- The paper introduces P1-VL, a framework that integrates vision-language processing with curriculum RL to enable Olympiad-level physics reasoning.
- It employs a rigorously curated multimodal dataset and advanced optimization techniques like GSPO and Seq-MIS to enhance symbolic and visual problem solving.
- Empirical results show P1-VL outperforms leading models in STEM reasoning, achieving top benchmark rankings and demonstrating robust generalization.
P1-VL: Visual Perception and Scientific Reasoning in Olympiad Physics
Motivation and Problem Setting
The intersection of multimodal perception and advanced scientific reasoning represents a critical threshold for the capability of LLMs. Physics Olympiads present a comprehensive challenge for these models: solutions require bridging abstract symbolic manipulation with spatial, geometric, and causal information encoded in diagrams, figures, and visual representations. Previous LLM systems demonstrated proficiency in textual reasoning but systematically failed to extract and utilize diagrammatic constraints that are essential for correct problem-solving at the Olympiad level. The P1-VL model family addresses this gap by explicitly unifying vision-language processing and science-centric RL training to enable genuine physics reasoning.

Figure 1: Example Olympiad question requiring bubble radius measurement and velocity estimation directly from visual input, illustrating the necessity for integrated visual-logical processing.
Dataset Composition and Multimodal Curation
P1-VL’s training corpus comprises 8,033 rigorously curated multimodal problems, spanning Olympiad competitions, undergraduate textbooks, and image-rich exercises. The dataset includes detailed solution annotations, symbolic expressions, and a wide variety of figures—allowing models to learn both visual-to-symbolic mapping and multi-step scientific derivations.
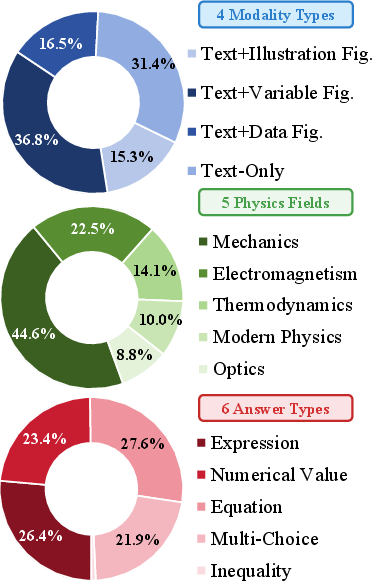
Figure 2: Visualization of the training data distribution across problem types and sources.
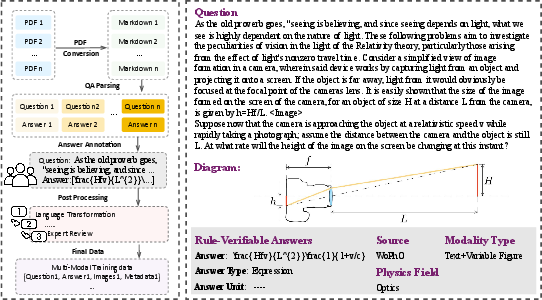
Figure 3: Overview of the data collection pipeline, detailing multimodal extraction, annotation, and iterative quality filtering.
Quality control employs sequential model-based verification, automated filtering of OCR artifacts, semantic consistency checks, and expert review, yielding a dataset with high fidelity for curriculum RL training.
Training Paradigm: Curriculum RL with Stabilization
RL post-training is performed exclusively on RLVR (reinforcement learning with verifiable rewards), formalized as a sequence-level Markov Decision Process. P1-VL leverages Group Sequence Policy Optimization (GSPO) to target sequence-level optimization with length-normalized importance ratios. The reward aggregation and answer extraction mechanisms are tailored for symbolic, multi-box answers in LaTeX, ensuring precise derivation and evaluation.
Training proceeds in a curriculum fashion:
- Difficulty Expansion: The dataset is filtered to remove trivial samples and recover malformed cases. Curriculum stages progressively prune easier samples, increasing the optimization focus on challenging reasoning tasks.
- Exploration Scaling: Generation window and group size are expanded as curriculum difficulty increases, providing sufficient search depth for hard-tail distribution problems.
- Train-Inference Mismatch Mitigation: Instability arising from engine discrepancies is neutralized using Sequence-Level Masked Importance Sampling (Seq-MIS), ensuring consistent policy updates and preventing catastrophic RL collapse.
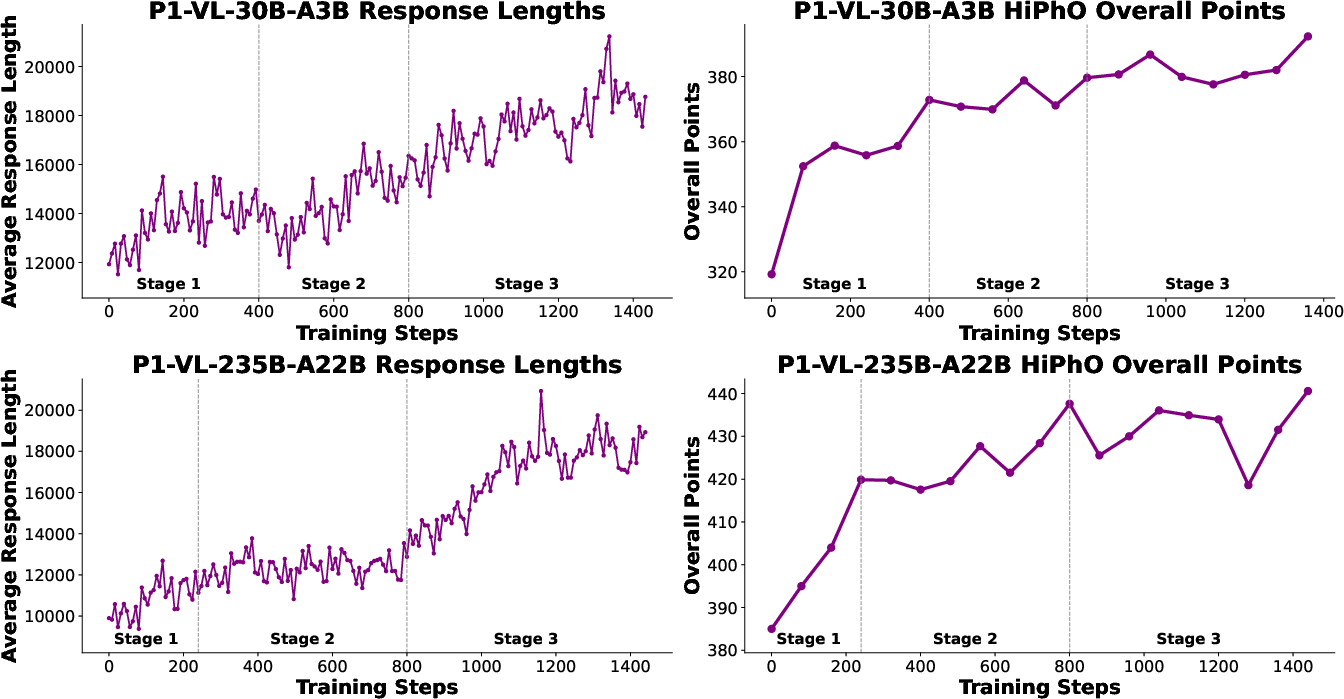
Figure 4: Training dynamics for both P1-VL variants, demonstrating steady improvement in reasoning depth and exam scores as curriculum and exploration settings are scaled.
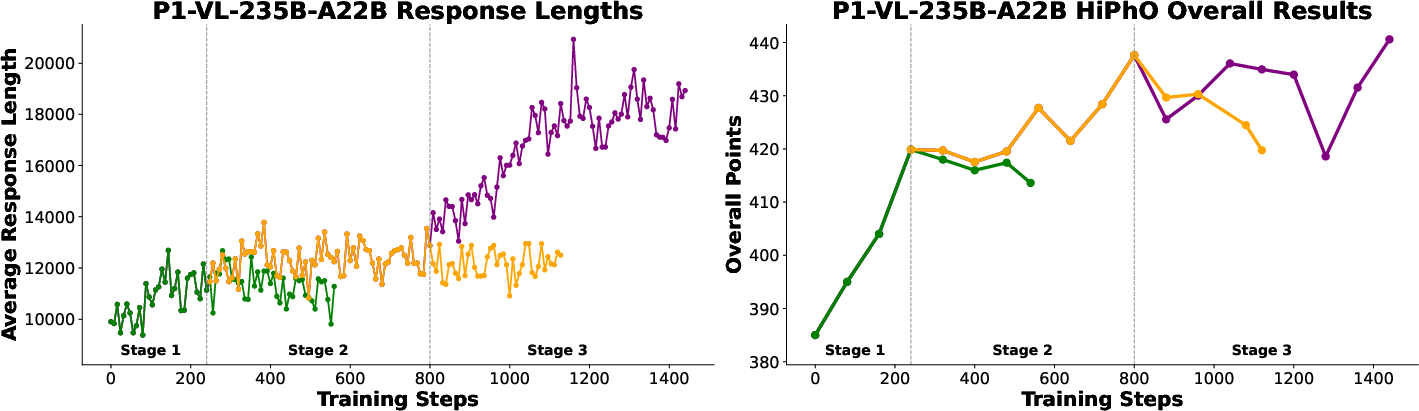
Figure 5: Comparative training dynamics with and without curriculum difficulty expansion, evidencing the necessity of structured curriculum for reasoning maturity.
Model Architecture and Agentic Augmentation
P1-VL models are initialized from large-scale vision-language foundations (Qwen3-VL), with vision encoder and projection layer frozen during RL. All samples—regardless of modality—are standardized for unified input processing, facilitating cross-modal reasoning and minimizing modality-specific catastrophic forgetting.
At inference, the PhysicsMinions agent framework is activated, fully leveraging the integrated visual processing pipeline. Multistage agentic augmentation enables iterative solution refinement, symbolic translation from diagrams, and domain-adaptive reasoning workflows. The agent framework is dynamically routed—depending on discipline—to optimal solver-verifier compositions (physics, chemistry, biology), and applies closed-loop reasoning for robust problem-solving.
Empirical Results: Olympiad-Level Physics Reasoning
P1-VL achieves state-of-the-art open-source performance on the HiPhO Olympiad benchmark, securing 12 gold medals (P1-VL-235B-A22B) and ranking third overall behind only Gemini-3-Pro and GPT-5.2. The mid-scale variant (P1-VL-30B-A3B) demonstrates high parameter efficiency, outperforming heavier open and closed-source baselines. When agentically augmented (P1-VL-235B-A22B+PhysicsMinions), the system ascends to second global rank and achieves top scores in several Olympiads.
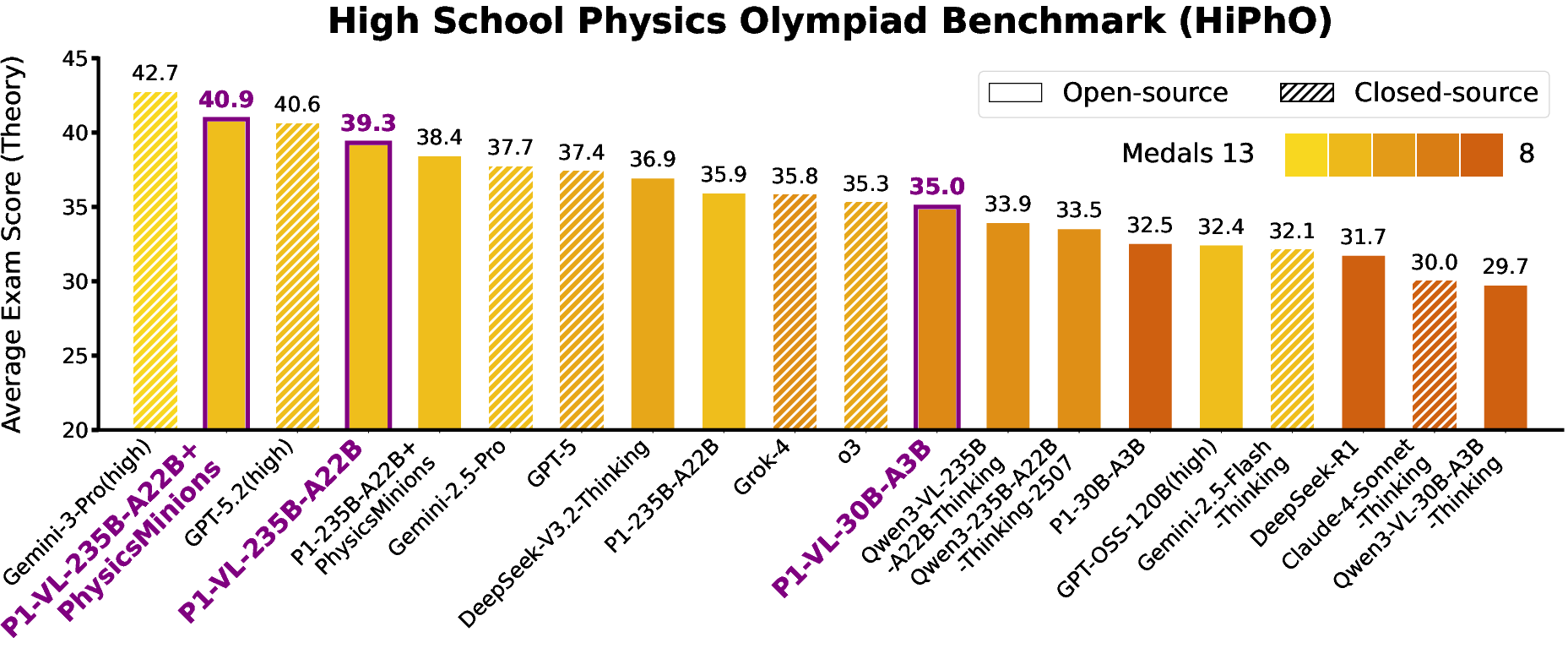
Figure 6: Summary of HiPhO rankings, with P1-VL variants outperforming most open-source VLMs; agentic augmentation additionally boosts performance.
Generalization and Out-of-Domain Reasoning
Domain adaptation does not compromise general STEM reasoning. P1-VL demonstrates significant positive transfer on the FrontierScience-Olympiad benchmark, achieving consistent gains across biology, chemistry, and physics, and outperforming base models even in text-only modalities. Notably, on rigorous math reasoning tests (AMOBench, MathArena, IMO-AnswerBench), P1-VL shows marked improvements, confirming scientific reasoning enhancements extend beyond physics.
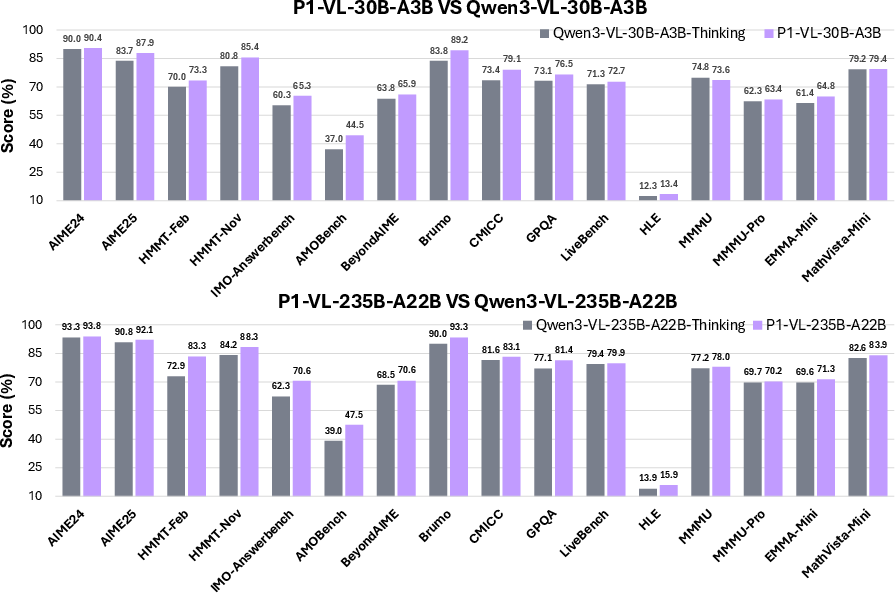
Figure 7: Comprehensive out-of-domain evaluation reveals consistent superiority of P1-VL variants in both text and multimodal STEM tasks.
Ablation Analyses
P1-VL’s stability stems from curriculum RL and effective importance sampling: without curriculum difficulty scaling, models stagnate and fail to achieve deep reasoning (Figure 5). Train-inference mismatch is catastrophic unless Seq-MIS is applied; standard token-level truncation is insufficient. Blank image padding allows seamless training on mixed modalities without negative transfer, further supporting mixed multimodal datasets.
Practical and Theoretical Implications
The P1-VL framework sets a new standard for physics-oriented VLMs, demonstrating that post-training reinforcement learning—when harmonized with curriculum difficulty expansion, agentic augmentation, and stable policy optimization—enables models to internalize complex scientific reasoning and bridge visual-logical processing.
Practically, the results indicate these systems are approaching reliable embodied physical intelligence. In agentic contexts, domain-adaptive pipelines unlock generalizable reasoning on heterogeneous scientific tasks. Theoretically, P1-VL’s advances pave the way for machine scientific discovery, grounded in robust world models and interpretable symbolic logic.
Conclusion
P1-VL represents the first open-source VLM family capable of competition-level proficiency in multimodal scientific reasoning on Olympiad physics problems. The dual framework of curriculum RL and agentic augmentation establishes not only physics mastery but also robust generalization across STEM disciplines. These developments accelerate the convergence of machine intelligence and scientific discovery, providing foundational models for future embodied and general-purpose AI.