- The paper introduces a meta-gradient data selection pipeline that dynamically rates image-text pairs to optimize text-to-image training.
- It employs a Shift-Gsample strategy that discards trivial samples and focuses on mid-ranked, informative examples to enhance data efficiency.
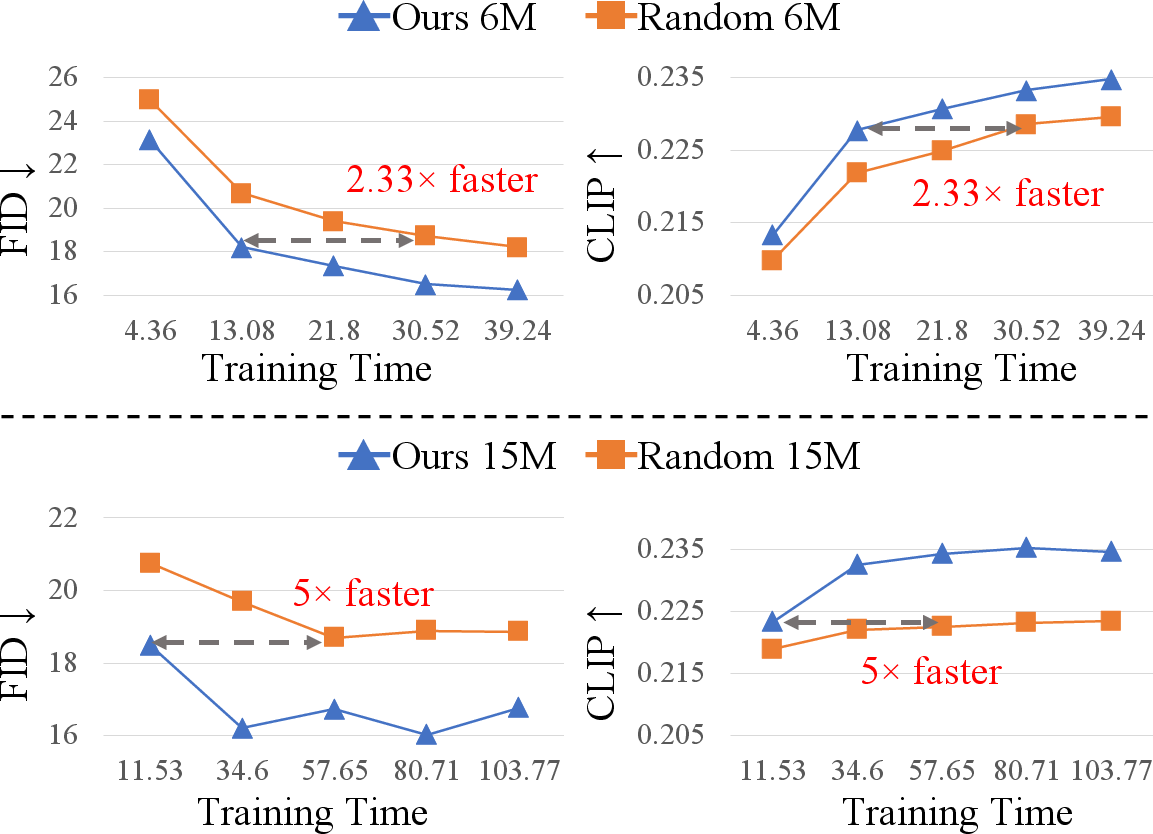
- Empirical results demonstrate up to 5× faster convergence and performance parity using only a fraction of the data compared to full-set training.
Alchemist: Meta-Gradient Data Selection for Text-to-Image Model Training
Overview and Motivation
Text-to-image (T2I) generative models, including architectures such as Imagen, Stable Diffusion, and FLUX, have established benchmarks for high-fidelity visual synthesis conditioned on natural language. However, the scalability and efficacy of these models are increasingly constrained by the quality and diversity of the underlying training data. Web-crawled and synthetic corpora, while vast, contain a preponderance of redundant or low-quality samples, which impairs generalization, introduces instability during optimization, and wastes computational resources. Conventional data curation strategies either rely on expensive manual filtering or static heuristic metrics and thus cannot efficiently scale or guarantee optimal downstream model performance.
Alchemist introduces a fully automatic, scalable, meta-gradient-based data selection pipeline customized for large-scale T2I training. By leveraging meta-optimization to dynamically assess sample importance and a novel data pruning strategy grounded in the gradient landscape, Alchemist achieves significant improvements in both convergence speed and generative performance, often surpassing models trained on the full dataset while utilizing only a fraction of the data.
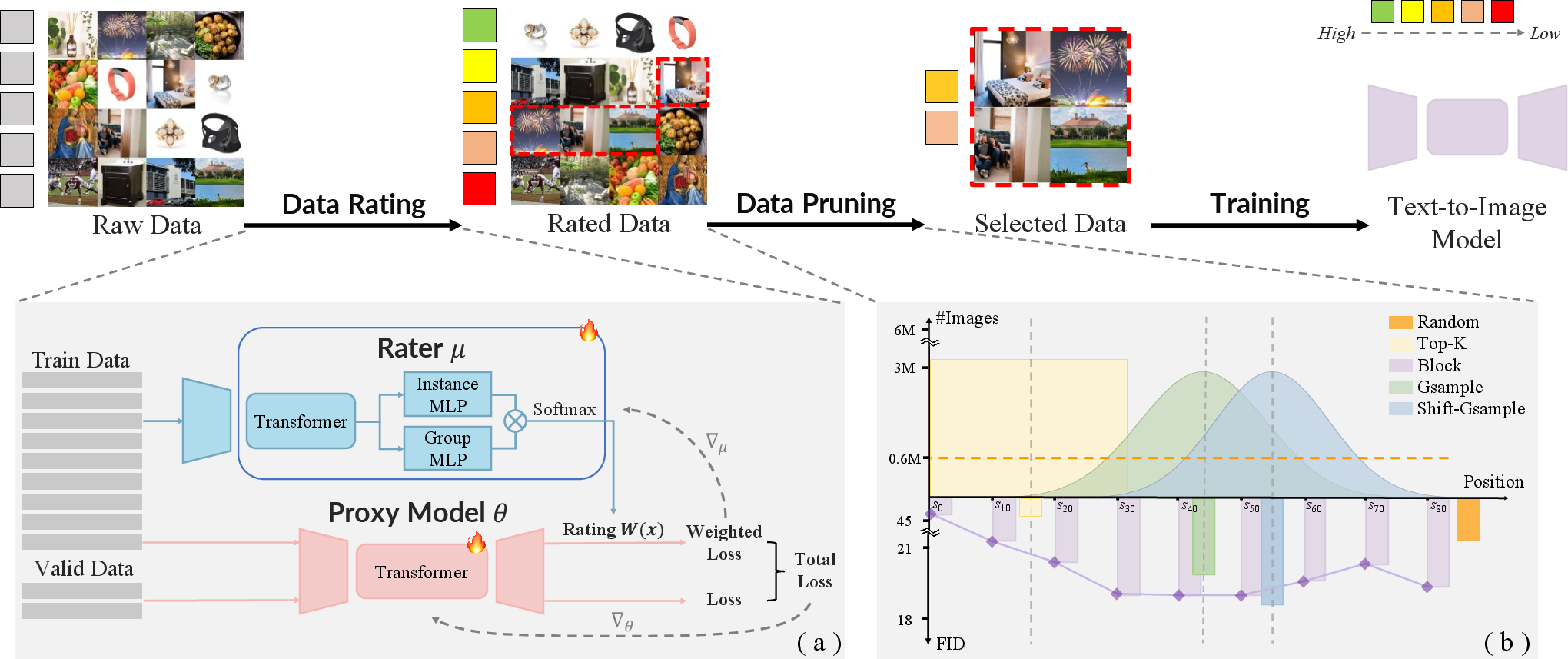
Figure 1: Alchemist's pipeline, comprising meta-gradient-based data rating followed by the Shift-Gsample pruning strategy, outputs a highly informative data subset optimized for downstream T2I training.
Methodology
Alchemist formalizes data selection as a bilevel meta-learning problem. A lightweight rater network is trained to predict the influence score for each image-text pair, where influence is defined as the reduction in validation loss attributable to the sample. The optimization consists of:
- An inner loop: A T2I proxy model is trained on the weighted training samples, where sample weights are provided by the rater.
- An outer loop: The rater's parameters are updated so as to minimize validation loss after inner loop updates.
This process avoids the computational intractability of exact bilevel optimization by approximating the meta-gradient via training unrolls of the proxy model. The rater operates on both instance and batch-level features (multi-granularity perception), leading to improved robustness against mini-batch variance and batch-dependent biases.
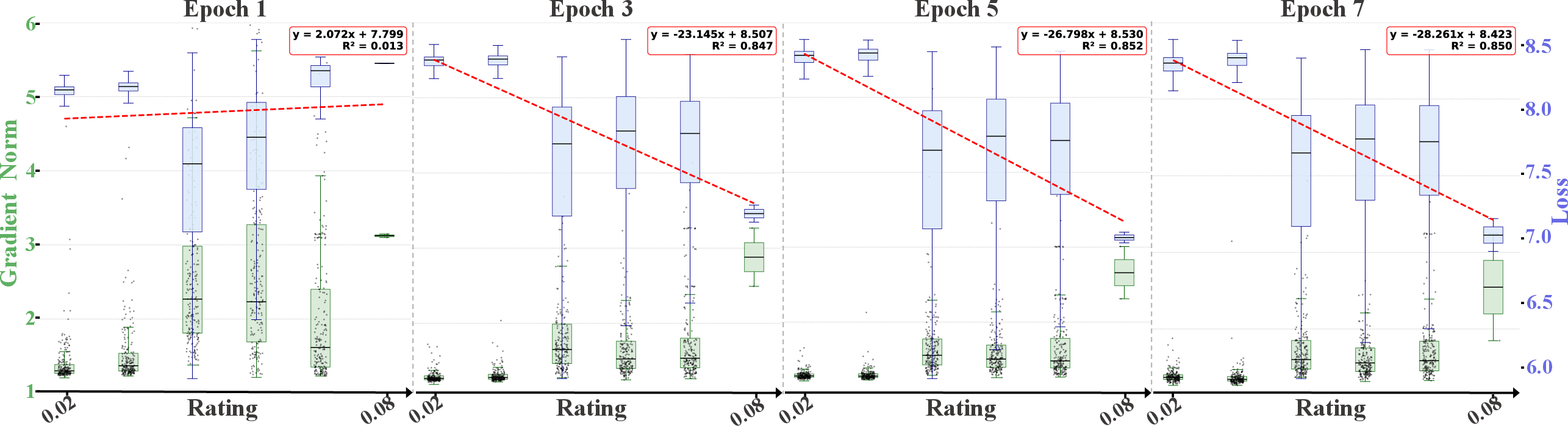
Figure 2: Distribution dynamics of loss and gradient norm across different rater-derived score regions, illustrating the informativeness of middle-to-late ranked samples.
Shift-Gsample Data Pruning
Unlike classic Top-K strategies, where only the highest-rated samples are retained, Alchemist empirically reveals that these "easiest" samples (often low-loss, low-gradient) contribute little to further learning as training progresses. The most valuable data reside in the middle-to-late segments of the score ranking, where samples induce larger and more dynamic gradient updates and are neither trivially easy nor pathological outliers.
Alchemist employs the Shift-Gsample strategy, which discards top-scoring samples and performs shifted Gaussian sampling over subsequent regions, centering on maximally informative examples while maintaining dataset diversity.

Figure 3: Qualitative examples illustrating that Alchemist predominantly retains semantically rich, visually diverse examples and discards plain or noisy samples.

Figure 4: Distributional analysis of Alchemist-selected data from LAION, which preferentially emphasizes mid-ranked, information-rich samples and minimizes low-value or noisy regions.
Empirical Evaluation
Comprehensive experiments deploying Alchemist across synthetic and web-crawled datasets (e.g., LAION-30M, HPDv3, Flux-reason) and a suite of T2I architectures (STAR family, FLUX-mini) demonstrate strong and consistent performance improvements.
Key empirical findings include:
Theoretical and Practical Implications
Alchemist provides rigorous evidence that naive data oversampling leads to substantial redundancy and ineffective resource utilization in T2I model scaling. The meta-gradient-based approach formalizes data value in terms of direct impact on validation loss, obviating reliance on classical but myopic quality metrics such as image clarity, text-image alignment, or aesthetics. Alchemist's approach advances the principle that training should be driven by downstream performance signal rather than heuristics, and that the most informative images are not those that are merely “high-quality” in a classical sense but those that stimulate meaningful model updates.
Integrating multi-granularity perception within the rater network further mitigates optimization stochasticity, providing a more consistent estimation of sample value in settings with substantial mini-batch noise. The Shift-Gsample strategy’s emphasis on middle distribution regions elegantly balances the learnability-diversity spectrum, preventing overfitting to simplistic exemplars and neglect of challenging yet educative cases.
Future Directions
Alchemist opens new lines of inquiry at the intersection of meta-learning, adaptive data curation, and efficient generative modeling. Further research could investigate:
- Large-scale adaptation: Extending meta-gradient curation to even larger training corpora and directly optimizing across evolving data distributions.
- Cross-modal selection: Applying Alchemist’s principles to other generative modalities, e.g., video, multimodal fusion, or large-scale language modeling.
- Joint model-data co-evolution: Co-designing architectures and data curriculums, possibly integrating Alchemist with active learning loops or semi-supervised self-training.
- Integration with scalable validation schemas: Leveraging rapidly evolving synthetic benchmarks or in-the-wild evaluation protocols to better tune proxy validation loss as a proxy for real-world generative utility.
Conclusion
Alchemist provides an advanced, automatic framework for meta-gradient-based selection of training data in text-to-image generation, supplanting both manual and static heuristic-based methods. Empirical results show consistent gains in quality, diversity, and convergence speed across domains and architectures. The methodology introduces a paradigm shift toward data-centric, performance-driven curation and lays a scalable foundation for future research in efficient generative modeling and dataset optimization (2512.16905).