- The paper presents a novel end-to-end, small on-device GUI agent that integrates visual and language models for effective GUI grounding and navigation.
- It employs supervised fine-tuning followed by reinforcement learning with verifiable rewards to optimize performance on diverse GUI tasks.
- Empirical results show competitive performance against larger models, demonstrating practical potential for deployment on resource-constrained devices.
Ferret-UI Lite: Design and Empirical Analysis of Small On-Device GUI Agents
Introduction
Ferret-UI Lite addresses the challenge of building compact, end-to-end agents capable of robustly interacting with graphical user interfaces (GUIs) across mobile, web, and desktop platforms. The work is motivated by the need for on-device deployment, where constraints on model size, latency, and privacy preclude the use of large-scale, server-side models. The paper systematically explores data curation, model architecture, training strategies, and evaluation protocols for a 3B-parameter multimodal LLM, providing a comprehensive empirical paper and practical lessons for the development of small GUI agents.

Figure 1: An illustration of Ferret-UI Lite on a multi-step GUI navigation task. Human users prompt with a high-level goal in plain text, and the model autonomously interacts with GUI devices through tapping, scrolling, typing, etc., until the task is complete. At each step, the model observes the GUI screen, generates think-plan-act traces, and executes the action.
Model Architecture and Training Paradigm
Ferret-UI Lite employs a unified, end-to-end architecture that directly maps GUI screenshots and user instructions to low-level action policies. The model integrates a ViTDet-based image encoder with a LLM backbone, leveraging the AnyRes strategy for flexible input resolution partitioning. The action space is unified across platforms, supporting both shared and domain-specific operations via a function-call schema, which enhances interpretability and aligns with tool-use paradigms.

Figure 2: Model architecture and training recipes of Ferret-UI Lite. The model takes a GUI screen and the user instruction as inputs, and predicts chain-of-thought reasoning traces and a low-level action policy to control GUI devices in an end-to-end manner directly. The model is trained through supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR).
Training is conducted in two stages:
- Supervised Fine-Tuning (SFT): The model is first trained on a mixture of human-annotated and synthetic datasets, covering both grounding and navigation tasks. Annotation formats are unified to ensure consistent supervision.
- Reinforcement Learning with Verifiable Rewards (RLVR): RL is applied to further align the model with task success, using rule-based, automatically computable rewards for both grounding (containment-based) and navigation (action type and parameter matching, with both sparse and dense reward variants).
Data Curation and Synthetic Data Generation
A key insight is the necessity of large-scale, diverse data for small models to generalize effectively. The SFT data mixture includes public benchmarks and systematically generated synthetic data, spanning multiple platforms and interaction types.

Figure 3: Synthetic navigation data generation pipeline, which consists of offline data generation based on human-annotated trajectories, and online rollouts collection from a multi-agent system.
Synthetic data generation encompasses:
- High-Resolution Grounding: Composite images with dense layouts to improve spatial localization.
- Chain-of-Thought (CoT) Navigation: Synthetic reasoning traces (plan, action think, reflect) generated via GPT-4o and SoM visual prompting, supporting both short and long CoT variants.
- Synthetic QA and Replanning: Visual QA pairs and perturbed trajectories to enhance robustness and recovery strategies.
- Online Rollouts: Multi-agent systems generate diverse, error-prone trajectories, filtered by VLM-based judges for quality assurance.
Reinforcement Learning and Reward Design
RLVR is used to overcome the limitations of strict imitation in SFT, allowing the model to optimize for verifiable task success. For grounding, a containment-based reward is used, and a zoom-in operation is introduced to refine predictions on cropped regions, mimicking human attention mechanisms and improving accuracy on cluttered or high-resolution interfaces.
For navigation, the reward function decomposes correctness into action type and parameter fidelity, with dense rewards providing graded feedback based on normalized distance from ground-truth locations. Group Relative Policy Optimization (GRPO) is employed for stable and sample-efficient RL, with online filtering to focus on informative examples.
Empirical Results
GUI Grounding
Ferret-UI Lite achieves strong results on ScreenSpot-V2 (91.6%), ScreenSpot-Pro (53.3%), and OSWorld-G (55.3%), outperforming all other 3B models and narrowing the gap to 7B and larger models. Notably, on ScreenSpot-Pro, it surpasses UI-TARS-1.5 (7B) by over 15%. The model demonstrates robust performance across mobile, desktop, and web platforms, with high-resolution synthetic data providing significant gains on challenging benchmarks.
GUI Navigation
On AndroidWorld, Ferret-UI Lite attains a 28.0% success rate, competitive with 7B models. On OSWorld, it achieves 19.8% (with extended step limits), outperforming all 3B baselines. However, the absolute performance on long-horizon navigation remains limited compared to larger models, highlighting the inherent challenges of scaling down agentic reasoning and planning.

Figure 4: Successful completion for ``Make sparkline charts for each order id with the data from Jan to Mar in the Chart column.'' task in OSWorld evaluation.

Figure 5: Successful Completion for ``Delete the following recipes from Broccoli app: Kale and Quinoa Salad, Baked Cod with Lemon and Dill, Rasperry Almond Smoothie'' task in AndroidWorld evaluation.

Figure 6: Successful Completion for ``Create a new contact for Lina Muller. Their number is +15410831733'' task in AndroidWorld evaluation.
Ablation Studies
- SFT vs RL: RL consistently improves grounding and navigation, with the zoom-in operation providing additional gains.
- Data Mixture Ratios: Balanced mixtures of grounding and navigation data yield the best results, with mutual benefits observed.
- Synthetic Data Scaling: Increasing the scale and diversity of synthetic data, especially with long CoT traces and online rollouts, leads to substantial improvements in navigation.
- Reward Design: Dense grounding rewards combined with action type rewards are most effective; reward design is critical for small model RL stability and performance.
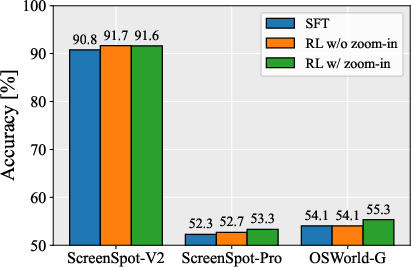
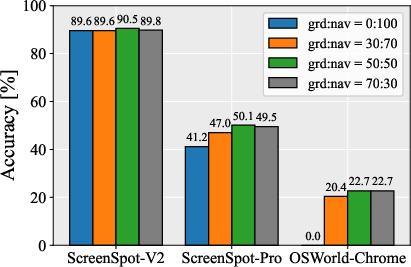

Figure 7: SFT vs RL variants.


Figure 8: Impact of SFT steps for RL.

Figure 9: Evolution of verifiable reward curve during RLVR training.
Practical and Theoretical Implications
Ferret-UI Lite demonstrates that with careful data curation, unified action schemas, and tailored RL reward structures, small on-device models can achieve competitive performance in GUI grounding and navigation. The results suggest that synthetic data generation, especially with diverse reasoning traces and online rollouts, is essential for compensating for limited model capacity. However, the persistent gap in long-horizon navigation underscores the need for further advances in compact model architectures, memory mechanisms, and hierarchical planning.
The work provides a reproducible recipe for building efficient, privacy-preserving GUI agents suitable for deployment on resource-constrained devices. The findings also inform the broader design of agentic systems, emphasizing the interplay between data diversity, reward engineering, and model architecture in low-resource settings.
Future Directions
Future research should explore:
- Hierarchical and Modular Architectures: To better decompose long-horizon tasks and leverage limited capacity.
- Continual and Online Learning: For adaptation to novel GUIs and user preferences in real-world deployment.
- Advanced Memory and Planning Mechanisms: To improve multi-step reasoning and error recovery in small models.
- Unified Evaluation Protocols: For more comprehensive benchmarking across platforms and task types.
Conclusion
Ferret-UI Lite establishes a strong empirical foundation for small, on-device GUI agents, demonstrating that with principled data curation, unified modeling, and reward-driven RL, compact models can approach the performance of much larger systems in grounding and navigation tasks. The work highlights both the promise and the current limitations of scaling down agentic AI, providing actionable insights and open challenges for the community.