MotionV2V: Editing Motion in a Video
Abstract: While generative video models have achieved remarkable fidelity and consistency, applying these capabilities to video editing remains a complex challenge. Recent research has explored motion controllability as a means to enhance text-to-video generation or image animation; however, we identify precise motion control as a promising yet under-explored paradigm for editing existing videos. In this work, we propose modifying video motion by directly editing sparse trajectories extracted from the input. We term the deviation between input and output trajectories a "motion edit" and demonstrate that this representation, when coupled with a generative backbone, enables powerful video editing capabilities. To achieve this, we introduce a pipeline for generating "motion counterfactuals", video pairs that share identical content but distinct motion, and we fine-tune a motion-conditioned video diffusion architecture on this dataset. Our approach allows for edits that start at any timestamp and propagate naturally. In a four-way head-to-head user study, our model achieves over 65 percent preference against prior work. Please see our project page: https://ryanndagreat.github.io/MotionV2V


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MotionV2V, a new way to edit videos that changes how things move without changing what they look like. Instead of redrawing or replacing parts of a video, the method keeps the original scene and characters, but lets you adjust their paths, speed, and even the camera’s motion—like making a dog run a different route or zooming the camera out—while the rest of the video stays consistent.
Key Questions the Paper Tries to Answer
- How can we edit the motion in an existing video (where and how things move) while keeping all the original content (the people, objects, background) the same?
- Can users simply “draw” or “drag” the motion they want, and have a model produce a realistic edited video that follows those new paths and timing?
- Can this work for any object or scene, not just humans? And can it handle camera motion and events that appear later in the video?
How the Method Works (in Simple Terms)
Think of your video as a story where characters follow paths. MotionV2V lets you change those paths directly.
- Motion tracks: Imagine placing colored stickers on key points of objects (like the nose of a dog, or the corner of a sign). As the video plays, each sticker moves along a path. These paths are called “trajectories.”
- Motion edits: A motion edit is the difference between the original path of a sticker and the new path you want. For example, if the dog ran straight before, you can draw a curved path instead—this change is the “edit.”
Here’s the basic recipe:
- Track points in the video
- The system follows your chosen points through the video (using a tracker, like a smart tool that keeps its eye on each sticker).
- You can add points to moving objects or even across the scene for camera control.
- Specify the new motion
- You “edit” the paths: drag the points, change when a character enters, or adjust camera zoom/pan by changing many points together.
- You can start an edit at any time, not just the first frame.
- A video diffusion model makes the edit look real
- A “diffusion model” is an AI that builds visuals step by step, like gradually cleaning a noisy image until it looks real.
- MotionV2V feeds the model three things:
- The original video (so it knows the scene and details),
- The original motion tracks (how things did move),
- The target motion tracks (how you want them to move now).
- The model learns to produce a new video: same content, but following your new motion.
- Special training with “motion counterfactuals”
- The team created pairs of videos that show the same scene but different motions (like the same swan on the lake, but once with a zoomed-in camera and once zoomed out).
- These pairs teach the model to keep content the same while changing motion.
- They made these pairs by:
- Reordering or resampling frames to change speed/timing,
- Generating bridging motion between two real frames,
- Applying crops/rotations/zoom consistently to both video and tracks so points still line up.
- Under-the-hood architecture (analogy)
- Think of the model as two cooperating parts:
- The main artist (the base video generator) that draws realistic videos,
- A motion coach (a “control branch”) that whispers instructions about where points should go.
- The motion coach is connected in a gentle way (using tiny “zero-initialized” layers) so it guides the artist without overpowering it. This is inspired by ideas like ControlNet but adapted to video transformers (DiT).
- Think of the model as two cooperating parts:
Main Results and Why They Matter
What MotionV2V can do:
- Edit object motion: Move a dog to a new path, raise someone’s arms, shift a bike rider to the other side—while keeping colors, textures, and background consistent.
- Edit camera motion: Zoom, pan, or change viewpoint, yet keep details like water ripples or buildings consistent across frames.
- Control timing: Delay when an object enters, slow down or speed up movement, or retime interactions between multiple things.
- Edit any frame: You’re not stuck with only the first frame. You can edit things that appear later in the video.
How well it works:
- In user studies, people preferred MotionV2V about 70% of the time over leading alternatives for:
- Preserving the video’s original content,
- Matching the requested motion,
- Overall edit quality.
- On quantitative tests (measuring how close the edited video is to a desired target), MotionV2V had lower errors than other methods, meaning it stayed closer to the ground truth.
Why this is important:
- Most previous tools generate videos from a single image (often the first frame). That misses things that appear later or when the camera moves. MotionV2V uses the entire video, so it can keep everything consistent throughout.
- It enables true “video-to-video” motion editing—changing motion while preserving the scene—as opposed to “image-to-video” generation that often has to invent missing details.
What This Could Mean Going Forward
- Easier video edits for creators and studios: Fix timing, adjust camera moves, or change motion outcomes without reshoots or complex visual effects tricks.
- New creative control: Storytellers can experiment—make one character arrive later, change race outcomes, or re-compose scenes—while keeping the original look.
- Better tools for education and sports: Replay moments with altered motion to study tactics or highlight different paths.
- Foundation for future apps: The approach could become a building block for video editing software where users “paint motion” directly with simple drags and timelines.
In short, MotionV2V shows that you can edit how a video moves while keeping its world intact—opening the door to powerful, flexible, and realistic motion edits without starting from scratch.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The paper leaves the following aspects missing or uncertain:
- Formal evaluation of motion adherence: No quantitative measure of how closely generated trajectories follow the user-specified target tracks (e.g., per-point positional/temporal error, visibility consistency, occlusion ordering accuracy).
- Limited scalability of control points: Inference is capped at ~20 correspondences; there is no analysis of failure modes or strategies to scale to dozens/hundreds of points (e.g., hierarchical control, attention gating, multi-stage conditioning).
- Sensitivity to tracker errors and occlusions: The approach relies on TAPNext for visibility and tracking; robustness to drift, mis-tracks, occlusion mislabeling, and point initialization noise is not evaluated.
- Camera control fidelity and 3D consistency: Camera edits depend on dynamic pointmaps (Monst3r) with unquantified accuracy; there is no evaluation on parallax-heavy scenes, rolling shutter, lens distortion, or intrinsics/extrinsics estimation errors.
- Content preservation guarantees: Despite claiming identical content in counterfactual pairs, there is no audit of appearance drift or identity changes (e.g., texture, color) especially under large motion edits or camera changes.
- Long-horizon stability: Subject drift is acknowledged; the rate of quality degradation and motion/appearance consistency over long videos (>49 frames) or successive edits is not measured or mitigated.
- High-resolution and long-duration scalability: The method is trained at 480×720 and 49 frames; memory/runtime constraints, chunking/streaming strategies, and seamless stitching across chunks remain unaddressed.
- Physical plausibility and kinematic realism: No constraints or metrics prevent unrealistic motion (e.g., foot sliding, limb hyperextension, collision violations) or quantify contact/rigid-body constraints under edits.
- Occlusion and visibility control: While tracks include visibility flags, the model’s ability to synthesize correct occlusion ordering after motion edits (e.g., who passes in front/behind) is not evaluated.
- Multi-object interaction fidelity: Handling interactions (collision avoidance, mutual occlusion, coordinated motion) is not analyzed; there is no metric for preserving inter-object relationships under edits.
- Fairness and comparability of baselines: Baselines use different base models and capacities (e.g., WAN 2.1 14B vs. CogVideoX-5B); the impact of base model strength and architectural differences is not disentangled.
- Benchmarking protocol for motion editing: Existing evaluations rely on L2/SSIM/LPIPS to target frames and small user studies; standardized datasets, ground-truth counterfactuals, and motion-specific metrics are missing.
- Trajectory representation ablation: No ablations on Gaussian blob variance, color coding, dropout rates, number of points, or alternative representations (e.g., dense flow, segmentation masks, 6-DoF object poses).
- Control branch design choices: Duplicating the first 18 DiT blocks is not justified or ablated; the effect of control depth and integration points on performance remains unexplored.
- Training objectives: The method uses standard diffusion L2 noise prediction; there is no explicit loss enforcing trajectory alignment, content preservation, or camera-edit consistency (e.g., pointwise adherence loss in latent space).
- Data generation biases: Counterfactual pairs are created via generator prompts, temporal resampling, and moving crops; whether content is truly “identical” and whether augmentations bias learning toward specific motion regimes is not verified.
- Generalization across domains: Performance on challenging domains (e.g., sports, crowded scenes, underwater, low light, heavy motion blur) and across diverse object types is not reported.
- Geometry under dynamic scenes: Camera edits on scenes with moving backgrounds and deformable objects are not evaluated for geometric consistency and artifact rates (e.g., warping, ghosting).
- Edit locality and propagation: How localized edits propagate across space-time (e.g., unintended changes to unaffected regions) is not quantified; no metric for edit spill-over.
- Text conditioning interplay: The role of text prompts during V2V editing (biasing appearance vs. motion) and risks of semantic drift or unintended appearance changes under motion edits are not analyzed.
- Real user workflows and latency: No measurements of edit latency, interactive responsiveness, or UI usability; practical constraints for iterative editing in production settings are unknown.
- Provenance and safety: No discussion of watermarking, provenance tracking, or safeguards against deceptive motion edits (deepfakes); open questions on responsible deployment remain.
- Reproducibility and data release: The training relies on an internal 500k-video dataset and generated counterfactuals; data, code, and detailed data composition/filters are not released, hindering replication.
- Handling previously unseen content: When camera edits reveal areas never visible in the input video, the model must hallucinate; the extent and quality of such hallucination and its detectability are not evaluated.
- Motion timing control metrics: While timing edits are claimed, there is no metric quantifying temporal alignment (e.g., time-to-event error, acceleration profiles) or assessing time warping artifacts.
- Identity preservation under edits: No specific metric evaluates preservation of identity attributes (e.g., face/body, clothing, logos) when objects are moved or retimed.
- Robustness to variable frame rates and frame drops: The pipeline assumes fixed-length clips; behavior under varying frame rates, dropped frames, or jitter is not studied.
- Cross-model portability: It is unclear whether the control-branch approach generalizes across different base T2V architectures without extensive re-tuning; portability and required adaptations are not examined.
- Failure case taxonomy: Aside from brief mention of subject drift and point-limit failures, no systematic taxonomy and frequency of failure modes (geometry artifacts, identity changes, occlusion errors) is provided.
Practical Applications
Practical, real-world applications of MotionV2V
Below are actionable use cases derived from the paper’s findings and innovations, grouped into immediate and long-term applications. Each item notes relevant sectors, potential tools/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
- Motion-aware post-production fixes in film/TV and VFX
- Sectors: media/entertainment, advertising
- Use cases: re-blocking subject motion without reshoots; camera reframing/zoom changes post-shoot; removing or repositioning occluding elements; timing adjustments (e.g., delaying an entrance) while preserving background motion and scene content
- Tools/workflows: “MotionV2V Editor” plugin for Adobe After Effects/Premiere/DaVinci; point-trajectory UI; iterative edit workflow (track -> edit -> generate -> review -> refine)
- Assumptions/dependencies: access to a capable video diffusion backbone (e.g., CogVideoX-5B or equivalent), accurate point tracking (e.g., TAPNext), and sufficient GPU compute; legal clearance for content alteration
- A/B motion variants for marketing and social media
- Sectors: advertising, e-commerce, creator economy
- Use cases: test different pacing, subject movement, and camera motion for engagement; keep product styling and scene identical across variants
- Tools/workflows: web app/API for batch motion edits; templated trajectory presets; lightweight review pipelines
- Assumptions/dependencies: model quality must preserve brand assets; small number of control points (≈20) per sequence for reliable edits
- Camera motion recomposition and stabilization after capture
- Sectors: media production, AR/VR, education
- Use cases: transform pan/zoom to static or vice versa; adjust focal length/field-of-view while preserving scene appearance (e.g., swan example)
- Tools/workflows: dynamic pointmap estimation (e.g., MONST3R), user-specified camera intrinsics/extrinsics; trajectory deviations solved and applied via MotionV2V
- Assumptions/dependencies: robust camera parameter estimation; model generalization to diverse scenes
- Instructional and educational video refinement
- Sectors: education, fitness/health coaching
- Use cases: retime demonstrations for clarity; reposition objects to reduce occlusions; adjust camera zoom to focus on key steps
- Tools/workflows: classroom or LMS integration; presets for common pedagogical edits (slow panning, step delays)
- Assumptions/dependencies: responsible disclosure when altering motion; usability for non-experts via simplified UI
- AR/VR content comfort tuning and accessibility
- Sectors: XR, accessibility
- Use cases: reduce motion intensity (e.g., slow panning or jitter); reposition moving objects to minimize motion sickness triggers
- Tools/workflows: accessibility profiles mapped to trajectory presets; batch processing across XR libraries
- Assumptions/dependencies: content fidelity must remain high; user consent; alignment with accessibility standards
- Sports coaching demos and highlights enhancement
- Sectors: sports analytics/training
- Use cases: adjust demo pace; emphasize technique by moving occluding players; camera reframing for clarity while preserving play context
- Tools/workflows: trajectory control over key players/ball; highlights toolkit integrated with coaching platforms
- Assumptions/dependencies: strict provenance labels to avoid misrepresentation; limited to explanatory edits, not factual game footage changes
- Product demo personalization for e-commerce
- Sectors: retail/e-commerce
- Use cases: show the same product scene with different motion (pace, object path) for culturally localized storytelling without rebuilding the set
- Tools/workflows: motion templates per campaign; batch edit pipeline for catalog videos
- Assumptions/dependencies: asset rights; model must preserve fine-grained product details
- Synthetic counterfactuals for computer vision research
- Sectors: academia, robotics, CV/ML
- Use cases: create motion counterfactual pairs to stress-test trackers, optical flow, action recognition by varying motion while keeping appearance identical
- Tools/workflows: “Counterfactual Data Generator” script; TAPNext tracking; automated motion augmentations (temporal resampling, frame interpolation)
- Assumptions/dependencies: reproducible pipeline; dataset licensing; accurate visibility handling and point dropout
- Privacy-preserving re-composition
- Sectors: safety/compliance
- Use cases: reposition or delay the appearance of identifiable subjects while preserving background content for internal reviews or educational demos
- Tools/workflows: trajectory edits on faces/subjects combined with standard blur/mask tools
- Assumptions/dependencies: risk of misuse; adherence to privacy laws; strong disclosure and consent practices
- Editorial continuity fixes and compliance
- Sectors: broadcast, corporate communications
- Use cases: correct continuity errors (timing, camera motion) in non-news editorial pieces; recompose scenes for brand consistency
- Tools/workflows: QC pipeline checklists; iterative motion edit followed by legal review
- Assumptions/dependencies: clear editorial guidelines; content labels indicating motion edits
Long-Term Applications
- Reshoot replacement at studio scale
- Sectors: film/TV, high-end VFX
- Use cases: large-scale scene motion rewrites (multi-object, multi-camera) post-capture, reducing costly reshoots
- Tools/workflows: deeply integrated MotionV2V pipeline with production asset management; collaborative trajectory versioning and review tools
- Assumptions/dependencies: higher base-model fidelity to avoid subject drift; robust multi-object control (beyond ≈20 points); standardized camera metadata ingestion
- Real-time or near-real-time motion editing for live broadcast
- Sectors: live sports, events
- Use cases: quick-turn replays with adjusted camera paths or slowed motion for tactical analysis; comfort-tuned camera motion for motion-sensitive audiences
- Tools/workflows: low-latency inference on edge GPUs; operator consoles for live trajectory edits
- Assumptions/dependencies: significant model optimization; dedicated hardware; strict authenticity/provenance protocols
- “What-if” counterfactual analytics in sports, traffic, robotics
- Sectors: sports analytics, transportation, robotics
- Use cases: counterfactual scenarios (alternate player movement, vehicle path) while preserving scene appearance; decision-support and training
- Tools/workflows: analytics platform with motion trajectory editors; simulation-to-video linkages
- Assumptions/dependencies: clear separation between analysis and reality; ethical safeguards; accurate multi-agent control
- On-set virtual cinematography and post-capture camera re-authoring
- Sectors: cinematography, XR production
- Use cases: adjust camera intrinsics/extrinsics after filming; virtual dolly/zoom moves synced to actor motion without re-shoot
- Tools/workflows: camera tracking metadata integration; dynamic pointmap pipelines; lens model libraries
- Assumptions/dependencies: robust geometric estimation; standardized onset metadata; high-fidelity generative backbones
- Consumer-grade mobile apps for intuitive motion editing
- Sectors: consumer software
- Use cases: drag-and-edit motion on smartphones for short-form video; template-driven motion styles
- Tools/workflows: on-device or cloud inference; simplified UI; library of motion presets
- Assumptions/dependencies: efficient models (quantization/distillation); safety rails to prevent deceptive edits; platform policy alignment
- Large-scale synthetic dataset generation for autonomous driving/drones/robotics
- Sectors: automotive, UAVs, robotics
- Use cases: create motion-varied sequences with identical environments for training perception/control systems; stress testing motion prediction
- Tools/workflows: automated counterfactual generation farms; trajectory curricula for edge cases
- Assumptions/dependencies: realism sufficient for sim-to-real transfer; domain-specific validation; licensing for base scenes
- Collaborative motion editing platforms with versioning and provenance
- Sectors: enterprise software, media production
- Use cases: multi-user trajectory editing, review, and approval; embedded content authenticity signatures
- Tools/workflows: trajectory diff/merge; motion edit audit trails; C2PA/metadata integration
- Assumptions/dependencies: industry adoption of provenance standards; secure content workflows
- Standards and policy frameworks for motion-edited media
- Sectors: policy/regulation, digital forensics
- Use cases: disclosure requirements; watermarking of motion edits; detection benchmarks and tools for motion-only manipulations
- Tools/workflows: standardized motion-edit metadata (e.g., C2PA extensions); detector research leveraging trajectory inconsistencies
- Assumptions/dependencies: multi-stakeholder alignment; regulatory buy-in; open datasets of motion-edited content
- Advanced accessibility personalization at scale
- Sectors: accessibility, media platforms
- Use cases: automatic per-user motion adaptation (e.g., reduced camera motion, slower subject movement) without altering scene identity
- Tools/workflows: platform-level motion profiles; batch transforms during upload or playback
- Assumptions/dependencies: user consent and preferences; platform cooperation; reliable motion edits across diverse content
- Creative authoring with composable, iterative motion programs
- Sectors: creative tools, education
- Use cases: chaining motion edits as “programs” (e.g., retime subject, then adjust camera, then alter path); reusable motion recipes for storytelling or pedagogy
- Tools/workflows: motion graph/recipe libraries; trajectory scripting APIs; visual diff of motion edits
- Assumptions/dependencies: robust iterative stability (reduced drift across repeated edits); intuitive programming abstractions
- Deepfake risk management specific to motion-only edits
- Sectors: platform trust/safety, journalism
- Use cases: detecting and flagging motion edits that alter outcomes while preserving appearance; authenticity checks for sensitive contexts
- Tools/workflows: motion-consistency detectors; provenance checks; editorial policies for permissible motion edits
- Assumptions/dependencies: advances in motion-edit detection; clear ethical guidelines; collaboration with media organizations
- Domain-specific motion control packs (e.g., sports, medical, industrial training)
- Sectors: vertical software (sports tech, healthcare training, industrial operations)
- Use cases: prebuilt motion trajectories for common scenarios (serve mechanics, gait rehab pacing, machine operation sequences) applied to real videos
- Tools/workflows: trajectory libraries; domain UIs; KPI-linked motion variants
- Assumptions/dependencies: expert-designed trajectories; validation with domain professionals; careful disclosure to avoid misinterpretation
Notes on general feasibility across applications:
- Model dependencies: quality of the base video diffusion model and VAE encoder/decoder strongly influence realism and drift; current inference is most reliable with ≈20 control points.
- Tracking dependencies: robust, visibility-aware point tracking (e.g., TAPNext) and accurate camera parameter estimation are necessary for precise control.
- Compute and data: training/finetuning require substantial GPU resources and appropriately licensed data; some applications can rely on pretrained models via hosted APIs.
- Ethics and policy: many scenarios require provenance, disclosure, and guardrails to prevent deceptive or harmful use; standards integration (e.g., C2PA) is advisable.
Glossary
- Arbitrary Frame Specification: The ability to apply edits to objects appearing at any point in a video rather than only the first frame; crucial for controlling mid-sequence content. "Arbitrary Frame Specification Unlike image-to-video approaches that rely on the first frame for content generation~\cite{gowiththeflow2025, motionprompt2024, revideo2024}, our framework supports editing objects that appear at any point in the video."
- Bidirectional point tracker: A tracking algorithm that follows points forward and backward in time to maintain consistent correspondences across frames. "We use TAPNext~\cite{tapnext}, a bidirectional point tracker, on ."
- Camera extrinsics and intrinsics: Extrinsics define the camera’s position and orientation in the world; intrinsics define internal parameters like focal length and principal point. "We estimate a dynamic pointmap~\cite{zhang2024monst3r}, reproject it into each frame using user-specified camera extrinsics and intrinsics, and then solve for deviations in the pointwise trajectories."
- CGI: Computer-generated imagery; synthetic visual content used to replace or augment real footage. "VFX pipelines can use tricks like retiming and plate stitching, isolated retimes with rotoscoping, or even full-dog CGI replacements."
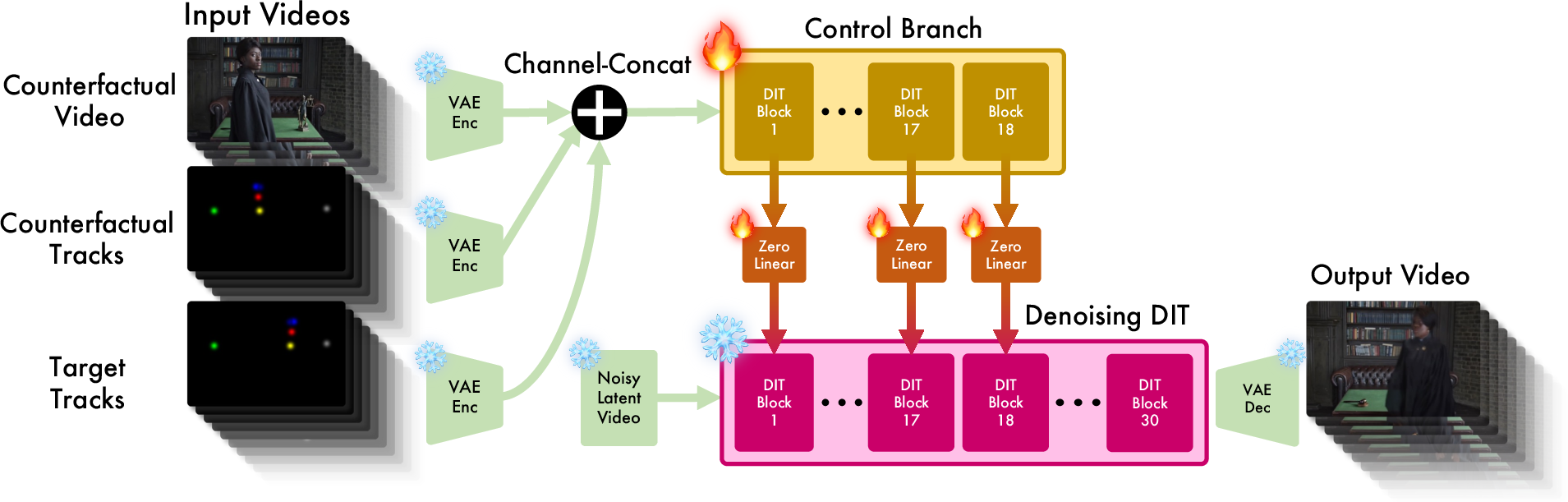
- Control branch: An auxiliary pathway added to a diffusion transformer to process conditioning inputs (e.g., videos and tracks) and influence the main generation. "In order to condition on motion and input videos we incorporate a control branch duplicating the first 18 transformer blocks of the DiT that feeds into the main branch using zero-initialized MLPs."
- ControlNet: A technique that adds conditional control to diffusion models by injecting structured signals through a dedicated network branch. "Conceptually the control branch is similar to a ControlNet~\cite{controlnet2023} applied to a DiT architecture."
- DDIM inversion: A method to invert diffusion sampling, mapping images back to latent noise; often used for editing but fails when structural correspondences change. "This makes the problem harder than appearance-based video editing and renders standard video editing techniques like DDIM inversion ineffective."
- DiT (Diffusion Transformer): A transformer-based diffusion architecture enabling scalable denoising for image/video generation. "We use a pre-trained T2V DiT as our base model~\cite{cogvideox2024}."
- Dynamic pointmap: A representation of scene geometry as time-varying point positions that can be reprojected into frames to reason about motion and camera changes. "We estimate a dynamic pointmap~\cite{zhang2024monst3r}, reproject it into each frame using user-specified camera extrinsics and intrinsics, and then solve for deviations in the pointwise trajectories."
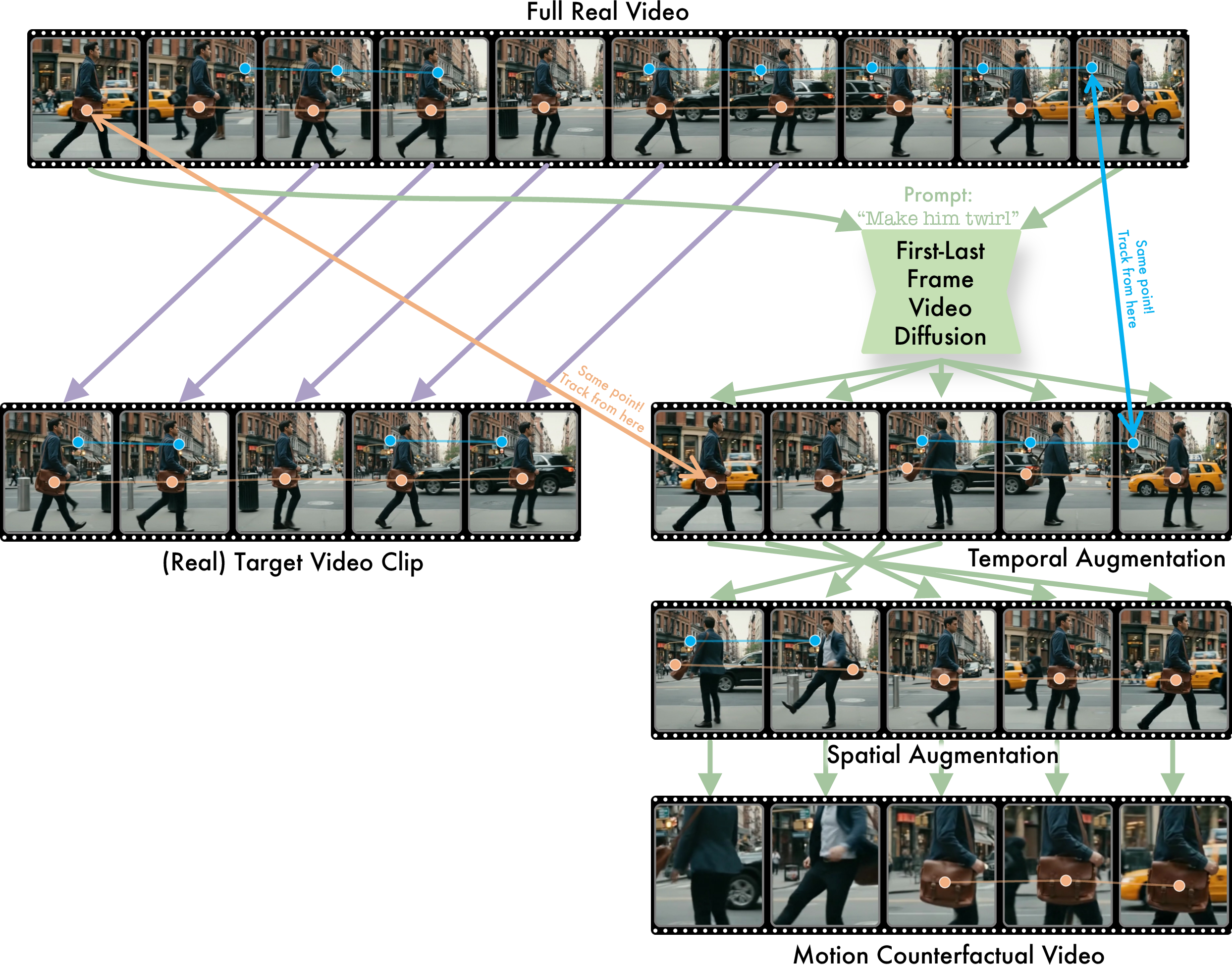
- Frame Interpolation: Generating intermediate frames between two given frames to create smooth motion or new content. "Frame Interpolation: We use a video diffusion model conditioned on frames to generate a -frame video."
- Image-to-video (I2V): Methods that synthesize a video conditioned on a single input image and additional controls, often failing to preserve unseen content. "Image-to-video (I2V) based approaches like Re-Video~\cite{revideo2024} and Go-with-the-Flow~\cite{gowiththeflow2025} can only generate new video with specified motion conditioned on a single image."
- Inpainting: Filling in or reconstructing missing/occluded regions in images or videos using generative priors. "Re-Video attempts to address this problem by inpainting information from the original video into the edited video, a technique which fundamentally breaks down when the video includes camera movement."
- L2 loss: A squared-error loss used to measure reconstruction fidelity between predicted and target frames during training or evaluation. "Training was conducted on 8 H100 GPUs for one week using standard latent diffusion training with L2 loss."
- Latent diffusion training: Training diffusion models in a compressed latent space (rather than pixel space) to improve efficiency and scalability. "Training was conducted on 8 H100 GPUs for one week using standard latent diffusion training with L2 loss."
- Latent representations: Compressed encodings of video frames produced by a VAE, used as input to diffusion transformers. "All video inputs are encoded using a 3D Causal VAE~\cite{cogvideox2024}, which compresses RGB videos of shape to latent representations of shape ..."
- Motion counterfactuals: Video pairs with identical content but different motion patterns used to train motion-conditioned editing models. "We generate these motion counterfactual videos from raw videos using a systematic process that ensures trackable point correspondences between video pairs (Figure~\ref{fig:video_prep})."
- Motion edits: Explicit specifications of how motion should change relative to an input video, applied via trajectory manipulation. "In this work we introduce motion edits, a new approach for editing videos by controlling the change in motion from the original to the edited video using video diffusion models."
- Optical flow: Dense motion field estimating per-pixel displacement between frames; used as a prior for motion-guided generation. "Conversely, optical flow-based methods~\cite{onlyflow2024, animateanything2024} utilize dense correspondence priors derived from optical flow estimators and point trackers~\cite{raft2020, tapir2023, bootstap2024, cotracker3_2024} to achieve fine-grained motion transfer."
- Patchifier: A component that converts input channels into tokenized patches for transformer processing. "our implementation has the key difference of allowing conditioning on three video tracks and using a control branch patchifier that handles input channels for the three conditioning videos in latent space."
- Photometric reconstruction error: A pixel-wise metric (e.g., L2) that measures how well a generated video matches a target video. "We developed a quantitative evaluation protocol using photometric reconstruction error to assess motion editing quality."
- Plate stitching: A VFX technique that combines multiple background plates to form a seamless shot. "VFX pipelines can use tricks like retiming and plate stitching, isolated retimes with rotoscoping, or even full-dog CGI replacements."
- Rasterization (Gaussian blobs): Rendering point tracks as colored Gaussian blobs on a black canvas to provide motion-conditioning inputs. "We rasterize the tracking information as colored Gaussian blobs on black backgrounds to create motion conditioning channels."
- Retiming: Altering the temporal speed or schedule of motion/events in footage. "VFX pipelines can use tricks like retiming and plate stitching, isolated retimes with rotoscoping, or even full-dog CGI replacements."
- Reprojection: Mapping 3D points back into 2D image frames using camera parameters to maintain geometric consistency. "We estimate a dynamic pointmap~\cite{zhang2024monst3r}, reproject it into each frame using user-specified camera extrinsics and intrinsics..."
- Rotoscoping: Frame-by-frame manual/assisted segmentation to isolate or modify elements in video. "VFX pipelines can use tricks like retiming and plate stitching, isolated retimes with rotoscoping, or even full-dog CGI replacements."
- TAPNext: A tracking method that predicts the next token/position for any point across time, enabling robust trajectories. "We use TAPNext~\cite{tapnext}, a bidirectional point tracker, on ."
- Temporal Resampling: Selecting frames at new temporal intervals to create speed changes or reversed motion. "Temporal Resampling: We extract frames evenly spaced between from $$."
- Transformer blocks: Stacked attention-based layers in the diffusion transformer that process tokens over space-time. "we incorporate a control branch duplicating the first 18 transformer blocks of the DiT that feeds into the main branch using zero-initialized MLPs."
- V2V editing (Video-to-Video editing): Approaches that modify an existing video by propagating edits across frames while preserving source content. "Concurrently, video-to-video (V2V) editing methods focus on propagating edits across frames while preserving the features of the source video~\cite{tokenflow2024, fatezero2023, codef2024, pix2video2023, tuneavideo2023, text2videozero2023, cove2024}."
- Zero-init: Initializing control layers to zero so conditioning gradually influences the main branch during training. "The control branch tokens are fed through zero-init~\cite{controlnet2023}, channel-wise MLPs and then added to the main branch token values in their respective transformer blocks."
- Zero-initialized MLPs: Multi-layer perceptrons initialized to zero to safely inject conditioning signals into the main transformer. "we incorporate a control branch duplicating the first 18 transformer blocks of the DiT that feeds into the main branch using zero-initialized MLPs."
Collections
Sign up for free to add this paper to one or more collections.

