- The paper demonstrates that advanced MLLMs consistently score near chance levels (around 54%) on intuitive physics tasks using GRASP and IntPhys 2.
- A probing analysis reveals that while vision encoders efficiently capture physical cues, their integration into language models is inadequate for complex reasoning.
- The study emphasizes the need for improved vision-language alignment to enhance MLLMs' capabilities in distinguishing plausible from implausible physical scenarios.
Probing Intuitive Physics Understanding in MLLMs
This essay explores the systematic evaluation of state-of-the-art multimodal LLMs (MLLMs) on intuitive physics tasks as presented in the paper titled "Pixels to Principles: Probing Intuitive Physics Understanding in Multimodal LLMs." The study employs the GRASP and IntPhys 2 datasets to assess models such as InternVL 2.5, Qwen 2.5 VL, LLaVA-OneVision, and Gemini 2.0 Flash Thinking, highlighting the persistent challenges these models face in distinguishing physically plausible from implausible scenarios.
Evaluation of Multimodal LLMs
The paper examines MLLMs' capabilities in reasoning about intuitive physics using datasets that consist of simulated videos. The findings indicate that even advanced MLLMs struggle with tasks that require distinguishing between plausible and implausible physics scenarios, showing performance only marginally above chance levels.
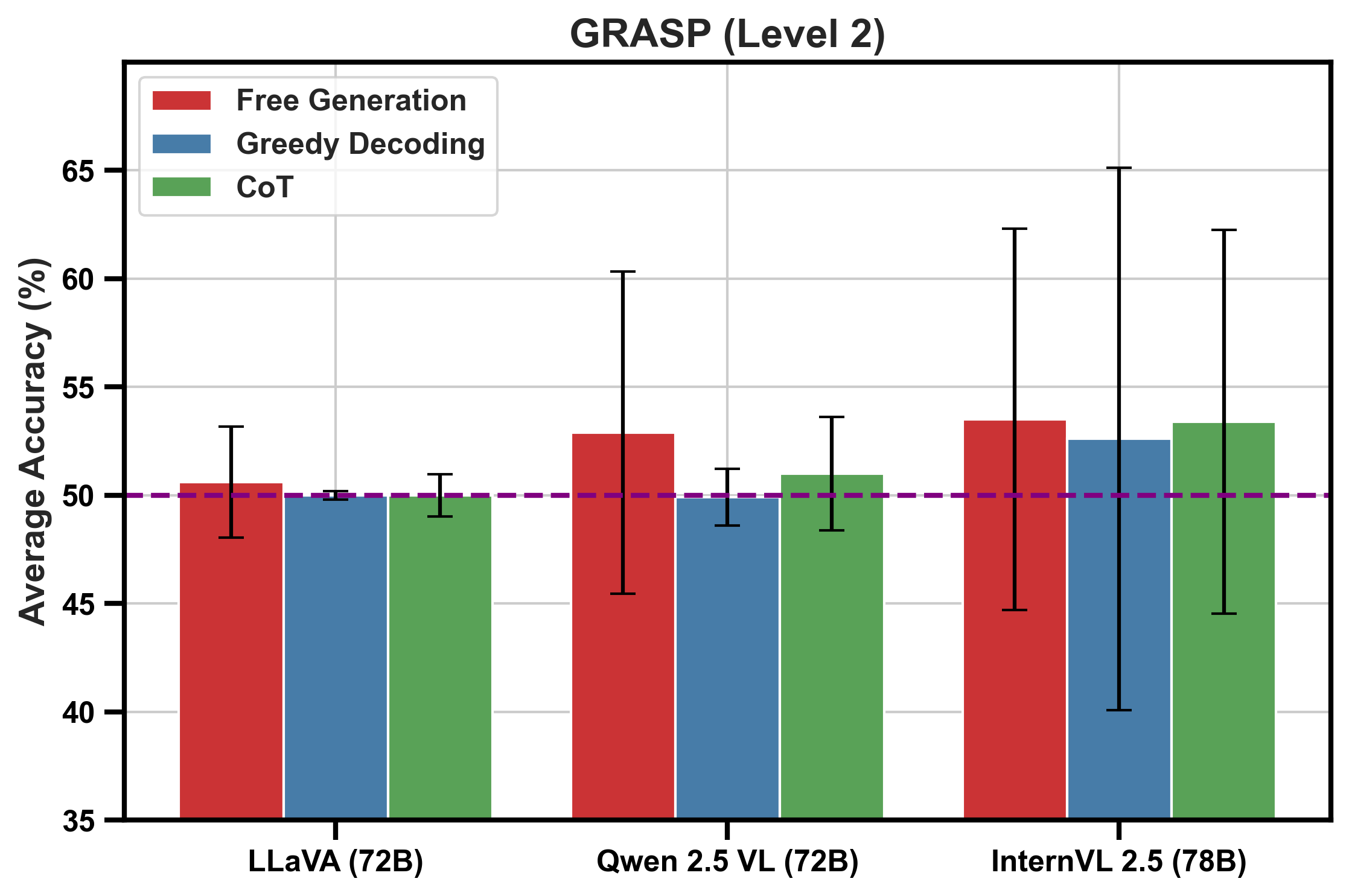
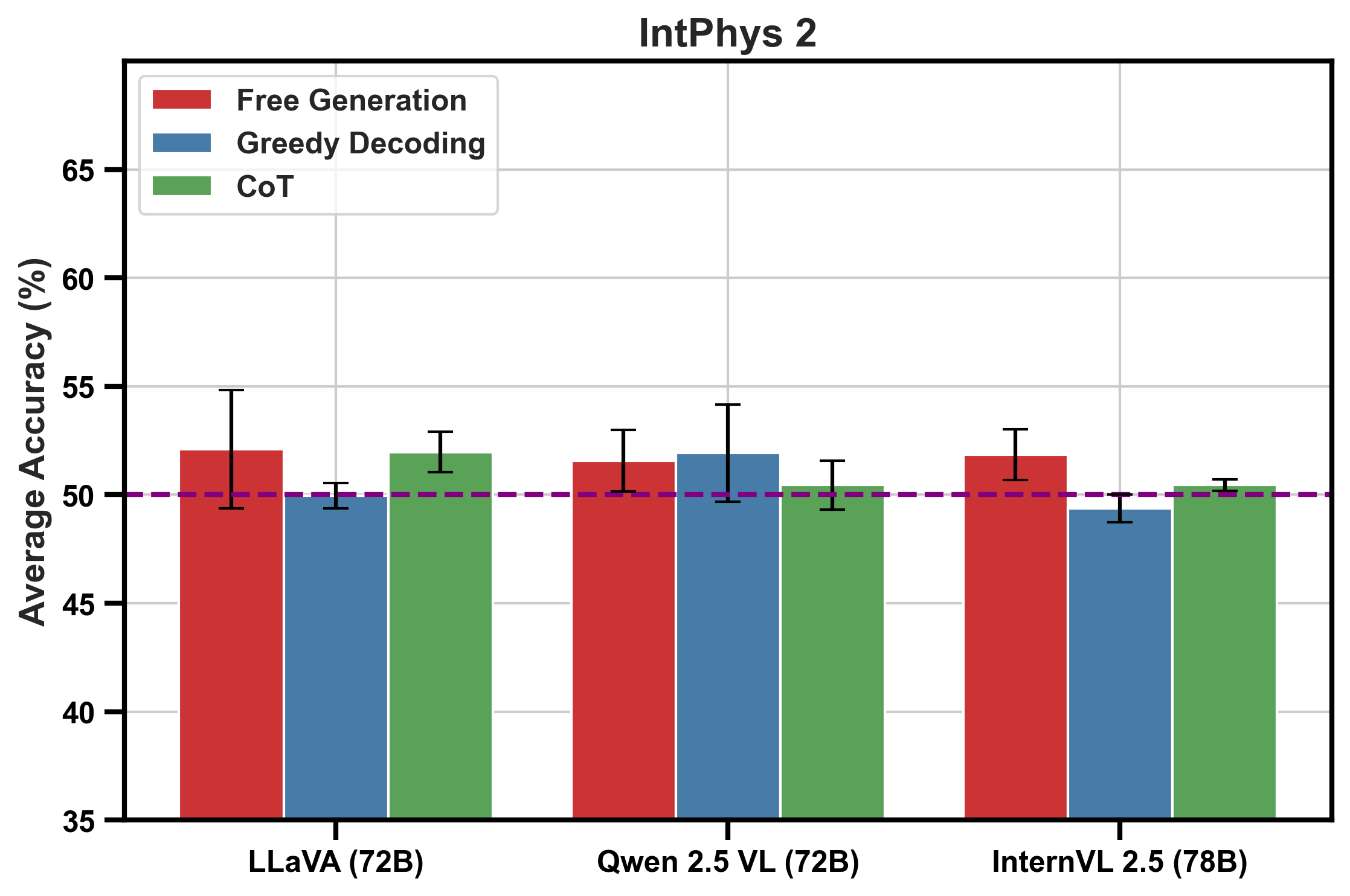
Figure 1: Average accuracy (\%) across the intuitive physics tests of GRASP and IntPhys 2 for the largest models. The dashed line represents chance performance.
Despite human performance being estimated at ~80% in similar tasks, models like Qwen 2.5 VL, InternVL 2.5, LLaVA-OneVision, and Gemini 2.0 Flash Thinking fail to exceed 54% accuracy. This indicates a fundamental limitation in MLLMs' current ability to integrate vision and language information efficiently.
Probing Analysis
In response to these limitations, the study performs a probing analysis to explore the internal model embeddings. The probing reveals critical insights into vision-language misalignment, which emerges as a key limitation in the task performance of MLLMs. The vision encoders are proficient in capturing physical cues, but this information is inadequately leveraged by the LLM components, leading to failures in intuitive physics reasoning.
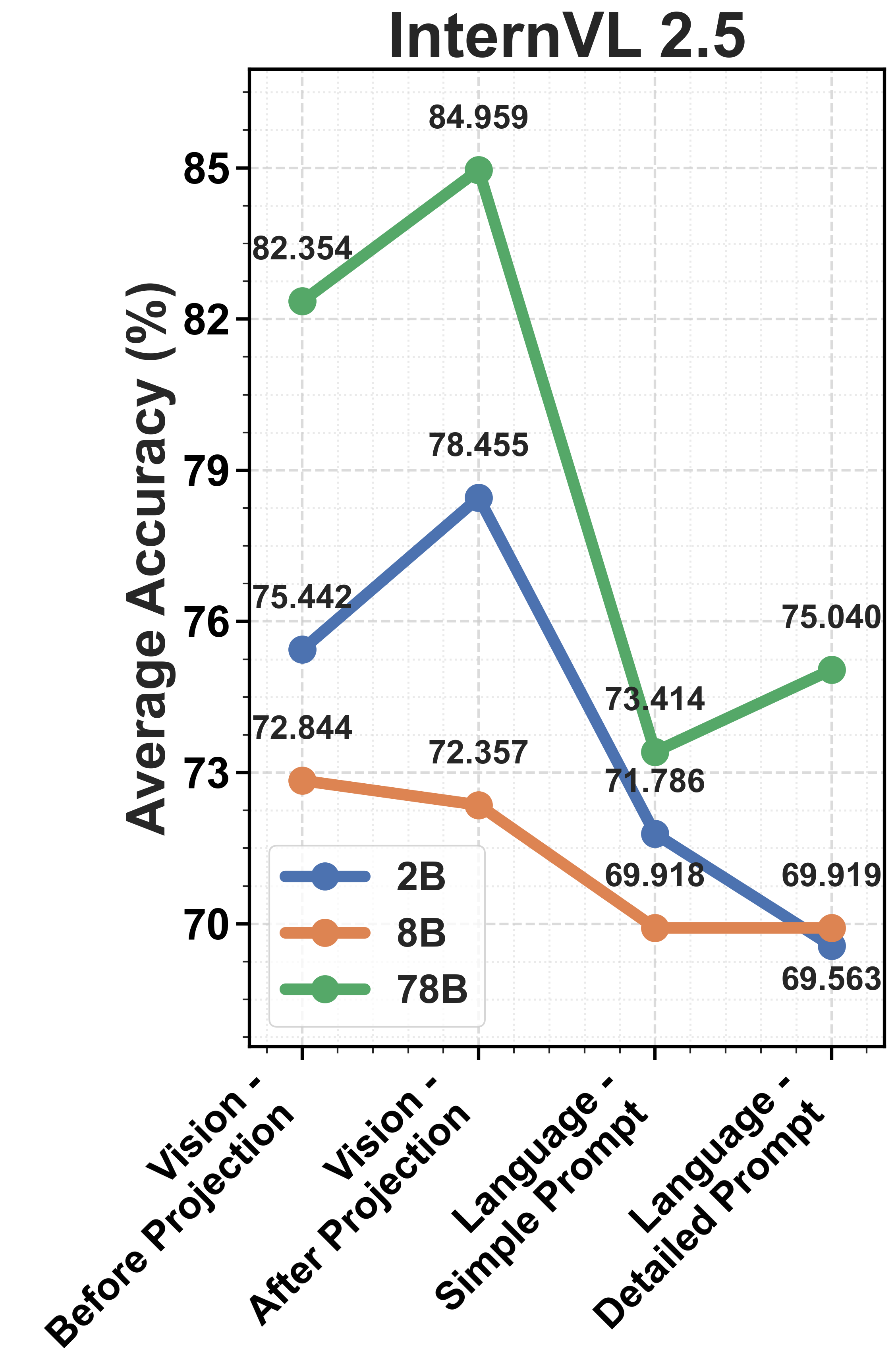
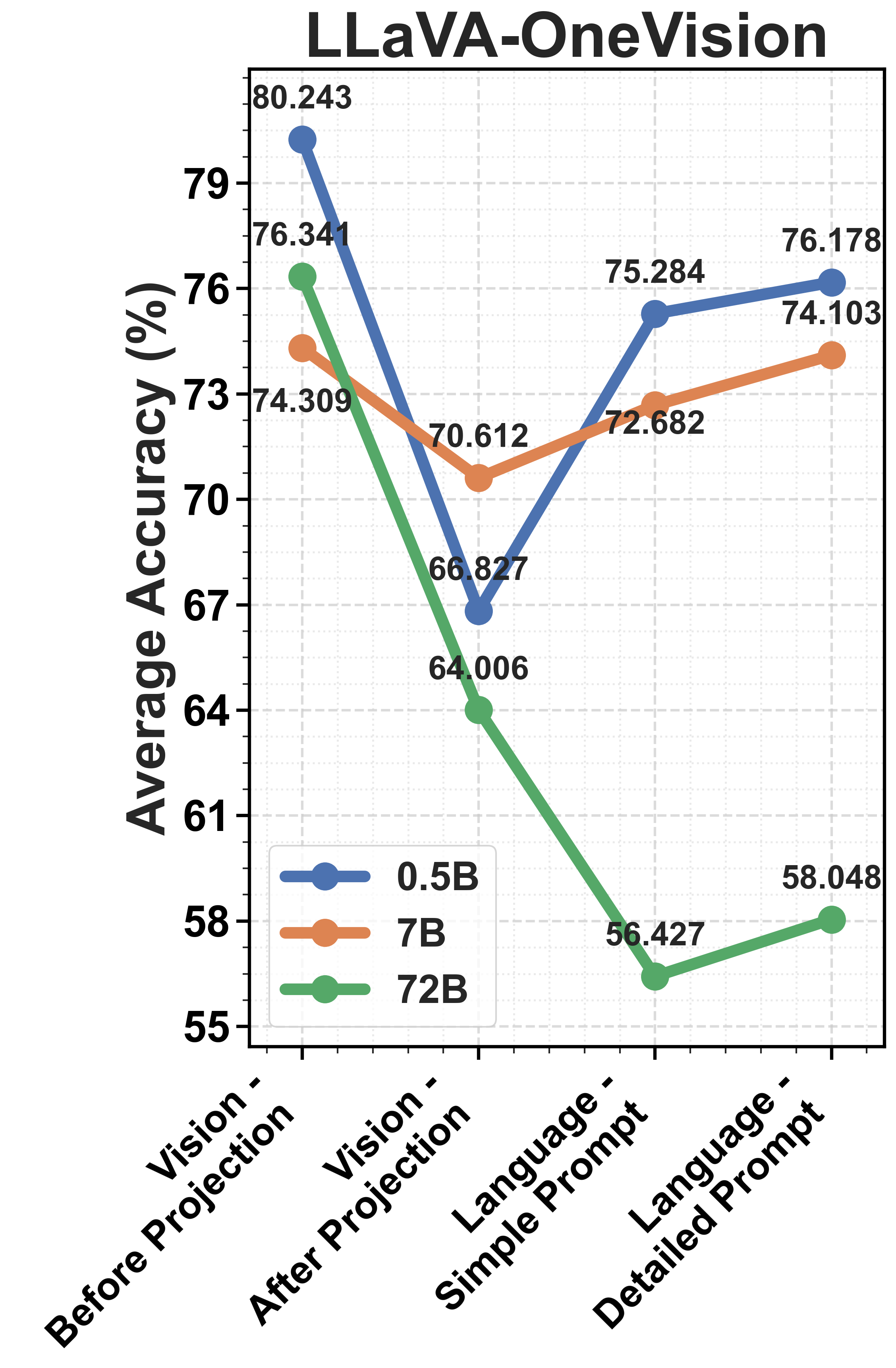
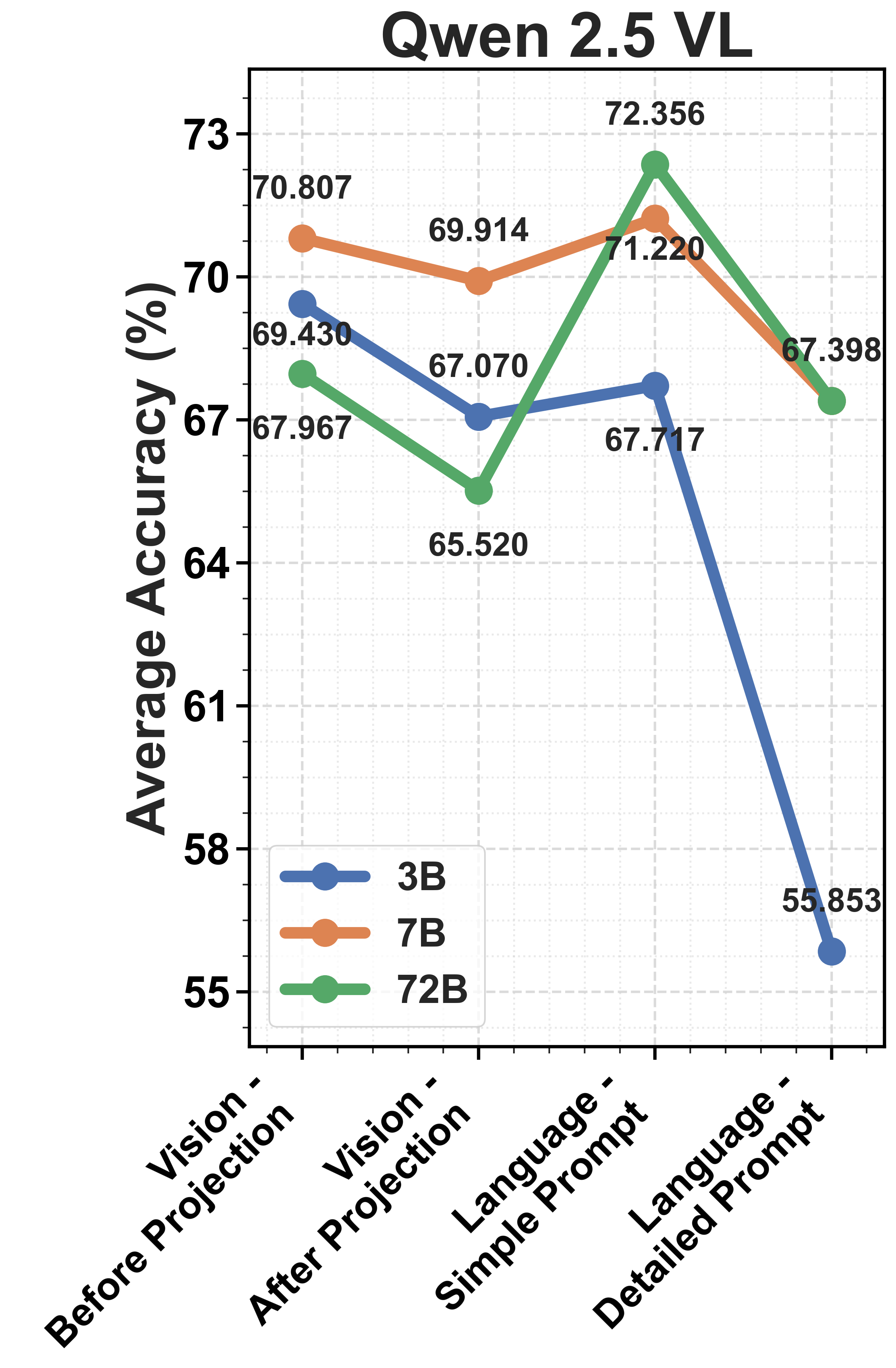
Figure 2: Comparison of model performance across three model families, highlighting alignment and performance variations.
The study utilizes intermediate representations from model processing stages and applies t-SNE clustering to visualize how well task-relevant information is retained through the model layers.
Vision-Language Alignment
The misalignment between vision and language components is identified as a bottleneck. Vision encoders efficiently cluster distinctions between plausible and implausible scenarios. However, this structure deteriorates after the information is processed by the LLM, suggesting that the degradation primarily occurs in the projection and alignment of vision embeddings with language representations.
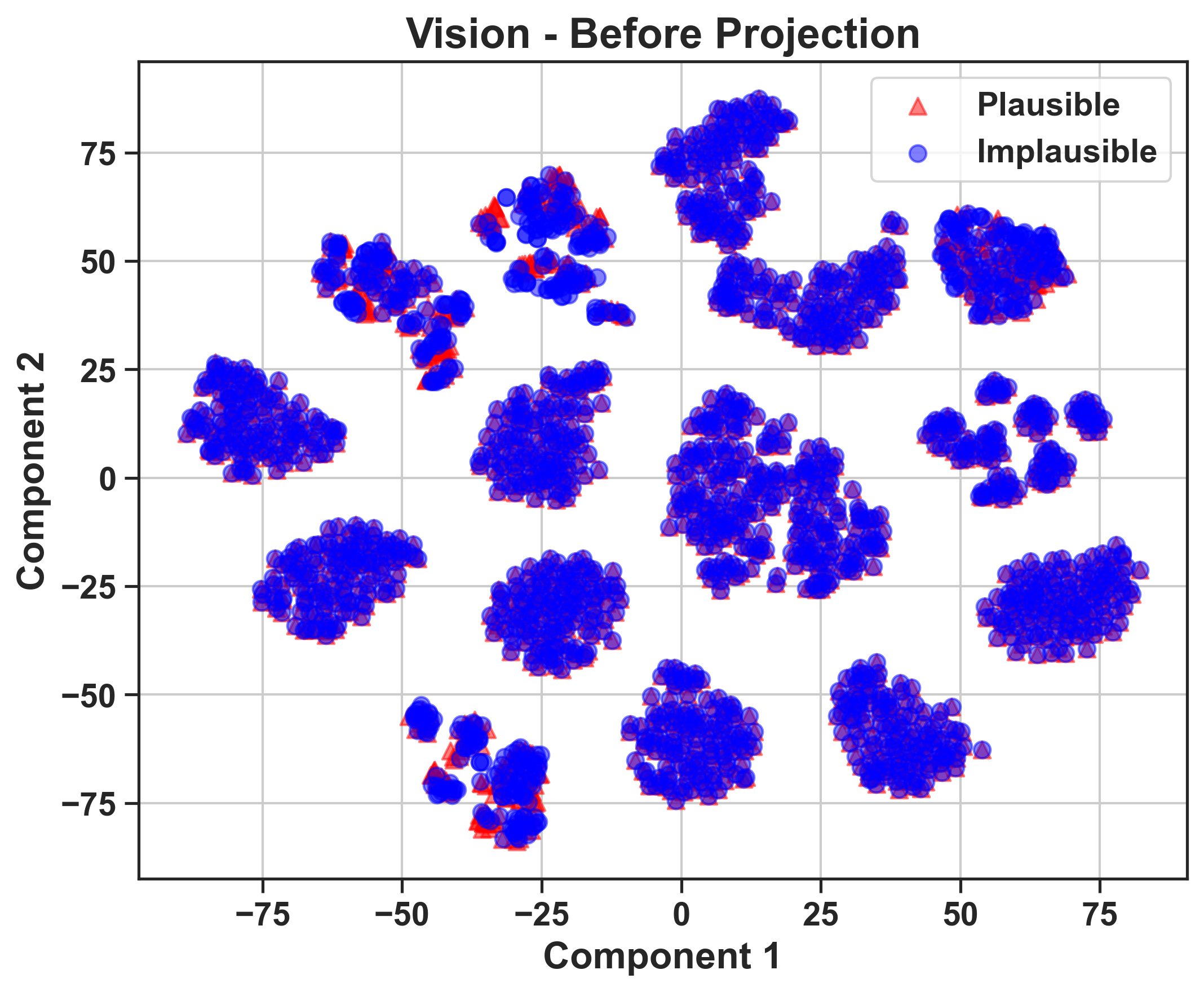
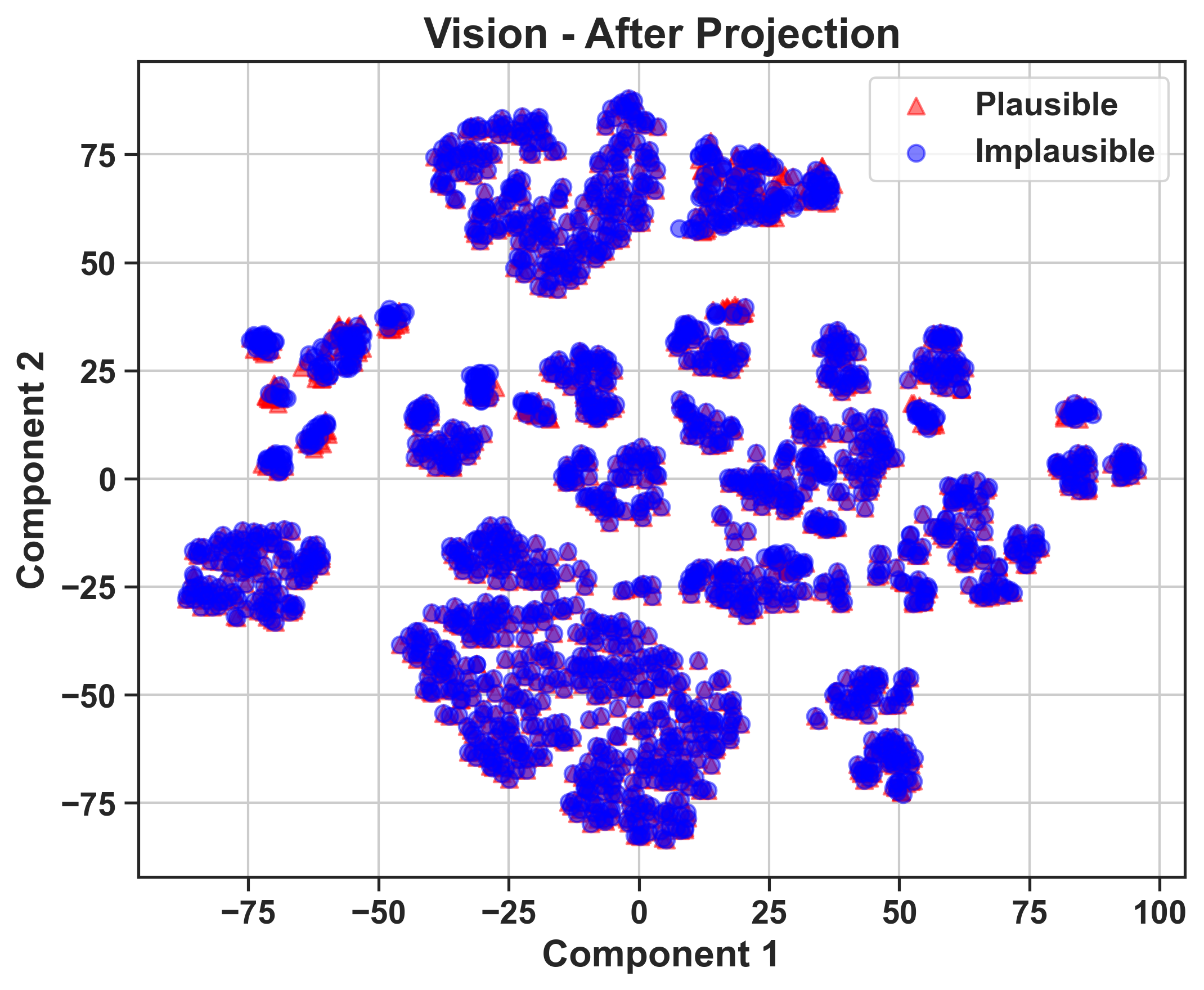
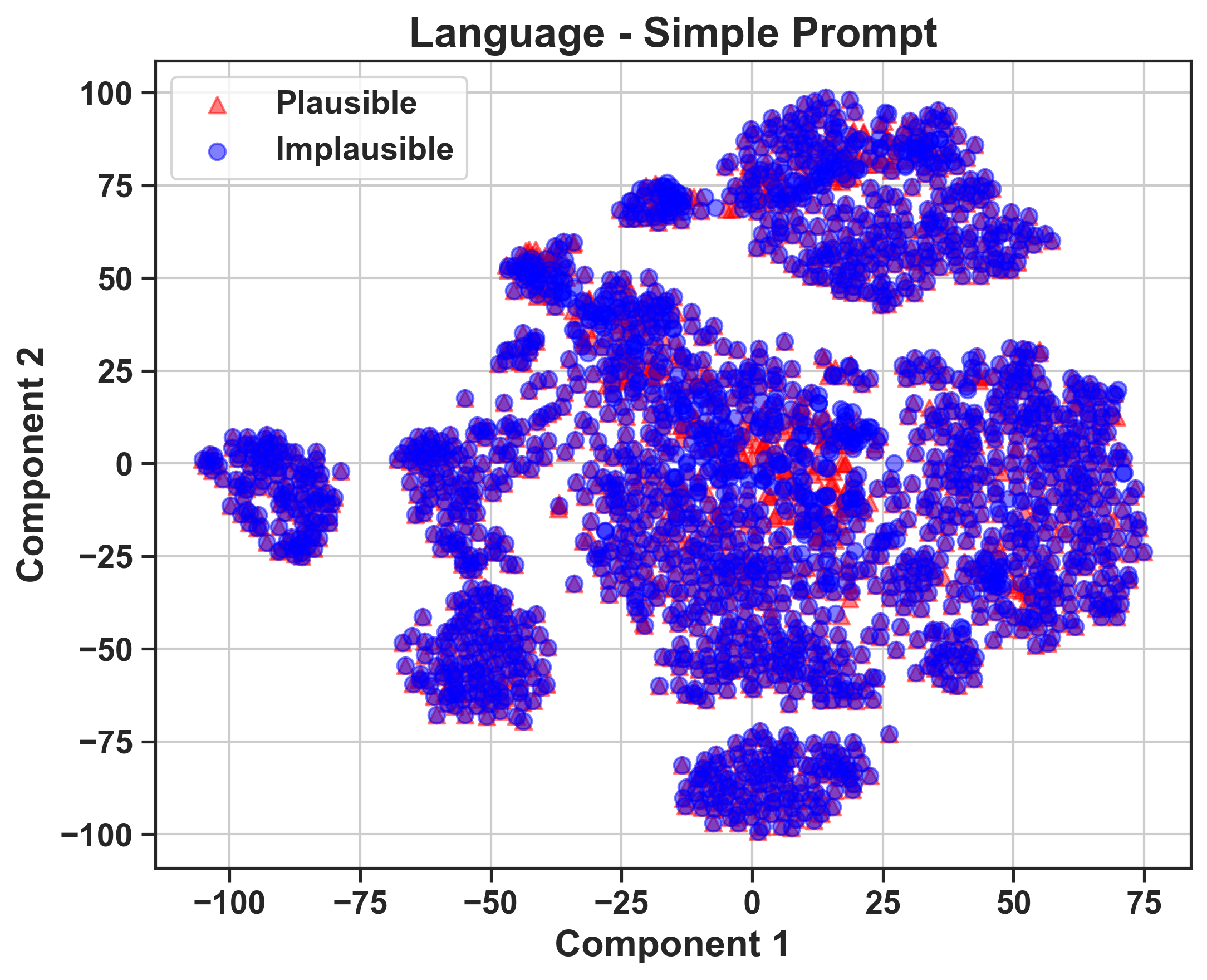
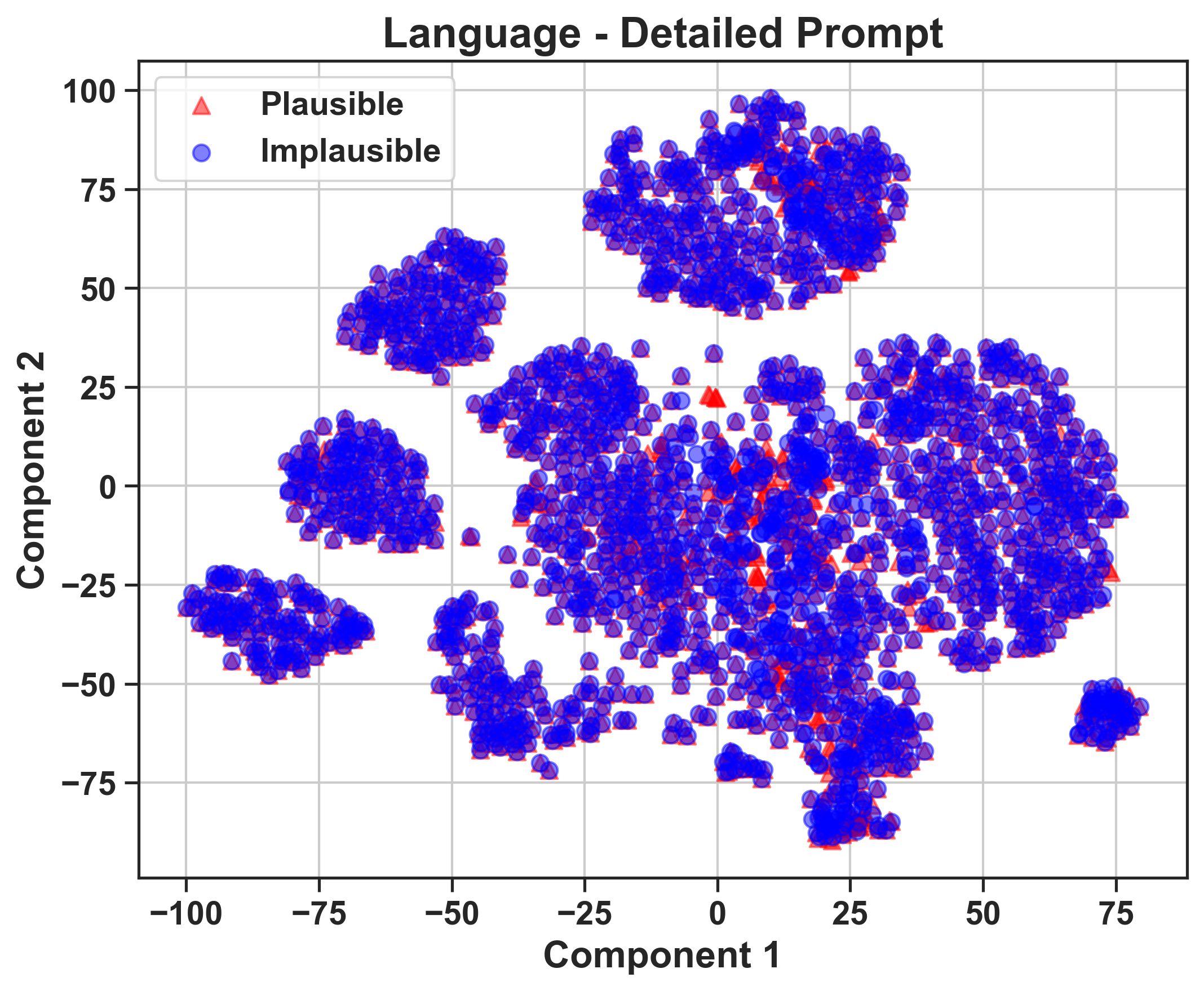
Figure 3: 2D t-SNE visualizations of video features (GRASP, level 2) for LLaVA-OneVision-72B, illustrating distinctions between plausible and implausible video features.
Despite advances in MLLM architecture, the inability to maintain meaningful clustering of physics concepts into the LLM decoder highlights the need for improved integration strategies.
Elementary Visual Understanding vs. Physics Reasoning
The study further distinguishes between simple visual understanding tasks and more complex intuitive physics reasoning. It finds that models perform significantly better on simpler visual tasks, achieving near-perfect accuracy, which underscores the particular difficulty presented by intuitive physics tasks.
These findings suggest the need for more intricate alignment mechanisms to bridge the gap between vision and language modalities for complex reasoning tasks.
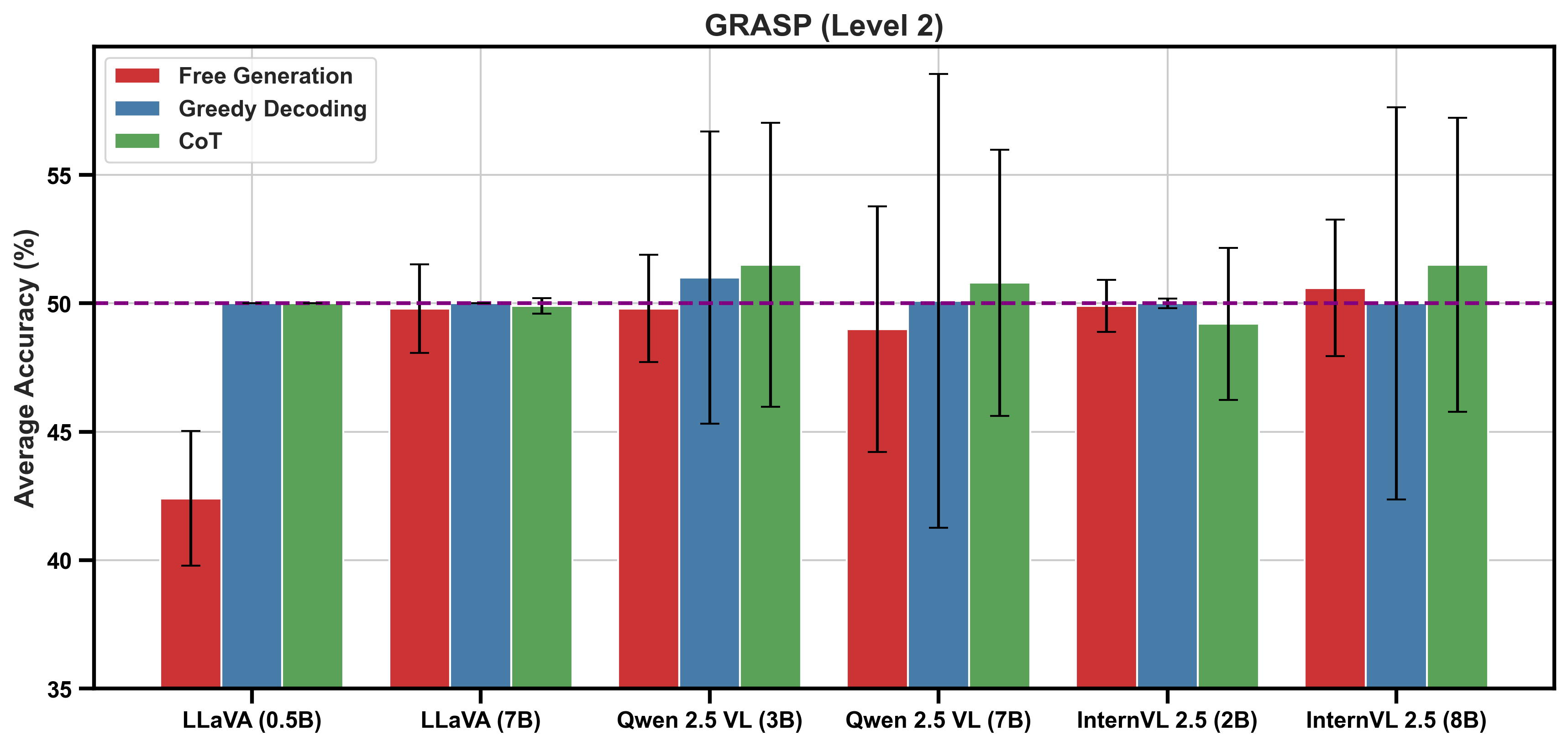
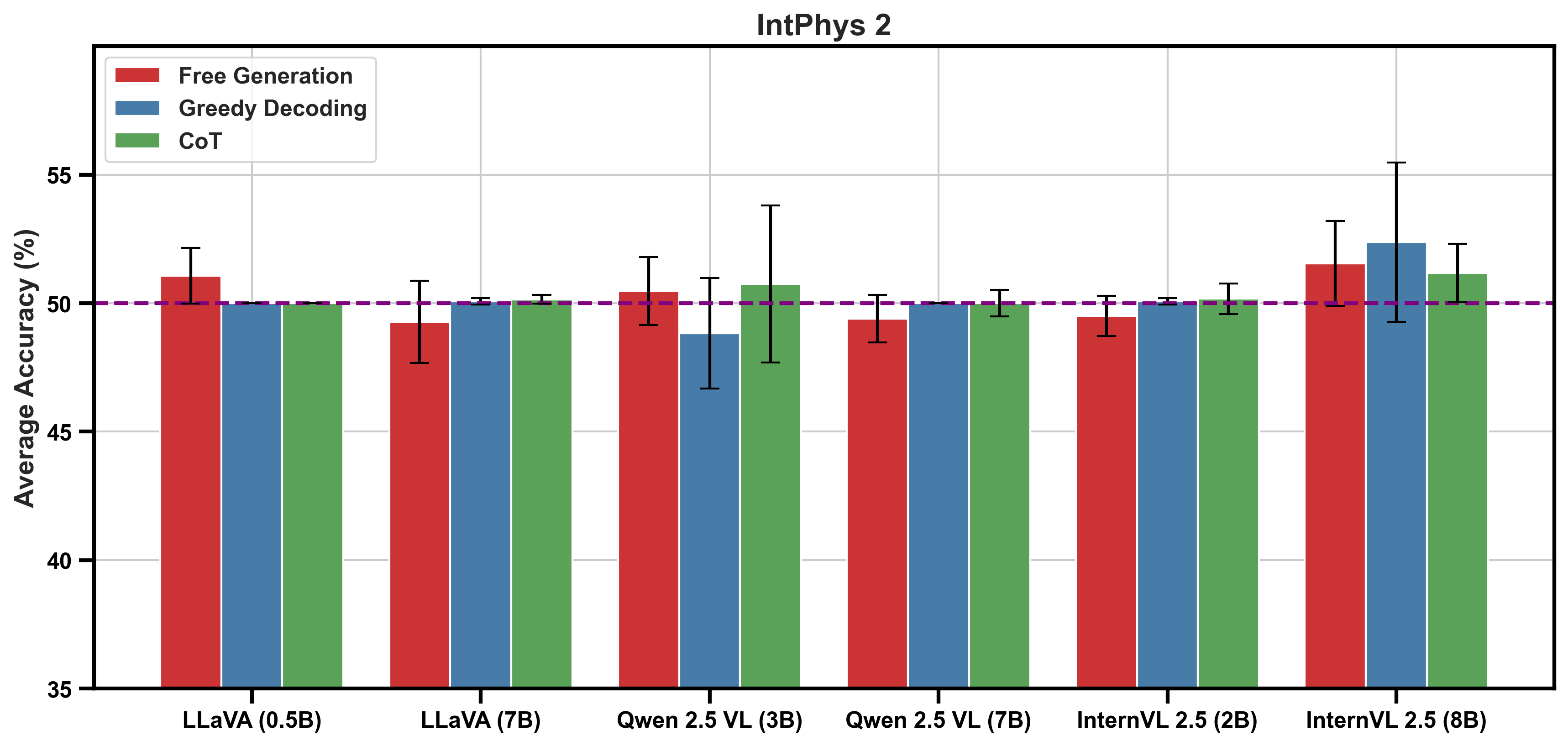
Figure 4: Average accuracy across intuitive physics tests for smaller model sizes, showing performances closer to chance.
Conclusion
In conclusion, while there is progress in MLLMs' performance on intuitive physics tasks, substantial challenges remain. The key limitation identified is the vision-language alignment, where the integration of visual cues into language reasoning processes needs significant refinement. Future work should focus on enhancing alignment methodologies, potentially drawing from developments in both LLM architectures and vision processing paradigms. Addressing these limitations could substantially improve the efficacy of MLLMs in tasks requiring sophisticated reasoning about the physical world.

