- The paper introduces a dual-mode pre-training strategy that unifies MV- and 3D-oriented paradigms to produce high-quality 3D scenes within seconds.
- It leverages cross-mode distillation with a consistency loss to enhance visual fidelity and ensure semantic coherence while drastically reducing inference time.
- Robust performance is achieved through out-of-distribution co-training on diverse datasets, supporting both text-to-3D and image-to-3D scene generation applications.
FlashWorld: High-Quality 3D Scene Generation within Seconds
FlashWorld introduces a unified, efficient framework for high-fidelity 3D scene generation from a single image or text prompt, achieving significant improvements in both visual quality and inference speed over prior methods. The approach departs from the conventional multi-view-oriented (MV-oriented) paradigm by directly generating 3D Gaussian representations, and further bridges the quality gap between MV- and 3D-oriented pipelines through a novel dual-mode pre-training and cross-mode distillation strategy.

Figure 1: FlashWorld enables fast and high-quality 3D scene generation across diverse scenes.
Background and Motivation
3D scene generation is a central problem for applications in gaming, robotics, and immersive environments. Traditional pipelines either assemble pre-existing 3D assets or reconstruct scenes from multi-view images, but these approaches often lack semantic coherence and multi-view consistency. The dominant MV-oriented paradigm employs a two-stage process: a diffusion model generates multi-view images, followed by 3D reconstruction. However, this leads to geometric and semantic inconsistencies and high computational overhead, with generation times ranging from several minutes to hours.
Recent 3D-oriented methods, which combine differentiable rendering with diffusion models, offer direct 3D scene generation but typically suffer from visual artifacts and require additional refinement, further impacting efficiency. Existing distillation techniques for diffusion models, such as consistency model distillation and distribution matching distillation (DMD), can accelerate inference but tend to amplify the limitations of their respective paradigms.








Figure 2: A brief comparison of different 3D scene generation methods.
Methodology
Dual-Mode Pre-Training
FlashWorld's core innovation is a dual-mode pre-training strategy, leveraging a video diffusion model as the backbone. The model is trained to operate in both MV-oriented and 3D-oriented modes:
- MV-oriented mode: Optimized for high visual fidelity, generating multi-view images conditioned on camera parameters and input (image or text).
- 3D-oriented mode: Outputs 3D Gaussian Splatting (3DGS) parameters, ensuring inherent 3D consistency by decoding multi-view features into 3D Gaussians and rendering novel views.
The denoising network is a Diffusion Transformer (DiT) augmented with 3D attention blocks. Camera parameters are encoded using Reference-Point Plücker Coordinates. The 3DGS decoder is initialized from the latent decoder, with modifications to support the additional Gaussian parameters.
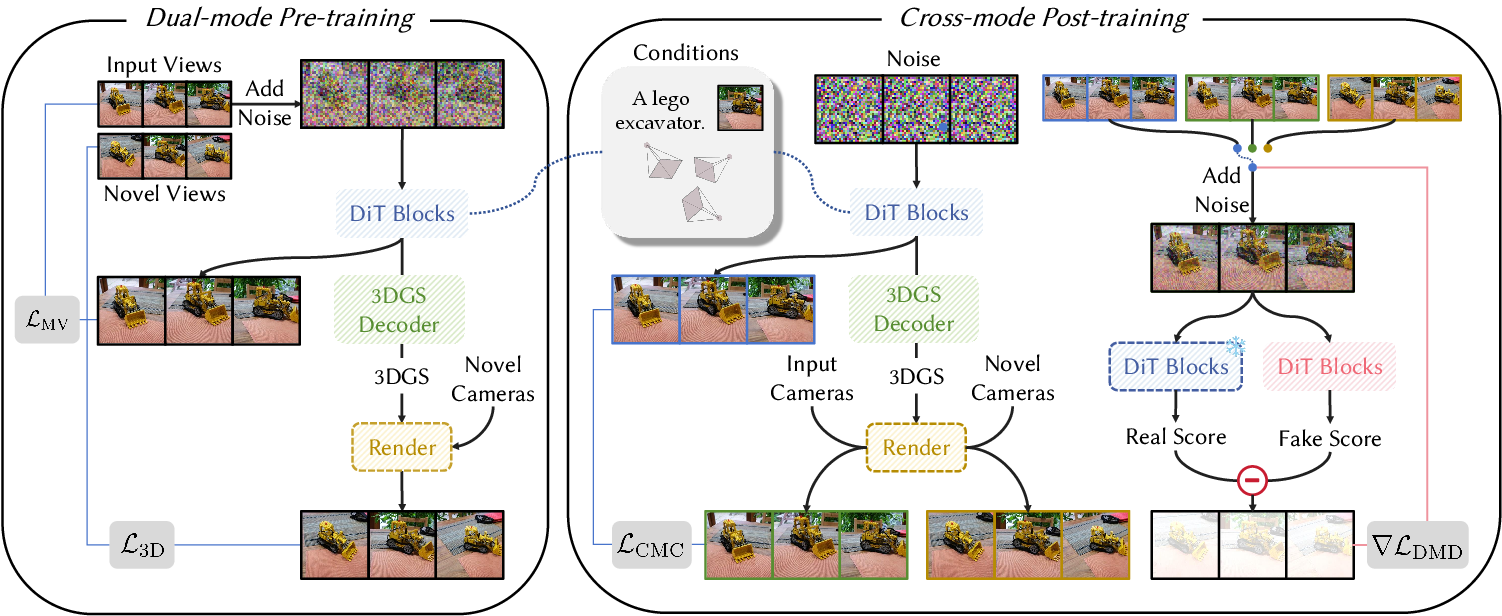
Figure 3: Method overview.
Cross-Mode Post-Training Distillation
To bridge the quality gap, FlashWorld employs a cross-mode post-training distillation strategy:
- The MV-oriented mode (teacher) provides high-quality visual supervision.
- The 3D-oriented mode (student) learns to match the teacher's distribution via DMD2, inheriting visual fidelity while maintaining 3D consistency.
- The student model is distilled into a few-step generator, drastically reducing inference time.
A cross-mode consistency loss regularizes the 3D-oriented mode using predictions from the MV-oriented mode, mitigating artifacts such as floating or duplicated elements.
Out-of-Distribution Data Co-Training
To enhance generalization, FlashWorld incorporates massive single-view images and text prompts with simulated camera trajectories during post-training. This strategy broadens the input distribution, improving robustness to out-of-distribution scenarios and diverse camera paths.
Experimental Results
Image-to-3D Scene Generation
FlashWorld demonstrates superior qualitative results compared to state-of-the-art MV-oriented baselines (CAT3D, Bolt3D, Wonderland), producing scenes with higher fidelity, more accurate geometry, and fewer artifacts. Baselines suffer from blurry textures, missing details, and geometric inconsistencies, while FlashWorld recovers intricate structures and maintains semantic coherence.






Figure 4: Image-to-3D scene generation results of different methods.
Text-to-3D Scene Generation
Against leading text-to-3D methods (Director3D, Prometheus, SplatFlow, VideoRFSplat), FlashWorld achieves more realistic, detailed, and semantically aligned scenes. Baselines exhibit blurry artifacts, incorrect geometries, and poor background realism, whereas FlashWorld generates fine-grained details and robust object structures.


Figure 5: Text-to-3D scene generation results of different methods.
Quantitatively, FlashWorld outperforms all baselines on most quality metrics (Q-Align, CLIP IQA+, CLIP Score) across T3Bench, DL3DV, and WorldScore datasets, while achieving an order-of-magnitude reduction in inference time (9 seconds per scene on a single H20 GPU).
WorldScore Benchmark
On the WorldScore benchmark, FlashWorld attains the highest average score and fastest inference among all compared methods, excelling in style consistency and subjective quality. While slightly trailing in 3D consistency and content alignment (attributable to the lack of explicit depth supervision), FlashWorld's qualitative results reveal fewer unnatural transitions and more faithful scene generation.
Figure 6: 3D scene generation results of different methods on WorldScore benchmark.
Ablation Studies
Ablation experiments confirm the necessity of each component:
- MV-oriented models (with or without distillation) yield noisy, inconsistent reconstructions.
- 3D-oriented models without distillation produce blurry results.
- Removing cross-mode consistency loss leads to floating/duplicated artifacts.
- Excluding out-of-distribution data reduces semantic alignment and generalization, especially on benchmarks with distribution shifts.












Figure 7: Qualitative ablation studies.
RGBD Rendering and Depth Generalization
Despite the absence of explicit depth supervision, FlashWorld's 3DGS outputs enable the export of depth maps, demonstrating the model's capacity to learn meaningful geometric information from image-only supervision.

Figure 8: RGBD rendering results.
Implementation Details
- Architecture: Dual-mode DiT initialized from WAN2.2-5B-IT2V, with 24 input views and a spatial downsampling factor of 16.
- Training: Pre-training (20k steps, 3 days) and post-training (10k steps, 2 days) on 64 NVIDIA H20 GPUs using FSDP and activation checkpointing. Batch size 64, bf16 precision.
- Datasets: MVImgNet, RealEstate10K, DL3DV10K for multi-view; proprietary and public datasets for out-of-distribution co-training.
- Inference: 9 seconds per scene (H20 GPU), supporting both image-to-3D and text-to-3D tasks in a unified model.
Limitations and Future Directions
FlashWorld's performance is still bounded by the diversity and coverage of available multi-view datasets. The model struggles with fine-grained geometry, mirror reflections, and articulated objects. Incorporating depth priors and more 3D-aware structural information may address these issues. Future work includes extending the framework to autoregressive and dynamic 4D scene generation.
Conclusion
FlashWorld establishes a new state-of-the-art in efficient, high-quality 3D scene generation by unifying MV- and 3D-oriented paradigms through dual-mode pre-training and cross-mode distillation. The approach achieves strong numerical results across multiple benchmarks, with significant improvements in inference speed and generalization. The framework is well-suited for real-world applications requiring rapid, high-fidelity 3D scene synthesis and provides a foundation for further advances in 3D and 4D generative modeling.