Fast-SAM3D: 3Dfy Anything in Images but Faster
Abstract: SAM3D enables scalable, open-world 3D reconstruction from complex scenes, yet its deployment is hindered by prohibitive inference latency. In this work, we conduct the \textbf{first systematic investigation} into its inference dynamics, revealing that generic acceleration strategies are brittle in this context. We demonstrate that these failures stem from neglecting the pipeline's inherent multi-level \textbf{heterogeneity}: the kinematic distinctiveness between shape and layout, the intrinsic sparsity of texture refinement, and the spectral variance across geometries. To address this, we present \textbf{Fast-SAM3D}, a training-free framework that dynamically aligns computation with instantaneous generation complexity. Our approach integrates three heterogeneity-aware mechanisms: (1) \textit{Modality-Aware Step Caching} to decouple structural evolution from sensitive layout updates; (2) \textit{Joint Spatiotemporal Token Carving} to concentrate refinement on high-entropy regions; and (3) \textit{Spectral-Aware Token Aggregation} to adapt decoding resolution. Extensive experiments demonstrate that Fast-SAM3D delivers up to \textbf{2.67$\times$} end-to-end speedup with negligible fidelity loss, establishing a new Pareto frontier for efficient single-view 3D generation. Our code is released in https://github.com/wlfeng0509/Fast-SAM3D.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Fast-SAM3D: 3Dfy Anything in Images but Faster — Explained Simply
1. What is this paper about?
This paper is about making a powerful 3D tool called SAM3D run faster. SAM3D can take a single photo of a scene plus a simple outline of an object (a mask) and build a detailed 3D model of that object. It works well, but it’s slow. The authors created Fast-SAM3D, a way to speed up SAM3D without retraining it, while keeping the 3D results accurate and detailed.
2. What questions did the researchers ask?
They focused on two main questions, explained simply:
- Why is SAM3D slow, and which parts of it take the most time?
- Can we make SAM3D faster by being smart about where and when it does the heavy work—without hurting the quality of the 3D models?
3. How did they approach the problem?
First, they studied SAM3D to see where time is spent. They found three bottlenecks:
- Two “step-by-step” generators that gradually improve the shape and texture (think of repeatedly cleaning up a blurry picture until it becomes clear). These take many steps.
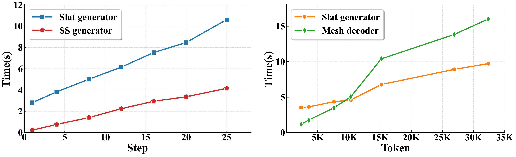
- A decoder that turns lots of small information pieces (called tokens, like tiny Lego blocks of data) into a final 3D mesh. This is expensive when there are lots of tokens.
They noticed that different parts of the model behave differently:
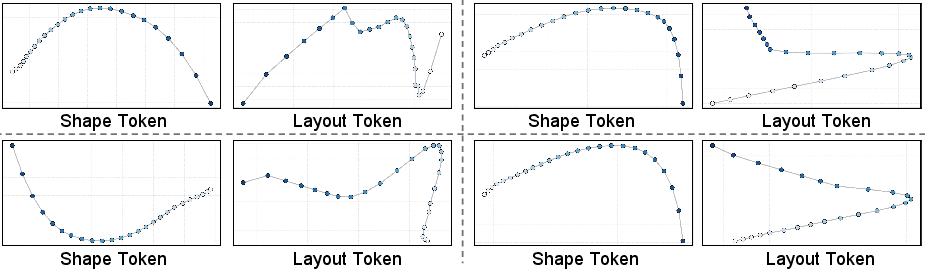
- “Shape” information changes smoothly over time, like a clay sculpture being refined.
- “Layout” information (pose, position, size) is very sensitive—small mistakes can make the object drift or tilt wrongly.
- “Texture” updates are sparse—only detailed areas (edges, patterns) need lots of attention.
- Some objects are simple (like a ball), while others are complex (like a bike), so they shouldn’t be treated the same when decoding.
To fix this, they introduced three smart, training-free tricks (no retraining needed). Here are the ideas with everyday analogies:
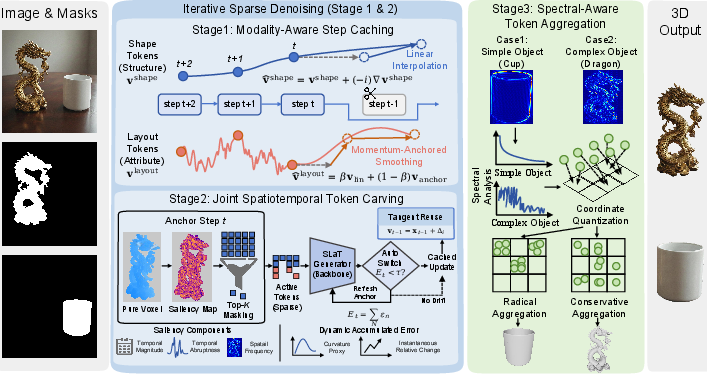
- Modality-Aware Step Caching: Treat shape and layout differently.
- For shape: reuse and predict the next steps using the recent trend (like guessing the next frame in a smooth animation).
- For layout: blend prediction with a reliable “anchor” from the last full calculation, so the object doesn’t drift (like checking your map often to avoid getting lost).
- Joint Spatiotemporal Token Carving: Focus effort where it matters most.
- Space: Pay more attention to areas with lots of detail (edges, corners, thin parts) and less to smooth surfaces (like polishing only the parts that still look rough).
- Time: When changes are small and predictable, reuse recent results instead of doing full work every step (like skipping steps when nothing much is changing).
- Spectral-Aware Token Aggregation: Adapt decoding to object complexity.
- “Spectral” here is like thinking in frequencies, similar to music: low-frequency = smooth, high-frequency = detailed.
- Measure how “complex” an object is using both its 2D outline and its rough 3D shape. If it’s simple, group nearby tokens more aggressively to save time; if it’s complex, keep more tokens to preserve detail (like using bigger brush strokes on simple parts and fine brushes on intricate designs).
Together, these tricks reduce unnecessary work and keep the quality strong.
4. What did they find, and why is it important?
They ran many tests and found:
- Fast-SAM3D speeds up the whole process by up to 2.67× for single objects and about 2.01× for full scenes.
- The 3D quality stays almost the same—and sometimes even gets slightly better—because focusing on important areas reduces noise.
- Other “generic” speed-up methods didn’t work well here. Some made the object layout drift (wrong pose or position), and others lost important details. Fast-SAM3D avoids these problems by being aware of how different parts of the 3D generation behave.
This matters because faster 3D building means more practical use:
- It moves SAM3D closer to real-time applications.
- Artists, game developers, and engineers can get 3D models quickly from photos.
- It saves computing power and energy.
5. Why does this matter in the bigger picture?
Fast-SAM3D shows that instead of using one-size-fits-all shortcuts, we should adapt to the “heterogeneity” (the different behaviors) inside complex AI systems:
- Treat shape, layout, and texture differently because they evolve differently.
- Focus effort where details are high and skip where changes are low.
- Adapt to each object’s complexity.
Because it’s training-free, anyone using SAM3D can add these speed-ups without retraining big models. This can help:
- 3D content creation for movies, games, and VR/AR.
- Quick prototyping in design and engineering.
- Educational tools that turn photos into 3D models faster.
In short, the paper presents a smart, practical way to “do less work where it doesn’t help” and “do enough work where it really matters,” making single-image 3D reconstruction both fast and reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored, framed to guide future research:
- Generalization beyond SAM3D: How well do the three modules (modality-aware step caching, spatiotemporal token carving, spectral-aware aggregation) transfer to other single-view 3D diffusion pipelines (e.g., Hunyuan3D, Trellis) and to alternative representations (implicit fields, point clouds)?
- Decoder coverage: The paper mentions both mesh and 3D Gaussian splatting decoders but only evaluates mesh; does the framework yield similar speed–fidelity trade-offs for GS decoding and other 3D heads?
- Theoretical guarantees: There is no formal analysis bounding error accumulation or drift for cached steps (layout pose, geometry topology). Under what conditions are the proposed caches provably stable?
- Solver compatibility: How do the caching/carving strategies interact with different diffusion samplers (e.g., DDPM, DDIM, DPM-Solver, ancestral samplers) and varying step schedules?
- Hyperparameter robustness: Many critical parameters (cache stride k, momentum β, carving weight γ, K for top-K, error threshold 𝔼, spectral thresholds τlow/τhigh, frequency cutoff, fusion weight w) lack systematic sensitivity analysis across object types, scenes, and samplers; can these be auto-tuned online or learned?
- Overhead accounting: The paper does not quantify the compute/memory overhead of the added modules (FFT on 2D/3D inputs, curvature estimation, token masks, coordinate quantization) and their net contributions to speedups across hardware.
- Hardware/precision portability: Speedups are reported without detailed hardware, precision, and batch configurations; how do results vary across GPUs/CPUs, FP16/FP8/INT8, and memory-constrained devices (mobile/edge)?
- Energy efficiency: FLOPs reductions are shown, but energy consumption and thermal behavior on common deployment platforms are not measured.
- Real-time interactivity: Claims of enabling interactive deployment lack end-to-end latency measurements within an interactive application loop (including mask extraction, pre/post-processing, visualization).
- Mask quality sensitivity: Reconstruction depends on input masks; robustness to segmentation errors, noisy masks, partial masks, and misaligned masks is not evaluated or quantified.
- Occlusion and clutter robustness: Performance under severe occlusions, cluttered scenes, motion blur, and low-light conditions remains untested; how do the modules behave under these harder real-world conditions?
- Failure-mode analysis: The paper does not characterize where Fast-SAM3D degrades (e.g., thin structures, highly specular/translucent materials, fine textures)—nor the types of artifacts introduced by token carving or spectral aggregation.
- Multi-object interactions: While “scene time” is reported, the impact of concurrent object reconstruction (cross-object interference, scheduling/caching across multiple objects, shared context tokens) is not analyzed.
- Spectral metric design: The dual-domain HFER metric uses fixed thresholds; alternative complexity estimators (e.g., wavelets, multi-resolution spectral features, learned predictors) and their trade-offs are unexplored.
- Adaptive K scheduling: Token carving uses a fixed top-K per step; can K be dynamically scheduled per timestep or per region based on confidence/uncertainty to improve fidelity further?
- Saliency proxy validity: Temporal saliency uses norms and first/second differences; comparisons against other proxies (e.g., gradient norms, attention maps, uncertainty estimates) are not provided.
- Aggregation operator choice: Max pooling is used for bin aggregation; how do other permutation-invariant aggregators (mean, median, learned pooling, attention within bins) affect mesh fidelity and speed?
- Topology preservation: Coordinate quantization and token merging may alter fine topology; formal and empirical measures of topology preservation (holes, genus changes, self-intersections) are missing.
- Layout-token handling: Momentum-anchored smoothing fixes β; dynamic or data-driven β schedules (or hybrid anchor strategies) are not explored, nor is integration with external pose/layout estimators.
- Dataset scope: Evaluation focuses on Toys4K, ADT, ISO3D; broader coverage across diverse real-world categories, outdoor scenes, and long-tail objects is needed to validate “open-world” claims.
- Perceptual validation: Aside from Uni3D and standard geometry metrics, no user study or human perceptual evaluation is conducted to assess semantic consistency and visual realism at scale.
- Synergy with training-based accelerators: Interactions with (and potential gains from) distillation, consistency models, and quantization are not studied; can lightweight fine-tuning amplify training-free modules?
- Reproducibility and determinism: The impact of random seeds, non-deterministic GPU kernels, and caching stochasticity on reconstruction repeatability is not reported.
- Memory footprint: Detailed VRAM usage and memory-pressure effects (especially with caching buffers and masks) are not provided; how does the approach behave under tight memory budgets?
- End-to-end pipeline integration: How does the acceleration interact with the upstream condition encoders (e.g., DINOv2 variants) and downstream post-processing (mesh cleaning, ICP alignment) in production systems?
Glossary
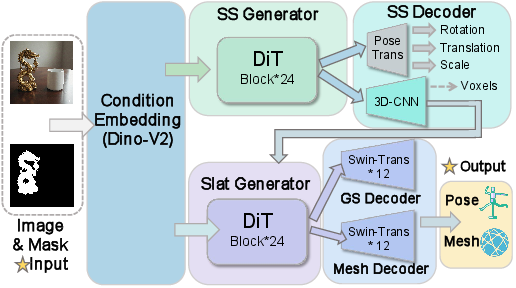
- 3D Gaussian splatting (GS) decoder: A renderer that represents scenes with 3D Gaussians to efficiently synthesize views. "including a mesh decoder and a 3D Gaussian splatting (GS) decoder."
- anchor-corrected prediction: A cached estimation method that blends linear extrapolation with a stable reference to reduce drift. "We introduce an anchor-corrected prediction that blends a linear trend with a stable anchor from the most recent full backbone evaluation."
- Chamfer Distance (CD): A geometric metric measuring the average closest-point distance between two point sets (e.g., predicted vs. ground-truth shapes). "Chamfer Distance (CD), F-Score, and Volumetric IoU (vIoU)"
- combinatorial complexity: Computational explosion due to large combinations or dense structures, making decoding expensive. "the combinatorial complexity of processing dense voxel tokens in the mesh decoder."
- coordinate quantization: Discretizing continuous 3D coordinates to merge nearby tokens for efficiency. "we quantize its coordinates"
- curvature proxy: A numeric proxy for local nonlinearity of a trajectory to decide when cached updates are safe. "We estimate local nonlinearity via a curvature proxy"
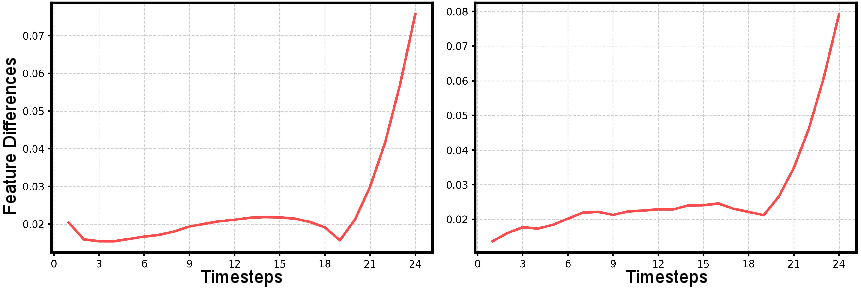
- diffusion trajectory: The path of latent variables evolving through timesteps in a diffusion process. "the diffusion trajectory is non-uniform"
- error-bounded switching: A control rule that triggers full computation when accumulated approximation error exceeds a threshold. "Error-bounded switching."
- Fast Fourier Transform (FFT): An algorithm to compute frequency spectra efficiently, used to assess detail complexity. "Fast Fourier Transform (FFT)"
- geometric spectral entropy: A frequency-domain complexity measure of shape signals guiding adaptive decoding. "utilizes geometric spectral entropy to aggressively compress simple shapes"
- High-frequency energy ratio (HFER): The proportion of signal energy residing in high frequencies, indicating geometric complexity. "we define the high-frequency energy ratio (HFER) as"
- high-entropy regions: Areas with high uncertainty or detail where refinement should be focused. "concentrate refinement on high-entropy regions"
- instance-agnostic downsampling: Uniform reduction in resolution that ignores object-specific complexity. "instance-agnostic downsampling erases high-frequency details on complex shapes."
- Iterative Closest Point (ICP): An algorithm to align two 3D shapes by iteratively refining rigid transforms. "meshes aligned via Iterative Closest Point (ICP)"
- joint spectral metric: A combined frequency-domain score from 2D and 3D signals to measure object complexity. "we compute a joint spectral metric"
- Joint Spatiotemporal Token Carving: A mechanism that selects and updates only salient tokens across space and time. "Joint Spatiotemporal Token Carving dynamically eliminates redundancy by concentrating refinement compute solely on high-entropy regions;"
- kinematic distinctiveness: Different dynamical behaviors (e.g., stability vs. sensitivity) across modalities like shape and layout. "the kinematic distinctiveness between stable shape evolution and sensitive layout updates"
- layout tokens: Latent tokens encoding global pose, translation, and scale of the object. "layout tokens exhibit high-frequency volatility."
- mask-conditioned: A model conditioned on an object mask to focus reconstruction on specified regions. "mask-conditioned, open-world multi-object reconstruction"
- max pooling: A permutation-invariant aggregation operator selecting maximum features within groups. "we use max pooling:"
- Modality-Aware Step Caching: A caching policy that treats different token modalities (shape vs. layout) with distinct update rules. "Modality-Aware Step Caching to decouple structural evolution from sensitive layout updates;"
- momentum-anchored smoothing: A stabilized extrapolation that blends momentum with a recent ground-truth anchor to prevent drift. "Momentum-anchored smoothing for layout tokens."
- Pareto frontier: The set of solutions offering the best trade-off between competing objectives (e.g., speed vs. quality). "establishing a new Pareto frontier for efficient single-view 3D generation."
- pose drift: Gradual misalignment of estimated pose over time due to approximation errors. "uniform skipping induces pose drift"
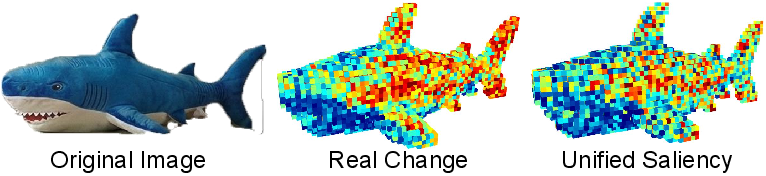
- saliency map: A score map highlighting regions that warrant higher computational focus. "our unified saliency map accurately predicts this pattern."
- semantic drift: Unintended change in semantic attributes during generation due to unstable updates. "step-skipping baselines like TaylorSeer exhibit severe semantic drift"
- single-view reconstruction: Recovering 3D geometry from a single image input. "single-view reconstruction model SAM3D"
- Spectral-Aware Token Aggregation: An adaptive token reduction scheme guided by frequency-domain complexity. "Spectral-Aware Token Aggregation to adapt decoding resolution."
- spectral variance: Variation in frequency content across shapes that affects detail preservation. "the spectral variance across geometries."
- tangent update reuse: Reapplying a cached tangent-like offset to approximate model outputs at skipped steps. "Tangent update reuse."
- training-free: Methods that accelerate inference without additional training or fine-tuning. "a training-free framework"
- Volumetric IoU (vIoU): Intersection-over-Union computed on volumetric representations to evaluate 3D overlap. "Volumetric IoU (vIoU)"
- voxel-aligned bin: Groups of tokens mapped to the same quantized voxel coordinate for aggregation. "voxel-aligned bin"
- shape tokens: Latent tokens encoding the object’s structural geometry. "shape tokens evolve along a smooth path"
Practical Applications
Overview
Below is a structured set of practical, real-world applications that build on the paper’s findings and innovations in Fast-SAM3D. Each item specifies the use case, sector(s), potential tools/products/workflows, and key assumptions or dependencies, and is categorized as either immediate or long-term based on deployability.
Immediate Applications
These applications can be deployed now using the training-free Fast-SAM3D framework and the released codebase.
- [Industry] Accelerated SKU-to-3D pipeline for e-commerce
- Sectors: Retail, Advertising/Marketing, Software
- What: Convert single product images with masks into usable 3D assets for web viewers and AR product previews, cutting GPU hours per SKU via modality-aware step caching and spectral-aware token aggregation.
- Tools/workflows: Batch microservice in the cloud; export GLB/USDZ; integrate with Shopify/Shopware, Unity/Unreal product viewers; QC loop with Uni3D/vIoU thresholds.
- Assumptions/dependencies: Requires reasonably accurate object masks; performance gains depend on GPU; quality validation needed for glossy/transparent items.
- [Industry] Rapid concept-art-to-3D for game/film previsualization
- Sectors: Media & Entertainment, Software
- What: Designers can turn single-view concept frames into provisional meshes and textured assets 2.67× faster for iterative ideation.
- Tools/workflows: Blender/Unreal/Unity plugins; Fast-SAM3D as an inference add-on; export to DCC pipelines; automatic token carving for high-entropy detail preservation.
- Assumptions/dependencies: Fine detail fidelity hinges on spectral-aware aggregation thresholds; artists may retopologize before production.
- [Industry] AR staging for real estate and interior design
- Sectors: Real Estate, AR/VR/XR, Software
- What: Generate furniture/fixture models from listing photos for rapid AR staging and layout planning.
- Tools/workflows: Mobile/web AR viewers; on-demand API that ingests photo+mask; mesh decoder with adaptive downsampling for simpler items.
- Assumptions/dependencies: Per-object masks (multi-object scenes require instance selection); occlusions may limit reconstruction completeness.
- [Industry] Insurance claims and asset documentation from photos
- Sectors: Insurance, Risk Management, Software
- What: Fast single-photo reconstructions of damaged goods or small incident scenes for adjusters, enabling quicker assessments.
- Tools/workflows: Claims app uploads; inference microservice; mesh plus 3D Gaussian splats for visual inspection; ICP alignment to reference catalog.
- Assumptions/dependencies: Reconstruction accuracy depends on view quality, lighting, and mask; not a substitute for multi-view photogrammetry for complex claims.
- [Industry] Robotics pick-and-place initialization from monocular cameras
- Sectors: Robotics, Manufacturing
- What: Generate coarse 3D geometry and layout parameters from a single frame to bootstrap grasp pose hypotheses.
- Tools/workflows: Perception stack integration; modality-aware caching to preserve pose; downstream physics/grasp simulation; active-token masks focus compute on edges/grasp-relevant regions.
- Assumptions/dependencies: Needs robust segmentation; thin parts/high-frequency objects may require relaxed token aggregation; safety validation is essential.
- [Daily life] Photo-to-3D for hobbyist 3D printing
- Sectors: Consumer software, Maker communities
- What: Turn a single photo into a printable mesh, with accelerated mesh decoding for simple shapes.
- Tools/workflows: Desktop app with STL export; lightweight post-processing (watertight fixes, supports); spectral-aware downsampling for speed on consumer GPUs.
- Assumptions/dependencies: Mesh may need manifold repair; quality depends on object visibility and mask quality.
- [Daily life] Social media UGC: 3D stickers/emojis from photos
- Sectors: Social platforms, Mobile apps
- What: Create stylized 3D stickers from a single selfie/object photo, enabling on-device or near-real-time generation.
- Tools/workflows: Mobile inference with joint token carving to lower compute; export GLB for AR filters; style transfer post-processing.
- Assumptions/dependencies: Mobile deployment may need quantization/distillation on top of Fast-SAM3D; per-user privacy safeguards.
- [Academia] Benchmarking heterogeneity-aware acceleration in 3D diffusion
- Sectors: Research, Education
- What: Use Fast-SAM3D as a reference to study kinematic/spectral heterogeneity in single-view 3D generation; compare caching/pruning strategies.
- Tools/workflows: Public code; datasets (Toys4K, ADT, ISO3D); metrics (CD, F-score, vIoU, Uni3D); reproducible ablations of β, K, τ thresholds.
- Assumptions/dependencies: Requires familiarization with SAM3D internals; consistent hardware configs for fair comparisons.
- [Policy] Immediate energy-efficiency gains in public-sector AI pilots
- Sectors: Government, Sustainability
- What: Adopt training-free acceleration to reduce GPU-hours in pilot digitization projects (e.g., museum artifact previews).
- Tools/workflows: Procurement specs that prefer heterogeneity-aware acceleration; energy/carbon dashboards measuring per-job savings.
- Assumptions/dependencies: Transparent reporting and standardized metrics; careful validation of cultural heritage fidelity.
- [Industry] Digital twin seeding from single images
- Sectors: Manufacturing, Logistics
- What: Quickly initialize small-object twins from single documentation photos, then refine later with multi-view.
- Tools/workflows: Pipeline stage that runs Fast-SAM3D for a coarse asset; subsequent photogrammetry pass merges details; adaptive scheduling per object complexity.
- Assumptions/dependencies: Intended as a coarse seed, not final CAD; mesh alignment to plant metadata required.
Long-Term Applications
These applications will benefit from further research, scaling, or development (e.g., on-device optimization, integration with quantization/distillation, domain-specific validation).
- [Industry] On-device single-view 3D capture for smartphones and XR headsets
- Sectors: Mobile, XR, Software
- What: Real-time or near-real-time 3Dfy from a single snapshot on consumer hardware.
- Tools/workflows: Combine Fast-SAM3D with quantization/distillation and low-rank adapters; dynamic token masks mapped to mobile accelerators; background segmentation.
- Assumptions/dependencies: Requires substantial model slimming; hardware-aware scheduling; privacy-preserving on-device processing.
- [Industry] Real-time 3D asset creation in creative tools
- Sectors: Media & Entertainment, Software
- What: Interactive “paint-to-3D” workflows where users see assets update live as they edit a single image prompt or mask.
- Tools/workflows: DCC plugins leveraging curvature-aware caching; progressive mesh decoding with spectral thresholds; GPU scheduling that prioritizes active regions.
- Assumptions/dependencies: Tight UI integration; latency must be <500 ms for usability; robust undo/redo and provenance tracking.
- [Industry] Autonomous retail robots with single-view reconstruction for dynamic inventory
- Sectors: Robotics, Retail
- What: Robots reconstruct and identify objects from single shelf frames to update counts and detect misplaced items.
- Tools/workflows: Token carving fused with semantic saliency; per-object layout anchoring to reduce pose drift; downstream SKU matching.
- Assumptions/dependencies: Domain adaptation and robustness to occlusions; safety/accuracy certification before deployment.
- [Academia] Generalized heterogeneity-aware accelerators for 3D diffusion families
- Sectors: Research
- What: Extend modality-aware and spectral-aware policies to other 3D generative pipelines (implicit fields, multi-view diffusion).
- Tools/workflows: Unified libraries for step caching, token carving, spectral aggregation; standard benchmarks for cross-method speed-fidelity Pareto curves.
- Assumptions/dependencies: Requires model-specific profiling; different representations may need new saliency proxies.
- [Policy] Standards for energy-efficient 3D generation in public procurement
- Sectors: Government, Sustainability
- What: Establish guidelines that favor heterogeneity-aware acceleration methods, with measurable targets for GPU-hours and fidelity thresholds.
- Tools/workflows: Reference metrics (CD, F-score, vIoU, Uni3D) plus energy/carbon accounting; auditability of acceleration parameters (e.g., β, τ).
- Assumptions/dependencies: Multi-stakeholder alignment on acceptable fidelity loss; transparent reporting frameworks.
- [Industry] 3D asset marketplaces with auto-quality grading and cost-aware rendering
- Sectors: Platforms, Advertising
- What: Marketplaces auto-grade single-view assets produced with acceleration, priced by fidelity tiers and production cost savings.
- Tools/workflows: Automated scoring pipelines; token-carving logs for provenance; spectral complexity tags for buyers.
- Assumptions/dependencies: Community acceptance of grading standards; enforcement against misleading reconstructed items.
- [Daily life] Consumer-level “scan later” workflows
- Sectors: Consumer apps, XR
- What: Users capture quick single photos that are later refined into high-fidelity 3D via hybrid cloud pipelines.
- Tools/workflows: Edge capture with Fast-SAM3D coarse model; cloud refinement adds multi-view or photometric consistency; device-friendly previews.
- Assumptions/dependencies: Seamless sync; privacy controls; connectivity for deferred refinement.
- [Industry] Photo-to-CAD translation assistance
- Sectors: Manufacturing, Engineering
- What: Use accelerated single-view recon as a scaffold for semi-automatic CAD reconstruction.
- Tools/workflows: Mesh-to-CAD fitting; spectral-aware aggregation tuned to preserve key edges; human-in-the-loop parametric constraints.
- Assumptions/dependencies: Complex engineering tolerances; significant domain-specific post-processing.
- [Academia/Industry] Hardware-software co-design for token-aware scheduling
- Sectors: Semiconductor, Systems
- What: Specialized accelerators that natively support spatiotemporal token carving and adaptive caching for 3D workloads.
- Tools/workflows: Runtime APIs that expose token masks; memory hierarchies optimized for active bins; max-pool aggregation primitives.
- Assumptions/dependencies: Multi-year hardware cycles; standardization across frameworks.
- [Policy] Provenance and disclosure norms for reconstructed content
- Sectors: Regulation, Ethics
- What: Policies that require tagging and disclosure when single-view reconstructions are used in media, advertising, or public documentation.
- Tools/workflows: Embedded metadata; reproducibility logs of acceleration parameters; moderate fidelity thresholds for sensitive domains.
- Assumptions/dependencies: Cross-industry consensus; enforcement mechanisms; user education.
Notes on Feasibility and Dependencies
- Inputs: Fast-SAM3D assumes a single image plus an object mask; mask quality critically affects reconstruction outcomes.
- Model compatibility: Designed around SAM3D’s pipeline; adapting to other 3D generators requires profiling and calibration of saliency and spectral metrics.
- Hardware: Reported speedups (up to 2.67×) depend on GPU and implementation details; mobile/on-device use will need quantization/distillation.
- Fidelity trade-offs: Spectral-aware aggregation and token carving introduce instance-adaptive reductions; thresholds (β, K, τ) should be tuned per domain.
- Ethics and compliance: Ensure rights to input images; apply provenance tags for reconstructed assets; validate in regulated domains (e.g., insurance, cultural heritage).
Collections
Sign up for free to add this paper to one or more collections.

