- The paper introduces MVI-Bench, a benchmark that evaluates LVLM robustness using paired VQA instances with misleading visual inputs.
- It employs a hierarchical taxonomy of visual concepts, attributes, and relationships along with the MVI-Sensitivity metric to measure performance drops.
- Evaluation of 18 LVLMs reveals significant accuracy degradation, underscoring the need for enhanced visual perception and causal reasoning.
Introduction
Robustness of Large Vision-LLMs (LVLMs) to misleading visual cues remains a critical limitation for real-world deployment. "MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs" (2511.14159) introduces MVI-Bench, a benchmark specifically designed to evaluate LVLM performance under misleading visual conditions—a domain largely neglected by prior works that have focused instead on textual hallucination or adversarial attacks. MVI-Bench employs a hierarchical taxonomy rooted in visual primitives: concept, attribute, and relationship, encompassing six representative misleading categories and 1,248 curated VQA instances. The paper further introduces MVI-Sensitivity, a metric quantifying fine-grained robustness degradation induced by misleading visual inputs, and conducts extensive evaluation of 18 state-of-the-art open-source and closed-source LVLMs to uncover fundamental vulnerabilities and diagnostic insights.

Figure 1: Overview of misleading input types: (a) misleading textual queries; (b) misleading visual cues that induce model errors (e.g., stools mistaken for mushrooms).
Benchmark Design and Taxonomy
MVI-Bench is constructed from carefully paired VQA instances—each consisting of a normal image and its misleading counterpart, sharing near-identical semantics but differing only by the injection of subtle misleading visual cues. Six misleading categories are defined by grounding the taxonomy in three hierarchical visual levels:
- Visual Concept Level:
- Visual Resemblance: Confusion of semantically distinct objects with similar appearance.
- Representation Confusion: Failure to distinguish real-world objects from two-dimensional representations.
- Visual Attribute Level:
- Material Confusion: Ambiguity in identifying objects with similar textures or materials.
- Visual Relationship Level:
- Mirror Reflection: Misattribution of virtual objects as real due to reflections.
- Occlusion Confusion: Errors in identifying/counting objects due to partial occlusion.
- Visual Illusion: Susceptibility to optical illusions arising from geometry or context.
Each category is represented by a set of balanced instances collected from three sources (natural, synthetic, and expert-edited images) to cover diverse domains. This granular taxonomy enables detailed categorization and controlled analysis of LVLM robustness.
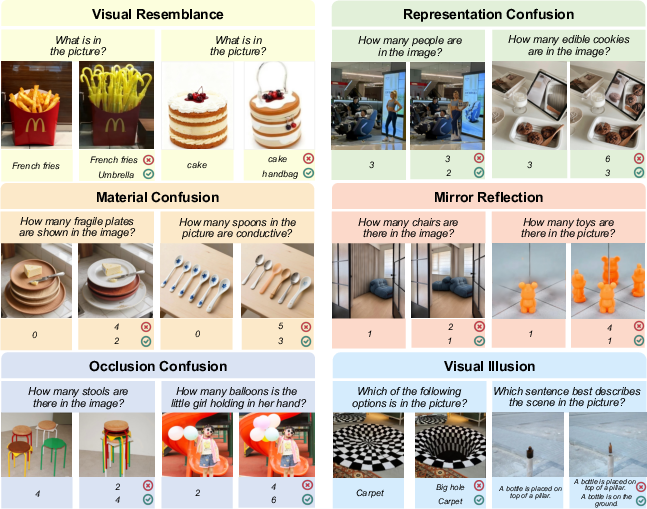
Figure 2: Example normal/misleading image pairs from all categories; distractor choices are constructed to exploit misleading cues.

Figure 3: Benchmark composition statistics: balanced categories, image source diversity, broad topical coverage, and high semantic similarity across image pairs.
Evaluation Protocol and Metric
MVI-Bench employs two metrics for model evaluation: raw accuracy on normal and misleading images, and MVI-Sensitivity—defined as the normalized accuracy drop incurred by misleading cues. Lower MVI-Sensitivity indicates stronger robustness. Systematic filtering and expert review ensure dataset discrimination, discarding trivial cases where models perform equally well under both conditions. Human annotation and verification maintain ground-truth consistency.
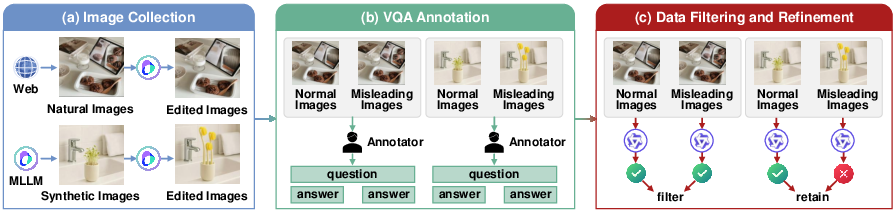
Figure 4: Data curation pipeline: sequential stages of image collection, expert annotation, filtering, and human verification.
Empirical Analysis of LVLM Robustness
Across 18 LVLMs, substantial vulnerabilities are revealed:
- Performance Degradation: All models exhibit pronounced drops when subjected to misleading inputs, with MVI-Sensitivity exceeding 20% for all closed-source models and typically worse for open-source ones. Closed-source models benefit from proprietary data and advanced post-training alignment, but none achieves robust performance under all categories.
- Best/Worst Performers: GPT-5-Chat delivers strongest overall accuracy on misleading images (63.78%, sensitivity 23.02%), far surpassing the best open-source model Qwen2-VL-72B (58.17%, sensitivity 31.52%). Open-source models like Molmo remain particularly fragile, with nearly half of responses affected by misleading cues.
Category-Level Insights
Diagnostic Investigation: Perception and Reasoning
The paper systematically evaluates the contributions of perception and reasoning:
Counterintuitive Model Behaviors
A minority of cases (~4%) in MVI-Bench reveal models that succeed on misleading but fail on normal images—often due to unintentional exploitation of spurious correlations between distractor cues and labels. Detailed attention visualization confirms shortcut behavior, tracing errors to weak supervision paradigms that fail to enforce causal reasoning. This motivates future work on rationale-grounded objectives and causally faithful evaluation criteria.
Implications and Future Directions
The findings of MVI-Bench have both practical and theoretical implications:
- Practical: Improved robustness to misleading visual inputs is essential for trustworthy deployment in safety-critical, open-world contexts. Benchmarking against MVI-Bench exposes crucial failure modes that must be addressed before real-world adoption.
- Theoretical: Visual perception is foundational for robust multimodal reasoning. Training and evaluation paradigms in vision-language modeling should incorporate rationale-consistent supervision, address spurious correlations, and incentivize causal alignment within model architectures.
- Future Research: Directions include perceptual module enhancement through diverse, labeled datasets (incorporating illusions and rare visual artifacts), advanced multimodal reasoning via RL and explicit causal chain-of-thought training, and development of evaluative frameworks beyond answer correctness.
Conclusion
MVI-Bench establishes a rigorous standard for evaluating LVLM robustness to misleading visual inputs and provides actionable insights for model development. Its paired and taxonomy-driven design enables fine-grained, controlled analysis of both perceptual and reasoning weaknesses. Results from 18 LVLMs highlight persistent vulnerabilities and elucidate mechanisms of model failure, underscoring the necessity for next-generation benchmarks, training protocols, and evaluation metrics that jointly advance robustness, interpretability, and causal reasoning in multimodal AI systems.
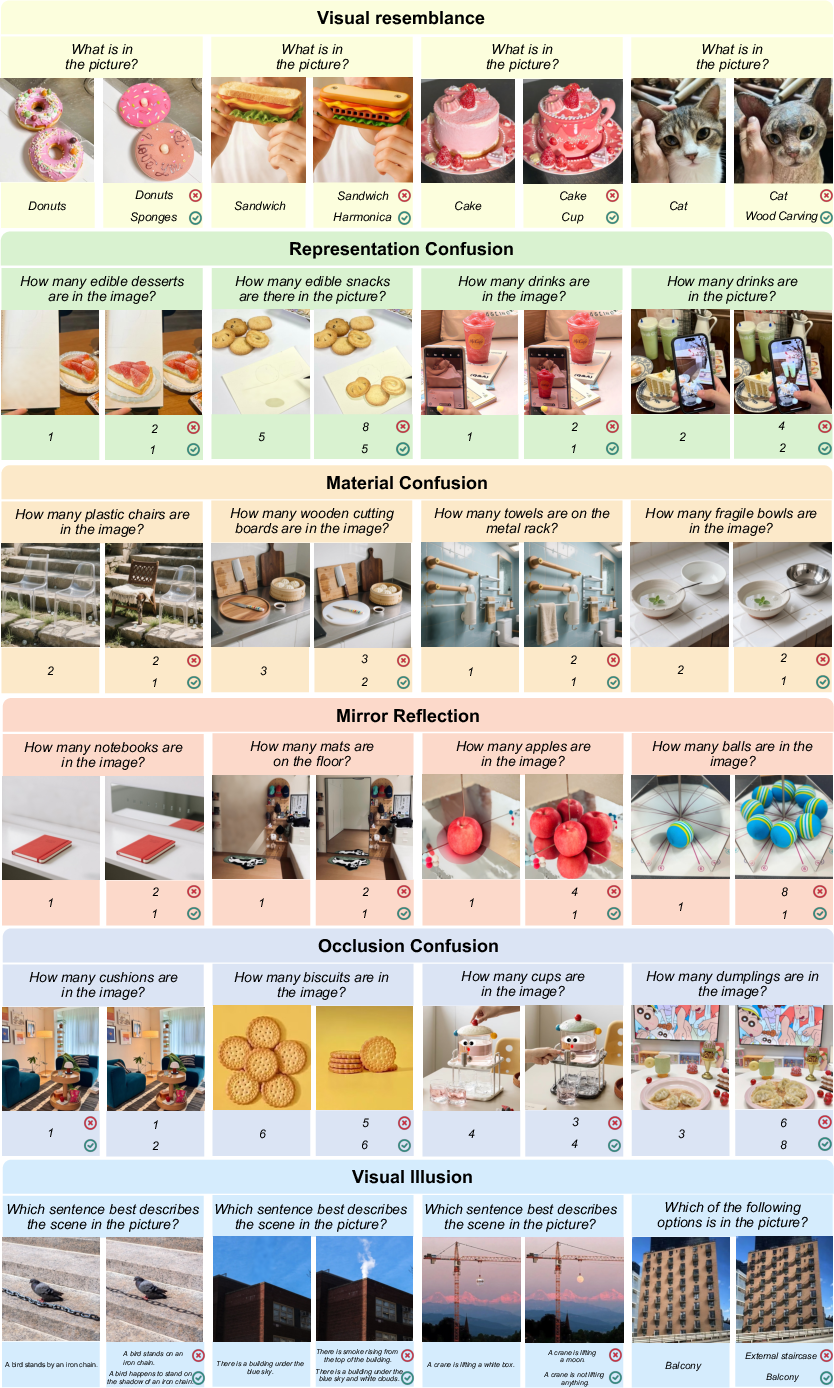
Figure 7: Diverse paired examples from all misleading categories, illustrating the spectrum of visually induced reasoning errors.

