UI-Venus-1.5 Technical Report
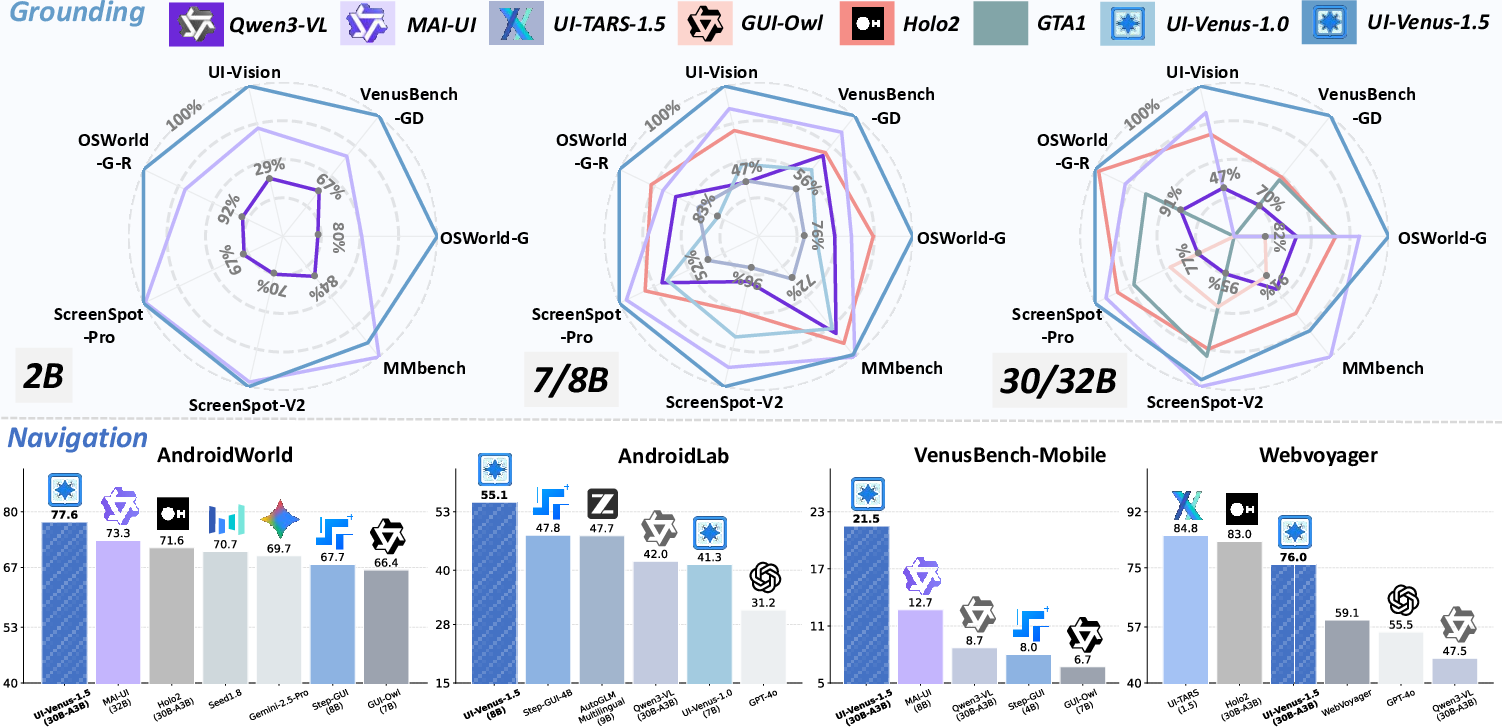
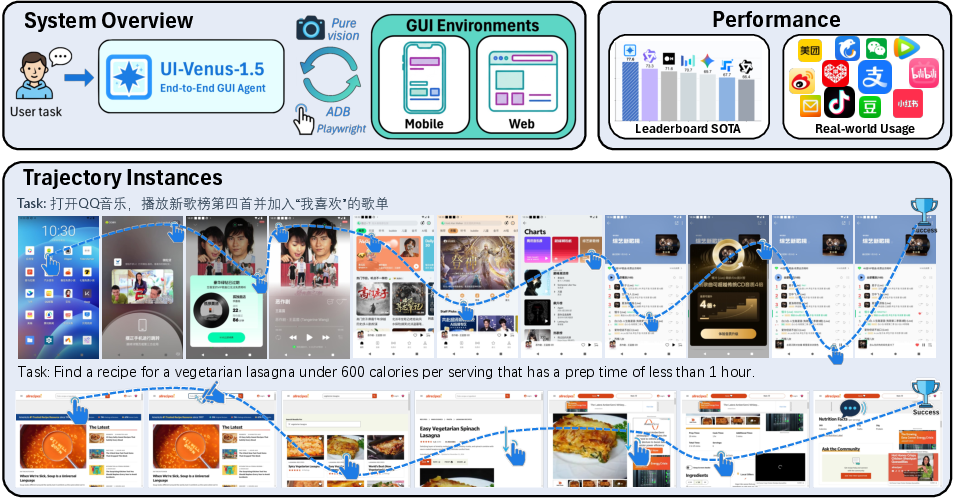
Abstract: GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces UI-Venus-1.5, an AI “computer helper” that can look at screens (like phone apps or websites), understand what a person wants, and then click, type, scroll, or press keys to get the job done—much like a human would. The goal is to build one unified agent that works well across many different apps and websites, not just a single program.
What questions did the researchers ask?
They focused on a few simple but important questions:
- How can we train one agent to handle many kinds of screens (mobile and web) and still do really well?
- How can we make the agent good at full tasks, not just single steps? (For example, finishing a “book a ticket” task from start to finish.)
- How do we combine different specialist skills (like finding the right button, browsing the web, and using phone apps) into one model that’s easy to use?
- How can we collect and clean up training data so the agent learns reliable habits and avoids “hallucinations” (making up answers)?
How did they build and train the agent?
First, some quick terms in plain language:
- GUI (Graphical User Interface): The stuff you see on a screen—buttons, text, icons, menus.
- Grounding: Matching words to the right thing on the screen, like “tap the Share icon” and then finding that icon.
- Navigation: Doing multiple steps in a row to finish a task, like searching, logging in, filling forms, and submitting.
- Reinforcement Learning (RL): Learning by doing—trying actions, getting feedback (rewards or penalties), and improving.
- Trajectory: The whole series of steps the agent takes to finish a task.
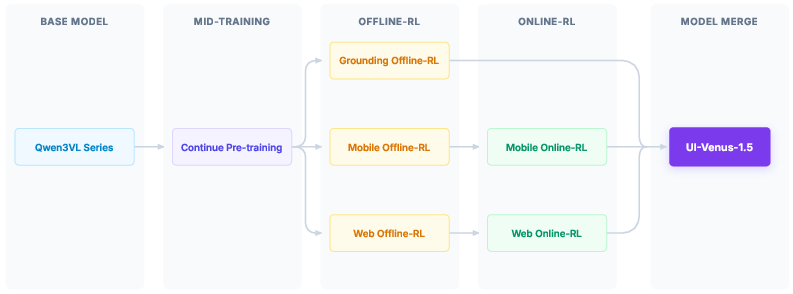
They trained UI-Venus-1.5 in four big stages, similar to how a person learns:
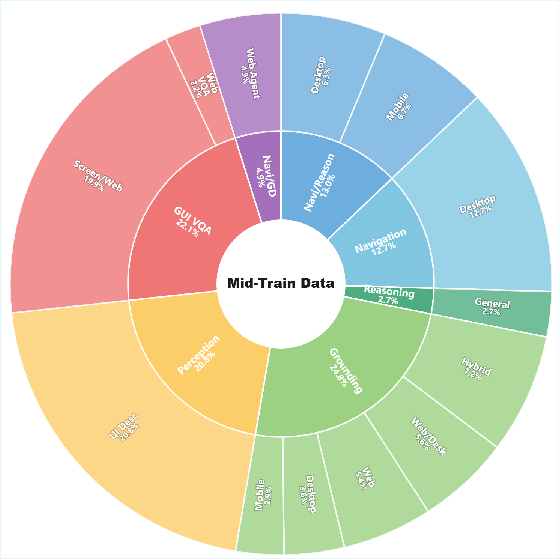
- Learn the basics with tons of examples (Mid-Training)
- The model studied over 10 billion “tokens” (think words and symbols) from more than 30 datasets about screens and apps.
- This gave it general GUI knowledge: recognizing icons, understanding layouts, and answering questions about screens.
- They also cleaned the data using a “teacher” AI that scored and fixed messy examples, plus human checks for quality.
- Practice with recorded examples (Offline Reinforcement Learning)
- The model learned how to produce valid actions (like proper “click” or “type” outputs) and match the right parts of the screen.
- It also learned to say “no” if the target doesn’t exist (a “refusal”), which reduces mistakes.
- Problem spotted: The model got better at single steps but not always at finishing whole tasks. That’s like getting good at dribbling but not winning the game.
- Practice live on real devices (Online Reinforcement Learning)
- They set up a cloud “playground” of phones and browsers (called DaaS: Device-as-a-Service) so the model could actually try tasks for real.
- The agent tried full tasks from start to finish, got rewards for success (and for doing it efficiently), and penalties for invalid actions.
- A smart training method (GRPO) compared groups of attempts and boosted the better ones. This helped it learn stable, long, multi-step behavior.
- Combine specialist models into one (Model Merging)
- They trained three specialists: grounding, web navigation, and mobile navigation.
- Then they merged them into a single model so users don’t need multiple versions.
- A careful merge method (TIES-Merge) kept the best parts of each specialist with minimal loss.
The agent also learned a wider set of actions that work across phone and web, such as click, type, scroll, hover, double-click, and hotkeys.
What did they find?
Here are the main results and why they matter:
- New state-of-the-art on key tests:
- Grounding (finding the right place on screen): 69.6% on ScreenSpot-Pro and 75.0% on VenusBench-GD—better than other strong models.
- Mobile app navigation: 77.6% success on AndroidWorld—top performance.
- Web tasks: 76.0% on WebVoyager—competitive with leading systems.
- Strong real-world skills:
- It handled tasks in 40+ popular Chinese mobile apps, like booking tickets, shopping, and managing chats—showing it works beyond lab tests.
- More reliable behavior:
- The “refusal” skill helps it avoid clicking on things that don’t exist, reducing errors and confusion.
- One unified agent:
- After merging specialists, users get a single model that’s easier to deploy and still performs very well across different kinds of tasks.
Why does this matter?
- Practical helpers: This kind of AI could save people time by automating everyday tasks—filling forms, browsing to the right pages, or completing multi-step actions.
- Accessibility: It could help people who find it hard to use complex apps or websites.
- Software testing and support: It can be used to test apps automatically or assist in customer workflows.
- A simpler path to deployment: A single, end-to-end model is easier to use in real products than juggling separate tools.
In short, UI-Venus-1.5 shows how to train a single AI to “use a computer like a person”—seeing the screen, understanding what to do, and taking the right steps—while performing strongly in both tests and real life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete future research.
- Mid-Training data transparency and ablations: the 10B-token corpus composition (per-dataset counts, domains, languages), mixing ratios, and supervision objective contributions (e.g., GUI-VQA vs grounding vs reasoning) are not disclosed or ablated; no study on how data quality, deduplication, and refinement thresholds affect downstream performance.
- Data licensing and release: the aggregated 30+ datasets and 30k real-device trajectories used for mid-training and online RL are not clearly released or licensed, limiting reproducibility and independent auditing for bias and privacy risks.
- Teacher-judge bias and reliability: the Qwen3-VL-235B “LLM-as-a-judge” used for data ranking and online success verification is not calibrated against human annotations; no inter-rater reliability, error analysis, or robustness to adversarial cases is provided.
- Feedback-loop risks in data generation: the iterative prompt/trajectory generation loop could amplify model biases; no safeguards or diagnostics are presented to prevent mode collapse or reward overfitting due to self-generated data.
- Refusal behavior calibration: while grounding introduces a refusal output ([-1, -1]), there is no quantification of false accept/false refuse rates, thresholding strategies, or impact on downstream navigation (e.g., when refusal should propagate to “abstain” in long-horizon tasks).
- Action space coverage: important real-world actions are missing or under-specified (e.g., drag-and-drop, long-press duration, right/middle-click, text selection and clipboard, multi-touch gestures like pinch/rotate, fine-grained scroll velocity, file dialog operations); the effect of expanding or parameterizing actions on learning stability and task success is unexplored.
- Partial observability and memory: the agent appears to rely on single screenshots with no reported temporal memory design; no studies on history length, frame stacking, or recurrence for handling occlusions, long forms, or multi-step contextual dependencies.
- Reward design sensitivity: key reward hyperparameters (e.g., w1/w2, coordinate tolerance schedule, invalid-action penalty λ, trajectory decay η, KL β schedule, entropy annealing) are unspecified and unaudited; no sensitivity or robustness analyses to reward misspecification or judge errors.
- Trajectory-level credit assignment: GRPO assigns the same advantage to all steps in a trajectory; there is no comparison to step-wise credit assignment, GAE, value-function baselines, or learned success detectors for more precise credit attribution.
- Online RL success verification: the dual-track (rules + MLLM-judge) verifier’s precision/recall is not reported; how often it mislabels successes/failures and how that affects learning is unknown.
- GRPO configuration and compute: group size G, clipping ε, batch sizes, device counts, interaction budgets, and wall-clock costs for online RL are not reported; sample efficiency and scaling laws remain unclear.
- Stability and catastrophic forgetting: while adaptive KL and entropy regularization are proposed, there is no quantitative study on stability over long online training, cross-domain forgetting (grounding ↔ navigation), or recovery from regressions.
- Model merging methodology: merge-weight selection, per-layer contributions, and failure modes of TIES-Merge are not analyzed; comparisons to alternatives (multi-task joint training, adapter/LoRA composition, task-vector arithmetic, or modular experts) are missing.
- Cross-lingual and locale generalization: the model is optimized for 40+ Chinese mobile apps; generalization to non-Chinese languages, right-to-left scripts, mixed-locale UIs, and different cultural iconography is not evaluated.
- Platform coverage gaps: online RL is described for mobile and web only; desktop training/evaluation (e.g., Windows/macOS apps, system dialogs, context menus) is not detailed despite desktop benchmarks being cited.
- iOS and device diversity: evaluations focus on Android and Chrome; performance across iOS, Safari/Firefox/Edge, varying screen sizes/aspect ratios, DPI, scaling settings, and accessibility modes (e.g., high-contrast, large fonts) is not examined.
- Robustness under UI variability: no stress tests on theme changes (dark/light), adaptive layouts, A/B tests, dynamic ads/popups, latency spikes, or non-deterministic elements; variance across runs and sensitivity to minor UI perturbations are unreported.
- Evaluation scope and selection bias: WebVoyager is evaluated on an unspecified subset; criteria, seed tasks, and time-sensitive exclusions are not documented, risking selection bias; multi-run statistics and confidence intervals are absent.
- Metrics beyond success: latency, steps-to-success, path optimality, error recovery rate, and user-centric metrics (e.g., satisfaction, interruption rate) are not reported; success-only metrics may hide inefficiencies.
- Failure analysis: there is no qualitative error taxonomy (e.g., mis-grounding icons, mistyped inputs, wrong-page navigation, failure to detect modal dialogs) to guide targeted improvements.
- Safety and guardrails: the paper does not address safeguards for online RL and deployment (e.g., preventing unintended purchases, data exfiltration, app ToS violations), rollback/undo, permission controls, or audit logging.
- Privacy and compliance: handling of credentials, PII, 2FA, and CAPTCHAs during data collection and online RL is unspecified; compliance with app store policies and data protection regulations is not discussed.
- Security and adversarial robustness: no evaluation against UI/prompt-injection, deceptive overlays, phishing-like UIs, or visually adversarial elements; no confidence estimation or abstention policy beyond grounding refusal.
- Hybrid perception with structured signals: the agent avoids APIs/DOM/accessibility trees by design; potential gains from fusing visual input with structured UI trees or OS accessibility metadata are left unexplored.
- Continual learning and drift: strategies for safe updates as apps/websites evolve (e.g., scheduled online RL, replay buffers, regularization against regression) are not specified or evaluated.
- Chain-of-thought (CoT) analysis: while > traces are enforced for format compliance, the necessity, faithfulness, or privacy implications of CoT are not studied; whether CoT improves success or can be distilled is unknown.
Resource usage and deployability: inference latency, memory footprint, and throughput for 2B/8B/30B-A3B models on commodity hardware or edge devices are not reported; on-device feasibility and cost-performance trade-offs remain unclear.
- MoE architecture clarity: details of the 30B-A3B mixture-of-experts variant (expert count, routing, capacity factor, load balancing) are missing, hindering replication and fair comparison to dense models.
- Open infrastructure gap: DaaS is central to results but not open-sourced; guidance for reproducing at smaller scales or with public device farms is absent, limiting community validation.
Practical Applications
Immediate Applications
The following applications can be credibly deployed now, leveraging UI-Venus-1.5’s unified, end-to-end GUI agent, refusal-aware grounding, online RL training with full-trajectory rewards, and DaaS-based device orchestration.
- Enterprise RPA for “last-mile” UI automation (Finance, Retail, Logistics, Insurance, Healthcare Administration)
- What: Replace brittle selector-based scripts with visual, instruction-following agents to handle portals, legacy apps, and third-party SaaS with no API (e.g., submitting claims, reconciling invoices, onboarding vendors).
- Tools/Products/Workflows: No-code agent builders; agent-runbooks with > /<action>/<conclusion> traces; human-in-the-loop supervision consoles; audit logs for compliance. > - Assumptions/Dependencies: Stable DaaS or VDI access to target apps; credential vaulting and session isolation; guardrails for irreversible actions; adherence to app ToS; performance comparable to benchmarked results in the target language/locale. > > - Software QA and cross-platform test automation (Software, DevTools, CI/CD) > - What: Visual end-to-end regression tests across mobile/web without element IDs, driven by the agent’s grounding and navigation SOTA; refusal helps fail fast when screens diverge. > - Tools/Products/Workflows: Agent-driven CI stages; test case generation from specs; automatic screenshot diffs and semantic “expected outcome” checks via MLLM-as-a-judge; flaky-test triage via trajectory analytics. > - Assumptions/Dependencies: Deterministic test environments; seeded data and resettable states; budget for device farms (DaaS) and batch rollouts; organizational tolerance for MLLM-based judgments where rules aren’t definitive. > > - Contact center and back-office copilots (E-commerce, Travel, Telecom, Utilities) > - What: Agents perform multi-app workflows (refunds, rescheduling, plan changes) by following natural language tasks; operators supervise and approve final steps. > - Tools/Products/Workflows: Dual-pane operator console showing agent trajectory and suggested actions; escalation triggers on refusal or low-confidence; templated flows per vendor. > - Assumptions/Dependencies: Real-time latency targets; robust fallbacks and undo operations; clear escalation policies; domain adaptation to non-Chinese ecosystems where needed. > > - Accessibility: voice-to-action screen control (Assistive Tech, Healthcare) > - What: Voice commands translated to on-screen actions for users with motor impairments; refusal reduces risky mis-clicks when a target isn’t present. > - Tools/Products/Workflows: On-device or edge-inference using 2B/8B variants; microphone and TTS integration; per-app safety policies (e.g., read-back before irreversible actions). > - Assumptions/Dependencies: Low-latency inference; strong privacy posture (on-device preferred); UI language and iconography coverage; regulatory compliance for assistive devices. > > - E-commerce and travel booking automation (Daily Life, Retail) > - What: Agents execute shopping, coupon application, and ticketing flows across mobile apps and websites—capabilities validated across 40+ Chinese apps. > - Tools/Products/Workflows: Personal shopping bots; itinerary builders that compare options across apps; automated rebooking flows when prices drop. > - Assumptions/Dependencies: Terms-of-service compliance; payment and 2FA handling via secure user-in-the-loop; dynamic content variability; region and language adaptation. > > - IT operations runbooks via GUI (ITSM, SRE) > - What: When APIs are missing or restricted, agents execute admin tasks (changing settings, provisioning, log downloads) directly through consoles and web UIs. > - Tools/Products/Workflows: Agentized runbooks with trajectory-level success verification; rollback steps; change tickets auto-attached with action traces. > - Assumptions/Dependencies: Least-privilege execution; hardened sandboxes; deterministic access to admin consoles; compliance logging. > > - Localization and UX quality checks (Product, Design, Localization) > - What: Use GUI-VQA and grounding to spot clipped text, overlapping elements, or missing affordances in localized builds; refusal flags targets that no longer exist. > - Tools/Products/Workflows: Pre-release UX sweeps; language pack validation dashboards; automated screenshots and semantic assertions per build. > - Assumptions/Dependencies: Multilingual grounding reliability; consistent build artifacts; integration with design tokens and layout baselines. > > - Academic data generation and benchmarking pipelines (Academia, HCI, ML) > - What: Reuse the iterative DaaS loop to produce high-quality, verified GUI interaction trajectories (>70% success after refinement) for new datasets and tasks. > - Tools/Products/Workflows: Open benchmarks for GUI-VQA, grounding with refusal, and long-horizon navigation; teacher-scored trace refinement; reproducible task banks. > - Assumptions/Dependencies: Access to device farms or emulators; ethical data collection; reproducibility protocols; license compliance for training corpora. > > - Agent safety scaffolds leveraging structured outputs (Software, Safety/Compliance) > - What: Enforce action schemas (XML tags, parseable actions) with penalties for invalid outputs, and integrate dual-track success checks (rule-based + MLLM-as-judge). > - Tools/Products/Workflows: Action parsers; per-action policy filters; incident replay with trajectory-level rewards; selective refusal and confirmation steps. > - Assumptions/Dependencies: Clear action ontologies per platform; robust parsers; policy tuning to balance productivity and safety. > > - Human productivity boosters: smart macros and repeatable workflows (Daily Life, SMBs) > - What: Record-and-generalize macros that adapt to UI changes via grounding; reusable “do this task” shortcuts across browsers and apps. > - Tools/Products/Workflows: Personal macro libraries; trigger phrases; screenshot-based parameterization (e.g., “Email latest invoice to …”). > - Assumptions/Dependencies: Stable UI semantics; small on-device models for privacy and speed; user review for sensitive steps. > > ## Long-Term Applications > > These applications are plausible extensions but need further research, domain adaptation, safety validation, or regulatory alignment. > > - Universal digital worker across desktop, web, and mobile (Cross-industry) > - What: Fully autonomous computer-use agents handling complex, multi-system workflows end-to-end with minimal supervision. > - Tools/Products/Workflows: Agent orchestration platforms with policy engines, hierarchical goals, and verifiable traces; multi-agent collaboration. > - Assumptions/Dependencies: Stronger reliability guarantees, task decomposition, and recovery; formal safety constraints; broad domain coverage beyond current datasets. > > - Healthcare EHR/EMR operations and clinical documentation (Healthcare) > - What: Agents navigate EHR GUIs for charting, order entry, and quality checks when APIs are constrained. > - Tools/Products/Workflows: HIPAA-compliant agent sandboxes; human-on-the-loop clinical validation; trajectory provenance for audits. > - Assumptions/Dependencies: Strict privacy/security; near-zero error tolerance; extensive domain adaptation to clinical UIs; regulator acceptance. > > - Trading and compliance automation via GUI (Finance) > - What: Execute trades, reconcile positions, and validate compliance attestations in broker and regulatory portals. > - Tools/Products/Workflows: Formal verification layers for high-stakes actions; deterministic approval gates; immutable logs. > - Assumptions/Dependencies: Market, compliance, and latency constraints; provable correctness; segregation of duties; adversarial robustness to UI changes. > > - Government service navigation for citizens at scale (Public Sector, Policy) > - What: Agents help citizens complete complex multi-portal tasks (benefits, permits, taxes) with accessibility support. > - Tools/Products/Workflows: Citizen-facing assistants; multilingual guidance; secure document handling; public kiosks with voice control. > - Assumptions/Dependencies: Policy approvals; data protection; equitable performance across languages and accessibility needs; content drift management. > > - Industrial HMI/SCADA co-pilots (Energy, Manufacturing, Utilities, Robotics) > - What: Assist operators with GUI-based supervision and control of HMIs/SCADA systems; propose steps and require human confirmation. > - Tools/Products/Workflows: Safety-rated confirmation workflows; certified guardrails; offline failover plans; digital twin testing. > - Assumptions/Dependencies: Safety certification; robust out-of-distribution handling; air-gapped or edge deployment; incident response integration. > > - IT helpdesk and auto-remediation agents (Enterprise IT) > - What: L1/L2 issue triage and resolution via GUIs across heterogeneous admin tools; learn optimal traces with online RL. > - Tools/Products/Workflows: Knowledge-grounded action libraries; playbook distillation; closed-loop validation in staging before production rollout. > - Assumptions/Dependencies: Access control and logging; safe rollback; up-to-date environment mirrors; continual policy improvement without regressions. > > - On-device privacy-preserving assistants (Mobile OS, Consumer) > - What: Fully local, low-latency GUI agents running on phones/tablets for private tasks (banking, health apps). > - Tools/Products/Workflows: Model compression/distillation from 30B-A3B to 2B/edge accelerators; energy-aware inference schedulers. > - Assumptions/Dependencies: Hardware acceleration; quantization without major grounding losses; energy/thermal limits; offline reward modeling. > > - Standardization and auditing frameworks for GUI agents (Policy, Standards, Assurance) > - What: Industry standards for action schemas, refusal behavior, trajectory logs, and MLLM-as-a-judge validation protocols. > - Tools/Products/Workflows: Conformance test suites; red-teaming harnesses for GUI agents; shared benchmarks including refusal and safety. > - Assumptions/Dependencies: Multistakeholder agreements; regulator buy-in; transparent reporting; alignment on acceptable error rates. > > - Autonomous curriculum generation for long-horizon learning (Academia, ML Platforms) > - What: Scale the DaaS loop into self-evolving curricula with stratified difficulty and environment randomization for robust generalization. > - Tools/Products/Workflows: Task marketplaces; curriculum schedulers; automated reward shaping; synthetic-to-real adaptation pipelines. > - Assumptions/Dependencies: Cost-effective device orchestration; robust MLLM judging; drift detection; careful avoidance of reward hacking. > > - Cross-app multi-agent collaboration (Productivity, Enterprise) > - What: Specialized agents (grounding, search, form-filling) coordinate to accomplish complex objectives across many apps. > - Tools/Products/Workflows: Multi-agent planners; shared blackboard state; conflict resolution and credit assignment beyond GRPO. > - Assumptions/Dependencies: Reliable inter-agent protocols; global state tracking; scaling without interference; advanced model merging strategies with minimal regression. > > Notes on feasibility and transferability: > > - Domain coverage and language: The paper reports strong results and deployments in Chinese mobile ecosystems; replication in other locales may require additional mid-training data and online RL on local apps. > > - Safety and reliability: While refusal and structured outputs reduce errors, safety-critical domains need additional verifiable guardrails, deterministic checks, and human oversight. > > - Infrastructure: Many applications assume access to a DaaS-like device farm or reliable emulators, along with secure networking and credential management. > > - Legal/ToS: Automating interactions with third-party apps/websites can trigger ToS or legal constraints; governance and consent are required.
Glossary
- Actor-Critic framework: A reinforcement learning architecture that uses separate policy (actor) and value (critic) networks to learn actions and evaluate them. "Unlike the conventional Actor-Critic framework, GRPO estimates relative advantages directly from a group of sampled trajectories, thereby bypassing the need for a separate value function network."
- Adaptive KL Constraint: A regularization technique that penalizes divergence from a reference policy and adapts the reference as the current policy improves. "Adaptive KL Constraint: To prevent the model from losing the fundamental GUI manipulation capabilities (e.g., basic clicking and swiping logic) acquired during SFT or Offline-RL, we incorporate a KL divergence penalty between the current policy and reference policy :"
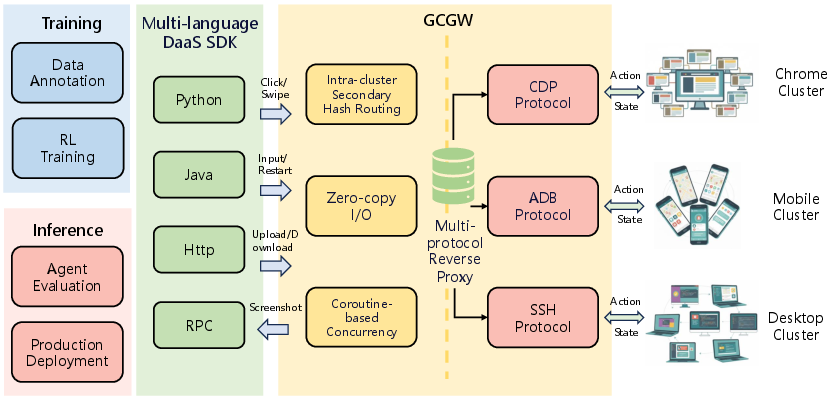
- Android Debug Bridge (ADB): A protocol and tool for communicating with and controlling Android devices programmatically. "including Android (ADB), Chrome (CDP), and Linux containers (SSH)"
- Annealed Entropy Regularization: A method to encourage exploration by adding an entropy term that is gradually reduced over training. "Annealed Entropy Regularization: After SFT or Offline-RL, policies often become overly deterministic, hampering exploration early in online training."
- Chain-of-Thought (CoT): Explicit intermediate reasoning steps generated by the model to break down complex tasks. "Sequential Reasoning: Generating Chain-of-Thought (CoT) traces that decompose high-level goals into intermediate steps."
- Chrome DevTools Protocol (CDP): A protocol for instrumenting, inspecting, debugging, and profiling Chrome-based browsers. "including Android (ADB), Chrome (CDP), and Linux containers (SSH)"
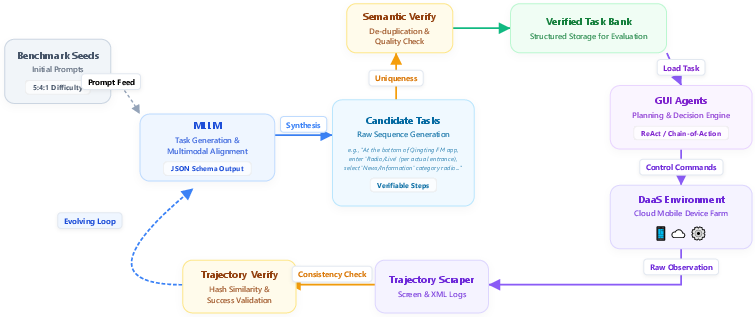
- closed-loop perception-action mechanism: An iterative loop where the agent perceives the environment and takes actions until goals are achieved. "the system operates via a closed-loop perception-action mechanism:"
- composite reward function: A reward design combining multiple components (e.g., completion, penalties, decay) to guide learning. "To guide the agent effectively in complex GUI environments, we design a composite reward function ."
- coroutine model: A concurrency architecture using lightweight cooperative threads to handle large numbers of connections efficiently. "Furthermore, the entire GCGW architecture is built on a high-concurrency coroutine model."
- curriculum learning: A training strategy that samples tasks by difficulty to improve learning stability and performance. "During each training iteration, batches are sampled proportionally from these three buckets to support structured curriculum learning."
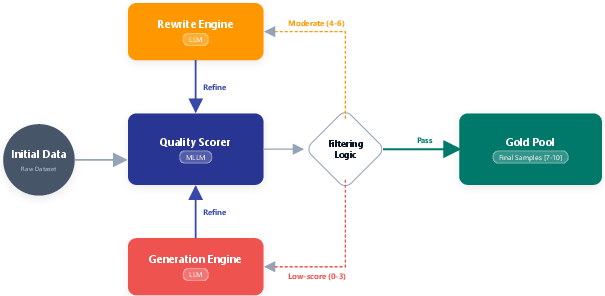
- deduplication function: A function that filters out semantically similar tasks to maintain uniqueness in a task pool. "To maintain task uniqueness, each newly generated goal is filtered by a deduplication function :"
- Device-as-a-Service (DaaS): A unified, scalable execution layer that provides access to heterogeneous devices for training and inference. "Therefore, we build a unified Device-as-a-Service (DaaS) layer"
- embedding similarity: A method of semantic comparison using vector representations to verify or filter generated content. "After semantic verification based on embedding similarity"
- Group Control Gateway (GCGW): A high-performance reverse proxy that orchestrates heterogeneous device protocols and routing. "Group Control Gateway (GCGW). The GCGW serves as a high-performance centralized reverse proxy"
- Group Relative Policy Optimization (GRPO): A policy optimization algorithm that uses group-based relative advantages without a value network. "We employ the Group Relative Policy Optimization (GRPO) algorithm."
- GUI grounding: Mapping natural language instructions to specific GUI elements or coordinates for interaction. "In terms of GUI Grounding, our model establishes a new state-of-the-art"
- GUI-VQA: Visual question answering specialized for graphical user interfaces, focusing on components, layout, and functionality. "GUI-VQA: Providing semantic interpretations of GUI components, functional descriptions, and layout logic."
- hierarchical reward strategy: A progressive relaxation of constraints (e.g., coordinate errors) to smooth reward signals during training. "For $R_{\text{coord}$, we adopt a hierarchical reward strategy that gradually relaxes the tolerance on coordinate errors, smoothing the reward scale and reducing the difficulty of policy optimization."
- Hotkey: A keyboard shortcut action primitive used by the agent in web environments. "we introduce three additional primitives: Hover, DoubleClick, and Hotkey."
- importance sampling ratio: The ratio between new and old policy probabilities used to reweight gradients in off-policy updates. "denotes the importance sampling ratio between the new and old policies at the action (or token) level."
- LLM-as-a-judge: Using a LLM to score or verify data quality or task success. "following the LLM-as-a-judge fashion."
- Mixture-of-Experts (MoE) variant: A model architecture that routes inputs to specialized expert subnetworks to improve performance. "one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios."
- Model Merging: Combining weights from multiple fine-tuned models into a single unified model via strategies like linear or TIES merging. "we apply a model merge strategy."
- Multi-annotator verification: Validating collected trajectories or data with multiple annotators to improve quality. "followed by multi-annotator verification"
- Multi-protocol reverse proxy: A proxy that supports multiple device control protocols while routing and securing connections. "secondary hash routing, zero-copy I/O, and a multi-protocol reverse proxy."
- Multimodal LLMs (MLLMs): Models that process and reason over multiple modalities, such as text and images. "With the rapid evolution of Multimodal LLMs (MLLMs)"
- Offline Reinforcement Learning (Offline-RL): Training policies from static datasets of interactions without live environment feedback. "We use the above reward system for stable Offline-RL."
- Online Reinforcement Learning (Online-RL): Training policies via live interactions with the environment to receive real-time rewards and adapt. "Online Reinforcement Learning(Online-RL) responds to these limitations"
- OCR-free dense captioning: Describing visual elements (including text) in GUIs without relying on optical character recognition. "OCR-free dense captioning."
- point-in-box reward: A reward function that checks whether a predicted point lies within a target bounding box. "We use the commonly used point-in-box reward noted as $R_{\text{point-in-box}$ to train the model."
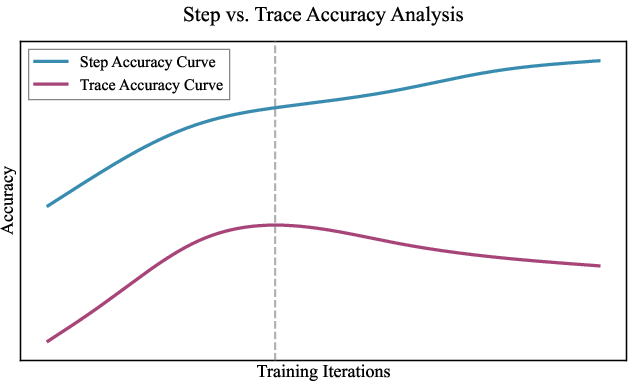
- policy collapse: Degeneration of a learned policy into poor or trivial behavior during training. "which can lead to policy collapse during extended online training."
- refusal capability: The agent’s ability to decline invalid instructions by outputting a standardized refusal signal. "incorporate what we define as refusal capability."
- secondary hash routing: A routing strategy ensuring requests for a device consistently reach the same gateway node to preserve stateful connections. "internal secondary hash routing algorithm."
- semantic verification: Checking generated tasks or outputs using semantic measures to ensure validity and non-duplication. "After semantic verification based on embedding similarity"
- state-of-the-art (SOTA): The best reported performance on benchmarks at the time of evaluation. "achieves SOTA performance across multiple GUI grounding and navigation benchmarks."
- stratified sampling: Sampling data proportionally from predefined difficulty buckets to balance training batches. "Stratified Sampling: We stratify tasks by difficulty"
- task vectors: Parameter differences between fine-tuned and base models used for merging and pruning. "First, it calculates task vectors (differences between fine-tuned models and the base model)"
- token-level F1-score: A precision-recall harmonic mean computed at the token level to measure text output accuracy. "$R_{\text{content}$ is applied to text-based actions and is computed as the token-level F1-score between the predicted and ground-truth content."
- trajectory-level advantage: A normalized advantage computed per full trajectory and assigned uniformly to its steps. "The trajectory-level advantage is derived by normalizing relative scores within the sampled group:"
- trajectory rollouts: Executing complete sequences of actions in the environment to evaluate rewards and train policies. "Online Reinforcement Learning with full-trajectory rollouts"
- trace length decay coefficient: A factor that reduces reward for longer trajectories to encourage shorter solutions. "and a trace length decay coefficient "
- Unified Client SDK: A high-level, multi-language client library that abstracts device management and protocol interactions. "a multi-language Unified Client SDK was developed that acts as a high-level API layer atop the GCGW."
- value function network: A neural network that estimates expected returns to guide policy updates in RL. "bypassing the need for a separate value function network."
- XML-based template: A strict output format using XML-like tags to structure reasoning, actions, and conclusions. "This component ensures the agent model follows a predefined XML-based template."
- zero-copy I/O: An optimization that avoids memory copying during data transfer to reduce latency and overhead. "zero-copy I/O"
Collections
Sign up for free to add this paper to one or more collections.

