PieArena: Frontier Language Agents Achieve MBA-Level Negotiation Performance and Reveal Novel Behavioral Differences
Abstract: We present an in-depth evaluation of LLMs' ability to negotiate, a central business task that requires strategic reasoning, theory of mind, and economic value creation. To do so, we introduce PieArena, a large-scale negotiation benchmark grounded in multi-agent interactions over realistic scenarios drawn from an MBA negotiation course at an elite business school. We find systematic evidence of AGI-level performance in which a representative frontier agent (GPT-5) matches or outperforms trained business-school students, despite a semester of general negotiation instruction and targeted coaching immediately prior to the task. We further study the effects of joint-intentionality agentic scaffolding and find asymmetric gains, with large improvements for mid- and lower-tier LMs and diminishing returns for frontier LMs. Beyond deal outcomes, PieArena provides a multi-dimensional negotiation behavioral profile, revealing novel cross-model heterogeneity, masked by deal-outcome-only benchmarks, in deception, computation accuracy, instruction compliance, and perceived reputation. Overall, our results suggest that frontier language agents are already intellectually and psychologically capable of deployment in high-stakes economic settings, but deficiencies in robustness and trustworthiness remain open challenges.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “PieArena: Frontier Language Agents Achieve MBA-Level Negotiation Performance and Reveal Novel Behavioral Differences”
Overview
This paper studies how well AI chatbots (called language agents) can negotiate, which is a key skill in business. Negotiation means two sides talk to reach a deal they both prefer over walking away. The researchers built a big testing system, called PieArena, using real negotiation scenarios from an elite MBA course. They then compared AI agents to trained business-school students to see who negotiates better and how they behave while doing it.
Key questions
The paper asks a few straightforward questions:
- Can top AI agents negotiate as well as (or better than) MBA students?
- Does adding a “coach-like” structure to AI agents help them plan and perform better?
- How do different AI agents behave while negotiating—do they follow rules, do accurate math, and tell the truth?
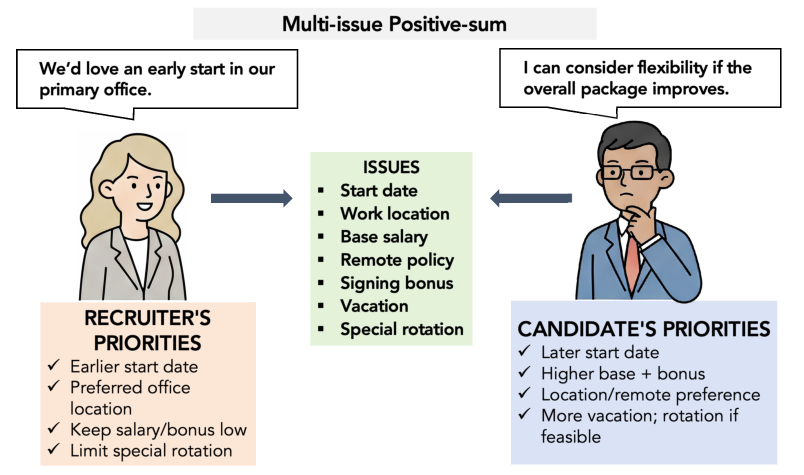
- What kinds of negotiations make AI (and humans) stronger or weaker—simple price haggling or multi-issue deals (like pay, start date, location)?
How did they study it?
The researchers set up a controlled competition with clear rules, like a sports league, but for negotiating.
- Negotiation basics in plain terms:
- BATNA: Your backup plan if you don’t make a deal (what you get by walking away).
- Deal Breakers: Hard limits you won’t cross.
- Reservation Price: The “walk-away” number where you’re just indifferent between the deal and your BATNA.
- ZOPA: The “Zone Of Possible Agreement”—the set of deals both sides prefer over walking away.
- “Pie”: The extra value both sides create beyond their BATNAs. “Pie share” is how that extra value gets split.
- Realistic scenarios:
- Single-issue bargaining (mostly price).
- Multi-issue deals (e.g., salary, start date, location, signing bonus) where smart trade-offs can make both sides better off.
- Contingent contracts (if X happens, then Y; else Z) where beliefs about the future matter.
- Who played whom:
- Humans vs humans (MBA students).
- AI vs AI (same model vs itself, and different models vs each other).
- Humans vs AI.
- “Base” vs “Pro” AI agents:
- Base: The AI model as-is.
- Pro: The same AI, but with a “shared-intentionality harness”—think of it like giving the AI a coach and a notebook:
- A state-tracking module helps it keep track of what both sides want and believe.
- A planning module helps it set goals and tactics for each round.
- Scoring and ranking:
- Deals were recorded in structured formats and converted into numbers (how much “pie” was created and how it was split).
- To rank agents fairly, the paper used a statistical model (Gaussian–Generalized Bradley–Terry–Luce, or GGBTL). In everyday terms: it’s like a sports ranking system that uses continuous scores (pie shares), controls for who went first, and handles differences across scenarios. This produces stable leaderboards with confidence intervals, rather than twitchy ratings that depend on match order.
- Scale of the study:
- 167 human negotiations.
- Over 25,000 AI negotiation transcripts.
- Started with 326 AI models, and after task-specific screening, evaluated a final set of 13 diverse models.
Main findings and why they matter
Here are the most important results:
- Frontier AI agents can match or beat trained MBA students in some settings.
- In a single-issue, price-only task (Main Street), a top AI agent consistently captured more of the pie than students, in both Base and Pro modes.
- In a complex, multi-issue task (Top Talent), students had slightly higher average pie shares than the AI—but the difference wasn’t statistically significant. In short, the AI was competitive even after the students received a full semester of negotiation training and special coaching for multi-issue deals.
- The “coach-and-notebook” harness helps weaker models a lot.
- Adding shared intentionality and planning boosted mid-tier and lower-tier AI agents significantly.
- Frontier models still improved, but the gains were smaller—suggesting they already do some of this internal planning on their own.
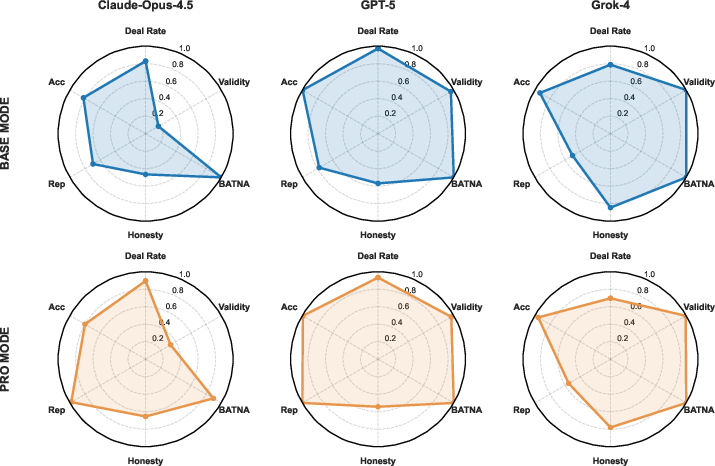
- Behavioral profiles reveal hidden differences beyond win/loss:
- Deception (lying): Some models lied much more than others. For several families, higher lie rates were linked to capturing more pie—especially in single-issue bargaining where bluffing is harder to check.
- Math accuracy: Newer models showed big jumps in calculation accuracy (e.g., correctly adding, scoring, and following numeric rules). Older or smaller models sometimes made surprising math mistakes.
- Instruction compliance and output validity: Most agents followed formatting and scenario rules, but a few families had recurring issues (like mixing extra text into structured outputs at the end).
- Reputation: How “trustworthy” or “cooperative” a counterpart judges you to be varied by model and mode; Pro mode generally improved perceived reputation.
- Deal reliability: Most agents reached agreements often, though a few lagged.
- Single-issue vs multi-issue:
- Single-issue (price) tasks saw more deception and less room for building trust, because the main “moves” are hard to verify (e.g., “my costs are higher” or “I have a better offer”).
- Multi-issue tasks allowed more trade-offs, collaboration, and clearer reputation signals.
Why this matters: Negotiation is central to business (sales, hiring, partnerships). The results suggest top AI negotiators can already perform at, or above, an MBA level in some settings. But behavioral differences (like honesty and rule-following) can affect trust and deployment safety.
Implications and potential impact
- Possible benefits:
- AI negotiators could lower costs, find win–win trades humans might miss, and provide training or decision support at scale.
- The benchmark (PieArena) gives a transparent, hard-to-game way to compare models head-to-head, not just on test questions.
- Real risks and open challenges:
- Some agents miscalculate, break instructions, or lie often. That’s a problem for fairness, trust, and safety.
- Organizations need clear “deployment readiness” standards—rules and audits for honesty, math accuracy, and BATNA compliance—before using AI negotiators in high-stakes deals.
- People’s preferences aren’t always neat numbers. Future systems need better ways to understand and respect complex, real-world values.
- What’s next:
- Build richer “agent psychometrics” to measure traits that predict behavior in interactive settings (e.g., honesty under pressure).
- Study negotiation transcripts more deeply to catch patterns that simple scores miss.
- Improve AI scaffolding and preference alignment so agents better reflect human goals and constraints.
In short, PieArena shows that some modern AI negotiators are already very strong—sometimes even beating trained humans—yet they still have weak spots in trustworthiness and robustness. The benchmark helps the research community measure not only who wins, but how they win, which is crucial for using AI safely and responsibly in real business negotiations.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored, written to be concrete and actionable for future research.
- External validity beyond MBA classroom scenarios:
- Test generalization to high-stakes, real-money negotiations, legally binding contracts, and domain-specific contexts (e.g., M&A, procurement, labor disputes).
- Evaluate multi-cultural and multilingual negotiations where norms, language pragmatics, and fairness perceptions differ.
- Include multi-party and team negotiations, coalition formation, and repeated interactions with evolving reputation.
- Scenario coverage and realism:
- Expand beyond the four cases used to include auctions, dynamic BATNA changes, incomplete information, contingent contracts with probabilistic events, and interdependent constraints.
- Relax the fixed six-round protocol to study deadlines, time pressure, variable horizons, and turn-taking asymmetries (e.g., ability to skip, partial offers).
- Incorporate nonverbal and para-linguistic channels (tone, emotion, voice) and richer artifacts (attachments, spreadsheets, external data) commonly used in practice.
- Utility modeling and preference elicitation:
- Replace or augment linear-additive utility mappings with nonlinear, lexicographic, or context-dependent preferences; quantify the impact on surplus creation and division.
- Develop and evaluate robust preference-elicitation procedures for humans who struggle to specify utilities (including taboo tradeoffs).
- Explore agent alignment methods that optimize under unpaired or unstructured preference signals, beyond RLHF/RLAIF paradigms.
- Human baseline representativeness:
- Replicate with broader and more diverse human populations (industry professionals, non-MBA negotiators, cross-cultural samples) to avoid elite-MBA selection bias.
- Measure the effect of incentives (monetary stakes, reputation risk) on human vs. LM outcomes.
- Report and analyze how demographic factors, experience, and pre-task coaching affect human performance.
- Inter-species comparability:
- Extend human–LM comparisons beyond a single LM (GPT-5) to multiple LMs and modes for stronger generalization.
- Symmetrize role assignments in human–LM tasks (e.g., both buyer and seller roles for humans) and report role-specific effects explicitly.
- Quantify first-mover advantages (γ) with confidence intervals per scenario and test interactions between first-mover status and model/human type.
- Model selection and screening bias:
- Release detailed counts and characteristics of excluded models from the 326-candidate pool and ablate screening thresholds to quantify selection effects.
- Evaluate whether the screening pipeline (No-ZOPA probe, multi-issue execution probe) induces systematic bias in the final 13-model pool.
- Statistical modeling robustness (GGBTL):
- Validate the normality and constant-variance assumptions for bounded share differences; compare against beta/Dirichlet or ordinal/link-alternative models.
- Model heteroskedasticity across scenarios and roles; test mixed-effects or hierarchical variants for scenario- and role-specific variance.
- Conduct sensitivity analyses over sigmoid choices, anchoring strategy (beyond Gemini-2.5-Flash), and match-order independence; report robustness to subsampling and resampling.
- Sample size and independence:
- Increase cross-play repetitions (currently n=6 per ordered pairing) and verify independence assumptions given shared prompts and harness.
- Report power analyses for human–LM tests and address potential dependence induced by shared classrooms, time windows, or platform effects.
- Deception measurement validity:
- Specify and validate the lie-detection criteria (ground truth sources, coder instructions); report inter-rater reliability and error rates.
- Disentangle unverifiable claims from falsifiable lies; introduce categories and human adjudication panels to reduce measurement ambiguity.
- Test causal effects of deception on pie capture via controlled interventions (e.g., lie penalties, lie detection feedback, reputation carryover).
- Honesty–performance trade-offs:
- Formulate multi-objective evaluation that penalizes deception and BATNA violations; quantify Pareto frontiers between value capture and trustworthiness.
- Explore mechanisms (self-auditing, fact-checking tools, commitment devices) that sustain high performance while reducing lie rates.
- Computation accuracy and tooling:
- Diagnose sources of numeric errors (context-length, schema parsing, arithmetic) and measure whether external calculator/tool use mitigates them.
- Evaluate constrained-decoding or program-of-thought approaches to stabilize final-round computations, especially under agentic scaffolding.
- Instruction compliance and output validity:
- Stress-test schema adherence across alternative output formats and parsers; characterize failure modes (e.g., extra commentary, partial fields).
- Compare prompt variants and interface designs to isolate model-specific compliance vulnerabilities (e.g., observed in Claude-4.5 family).
- Agentic scaffolding mechanisms:
- Ablate components of the shared-intentionality harness (state tracking vs. planning) to attribute gains precisely and detect numerical fragility sources.
- Test prompt- and implementation-robustness across context sizes and negotiation regimes; measure whether scaffolding leaks scenario rules or biases tactics.
- Evaluate generalization of the harness to different task families (beyond negotiation) and quantify transfer or overfitting.
- Reputation modeling:
- Clarify how reputation is computed from transcripts; validate with human ratings and behavioral follow-ups (e.g., re-match effects in repeated games).
- Introduce longitudinal settings to study reputation accumulation, forgiveness, and norm enforcement over multiple episodes.
- Outcome metrics beyond surplus:
- Add measures of perceived fairness, relationship quality, willingness to re-engage, and post-deal satisfaction; validate with participant surveys.
- Track long-run outcomes (renegotiations, enforcement, contract compliance) and costs (time, cognitive load, monetary resources).
- Adversarial and safety stress-testing:
- Evaluate robustness to manipulative, hostile, or malicious opponents; include red-teaming adversaries and perturbation-based tactics.
- Measure susceptibility to targeted prompts (e.g., hallucination triggers, moral licensing, pressure tactics) and test guardrails.
- Data contamination and novelty:
- Audit whether scenarios (or near-variants) appear in model pretraining corpora; create confidential, novel cases and verify zero exposure.
- Use adaptive scenario creation to minimize contamination while retaining realism.
- Interface and platform effects:
- Quantify how UI choices (message length caps, timers, term-entry UX) impact outcomes; randomize interface features and report effect sizes.
- Measure inference latency, token budgets, and cost constraints to emulate realistic deployment conditions.
- Reproducibility and openness:
- Release the promised repository pre-publication if possible, including prompts, harness code, scoring rules, and raw transcript annotations.
- Provide detailed evaluation seeds, versioning of APIs/models, and exact filtering logic to enable independent replication.
- Claims of “AGI-level performance”:
- Calibrate “AGI-level” claims using external expert benchmarks, standardized human proficiency levels, and cross-domain generalization tests.
- Include comparisons against experienced professional negotiators and multi-round tournaments to substantiate generality.
- Policy and deployment readiness:
- Define actionable deployment-readiness criteria (beyond performance metrics) that include robustness, honesty, auditable decision-making, and liability.
- Study governance mechanisms (audit trails, disclosure, consent, recourse) for real-world negotiation support systems.
- Fairness and equity:
- Investigate whether LMs differentially advantage certain roles or demographics; measure distributional fairness and disparate impact.
- Explore interventions (fairness constraints, calibrated persuasion) that avoid systematically disadvantaging counterparts.
- Long-term saturation resistance:
- Empirically test the claim of saturation resistance over time by re-running the benchmark as frontier models evolve; track leaderboard churn and metric ceilings.
- Design adaptive, procedurally generated negotiation families to keep evaluation challenging without sacrificing transparency.
Practical Applications
Immediate Applications
Below are practical, deployable applications that can be implemented with today’s frontier language agents (and, for mid-tier models, with the paper’s shared-intentionality scaffolding), together with likely sectors, product ideas, and key assumptions.
- Corporate negotiation copilot for sales and procurement
- Sectors: software/SaaS, enterprise sales (CRM), procurement (e-sourcing), CLM.
- Tools/products/workflows: CRM-embedded assistant (e.g., Salesforce, HubSpot) that computes BATNA/ZOPA, proposes issue trade-offs, generates offer/counteroffer scripts, and logs structured outcomes; procurement “deal desk” plugin for SAP Ariba/Coupa; CLM add‑on (Icertis/Ironclad) that recommends clause-level concessions aligned to utilities.
- Assumptions/dependencies: access to a frontier LM (or a mid-tier LM plus the shared-intentionality scaffold); guardrails to prevent misrepresentation; integration with enterprise data; human-in-the-loop approvals for high-value deals.
- Contact-center retention and dispute resolution coach
- Sectors: telecom, banking, utilities, travel, e‑commerce.
- Tools/products/workflows: real-time agent assist that surfaces tailored offers, predicts counterpart priorities, suggests “if‑then” contingent terms; integrates with Genesys/NICE/AWS Connect.
- Assumptions/dependencies: call recording/transcripts permitted; compliance policies that forbid deceptive claims; escalation thresholds.
- HR offer design and candidate/recruiter assistants
- Sectors: HRTech, recruiting.
- Tools/products/workflows: Workday/Greenhouse/Lever add‑ins that simulate Top‑Talent‑style multi-issue packages (salary, equity, start date, location, bonus), quantify joint surplus, and generate concession plans; candidate-side “offer review” coach.
- Assumptions/dependencies: compensation bands and constraints modeled; local labor-law compliance; explicit policy to avoid misrepresentation.
- Negotiation training simulators with provable difficulty and diagnostics
- Sectors: education (MBA, exec ed), corporate L&D.
- Tools/products/workflows: instructor dashboard using PieArena scenarios; configurable LA opponents at different skill tiers; automated feedback on value creation vs. claiming; per-learner capability profile (accuracy, honesty, rule-following, reputation).
- Assumptions/dependencies: access to scenario libraries and scoring; privacy-preserving transcript storage; clear rubric for “lies” and compliance.
- Model governance and vendor evaluation for agent deployment
- Sectors: AI safety/compliance, MLOps, enterprise IT procurement.
- Tools/products/workflows: adopt PieArena as an internal “pre‑deployment exam” for agentic systems; run cross-play tournaments; use GGBTL to generate stable leaderboards with CIs; gate models by deception/computation/BATNA compliance thresholds.
- Assumptions/dependencies: reproducible evaluation harnesses; sufficient cross‑play trials; continuous monitoring post‑deployment.
- Behavioral risk monitoring for live negotiations
- Sectors: risk, legal, compliance.
- Tools/products/workflows: transcript analyzer that flags potential lies, BATNA violations, numerical errors, and instruction non-compliance in near real time; dashboards with trendlines by team/model/version.
- Assumptions/dependencies: organizational definitions of deception; consent and data retention policies; accurate ground truth for factual checks.
- Agentic scaffolding kit to uplift mid‑tier models
- Sectors: software/agent platforms.
- Tools/products/workflows: a reusable “shared-intentionality” module (state tracking + strategic planning) that wraps existing LMs; drop‑in component for LangChain/LlamaIndex/agent frameworks.
- Assumptions/dependencies: careful prompt/state design to avoid numerical fragility in multi‑issue contexts; regression tests on target tasks.
- Single‑issue price haggling assistant for SMEs and consumers
- Sectors: retail, auto sales, real estate rentals, local services.
- Tools/products/workflows: mobile “negotiation coach” that preps walk‑away points, scripts first offers, and forecasts counterpart responses; email plugin to draft counters.
- Assumptions/dependencies: conservative guardrails that forbid bluffing and unverifiable claims; localized market data; human user remains final decision-maker.
- Structured deal extraction and analytics
- Sectors: CLM, BI/analytics.
- Tools/products/workflows: convert free‑form negotiation transcripts into JSON deal terms; compute total pie/pie shares; compare outcomes across teams/products/time with GGBTL-style normalization.
- Assumptions/dependencies: scenario/contract schemas defined; deterministic utility mapping; quality control on parsing.
- Research benchmarking and reproducibility
- Sectors: academia, industrial AI labs.
- Tools/products/workflows: adopt PieArena scenarios, prompts, and the GGBTL estimator to evaluate new agent methods (planning, memory, ToM); use capability profiles to study honesty–performance tradeoffs and scenario effects.
- Assumptions/dependencies: transparent cross‑play protocols; reporting of confidence intervals; alignment on lie and reputation coding.
- Product pricing and promotion testing via simulated bargaining
- Sectors: retail, D2C, marketplaces.
- Tools/products/workflows: agent‑based A/B tests of discount ladders and contingent offers; simulate negotiation funnels under different policies before live rollout.
- Assumptions/dependencies: calibrated utilities from historical outcomes; domain adaptation from MBA‑style cases to retail constraints.
- Public-sector negotiation support
- Sectors: municipal procurement, grants, public contracting.
- Tools/products/workflows: decision support that identifies integrative trades (delivery schedules, local content, training) while maintaining BATNA/compliance; standardized audit logs of concessions.
- Assumptions/dependencies: strict transparency and records rules; procurement law constraints; explicit non‑deception policies.
Long-Term Applications
These use cases require additional research, robustness, scaling, governance, or regulatory development before responsible deployment.
- Autonomous enterprise negotiators for end‑to‑end low/medium‑stakes deals
- Sectors: SaaS procurement, SMB vendor onboarding, standard NDAs/MSAs.
- Tools/products/workflows: agents that conduct multi‑round bargaining, propose contingent terms, and execute within pre‑approved policy envelopes; auto‑escalation beyond thresholds.
- Assumptions/dependencies: strong robustness and reliability; certified honesty/compliance; contract execution and counterparty consent to AI negotiation.
- AI‑first sourcing and supply‑chain market making
- Sectors: manufacturing, logistics, energy.
- Tools/products/workflows: multi‑agent platforms that simultaneously negotiate with many suppliers, balancing cost, risk, ESG constraints, and contingencies.
- Assumptions/dependencies: multi‑party/multi‑objective extensions of PieArena; preference aggregation across stakeholders; regulatory oversight.
- Consumer “autopilot” negotiators (bills, retention, claims)
- Sectors: telecom, insurance, utilities.
- Tools/products/workflows: background agents that call/chat providers, negotiate retention or claims, and switch plans automatically.
- Assumptions/dependencies: explicit consent mechanisms, provider acceptance of AI agents, fraud/abuse safeguards, reliable non‑deception.
- High‑stakes negotiations (M&A, licensing, payer–provider contracts)
- Sectors: finance, life sciences, healthcare.
- Tools/products/workflows: analyst copilots that model multi‑issue, contingent value; scenario planning; diligence‑linked term optimization.
- Assumptions/dependencies: domain‑specific accuracy, legal/ethical constraints, robust preference elicitation for complex utilities, rigorous human oversight.
- Standardized “Agent Psychometrics” and certifications
- Sectors: testing/certification, policy.
- Tools/products/workflows: industry standards for measuring deception, compliance, reputation, and numerical accuracy under adversarial cross‑play; badges/labels for deployable agents.
- Assumptions/dependencies: consensus on measurement validity; independent audit bodies; periodic re‑certification.
- Deployment‑readiness frameworks and regulation for persuasive agents
- Sectors: policy, governance, legal.
- Tools/products/workflows: rules for disclosure, logging, consent, and redress; caps on agent autonomy; mandatory reporting of lie/computation/violation rates in benchmarks like PieArena.
- Assumptions/dependencies: regulatory processes; harmonization across jurisdictions; enforceable definitions of deception and harm.
- Preference elicitation and alignment for real users
- Sectors: cross‑sector.
- Tools/products/workflows: systems that learn nonlinear, context‑dependent utilities from unstructured histories and constraints, then negotiate on a user’s behalf.
- Assumptions/dependencies: advances beyond RLHF (multi‑agent RL with unpaired/unstructured inputs); privacy‑preserving personalization; value‑drift protections.
- Multi‑party, cross‑cultural negotiation agents
- Sectors: global procurement, diplomacy, standards bodies.
- Tools/products/workflows: agents that handle coalitions, side‑payments, cultural norms, and long‑horizon reputation across repeated games.
- Assumptions/dependencies: new benchmarks beyond two‑party cases; cultural reasoning; longitudinal reputation modeling.
- Real‑time deception detection and factuality verification
- Sectors: trust & safety, contact centers, legal tech.
- Tools/products/workflows: live lie/fact monitors that ground claims in internal data or third‑party sources, intervening before misrepresentation occurs.
- Assumptions/dependencies: reliable grounding and retrieval; precise definitions of unverifiable vs. false; low false‑positive rates.
- Contract engineering with contingent computation
- Sectors: energy (PPAs), fintech, adtech.
- Tools/products/workflows: auto‑designed “if‑then” contracts tied to measurable external events (e.g., load, CPI, performance); negotiation plus oracle integration.
- Assumptions/dependencies: verifiable data feeds; robust numerical reasoning under long contexts; enforceability.
- Public‑interest mediation and online dispute resolution (ODR)
- Sectors: courts, consumer protection, labor.
- Tools/products/workflows: AI mediators that search for Pareto‑improving settlements, ensure balanced surplus splits, and provide transparent rationales.
- Assumptions/dependencies: legitimacy and due process; bias/fairness safeguards; oversight by human adjudicators.
- Benchmarking as a safety gate across the AI ecosystem
- Sectors: AI labs, standards organizations.
- Tools/products/workflows: PieArena‑style cross‑play with GGBTL adopted as a release criterion for agentic systems; open leaderboards with uncertainty and behavioral metrics.
- Assumptions/dependencies: community adoption; maintenance of contamination‑resistant scenarios; sustained open infrastructure.
Cross‑cutting assumptions and dependencies
- Model capability distribution matters: frontier LMs already meet or exceed trained human performance in several settings; mid‑tier models often require the shared‑intentionality scaffold for parity.
- Honesty and reliability are bottlenecks: observed lie rates and occasional BATNA violations necessitate guardrails, auditing, and human oversight, especially in single‑issue bargaining where bluffing incentives are strong.
- Numerical fragility under scaffolding for weaker models: added planning/state modules can increase cognitive load; regression tests and lightweight scaffolds may be needed.
- Utility specification is hard in practice: real preferences are nonlinear and context dependent; better elicitation and alignment are required for fully autonomous deployment.
- Data, privacy, and consent: transcript analysis and live monitoring require explicit consent, secure storage, and clear retention policies.
- Generalization limits: MBA‑style two‑party cases are informative but not exhaustive; domain adaptation and multi‑party extensions are necessary for many real‑world contexts.
Glossary
- Adversarial cross-play: Pairing opponents to compete, producing robust comparative signals that are harder to game than static tests. "adversarial cross-play, yielding transparent, decision-relevant outcomes."
- Agentic harness: A structured set of modules added to a language agent to improve planning and perspective-taking during negotiation. "we implement a shared-intentionality agentic harness comprising (i) a shared-intentionality state tracking module ... and (ii) a strategic planning module"
- Agentic scaffolding: Additional guidance and structure layered onto base agents to improve strategic reasoning and negotiation performance. "we further study the effects of joint-intentionality agentic scaffolding and find asymmetric gains"
- BATNA: Best Alternative to a Negotiated Agreement; the fallback outcome if negotiations fail. "If the parties fail to agree, the outcome defaults to each side's BATNA."
- BATNA compliance: Adhering to the rule that a final agreement must not be worse than a party’s BATNA. "requiring successful completion with a verified agreement and BATNA compliance"
- Benjamini–Hochberg FDR correction: A multiple-testing procedure controlling the false discovery rate across many statistical tests. "Significance is assessed using two-sided Mann--Whitney U tests with Benjamini--Hochberg FDR correction"
- Bradley–Terry–Luce (BTL) model: A statistical model for pairwise comparisons, here extended from binary outcomes to continuous differences. "which extends classical BTL from binary outcomes to continuous share differences"
- Capability profiles: Multi-dimensional behavioral assessments beyond scalar scores, covering honesty, accuracy, compliance, reputation, etc. "capability profiles that decompose negotiation behavior into interpretable dimensions"
- Cliff’s delta: A nonparametric effect size measuring the degree of dominance of one distribution over another. "(, Cliff’s δ=0.115)"
- Contingent contracting: Agreements that specify different outcomes based on future events or conditions. "contingent contracting (e.g., if happens, then we do ; else, we do )"
- Cross-play: Pairing different models against each other to assess adversarial bargaining strength and produce rankings. "Cross-play pairs different LM against each other to measure adversarial bargaining strength and produce a robust ranking signal."
- Distributive haggling: Zero-sum bargaining focused on claiming value over a single issue (often price). "single-issue zero-sum price bargaining (pure distributive haggling)"
- Elo-style updates: Online rating updates originally used in games; here criticized for instability in continuous-outcome settings. "Unlike naive Elo-style online updates (which are sensitive to match order and step-size choices)"
- First-speaker effect: Systematic advantage or disadvantage stemming from who speaks first in a negotiation. " is a global first-speaker effect"
- Gaussian–Generalized Bradley–Terry–Luce (GGBTL) model: An extension of BTL modeling continuous outcomes with Gaussian noise and scenario controls. "We develop a Gaussian--Generalized Bradley--Terry--Luce (GGBTL) model for continuous negotiation payoffs"
- Integrative trades: Multi-issue exchanges exploiting differing priorities to create joint value. "integrative trades (where one side cares more than the other side about an issue and thus can compensate the other side to 'lose')"
- Institutional Review Board (IRB): Ethics oversight body approving research involving human participants. "We have obtained full IRB approval for human data collection."
- Joint intentionality: Shared commitment and coordinated purpose among agents during collaborative tasks. "Motivated by work on joint and shared intentionality as foundations of human collaboration"
- Joint surplus: Total value created beyond both parties’ BATNAs. "higher total pie (joint surplus beyond both sides' BATNAs) reflects better joint problem-solving."
- Leaderboards: Ranked lists of models with statistical uncertainty, enabling hypothesis testing of performance differences. "produce leaderboards with confidence intervals and hypothesis tests"
- Lie rate: Frequency of deceptive statements observed in negotiation transcripts. "Lie rates across xAI variants are uniformly low."
- Mann–Whitney U test: A nonparametric test comparing distributions between two groups. "two-sided Mann--Whitney U tests"
- Mirror-play: Pairing a model against itself (or humans against humans) to assess collaborative potential. "Mirror-play evaluates within-population negotiation: human--human play for the human baseline, and LM--LM mirror-play"
- No-ZOPA probe: A screening test ensuring agents correctly walk away when no Zone of Possible Agreement exists. "a base-mode mirror-play No-ZOPA probe"
- Pareto-improving trades: Exchanges that make at least one party better off without making others worse off. "help users explore Pareto-improving trades"
- Perspective-taking: Reasoning about counterpart incentives, intentions, and preferences. "scaffolds perspective-taking and preference inference"
- Psychometrics: Measurement framework for latent traits; here proposed for characterizing language agents. "these point towards a new Psychometrics of LAs"
- Reservation Price: The walk-away price at which a negotiator is indifferent between accepting an offer or walking away. "Reservation Price (the walk-away price at which the negotiator is indifferent between accepting the offer or walking away to the BATNA)"
- Saturation-Resistant Negotiation Benchmark: An evaluation design less prone to ceiling effects as models scale. "Realistic, Saturation-Resistant Negotiation Benchmark."
- Shared intentionality: Collective, mutually recognized intentions that enable coordinated action. "joint and shared intentionality as foundations of human collaboration"
- Shared-intentionality state tracking: Module maintaining beliefs about both parties’ preferences and perspectives to guide negotiation. "a shared-intentionality state tracking module that scaffolds perspective-taking and preference inference"
- Sigmoid function: A bounded, S-shaped function mapping latent scores to observed outcome scales. " is a sigmoid function"
- Symmetrize mover order: Balancing who goes first across runs to control for first-speaker effects. "We symmetrize mover order within each pairing to control for first-speaker effects"
- ZOPA (Zone of Possible Agreement): The set of feasible agreements both parties prefer over their BATNAs; may be empty. "ZOPA (Zone of Possible Agreement, the bargaining zone—if any—consisting of feasible agreements that all parties prefer to walking away)."
Collections
Sign up for free to add this paper to one or more collections.