- The paper introduces FastVMT, which eliminates redundant computations in video motion transfer by leveraging a sliding-window attention mechanism and gradient reuse strategy.
- The methodology reduces computational complexity from O(F^2) to O(F) and achieves up to 14.91x lower latency while maintaining near-lossless visual fidelity.
- The framework's innovations enable real-time controllable video generation for media applications and set a new paradigm for efficient diffusion-based generative pipelines.
FastVMT: Eliminating Redundancy in Video Motion Transfer
The FastVMT framework addresses the efficiency bottlenecks in training-free video motion transfer using diffusion transformers (DiT). Contemporary training-free approaches typically rely on exhaustive global token similarity computations and repetitive gradient calculations during the denoising diffusion loop, leading to substantial computational costs. This work identifies two forms of redundancy:
- Motion Redundancy: The extraction of motion embeddings disregards the local consistency and limited magnitude of frame-to-frame motion, leading to unnecessary global similarity calculations between tokens in consecutive frames.
- Gradient Redundancy: Gradient updates in iterative optimization steps are largely stable, yet they are recomputed at every step, ignoring their redundancy along the diffusion trajectory.
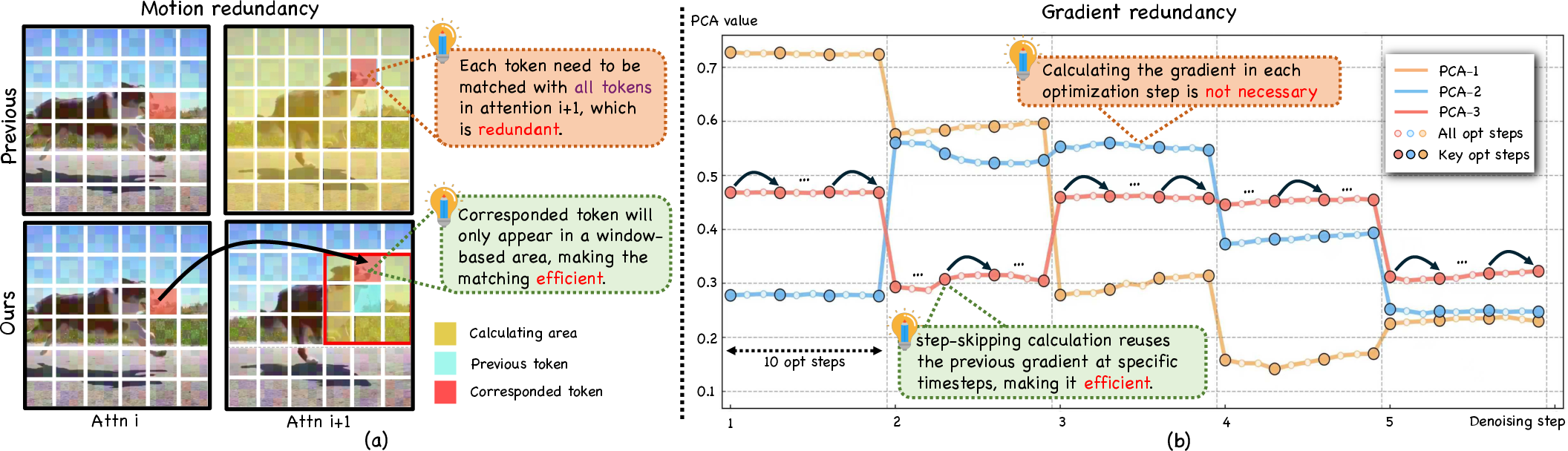
Figure 1: Redundancy phenomena—motion is small/locally consistent and gradients are stable across optimization steps, motivating FastVMT’s architectural and algorithmic improvements.
Methodology
To resolve motion redundancy, FastVMT implements a sliding-window strategy in attention map computation within DiT. Instead of global token similarity, the method partitions spatial dimensions into tiles, computes attention locally, and determines the most relevant local motion correspondence. This spatial constraint both improves computational efficiency by reducing complexity from O(F2) to O(F) and corrects mismatches.

Figure 2: Sliding window mechanism yields improved attention alignment, enhancing local motion fidelity.
Corresponding-Window Loss
Temporal consistency is reinforced by the corresponding-window loss, a regularization that penalizes inconsistency in key representations across adjacent frames. This loss synergizes with the weighted Attention Motion Flow (AMF) loss to guarantee consistent and accurate motion transfer, with minimal additional computational cost.
Step-Skipping Gradient Optimization
To exploit gradient redundancy, FastVMT deploys interval-based gradient reuse. Gradients are computed only at selected steps; intermediate steps reuse cached gradients, resulting in substantial reduction of backpropagation calls without adverse influence on optimization effectiveness.
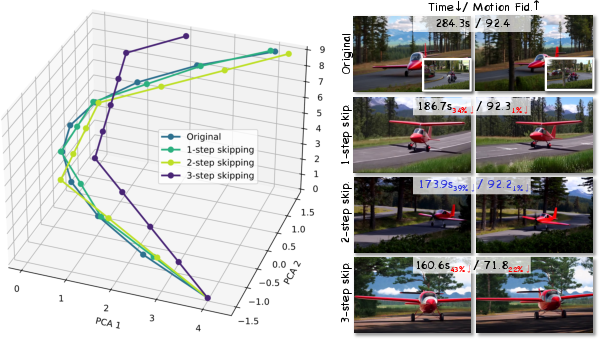
Figure 3: Step-skipping gradient optimization maintains transfer quality while reducing redundancy.
Overall Pipeline
During inference, FastVMT extracts motion embeddings using the sliding-window strategy, applies corresponding-window loss during denoising, and guides video generation via step-skipping gradient optimization in the latent space.
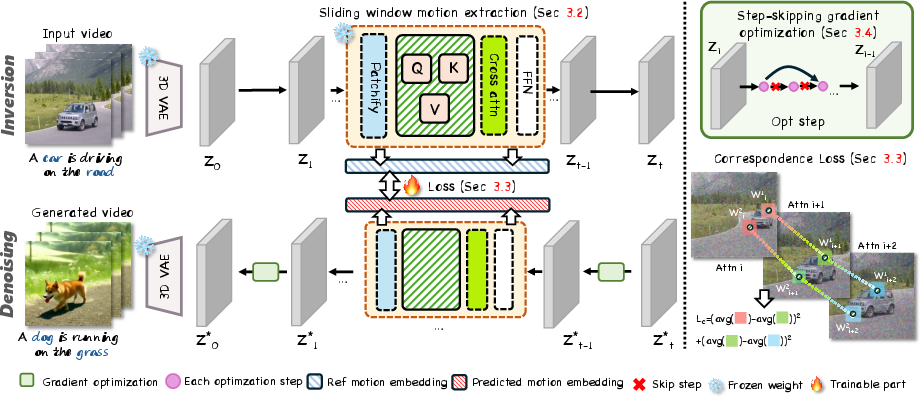
Figure 4: End-to-end workflow—sliding window extraction, corresponding-window loss, step-skipping optimization form the FastVMT pipeline.
Experiments and Results
FastVMT was evaluated on DAVIS and bespoke datasets, compared to state-of-the-art approaches including MOFT, MotionInversion, MotionClone, SMM, DiTFlow, and DeT, using consistent backbones. Key findings:
- Efficiency: Achieves 3.43× speedup on average and up to 14.91× lower latency versus training-free baselines.
- Quality: Maintains near-lossless visual fidelity and temporal consistency—text similarity ($0.2422$, best), motion fidelity ($0.7471$, best), and temporal consistency ($0.9865$, best).
- User Study: Outperformed competitors in motion preservation and appearance fidelity.
- Scalability: Handles longer sequences and complex motions with consistent efficiency gains.

Figure 5: Qualitative gallery—FastVMT preserves diverse motion patterns across various generative scenarios.

Figure 6: Comparative visuals—FastVMT yields superior transfer across baseline tasks and motion types.
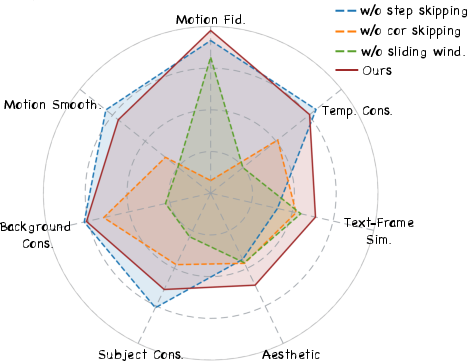
Figure 7: Ablation metrics—component contributions empirically validated, supporting architectural/algorithmic choices.
Theoretical and Practical Implications
FastVMT's architectural enhancements (sliding-window attention and corresponding-window loss) and diffusion algorithmic optimizations (step-skipping gradient reuse) collectively address fundamental inefficiencies in transformer-based training-free video motion transfer. The results demonstrate that local spatial/temporal priors can be leveraged for substantial empirical speedups, transcending incremental hardware or mathematical acceleration by eliminating structural redundancy.
Practically, FastVMT enables real-time controllable video generation, facilitating application in content creation, advertising, cinematic production, and interactive media. Theoretically, FastVMT’s design underlines the significance of harnessing signal locality and temporal smoothness, opening avenues for further research in efficient diffusion-based generative pipelines—such as adaptive sparsification, region-based guidance, and differentiable windowing for tailored gradient flows.
Future Directions
- Hierarchical Locality Modeling: Extending sliding-window mechanisms to multi-scale or non-uniform windowing could further adapt to complex motion regimes.
- Adaptive Gradient Update Scheduling: Incorporating learned or dynamic scheduling for gradient recomputation may optimize the tradeoff between efficiency and accuracy.
- Generalized Redundancy Exploitation: Applying parallel strategies in other generative domains (e.g., audio, 3D, multimodal) where local consistency and gradient stability hold.
Conclusion
FastVMT presents a principled approach to eliminating structural redundancy in training-free motion transfer via diffusion transformers. By combining locality-aware attention extraction and interval-based gradient reuse, it achieves state-of-the-art quality and efficiency. These methodological innovations provide a paradigm for scalable video generation, setting the stage for further advances in efficient control, editing, and customization of generative visual pipelines (2602.05551).

