Published 3 Feb 2026 in cs.LG, math.OC, and stat.ML | (2602.03566v1)
Abstract: Computational optimal transport (OT) offers a principled framework for generative modeling. Neural OT methods, which use neural networks to learn an OT map (or potential) from data in an amortized way, can be evaluated out of sample after training, but existing approaches are tailored to Euclidean geometry. Extending neural OT to high-dimensional Riemannian manifolds remains an open challenge. In this paper, we prove that any method for OT on manifolds that produces discrete approximations of transport maps necessarily suffers from the curse of dimensionality: achieving a fixed accuracy requires a number of parameters that grows exponentially with the manifold dimension. Motivated by this limitation, we introduce Riemannian Neural OT (RNOT) maps, which are continuous neural-network parameterizations of OT maps on manifolds that avoid discretization and incorporate geometric structure by construction. Under mild regularity assumptions, we prove that RNOT maps approximate Riemannian OT maps with sub-exponential complexity in the dimension. Experiments on synthetic and real datasets demonstrate improved scalability and competitive performance relative to discretization-based baselines.
The paper introduces a continuous neural OT framework that bypasses discretization, mitigating the curse of dimensionality on manifold-valued data.
It leverages geometric feature encoding and c-concave neural potentials to construct transport maps with provable polynomial complexity guarantees.
Empirical results on spheres and tori demonstrate superior scalability and accuracy compared to traditional discretization methods in high dimensions.
Riemannian Neural Optimal Transport: Theory and Empirics
Introduction and Motivation
The paper "Riemannian Neural Optimal Transport" (2602.03566) presents an intrinsic neural optimal transport (OT) framework for generative modeling on compact Riemannian manifolds. Neural OT approaches traditionally leverage Euclidean geometry, exploiting the structure of convex potentials for quadratic cost via Brenier's theorem. However, many contemporary data domains—such as protein conformations, geology, robotics, and angular statistics—involve observations on non-Euclidean, manifold-valued spaces. Extending neural OT methods to Riemannian manifolds is non-trivial because discrete map parameterizations (e.g., via finite site templates) inherently suffer from the curse of dimensionality (CoD), resulting in exponentially scaling complexity with respect to manifold dimension.
This work rigorously establishes the CoD barrier for all discrete-output manifold OT parameterizations and introduces Riemannian Neural Optimal Transport (RNOT): a methodology that circumvents discretization by constructing continuous neural parameterizations of OT maps directly on manifolds, with provable polynomial complexity guarantees and intrinsic handling of geometric structure.
Discrete OT and the Curse of Dimensionality
A principal contribution is a theoretical lower bound showing that discretization-based methods (including Riemannian Convex Potential Maps, or RCPMs) incur exponential complexity in manifold dimension p for any fixed RMSE accuracy δ: specifically, for discrete-output maps with m support points, the minimax RMSE scales as Cm−1/p. Thus, to achieve accuracy δ, at least (C/δ)p parameters/sites are required (see Corollary~2 and Theorem~1 in the paper). This exponential barrier is fundamental, independent of specific OT algorithms, and holds for any parameterization that restricts the output support to finitely many locations.
Riemannian Neural OT: Construction and Universality
RNOT replaces discretization with a continuous, amortized mapping via neural networks. The main architectural innovation is a feature-based pullback, where manifold points are encoded using injective geometric feature maps (specifically, Gromov landmark distance embeddings; see Proposition~1), and these are consumed by dense neural network architectures. Critically, the c-concavity constraint for OT potentials—central for optimal transport—is enforced by construction, using the c-transform operator adapted to the manifold setting. This yields transport maps of the form T(x)=expx(−∇ϕ(x)), where ϕ is the neural c-concave potential, leveraging the Riemannian exponential and gradient.
A universality theorem (Theorem~3) shows that these implicit c-concave neural potentials can approximate true Riemannian OT potentials arbitrarily well, with the associated transport maps converging to the Monge map almost everywhere under the source distribution.
Complexity: Breaking the Curse
Under mild regularity (Hölder smoothness) assumptions, the paper proves explicit polynomial bounds for the number of neural network parameters (Wε=O(ε−4p/3(kp+1))) and depth required to approximate OT potentials (and the transport map) to prescribed accuracy ε (see Theorem~4 and Corollary~3). Crucially, this scaling is polynomial in ε−1—not exponential in p—and matches uncursed Euclidean deep learning rates once suitable injective features are supplied. Map stability is established via a pointwise minimizer perturbation argument: the error of the transport map induced by approximated potentials is shown to scale as O(ε) almost everywhere.
Empirical Results: Real Data and High-Dimensional Scaling
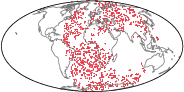
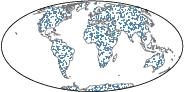
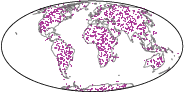
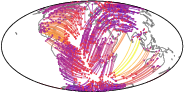
Empirical validation includes both real-world and synthetic manifold datasets. A showcase application studies continental drift on the sphere S2, using paleogeographic reconstructions (Figure~1):
Figure 1: Source mass distribution μ at 150 Ma, visualized for continental drift OT modeling on S2.
The learned transport map T yields geodesic flows that respect plate boundaries and achieve high plate purity, with Monge gap error below 0.1%. Visualizations of the transported densities and induced geodesic trajectories demonstrate interpretability and geometric fidelity.
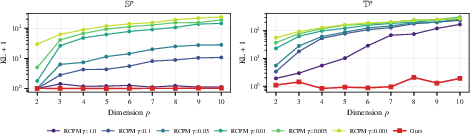
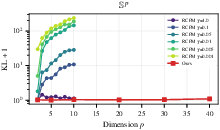
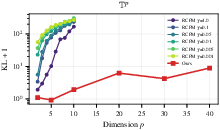
Further experiments on Sp and Tp (higher-dimensional spheres and tori) quantitatively compare RNOT with leading baselines (RCPM, RCNF, Moser Flow). KL divergence and ESS metrics reveal that RNOT maintains stable, low error even as p increases, while RCPM rapidly degrades (Figure~3 and Figure~5):
Figure 2: KL divergence (log scale) versus dimension p, showing stable performance for RNOT and exponential degradation for RCPM.
Figure 3: KL divergence scaling with p for RNOT vs. RCPM at varying regularization γ; RNOT exhibits dimension-favorable scaling up to p=40.
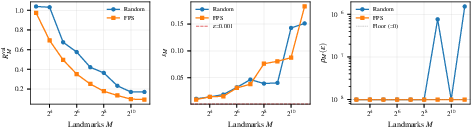
Ablation studies highlight the critical role of landmark geometry (FPS sampling), initialization strategy (LogSumExp warm start), and argmin solver design. For both spheres and tori, RNOT is competitive with RCPM in low dimensions and vastly superior at high dimensions; RCNF and Moser Flow are markedly less effective.
Implementation: Intrinsic Feature Encoding and Semi-Dual Training
RNOT employs Gromov/FPS landmarks for geometric encoding and is trained using sample-based Kantorovich semi-dual objective, sidestepping Jacobian determinant evaluation required for likelihood-based normalizing flows. The c-transform is implemented via Riemannian gradient descent, initialized by a softmin approximation and differentiated using envelope theorem (with practical stabilization via implicit function theorem and numerical diagnostics).
Figure 4: Embedding diagnostics on S2: FPS sampling yields lower coverage radius and better separation.
Practical and Theoretical Implications
Practically, RNOT enables scalable, amortized learning of high-fidelity generative models on arbitrary compact manifolds—crucial for geometric data domains. It empirically unlocks dimension-friendly learning without the exponential bottleneck of prior discretization-based approaches.
Theoretically, the work bridges gaps in geometric deep learning: it proves that, given injective continuous features and piecewise-linear activations, the curse of dimensionality for transport maps is not fundamental but rather a consequence of discretization. It suggests that amortized, continuous parameterization—combined with intrinsic geometric constraints—can universally approximate the desired OT structures with tractable complexity.
Future Directions
Limitations include focus on smooth, compact manifolds, assumptions on regularity, and the computational cost of inner minimization. Extending to general cost functions, manifolds with boundary, and accelerating argmin layers (e.g., via learned solvers or amortization) are promising future directions. The results motivate further exploration of intrinsic neural modeling for geometric domains, particularly for applications in physics, bioinformatics, and directional statistics.
Conclusion
"Riemannian Neural Optimal Transport" provides both rigorous foundations and empirical demonstrations for neural OT on manifolds, delivering a scalable, theoretically grounded framework that breaks the dimensional bottleneck inherent to discrete parameterizations. This work substantially advances the landscape of generative modeling for geometrically structured data and establishes new directions for dimension-friendly manifold learning.