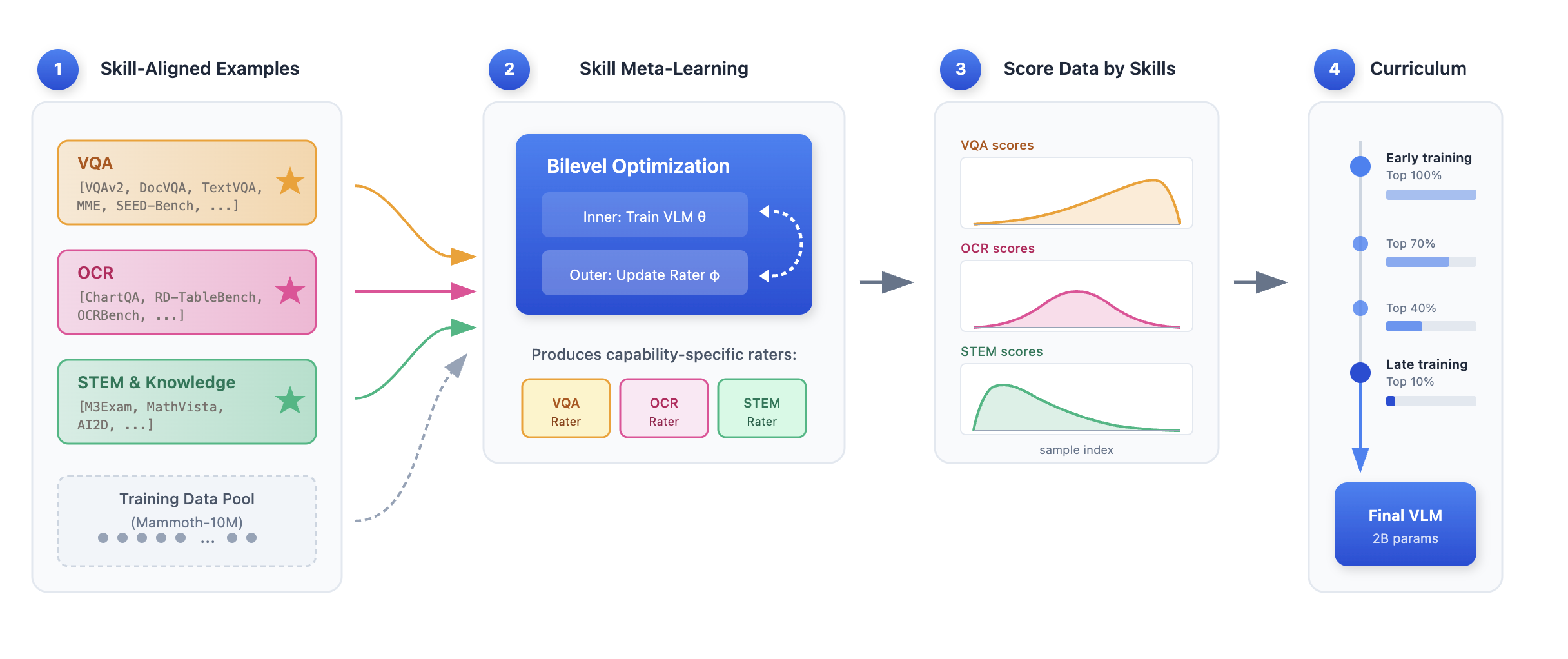
This paper introduces SkillRater, a new way to pick better training examples for vision-LLMs—AI systems that can look at pictures and read text. Instead of giving each example one “quality score,” the authors argue that quality has many parts (or skills), like understanding an image, reading text inside an image (OCR), and doing math/science reasoning (STEM). SkillRater uses separate “raters” for each skill so the model learns all of them more effectively.
What questions did the researchers ask?
The paper focuses on three simple questions:
- Is it better to judge training data with multiple skill-specific scores instead of just one?
- Can separate raters (one per skill) pick training examples that actually improve those skills more?
- Does a “training plan” that starts broad and gets stricter over time help the model improve across different skills?
How did they study it?
Think of training the model like teaching a student with mixed homework: photos, diagrams, charts, and questions. SkillRater works like having three specialist teachers:
- A “visual understanding” teacher,
- An “OCR” (reading text in images) teacher,
- A “STEM reasoning” teacher.
Each teacher learns to spot examples that are most helpful for their skill using a process called meta-learning. Here’s the idea in everyday terms:
- Meta-learning: It’s like trying a mini-lesson with a small test, then adjusting which practice problems you choose next time based on how much the test score improves. The rater “learns how to choose” examples that lead to better skill scores.
- Multiple raters: Instead of one general teacher giving a single grade to every example, each specialist teacher scores examples only for their skill. This avoids mixing different needs into one number.
- Union rule: If any teacher says, “This example is good for my skill,” the example stays. This keeps useful diversity—especially early in training.
- Curriculum learning: The training plan starts wide (keeping most examples) and gradually gets stricter (keeping only high-value examples). Early on, the student sees many kinds of images and questions; later, they focus on the hardest and most helpful ones. The thresholds tighten over 10 stages, ending with roughly the top 19% of data.
What did they find?
The results show that splitting quality into skills and using a curriculum works better than a single “one-size-fits-all” score.
Key findings:
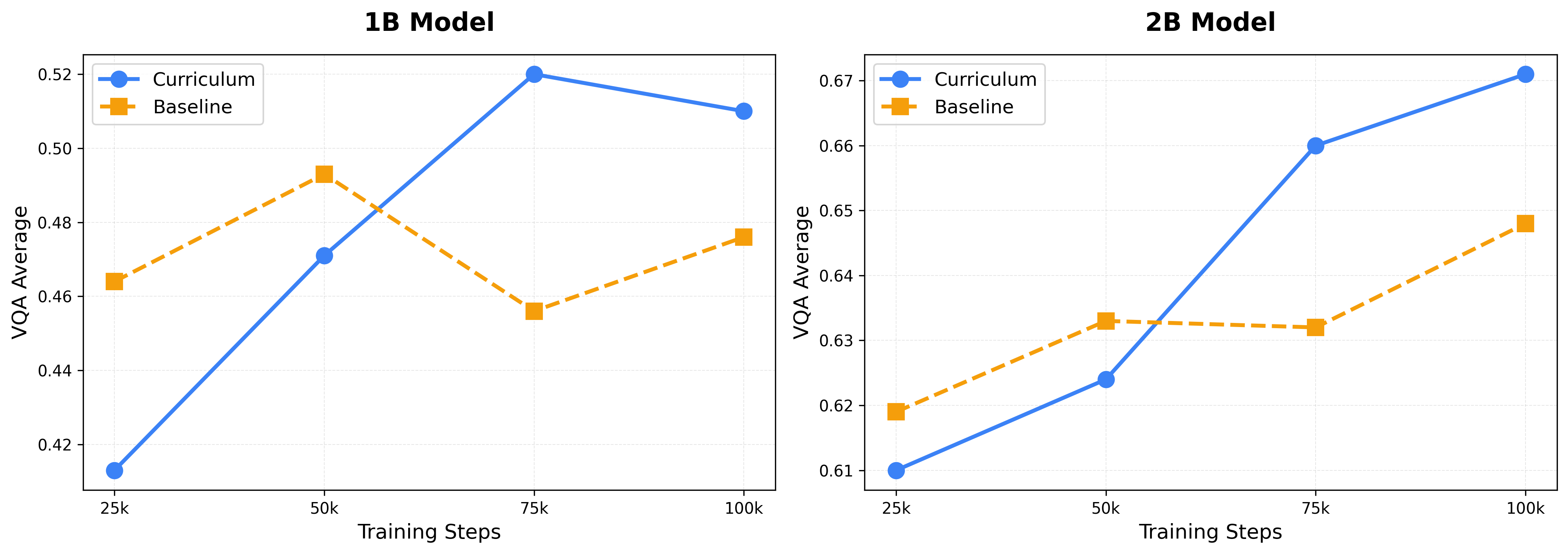
- Skill-specific gains:
- Visual understanding improved by 5.63%.
- OCR improved by 2.00%.
- STEM reasoning improved by 3.53%.
- Overall improvement: The combined score (across all three skills) improved by about 3.7 points compared to training without filtering.
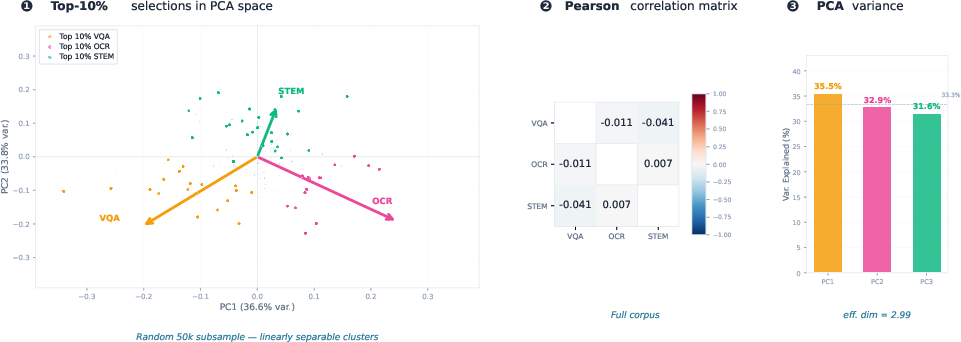
- The raters’ scores are “near orthogonal”: That means each rater picks different kinds of helpful examples with very little overlap. In plain terms, the visual teacher, the OCR teacher, and the STEM teacher disagree in useful ways—so together they cover more ground.
- Curriculum beats static filtering: A staged plan that gets stricter over time performs better than choosing a fixed top % of examples from the start.
- Scale transfer: Raters trained on a smaller model still help a larger model without retraining, suggesting the method generalizes well.
Why is this important? When you compress different skills into one score, you often lose what makes each skill unique. By keeping skills separate, the model learns each area more effectively.
Why does it matter?
This approach makes training smarter and more efficient:
- It helps models that need multiple abilities (like seeing, reading, and reasoning) learn each one well, without sacrificing one skill for another.
- It uses training data more wisely: keep diverse examples early, then focus on the best ones later.
- It can be applied beyond images and text—any time an AI must learn different skills (like writing, coding, or following instructions), separate raters could help.
In short, SkillRater shows that “quality” isn’t just one thing. By treating it as a set of skills and training with a thoughtful curriculum, we can build AI systems that are better at the tasks we actually care about.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up work:
- Capability coverage is limited to three axes (visual understanding, OCR, STEM); performance and design implications for other skills (e.g., spatial/3D reasoning, temporal/video, scientific diagrams beyond AI2D, multilingual OCR, safety/harms) are untested.
- Sensitivity to the choice of validation benchmarks is not quantified; no study shows robustness of raters to different benchmark sets or alternative splits, nor to removal/perturbation of specific validation tasks.
- The paper does not determine how many raters (capability dimensions) are optimal before diminishing returns; there is no empirical curve of “number of raters vs. gains.”
- Automatic discovery of capability axes is not explored; raters are predefined rather than learned or discovered from data (e.g., via unsupervised clustering or multi-objective factorization).
- Score calibration across raters is not addressed; thresholds are set via per-rater top-p, but differences in score distributions or drift over time could bias union selection.
- The union-composition rule is the only aggregator evaluated; alternatives (intersection, weighted unions, learned gating, Pareto-front selection, hypervolume maximization) are not compared.
- The independence assumption used to invert union retention (1 − (1 − p)C) is only approximately true; no mechanism adapts thresholds when empirical correlations deviate from this assumption.
- Hard filtering is favored over continuous reweighting; the paper does not test hybrid strategies that combine continuous per-rater weights with curriculum or that interpolate between union and scalarization.
- The curriculum schedule is hand-designed (quadratic decay); no ablation over schedule shapes, stage counts, learned curricula, or joint bilevel optimization of curriculum parameters.
- The first-order (stop-gradient) meta-learning surrogate introduces bias; there is no quantification of the gap vs. second-order meta-gradients or partial unrolling strategies, and no sensitivity analysis to inner-loop length S and K/K′.
- Compute overhead and scalability are not reported (rater inference FLOPs, wall-clock, memory); it is unclear how the approach scales to web-scale corpora (109–1012 samples) or how to amortize scoring.
- Raters appear static during mid-training; the paper does not study online/adaptive raters that update as the base model and data distribution evolve, nor the stability of fixed raters across long runs.
- Rater features are extracted from a frozen SigLIP-400M encoder; the impact of using base-model features, jointly training the feature extractor, or capability-specific feature towers is not evaluated.
- Generalization across architectures is only shown for 1B→2B transfer; transfer to larger scales (e.g., ≥7B) or different backbones (e.g., EVA, SAM-like vision encoders) is untested.
- The method is validated on a specific data pool (MAmmoTH-like mid-training); portability to pretraining mixtures, alternative instruction-tuning corpora, or noisy web scrapes is not demonstrated.
- Quantitative analysis of what the raters retain is limited; there is no measurement of retained-data diversity, domain distribution shifts, or long-tail coverage across image types and text genres.
- Effects on fairness, demographic representation, toxicity/NSFW, and PII retention are not assessed; capability-driven selection might inadvertently amplify biases or safety risks.
- Statistical stability and reproducibility are unclear; results lack confidence intervals, multiple-seed variance, or sensitivity to different random initializations and data orderings.
- Capacity allocation across raters (fixed 150M total) is not optimized; the impact of per-capability rater size and capacity balancing on performance is unknown.
- Cross-skill interactions are underexplored; union may overselect single-skill samples while underserving multi-skill examples, and the trade-off between specialization and compositionality is not analyzed.
- The approach assumes benchmarks adequately proxy capabilities; strategies for weak/self-supervised rater training (e.g., pseudo-labels, self-consistency, contrastive goals) are not explored for under-benchmarked skills.
- Applicability beyond “multimodal mid-training” to pretraining and instruction tuning is asserted but not empirically validated.
- Task breadth remains narrow; downstream tasks beyond the evaluated VQA/OCR/STEM suite (e.g., grounding, dense captioning, retrieval, referring expressions, chart/table synthesis, video QA) are not assessed.
- Interactions with standard curation steps (deduplication, aesthetic filtering, NSFW/PII removal) are not studied; the marginal benefit of SkillRater on top of these common filters is unknown.
- Potential negative side-effects (e.g., exclusion of hard but valuable outliers, catastrophic forgetting of general visual features) are not measured; no retention/forgetting diagnostics are reported.
- Score drift and temporal dynamics are not monitored; there is no mechanism to recalibrate thresholds if rater score distributions or sample utility shift during training.
- Risks of benchmark leakage/contamination are only addressed at a high level; there is no audit of overlaps between training data and validation/evaluation benchmarks.
- Practical reproducibility is limited: core resources (Isaac 0.2 recipe, full rater architecture, code/checkpoints) are not publicly released, hindering external verification and extension.
Glossary
- Activation memory: The amount of memory used to store intermediate activations during neural network training or inference. Example: "which reduces peak activation memory from"
- Aesthetic scoring: A heuristic that predicts the visual appeal of images using learned embeddings. Example: "aesthetic scoring~\cite{schuhmann2022laion5b} predicts visual appeal from learned embeddings"
- Bilevel meta-learning: An optimization framework with an inner training loop and an outer loop that optimizes a meta-objective based on the inner loop’s outcome. Example: "is a bilevel meta-learning method"
- Bilevel optimisation: Framing data or parameter selection as a nested optimization problem with inner and outer objectives. Example: "frames data selection as bilevel optimisation"
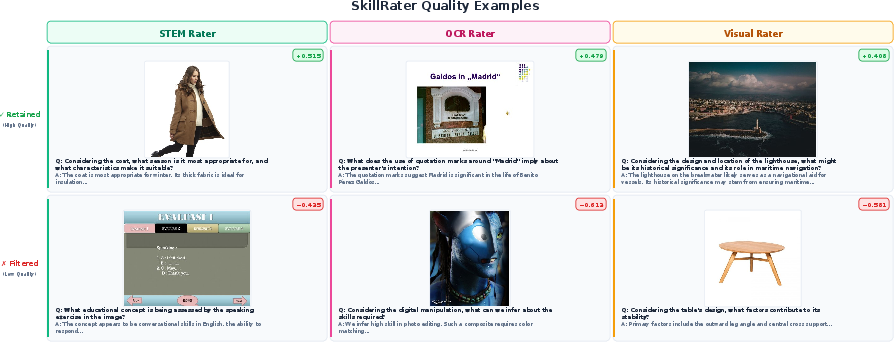
- Capability-aligned filtering: Selecting training data using evaluators specialized for different target capabilities. Example: "Capability aligned filtering. We propose SkillRater, a framework that trains specialized raters via meta learning on disjoint validation objectives"
- CLIP score filtering: Filtering image–text pairs by their CLIP-derived similarity score to favor aligned examples. Example: "CLIP score filtering \cite{schuhmann2022laion5b, gadre2024datacomp} measures image text alignment"
- Curriculum learning: A training strategy that orders or filters data from easier/broader to harder/more selective over time. Example: "We instead adopt a curriculum that progressively tightens quality thresholds over training"
- Data curation: The process of filtering, selecting, or weighting training data to improve downstream model performance. Example: "Data curation methods typically assign samples a single quality score."
- Deduplication: Removing near-duplicate examples from datasets to reduce redundancy and overfitting. Example: "deduplication~\cite{lee2022dedup} removes near duplicates through hashing."
- Disjoint validation objective: Separate validation targets used to specialize different components or raters without overlap. Example: "each trained via meta-learning on a disjoint validation objective"
- Effective dimensionality: A measure of how many principal components meaningfully explain variance in a set of signals. Example: "effective dimensionality 2.99 out of 3.0"
- Effective fraction of retained data: The portion of the dataset kept after filtering at a given curriculum stage. Example: "scheduling the effective fraction of retained data as a quadratic decay"
- First-order influence approximation: An approximation technique that estimates data influence using first-order terms to avoid expensive second-order computations. Example: "via first order influence approximation"
- First-order surrogate: An approximate meta-objective/gradient that ignores second-order terms to reduce computational and memory costs. Example: "We instead adopt a first-order surrogate with stop-gradient on the inner trajectory"
- Held-out benchmarks: Evaluation datasets not used during training or rater optimization, reserved for unbiased assessment. Example: "on held out benchmarks"
- Importance resampling: Reweighting or sampling data according to estimated importance to improve training efficiency or performance. Example: "reweight text by importance resampling and robust domain optimization."
- Inner loop: The lower-level optimization steps (e.g., training steps) within a bilevel framework. Example: "In the inner loop, we initialize the base model parameters"
- Interleaved text and vision tokens: A joint sequence representation that mixes textual and visual tokens for multimodal models. Example: "Training data is represented as interleaved text and vision tokens in a single sequence."
- Linearly separable: Describing data that can be divided by linear boundaries in feature space. Example: "linearly separable directions in score space."
- Meta-gradient: The gradient of the outer/meta-objective with respect to meta-parameters (e.g., rater parameters) in bilevel learning. Example: "The exact meta-gradient differentiates through the inner optimization trajectory"
- Meta-learning: Learning to learn; optimizing parameters (e.g., of a rater or scheduler) that guide another learning process. Example: "trained via meta-learning"
- Microbatch: A subdivision of a batch used to reduce memory footprint and accumulate gradients across smaller chunks. Example: "validation microbatches"
- Multimodal featurization: Converting heterogeneous inputs (e.g., images and text) into a joint feature representation. Example: "Multimodal featurization."
- OCR: Optical Character Recognition; the capability to read and interpret text embedded in images. Example: "visual understanding, OCR, and STEM reasoning."
- Orthogonality: Low-correlation or independence among signals or components, enabling disentangled contributions. Example: "Orthogonality."
- Outer-loop meta-update: The higher-level optimization that updates meta-parameters based on validation performance after inner-loop training. Example: "Outer-loop meta-update."
- Pairwise Pearson correlation: A measure of linear correlation between pairs of variables. Example: "pairwise Pearson correlations range from"
- Principal component analysis: A technique for dimensionality reduction by projecting data onto orthogonal directions of maximal variance. Example: "Principal component analysis shows near-uniform variance across components"
- Quadratic decay: A schedule where a quantity decreases proportionally to the square of normalized time or stage index. Example: "as a quadratic decay"
- Rater: A learned scoring function that assigns quality/utility scores to samples for a specific capability. Example: "Each rater is a 50M-parameter transformer"
- Reweighting: Adjusting the contribution of training examples by assigning weights to their losses. Example: "or reweight incoming training data"
- Robust domain optimization: Optimization aimed at improving performance across or against domain shifts using robust objectives. Example: "reweight text by importance resampling and robust domain optimization."
- Scale transfer: Applying components (e.g., raters) trained at one model size to a different, often larger, model size. Example: "Scale transfer at 1B and 2B parameters."
- Selection threshold: A cutoff score used by a rater to decide whether to include a sample in training. Example: "progressively tightens selection thresholds"
- SigLIP encoder: A specific vision-language encoder architecture (here, a 400M-parameter model) used for feature extraction. Example: "SigLIP 400M encoder"
- Spearman rank correlation: A nonparametric measure of rank-order correlation between variables. Example: "Spearman rank correlations are similarly low"
- Static top-k filtering: Selecting the top-k percent of samples by score throughout training without changing thresholds over time. Example: "The original DataRater approach applies static top- filtering"
- Stop-gradient: An operation that prevents gradient flow through certain tensors, treating them as constants during backpropagation. Example: "stop-gradient on the inner trajectory"
- Token-level loss gaps: Differences in per-token losses used as a signal for data selection or difficulty. Example: "select data by gradient influence or token level loss gaps"
- Top-p selections: Retaining samples within the top p-percentile according to a score distribution. Example: "the union of independent top- selections"
- Transformer backbone: The core Transformer architecture used as the main feature-processing component. Example: "rater's transformer backbone"
- Union rule: A selection rule that retains a sample if any of several raters deem it above their threshold. Example: "(union rule)"
- Unsupervised clustering methods: Techniques that group data without labels to find natural structure for selection or analysis. Example: "Unsupervised clustering methods discover natural data groupings"
- Validation objective: The performance measure on held-out data used to guide meta-optimization of data selection. Example: "validation objective"
- Vision-LLM (VLM): A model that processes and jointly reasons over visual and textual inputs. Example: "VLM training is more sensitive to early loss of visual diversity"
- Weighted microbatch gradient: A gradient computed over a microbatch where each sample’s loss is scaled by a learned weight. Example: "weighted microbatch gradient"
- Weighted SGD steps: Stochastic gradient descent updates where training samples contribute proportionally to assigned weights. Example: "run weighted SGD steps"
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can adopt the paper’s methods with modest engineering effort and readily available benchmarks and compute.
- Multimodal foundation-model data pipelines (software/AI industry) — Improve VLM mid-training by replacing single-score filters with capability-specific raters (e.g., Visual Understanding, OCR, STEM) and a union-based curriculum schedule.
- Tools/workflows: Training plugin that scores incoming batches with multiple raters; curriculum that tightens thresholds over time; dashboards tracking capability coverage and correlation.
- Assumptions/dependencies: Availability of capability-aligned validation benchmarks; capacity to run first-order meta-learning; access to a feature encoder (e.g., SigLIP or equivalent) compatible with rater inputs.
- Document AI and OCR automation (finance, legal, healthcare, government) — Curate training data for invoice processing, KYC/ID verification, claims intake, and records digitization by emphasizing OCR-relevant samples without sacrificing early visual diversity.
- Tools/products: DocumentOps pipeline integrating an OCR-focused rater; pretraining/fine-tuning sets filtered along OCR axes; quality reports for contract SLAs.
- Assumptions/dependencies: High-quality doc/image datasets with OCR benchmarks (e.g., TextVQA, DocVQA); privacy/PII compliance in data handling.
- Chart/table understanding for analytics (BI, enterprise software) — Improve chart/table QA and extraction by combining OCR and STEM raters to select chart-rich and reasoning-relevant samples.
- Tools/products: Chart intelligence modules trained on rater-filtered corpora (e.g., ChartQA-style data); pipeline checkpoints that preserve table/figure diversity early.
- Assumptions/dependencies: Representative chart/table datasets; task-aligned evaluation; compatible tokenizer/vision encoder for featurization.
- STEM and diagram tutors (education/edtech) — Curate multimodal math/diagram content (e.g., MathVista/AI2D-like) to boost reasoning with images and diagrams for tutoring systems.
- Tools/workflows: STEM-focused rater to select high-value, multi-step reasoning samples; curriculum to phase from broad coverage to reasoning-heavy data.
- Assumptions/dependencies: Coverage of target STEM subskills in validation benchmarks; sufficient diagram-rich corpora.
- Retail/e-commerce media quality and QA (retail) — Train product-search and visual QA systems using visual-understanding raters to prioritize diverse, aligned product imagery and captions; use OCR rater for receipt/label apps.
- Tools/products: Content ingestion filters; acceptance tests for product page media; OCR-enhanced shopping assistants.
- Assumptions/dependencies: Mapping between retail KPIs and capability benchmarks; robust visual diversity early in training.
- Robotics perception with multimodal reasoning (robotics) — Maintain scene and object diversity early while selectively refining perception-plus-reasoning data later, improving VLM components in embodied systems.
- Tools/workflows: Robotics dataset curation that unions multiple capability raters; staged thresholds integrated into robot learning loops.
- Assumptions/dependencies: Transferability of visual/STEM capability benchmarks to robot tasks; availability of multimodal robot data.
- Data marketplaces and curation vendors (data industry) — Offer “rater-as-a-service” that scores client datasets on multiple capability axes, providing orthogonality diagnostics and selection schedules.
- Tools/products: Scoring APIs; capability dashboards; retention/threshold schedulers; client-facing reports on coverage and trade-offs.
- Assumptions/dependencies: Licensing for feature encoders and benchmarks; generalization of raters to client domains.
- MLOps QA/governance for datasets (enterprise/policy) — Replace single “quality” numbers with capability-aware scorecards; audit diversity retention and threshold schedules for fairness and performance.
- Tools/workflows: Dataset scorecards per capability; union-rule retention audits; correlation heatmaps to detect over-compression or capability gaps.
- Assumptions/dependencies: Agreed capability taxonomy; internal buy-in to track and enforce multi-axis quality standards.
- Multimodal RAG indexing and retrieval (software) — Prioritize ingestion of items aligned to downstream capabilities (e.g., OCR-heavy docs for document-answers; diagram-rich items for STEM QA).
- Tools/workflows: Pre-index filters that weight content by capability scores; capability-aware retrieval policies.
- Assumptions/dependencies: Clear linkage between target QA tasks and capability axes; compatible embedding/indexing pipeline.
- Research labs and SMEs with limited compute (academia/SMBs) — Use small (≈50M) capability raters and first-order meta-learning to improve mid-training data quality without monolithic heavy scoring or large-scale hypergradients.
- Tools/workflows: Open-source rater modules; microbatch streaming and stop-gradient approximations for memory efficiency.
- Assumptions/dependencies: Implementation expertise; compatibility with the lab’s model/encoder stack and training recipe.
Long-Term Applications
These opportunities build on the paper’s core ideas but require additional research, scaling, or ecosystem maturation.
- Extension to other modalities/domains (text, code, audio/video) — Deploy capability-specific raters for text pretraining (e.g., factuality, reasoning, safety), code (correctness, style, test coverage), or speech (ASR accuracy, speaker variability).
- Potential products: Domain “Rater Zoo” with pre-trained raters per capability; cross-domain data curation suites.
- Assumptions/dependencies: Curated, representative validation benchmarks per capability; evidence of low cross-capability correlation in each domain.
- Jointly learned curricula and raters — Meta-learn curriculum parameters (thresholds, stage timing) along with rater weights to optimize end-task KPIs automatically.
- Potential tools: Auto-curriculum controllers; bilevel optimization libraries with efficient hypergradient approximations.
- Assumptions/dependencies: Stable, scalable hyperparameter optimization; robust proxies for downstream objectives.
- Automatic capability discovery (unsupervised/weakly supervised) — Discover latent capability axes and train raters without hand-crafted benchmark assignments, reducing reliance on expensive labeled evaluations.
- Potential products: Unsupervised capability mining services; clustering-backed rater initialization.
- Assumptions/dependencies: Meaningful structure in data; validation mechanisms to align discovered axes with useful behaviors.
- Streaming/online data firehose filtering (continual learning) — Apply union-of-raters selection in real time for continuous data ingestion, balancing diversity and targeted refinement as distributions shift.
- Potential tools: Real-time scoring microservices; drift-aware threshold re-schedulers.
- Assumptions/dependencies: Low-latency featurization; robust raters under distribution shift; monitoring and rollback mechanisms.
- Fairness-aware, capability-balanced curation (policy/ethics) — Use multi-axis raters (including fairness/safety) with union rules to prevent early loss of minority/dialect/low-resource content and to audit capability trade-offs.
- Potential products: Regulatory-grade dataset audits; fairness-preserving curriculum templates.
- Assumptions/dependencies: Fairness-capability benchmarks; consensus on fairness metrics; governance frameworks.
- Synthetic data generation closed-loop control — Guide synthetic data generators (text-to-image, data augmentation) to produce samples that fill capability gaps identified by raters.
- Potential tools: Generator–rater feedback loops; capability-targeted sampling policies.
- Assumptions/dependencies: Controllable generators; reliable signal from raters on synthetic content utility.
- Sector-specific raters (healthcare, geospatial, scientific domains) — Train orthogonal raters for domain-specific capabilities (e.g., radiology report grounding, map OCR, lab plots) for highly specialized AI systems.
- Potential products: Domain “Capability Packs” with raters and curricula; compliance-ready curation services.
- Assumptions/dependencies: Domain datasets and expert-defined benchmarks; strict privacy/compliance constraints.
- Standard-setting and certification for multi-dimensional data quality (policy/standards bodies) — Define procurement and reporting standards that require capability-wise dataset metrics and documented curricula.
- Potential products: Certification programs; standardized capability scorecards in Datasheets-like documentation.
- Assumptions/dependencies: Industry consensus; alignment with legal frameworks and auditing practices.
- Training system and hardware support for bilevel optimization — Integrate efficient first-order/budgeted hypergradient routines into training stacks and accelerators to make meta-learning ubiquitous.
- Potential tools: Framework-level APIs (e.g., PyTorch/TF/accelerators) for memory-efficient bilevel loops.
- Assumptions/dependencies: Vendor support; evidence of ROI across workloads.
- On-device/edge capability filtering for privacy-preserving curation — Lightweight raters select data locally before sharing, keeping sensitive content on-device while preserving capability utility.
- Potential products: Edge scoring SDKs; federated rater training.
- Assumptions/dependencies: Efficient on-device featurization; federated learning infrastructure; quantization-friendly raters.
- Explainability and audit tools grounded in orthogonality — Use low inter-rater correlation to explain why samples were kept/filtered and to visualize capability trade-offs for stakeholders.
- Potential tools: Capability-space plots; counterfactual “what-if” threshold simulations.
- Assumptions/dependencies: Stable, interpretable rater outputs; user education around multi-axis quality.
Notes on Key Dependencies Across Applications
- Capability benchmarks: Most applications require well-chosen, representative validation suites per capability; gaps in benchmark coverage limit what raters can learn to value.
- Orthogonality assumption: The union-based selection and threshold inversion assume low cross-rater correlation; if capabilities are entangled, gains may diminish.
- Compute and integration: While raters are relatively small (~50M), meta-learning and feature extraction add overhead; teams need MLOps integration and memory-efficient training (e.g., first-order surrogates).
- Encoder compatibility: Raters in the paper use features from a frozen SigLIP-like encoder; porting to different stacks requires compatible feature interfaces or retraining.
- Data governance: For regulated domains, privacy, licensing, and bias audits must be integrated into curation workflows from the outset.
Collections
Sign up for free to add this paper to one or more collections.