Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning
Abstract: Supervised fine-tuning (SFT) on chain-of-thought data is an essential post-training step for reasoning LLMs. Standard machine learning intuition suggests that training with more unique training samples yields better generalization. Counterintuitively, we show that SFT benefits from repetition: under a fixed update budget, training for more epochs on smaller datasets outperforms single-epoch training on larger datasets. On AIME'24/25 and GPQA benchmarks, Olmo3-7B trained for 128 epochs on 400 samples outperforms the equivalent 1 epoch on 51200 samples by 12-26 percentage points, with no additional catastrophic forgetting. We find that training token accuracy reliably signals when repetition has saturated; improvements from additional epochs plateau at full memorization, a pattern consistent across all settings. These findings provide a practical approach for reasoning SFT, where scaling epochs with token accuracy as a stopping criterion can replace expensive undirected data scaling. We pose the repetition advantage, where full memorization coincides with improved generalization, as a new open problem for the community in understanding the training dynamics of LLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a common way to train reasoning AI models called supervised fine-tuning (SFT). In SFT, the model practices by reading lots of example problems and their full step-by-step solutions, called “chain-of-thought” (like showing your work in math). The surprise: the authors find that repeating a small set of high-quality examples many times works better than using a huge set only once, if you keep the total training effort the same.
What questions were the researchers trying to answer?
They asked very practical questions about how to get the most out of limited, expensive training data:
- If you have a fixed training effort (think: same “practice time”), is it better to see more unique examples once, or fewer examples many times?
- How many repeats (epochs) are helpful before improvements stop?
- Are there simple signals to know when to stop repeating?
- Does repeating make the model forget general knowledge?
- Does the quality of the data (and the “teacher” model that created it) change the result?
How did they test this?
Think of training as studying from a workbook:
- “Dataset size” = how many different problems are in the workbook.
- “Epochs” = how many times you re-read the same workbook.
- “Update budget” = total study time. They kept this fixed so the comparisons are fair.
Their approach:
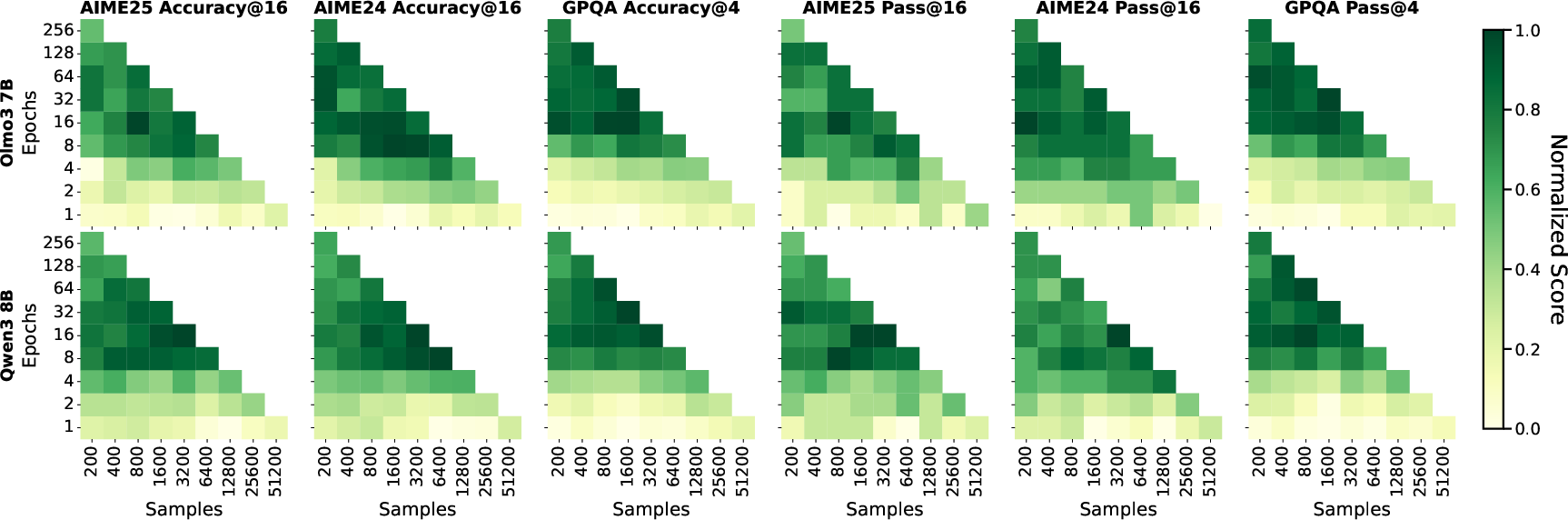
- They trained three LLMs (Olmo3-7B and Qwen3-4B/8B) using long, step-by-step solutions (chain-of-thought) across math, science, and general reasoning.
- They varied how many unique samples they used (from 200 to 51,200) and how many times they repeated them (from 1 to 256 epochs), while keeping total training steps the same.
- They tested the models on tough benchmarks:
- AIME 2024 and 2025 (math contest problems where answers are integers),
- GPQA (graduate-level multiple-choice questions in biology, physics, and chemistry).
- They measured:
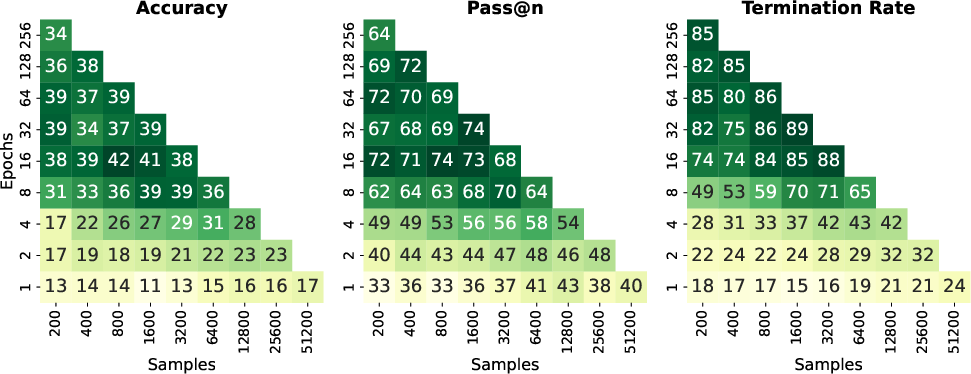
- Accuracy@n: average accuracy when trying n times per problem,
- Pass@n: whether at least one of n tries got the problem right,
- Termination rate: how often the model actually finishes its answer instead of stopping mid-stream.
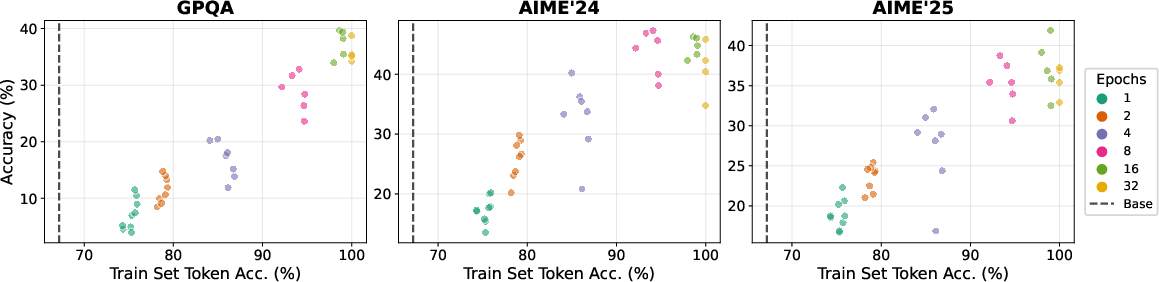
- They also tracked “token accuracy” on the training data, which is like checking how often the model predicts the next word of the training solution correctly—similar to knowing the homework answers word-for-word.
What did they find, and why does it matter?
Main findings:
- Repeating beats scaling: With the same training effort, “more repeats on a smaller set” consistently outperformed “one pass on a huge set.” For example, Olmo3-7B trained for 128 epochs on just 400 examples did 12–26 percentage points better than training on 51,200 examples only once.
- Improvements saturate: Gains keep rising up to around 32–64 epochs, then plateau.
- A simple stopping rule: Once the model reaches near-perfect token accuracy on the training set (it has “memorized” the examples), extra repeats stop helping. This makes token accuracy a practical “stop here” signal.
- Finishing matters: Models that repeat more often are much more likely to finish their reasoning and produce a final answer, which strongly links to higher accuracy.
- No extra forgetting: Repeating a small set many times did not cause worse “catastrophic forgetting” (losing general knowledge) than training once on a huge set. In fact, repeat training often forgot less, while improving reasoning more.
- Data quality shapes the ceiling: Using higher-quality teacher models to create training solutions raises overall performance. However, the “repetition advantage” holds even when the teacher is weaker.
- Even wrong solutions help: Training on incorrect chain-of-thought solutions did not hurt—sometimes it even helped. Likely because these come from harder problems, and practicing tough reasoning attempts can still build skill.
Why it matters:
- Long chain-of-thought data is costly to create or collect. This paper shows you can get better results by repeating good examples, saving time and money.
- Token accuracy gives a clear signal to stop training, preventing waste.
- It challenges the usual “more unique data is always better” intuition for this specific training stage.
What’s the bigger picture?
This study suggests a practical recipe for training reasoning AI:
- Pick a small, high-quality set of step-by-step solutions.
- Train for many epochs, watching token accuracy on the training set.
- Stop when token accuracy saturates (near 100%).
- Expect strong gains in reasoning quality and better chance of finishing answers, without extra forgetting.
It also raises an open scientific question: Why does full memorization of training examples go hand-in-hand with better generalization on new problems in this setting? Understanding this could help us design even more efficient training strategies and make advanced reasoning AI accessible to more groups with limited data and compute.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Mechanism: The causal explanation for why repeated exposure (multi-epoch SFT) improves generalization in long-CoT remains unknown; isolate and test candidate mechanisms (e.g., termination learning, entropy minimization, representation consolidation, gradient noise scale effects).
- Token-accuracy stopping rule: Generality of using training token accuracy saturation as a stopping criterion is unvalidated across datasets, domains, languages, and larger models; test whether a fixed threshold reliably predicts convergence and optimal epoch count.
- Compute matching: Update budget equality (epochs × samples, batch size 1) does not control for total training tokens or sequence lengths per update; re-run with compute matched by tokens processed to rule out confounds from variable sequence lengths.
- LR and schedule sensitivity: Learning rate was chosen from 1-epoch runs and reused; re-optimize LR, warmup, and scheduler per epoch–dataset configuration to ensure repetition advantage is not a hyperparameter artifact.
- Batch size dependence: All experiments use batch size 1; evaluate whether the repetition advantage holds for larger batch sizes and gradient accumulation, and whether gradient noise scale mediates the effect.
- Decoding hyperparameters: Results rely on “recommended” sampling parameters; systematically ablate temperature, nucleus/top-p/top-k, max tokens, and termination rules to quantify sensitivity and to test whether improved termination alone explains gains.
- Forced termination tests: Directly intervene at decoding (e.g., constrained decoding, forced EOS, answer-format enforcement) to quantify how much of the accuracy gain is attributable to improved termination behavior versus improved reasoning.
- Memorization measurement: Token accuracy is measured on a 200-sample subset; validate conclusions by computing on the full train set and by alternative memorization probes (exact-match, influence functions, gradient-based memorization metrics).
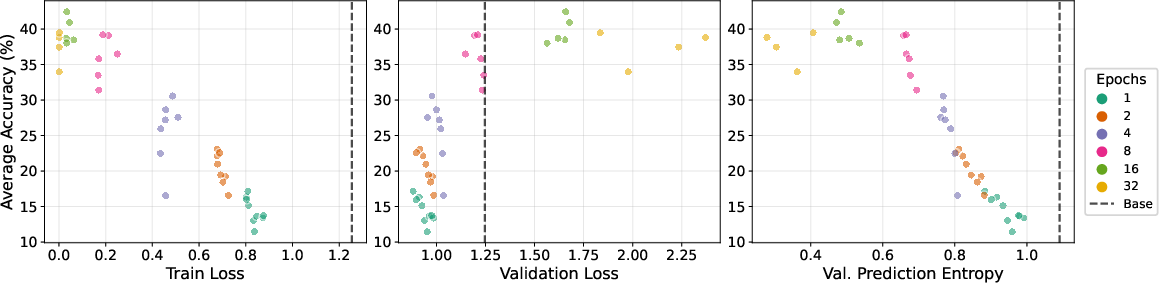
- Overfitting paradox: Why validation loss rises while downstream accuracy improves remains unresolved; test distribution mismatch hypotheses by constructing validation sets matched to benchmark domains or by measuring domain-wise losses.
- Generality across domains: Benchmarks focus on AIME’24/’25 and GPQA; extend to diverse reasoning tasks (e.g., GSM8K, MATH500, CS coding, scientific proofs, commonsense) to assess domain coverage and limits.
- Model scale: Only 4B–8B–7B models are tested; evaluate whether the repetition advantage scales to 30B–70B and beyond, including mixture-of-experts architectures and different pretraining corpora.
- Instruction-tuned starting points: The paper uses base (pre-instruction) checkpoints; test whether the effect persists or changes when starting from instruction-tuned or RL-finetuned checkpoints.
- Multilingual and multimodal: Examine whether repetition advantage holds for multilingual SFT and multimodal reasoning traces (vision, code execution traces).
- Safety and alignment: Effects on safety, toxicity, factuality, calibration, and refusal behaviors are not assessed; measure safety/harms trade-offs under epoch scaling versus data scaling.
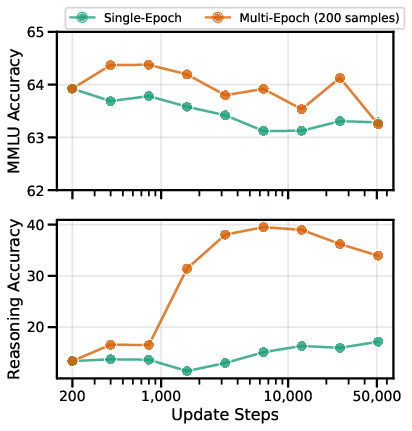
- Catastrophic forgetting breadth: Forgetting is measured only on MMLU; evaluate broader capability retention (reading comprehension, factual QA, coding, summarization, translation) and calibration under repetition.
- Data leakage: No formal leakage analysis between SFT data and benchmarks; audit overlap (problems, solutions, templates) to ensure gains are not inflated by contamination.
- Dataset selection bias: Nested random splits use a single RNG seed (42); replicate across multiple seeds and non-nested sampling to rule out selection bias (e.g., math-heavy subsets).
- Data quality gradients: Teacher-quality analysis is limited to two teacher sizes; further map how correctness rates, chain length, structure, and noise levels interact with repetition and peak performance.
- Negative trajectories: While training on negatives did not harm performance, it remains unclear why; quantify problem difficulty, wrong-answer types, and whether negative reasoning induces harmful biases or error modes.
- Optimal dataset size: The paper notes dataset-size optimality is data- and model-dependent; develop principled criteria or estimators (e.g., curvature, gradient noise scale, domain match) to choose size before training.
- Sequence length effects: Long-CoT samples vary widely (up to 10k tokens); analyze how average/variance in sequence length affects repetition advantage and whether shorter/longer traces benefit differently.
- EOS and formatting conventions: Gains may depend on learning structural conventions (> tags, \boxed{} answers); test removal or alteration of tags and answer-format instructions to gauge reliance on formatting.
Loss design: Only cross-entropy on response tokens is used; compare against alternative objectives (KL to teacher, label smoothing, entropy penalties, consistency training) to see if repetition advantage is objective-specific.
- Optimizer and precision: Results use 8-bit Adam with bfloat16 and Unsloth kernels; ablate optimizer type (AdamW, Adafactor), precision, and gradient clipping to assess robustness.
- Warmup fraction: Warmup is 10% of total updates for all runs; test different warmup fractions, cosine vs linear schedules, and per-epoch resets to disentangle schedule–epoch interactions.
- Termination learning dynamics: The strong termination–accuracy correlation is described but not mechanistically probed; instrument models to track EOS logits over time and evaluate causality via targeted training on end-of-reasoning patterns.
- RL compatibility: Downstream impact on subsequent RL phases (RLHF/RLAIF/verifiable rewards) is unknown; compare final RL performance, sample efficiency, and stability when starting from repeated-small SFT vs single-pass-large SFT.
- Test-time scaling interactions: Interaction with s1/simple test-time scaling and other sampling-time methods is not studied; evaluate whether repetition SFT complements or substitutes for test-time scaling.
- Curriculum and replay effects: Investigate whether repetition advantage arises from implicit curriculum/replay on consistent patterns; contrast fixed-repetition vs stochastic re-sampling and schedule-based replay.
- Calibration and uncertainty: Entropy decreases with epochs, but calibration is not measured; assess calibration (ECE/Brier), confidence in wrong answers, and whether repetition induces overconfidence.
- Long-horizon robustness: Stability across longer training horizons and budgets beyond 51,200 updates is not explored; map performance/forgetting curves over much larger compute and mixed epoch–data schedules.
- Hardware and reproducibility: All runs use a single H100; test reproducibility across hardware, software stacks, and multiple seeds; publish full configs for deterministic re-runs.
- Practical recipe: While token-accuracy saturation is proposed as a stopping rule, a full operational recipe (target token-accuracy threshold, recommended epoch ranges per model size/domain, early-stop safeguards) is not provided; develop and validate such guidelines.
Glossary
- 8-bit Adam optimizer: A memory-efficient variant of Adam that quantizes optimizer states to 8 bits to reduce memory and bandwidth during training. "We load models in bfloat16, use Unsloth optimized kernels \cite{unsloth}, and the 8-bit Adam optimizer \cite{dettmers2022optimizers} with a cosine learning rate schedule."
- Acc@: An evaluation metric that averages accuracy over n independent generations per problem. "We report three metrics: Acc@, the accuracy averaged over independent generations per problem;"
- AIME: The American Invitational Mathematics Examination, used here as a rigorous math reasoning benchmark. "AIME \cite{aops_aime_problems_solutions_2025} is a mathematical reasoning benchmark consisting of 30 competition problems per year, requiring multi-step reasoning across algebra, geometry, number theory, and combinatorics; each answer is an integer from 0 to 999."
- Behavioral cloning: An imitation learning approach where a model learns to mimic demonstrated behavior. "This SFT step, analogous to behavioral cloning in reinforcement learning \cite{osa2018imitation}, primes the model for subsequent stages such as reinforcement learning from human feedback \cite{ouyang2022instructgpt} or reinforcement learning with verifiable rewards \cite{guo2025deepseekr1, deepseek-math}."
- bfloat16: A 16-bit floating-point format with a wider exponent than FP16, enabling efficient training without as much numeric underflow. "We load models in bfloat16, use Unsloth optimized kernels \cite{unsloth}, and the 8-bit Adam optimizer \cite{dettmers2022optimizers} with a cosine learning rate schedule."
- Chain-of-Thought (CoT): Explicit multi-step reasoning traces included in demonstrations to guide model reasoning. "For reasoning-focused models, post-training typically begins with supervised fine-tuning (SFT) on long Chain-of-Thought (CoT) demonstrations, often distilled from more capable models, where reasoning traces can span thousands of tokens before reaching a final answer."
- Cosine learning rate schedule: A learning-rate schedule that decays following a cosine curve to improve optimization stability. "We load models in bfloat16, use Unsloth optimized kernels \cite{unsloth}, and the 8-bit Adam optimizer \cite{dettmers2022optimizers} with a cosine learning rate schedule."
- Cross-entropy loss: The standard token-level objective for next-token prediction in language modeling. "SFT minimizes the cross-entropy loss over next-token predictions:"
- Diffusion LLMs: Models trained with diffusion objectives for text, which can leverage repeated data differently from autoregressive training. "Relatedly, recent work on diffusion LLMs shows that, in data-constrained pretraining regimes, extensive data repetition can be beneficial, with diffusion objectives extracting substantially more value per unique token than autoregressive training \citep{ni2025superdatalearner}."
- End-of-sequence token: A special token used to mark the end of generated output sequences. "Termination, the fraction of generations that conclude with an end-of-sequence token rather than being truncated."
- Entropy minimization: A fine-tuning strategy that encourages lower predictive uncertainty to elicit confident reasoning behavior. "This view aligns with recent work on entropy minimization in fine-tuning \cite{agarwal2025entropy}"
- GPQA: A graduate-level multiple-choice reasoning benchmark covering biology, physics, and chemistry. "GPQA \cite{rein2024gpqa} is a graduate-level multiple-choice benchmark with expert-written questions in biology, physics, and chemistry, where the model must reason through the problem before selecting from four options."
- MMLU: Massive Multitask Language Understanding, a broad knowledge benchmark across 57 subjects. "we measure performance on MMLU \cite{hendrycks2021mmlu}, a broad knowledge benchmark spanning 57 subjects."
- Negative trajectories: Chain-of-thought demonstrations where the final answer is incorrect. "We define negative trajectories as chain-of-thought samples where the model's final answer is incorrect."
- Pass@: A metric indicating whether at least one of n sampled generations solves the problem. "Pass@, the fraction of problems solved in at least one of attempts;"
- Prediction entropy: The average token-level entropy of the model’s output distribution, reflecting confidence and uncertainty. "We also measure prediction entropy on the validation set, defined as the average token-level entropy of the model's output distribution."
- Reinforcement learning from human feedback (RLHF): A fine-tuning approach where models are optimized using human-provided preference or reward signals. "This SFT step, analogous to behavioral cloning in reinforcement learning \cite{osa2018imitation}, primes the model for subsequent stages such as reinforcement learning from human feedback \cite{ouyang2022instructgpt} or reinforcement learning with verifiable rewards \cite{guo2025deepseekr1, deepseek-math}."
- Reinforcement learning with verifiable rewards: An RL approach where rewards are computed via automatic verification (e.g., checking correctness of final answers). "This SFT step, analogous to behavioral cloning in reinforcement learning \cite{osa2018imitation}, primes the model for subsequent stages such as reinforcement learning from human feedback \cite{ouyang2022instructgpt} or reinforcement learning with verifiable rewards \cite{guo2025deepseekr1, deepseek-math}."
- Scaling laws: Empirical regularities describing how performance scales with model size, data, and compute. "Scaling laws for LLM pretraining characterize how validation loss improves predictably with increased model size, total training tokens, and compute \citep{kaplan2020scalinglaws,hoffmann2022chinchilla}."
- Supervised fine-tuning (SFT): Post-training stage where a pretrained model is trained on demonstrations to elicit target behaviors. "Supervised fine-tuning (SFT) on chain-of-thought data is an essential post-training step for reasoning LLMs."
- Teacher model: A stronger model used to generate distilled demonstrations for training a student model. "generate solutions using reasoning checkpoints of Qwen3-0.6B and Qwen3-8B as teacher models."
- Termination rate: The proportion of generations that successfully end with an EOS token, affecting the ability to produce final answers. "Termination rate correlates strongly with accuracy and may be a primary driver of performance gains, as models that fail to terminate cannot produce a final answer."
- Token accuracy: The fraction of response tokens where the model’s top prediction matches the target; used as a memorization/convergence signal. "Token accuracy measures the fraction of response tokens where the model's top prediction matches the training target."
- Update budget: The total number of gradient updates used in training, often computed as epochs × unique samples. "Throughout this work, we use update budget to denote the total number of gradient updates during training, which for batch size one is equal to the number of epochs multiplied by the number of unique samples."
- vLLM: An efficient LLM serving and inference system used for large-scale generation. "We use recommended sampling parameters from each model's technical report and vLLM \cite{kwon2023efficient} for efficient inference."
- Warmup: An initial training phase where the learning rate is gradually increased to stabilize optimization. "Warmup is set to 10\% of the total update budget for each run."
- Weak-to-strong generalization: A phenomenon where training with weaker teacher data can initially help but later harm stronger student performance. "This pattern echoes findings in weak-to-strong generalization \cite{w2s}, where student models trained on weaker teacher data can initially exceed teacher performance but degrade with prolonged exposure."
Practical Applications
Overview
The paper demonstrates that, in supervised fine-tuning (SFT) of reasoning-focused LLMs on long chain-of-thought (CoT) data, repeating a smaller, high-quality dataset for many epochs consistently outperforms training once on a much larger set under a fixed update budget. It also introduces practical signals and levers—training token accuracy as a stopping criterion and termination rate as a key quality metric—while showing limited risk of additional catastrophic forgetting and surprising robustness to incorrect (negative) trajectories. Below are concrete applications derived from these findings.
Immediate Applications
- Efficient reasoning SFT pipelines for LLM teams (Software/AI)
- Replace “collect more SFT data” with “curate 200–3,200 high-quality CoT samples and train 16–64+ epochs,” using token accuracy to stop when memorization saturates. Delivers large gains on reasoning benchmarks under the same compute.
- Dependencies/assumptions: Long-CoT supervision; access to base checkpoints with latent reasoning ability; monitoring infra for token-accuracy and termination; safe domains for CoT use.
- Token-accuracy early stopping and training dashboards (MLOps/Tooling)
- Add a simple training monitor that computes token-level accuracy on a small, fixed train subset; stop when it plateaus near 100%. Track termination rate alongside task metrics for reliable model selection.
- Dependencies/assumptions: Instrumentation to evaluate on masked response tokens; standardized chat templates; reproducible subsets.
- Termination-aware training and decoding (Software/Inference)
- Incorporate termination rate into acceptance criteria and decoding workflows (e.g., insist on end-of-sequence completion; penalize non-terminating outputs during SFT). Expect fewer hung generations and more parsable final answers.
- Dependencies/assumptions: Task formats with explicit termination conventions; inference stack control (e.g., vLLM).
- Cost- and data-compliance friendly SFT (Industry/Policy)
- Shift emphasis from scaling unique SFT samples to curation and repetition—lower data procurement costs, better data governance (fewer unique records to vet), reduced privacy risk.
- Dependencies/assumptions: Legal clearance for repeated exposure to curated sets; processes for quality vetting and de-duplication.
- Small-cohort domain adapters for regulated reasoning (Healthcare, Finance, Legal)
- Build domain-specific reasoning adapters using a few hundred carefully validated CoT cases, repeated over many epochs; use token-accuracy convergence to minimize compute and risk.
- Dependencies/assumptions: Expert-verified CoT traces; strict safety QA; recognition that negative trajectories were benign in math but may be unsafe in clinical/legal settings if unfiltered.
- Education-focused tutors and graders from limited exemplars (Education)
- Develop math/logic tutors by repeating a few hundred teacher-written worked solutions; improved reasoning and consistent final answers without collecting large corpora.
- Dependencies/assumptions: Quality solutions with clear reasoning and answer conventions; appropriate CoT privacy and pedagogy choices (e.g., hide CoT at inference if required).
- Code reasoning assistants trained on curated traces (Software/DevTools)
- Fine-tune models on a small set of high-quality code reasoning and debugging traces; repetition improves structured reasoning and the likelihood of producing a complete fix.
- Dependencies/assumptions: High-quality code-CoT traces; task templates that encourage explicit final outputs (patch, diff, or summary).
- Hard-example mining via negative trajectories (R&D/Industry)
- Use incorrect-but-informative traces to diversify training difficulty when data is scarce; combine with repetition for gains similar to or exceeding positive-only sets in math-like domains.
- Dependencies/assumptions: Robust filters to avoid harmful or misleading negatives in sensitive domains; evaluation safeguards.
- Updated model selection: de-emphasize validation loss for reasoning SFT (Academia/Industry)
- Use downstream task accuracy and termination over validation loss/entropy, which may trend “worse” even as reasoning improves with repetition.
- Dependencies/assumptions: Access to representative downstream evals; acceptance of task-centric early stopping.
Long-Term Applications
- Auto-curricula and repetition schedulers for post-training (Software/AI)
- Build “RepeatTune” schedulers that dynamically choose epochs vs. unique samples using token accuracy and termination signals; integrate into SFT→RLHF/R1 pipelines.
- Dependencies/assumptions: Generalization of signals across tasks; compatibility with RL phases; robust automation.
- Generalization to high-stakes reasoning with verification layers (Healthcare, Legal, Safety)
- Apply repetition advantage to build smaller, auditable adapters, paired with verifiable rewards or strict validators to safeguard against errors from negative trajectories.
- Dependencies/assumptions: Access to verifiers/validators; domain-specific safety tooling; regulatory approval.
- On-device or edge personalization via micro-SFT (Consumer/Privacy)
- Personal assistants fine-tuned locally on tens–hundreds of user examples (e.g., task workflows, email triage) with multi-epoch repetition and token-accuracy stopping.
- Dependencies/assumptions: Efficient adapters (LoRA/QLoRA), memory/compute budget on-device, privacy-preserving data handling.
- Multimodal and robotics reasoning (Robotics/Autonomy)
- Port the repetition principle to language-conditioned planning and multimodal chains-of-thought (e.g., few high-quality demonstrations repeated); explore termination analogs (e.g., plan completion).
- Dependencies/assumptions: Well-defined “termination” signals; safe sim-to-real transfer; alignment with imitation learning objectives.
- Data-procurement standards that prioritize curation over scale (Policy/Procurement)
- Update guidelines to reward data quality and transparency of CoT sources; encourage smaller, validated corpora with repetition in public-sector or enterprise model development.
- Dependencies/assumptions: Stakeholder buy-in; metrics and audits for quality; reproducibility standards.
- Theory- and metric-driven SFT diagnostics (Academia)
- Develop theory on why full memorization coincides with better generalization in reasoning SFT; new diagnostics beyond validation loss (e.g., structural reasoning metrics, termination reliability).
- Dependencies/assumptions: Open benchmarks and datasets; cross-lab replication; standardized tooling.
- Curriculum design using mixed positive/negative trajectories (Academia/Industry)
- Systematically blend correct and incorrect long-CoT traces to induce robust reasoning under scarcity; characterize when negatives help vs. harm.
- Dependencies/assumptions: Difficulty calibration; robust labeling of correctness; domain-specific safety controls.
- Safer post-training through reduced catastrophic forgetting (Safety/AI Alignment)
- Leverage epoch scaling’s lower forgetting to preserve general capabilities during specialization, reducing regression risks as models are adapted for verticals.
- Dependencies/assumptions: Continuous evaluation (e.g., MMLU or broader capability suites); guardrails for drift.
- Tooling products and plugins (Software/MLOps)
- “Token-Accuracy Early Stopper,” “Termination Meter,” and “Epoch–Sample Optimizer” integrated with vLLM/Unsloth stacks; CI/CD recipes for small-batch, multi-epoch SFT.
- Dependencies/assumptions: Integration with training/inference stacks; accessible metrics APIs; UX for data scientists.
Each application assumes the findings’ current evidence base: long-CoT SFT on 4B–8B class models and reasoning-heavy tasks. Extending to other tasks or larger models likely requires validation. In safety-critical domains, correctness assurance and verification must supersede the observed tolerance to negative trajectories seen in math benchmarks.
Collections
Sign up for free to add this paper to one or more collections.