- The paper demonstrates that disentangling superposition using sparse autoencoders clarifies hidden alignment in neural representations.
- The paper introduces a permutation-based metric leveraging latent sparsity and optimal transport to accurately compare representational bases.
- The paper empirically validates that SAE disentanglement boosts alignment scores in toy models and DNNs, with promising NeuroAI applications.
Superposition Disentanglement of Neural Representations Reveals Hidden Alignment
Introduction
This paper explores the interaction between superposition in neural representations and the alignment metrics used to compare them. It posits that superposition—where a single neuron represents multiple features—can obscure true representational alignment between neural systems, whether artificial or biological. The authors hypothesize that disentangling superposition using sparse autoencoders (SAEs) can reveal hidden alignments that strict metrics like semi-matching and soft-matching miss.
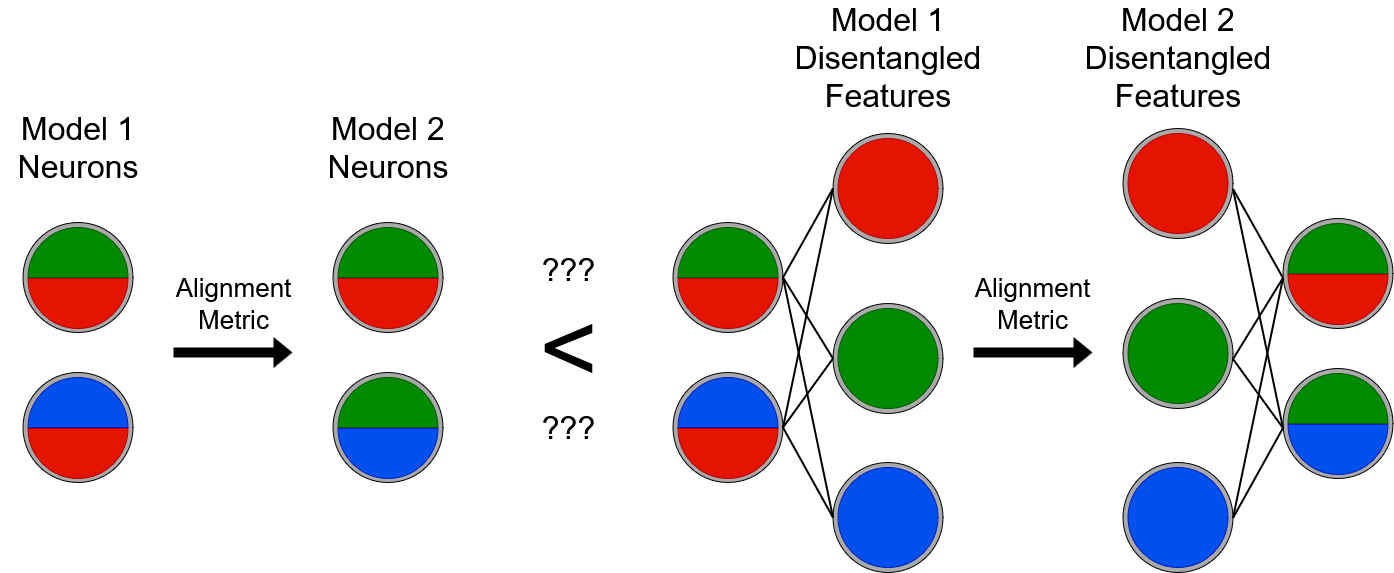
Figure 1: A visual depiction of the question: does superposition disentanglement increase representational alignment? Features are represented as colors, and neurons may contain multiple features in superposition.
Theory of Superposition and Alignment Metrics
The study introduces a theoretical framework to analyze how superposition arrangements affect alignment scores. It focuses on metrics that are sensitive to representational bases, such as soft-matching, which is generalized to accommodate differences in system size through optimal transport theory. This approach offers a symmetric metric that captures fine-grained representational similarities.
The paper develops a permutation-based alignment score dependent on latent feature sparsity and the restricted isometry property. It argues that perfect alignment can be theoretically achieved post-disentanglement, provided conditions on sparsity and mixing matrices are met. However, different superposition arrangements across models can deflate alignment scores, characterized by mismatched sparsity levels or patterns among latent representations.
Experimental Validation with Toy Models
The authors employ toy models to empirically validate their hypotheses. These models use sparse features distributed in superposition arrangements that differ due to varied random initializations.
Setup
- Feature Dataset: Consists of sparse vectors simulating features, each with a 10% chance of being non-zero.
- Toy Models: Two-layer autoencoders with fewer neurons than features enforce superposition.
- SAE Training: Used to disentangle features from neural activations.
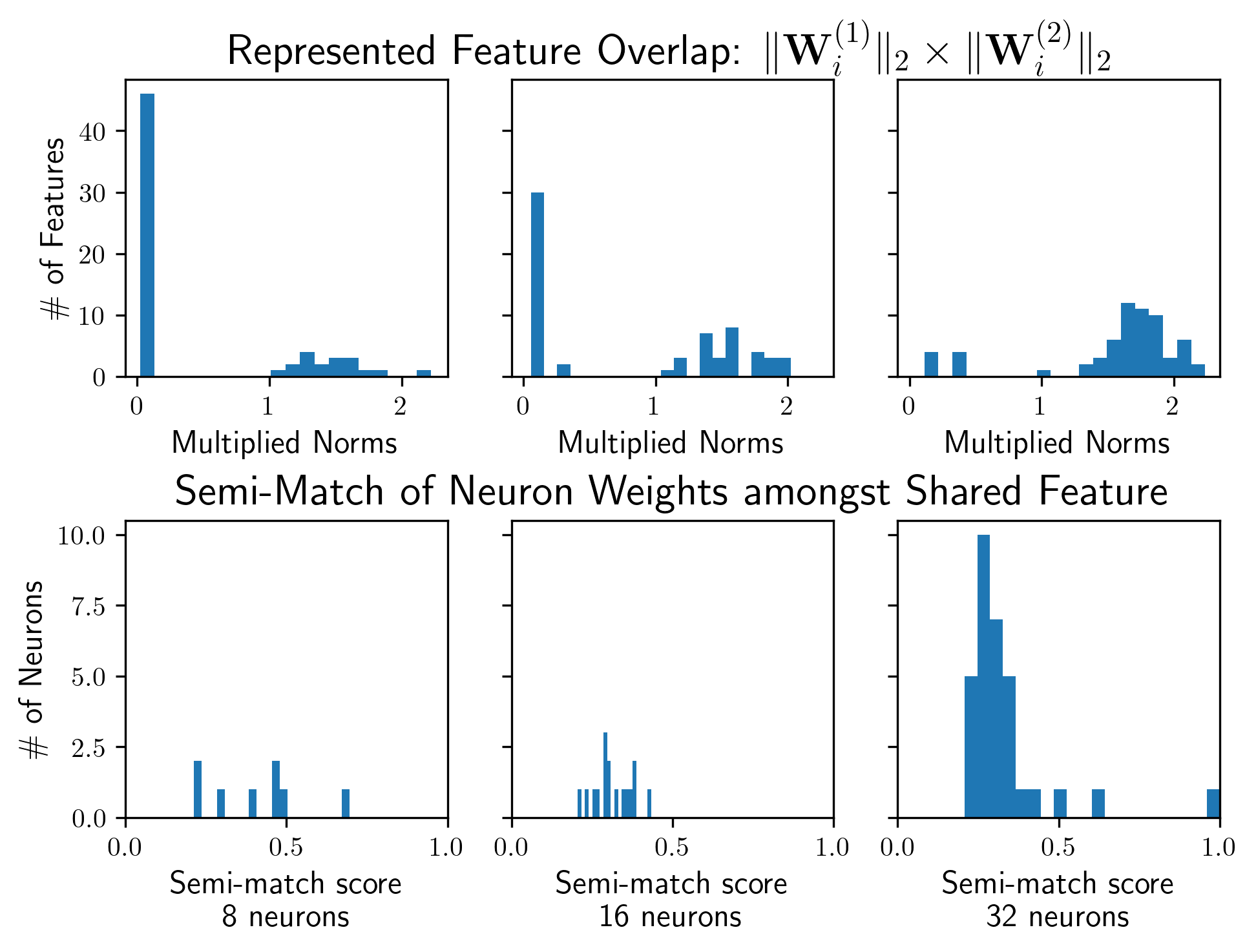
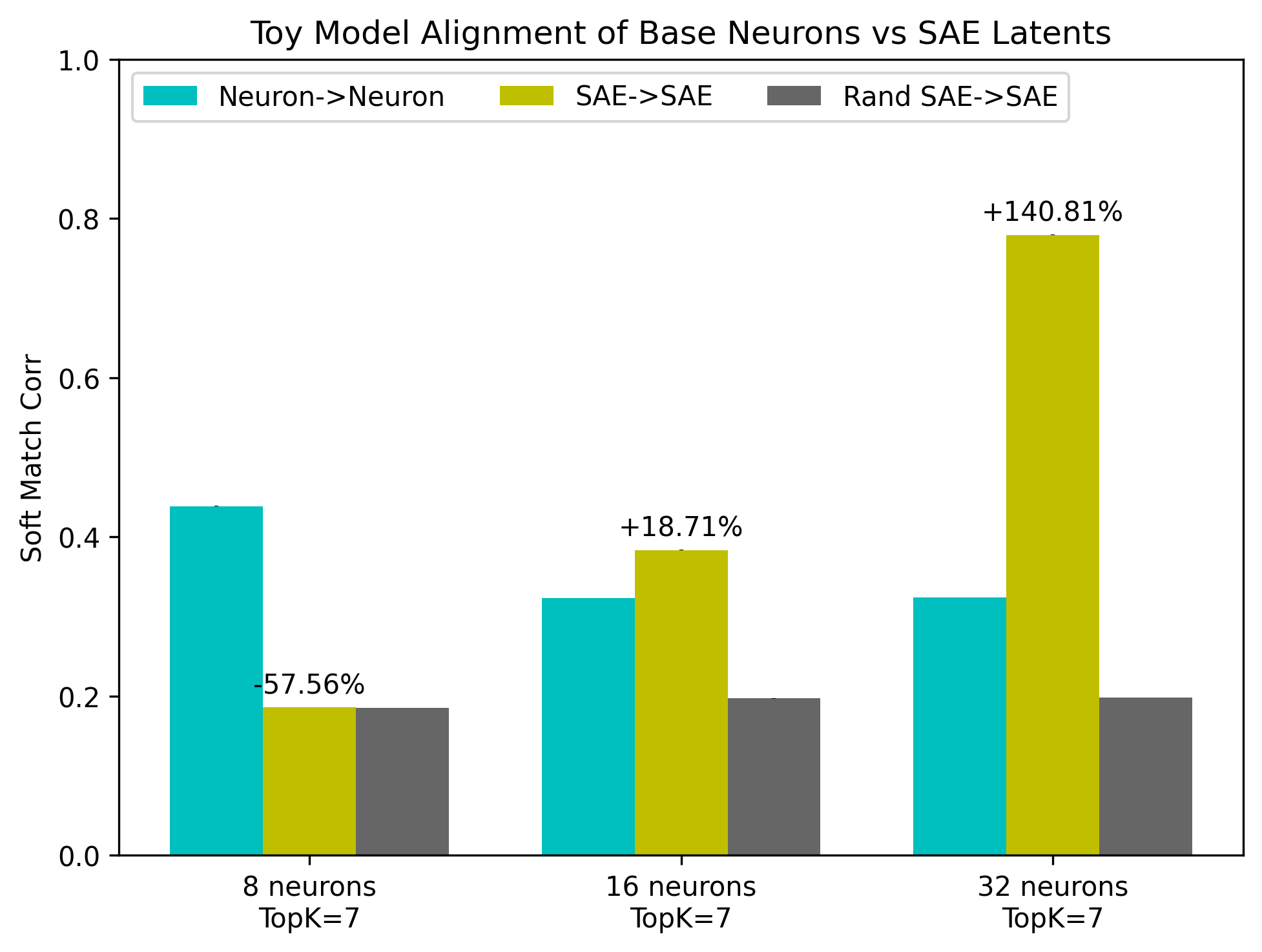
Figure 2: Feature overlap (left, top row) and the superposition arrangement comparison (left, bottom row) of the shared features; soft-matching alignment sees a significant increase when SAE latents replace base neurons.
Results
The study demonstrates substantial increases in alignment scores when SAE latents are used instead of base neural representations. Particularly for models with larger neuron counts, SAE disentanglement closely approximates ground truth feature representations, revealing hidden alignments obscured by neural superposition.
Real Models: DNNs and Brain Alignment
Investigations extend to real-world deep neural networks (DNNs), comparing representational alignment between differently seeded versions of ResNet50 and ViT-B/16 trained on ImageNet.
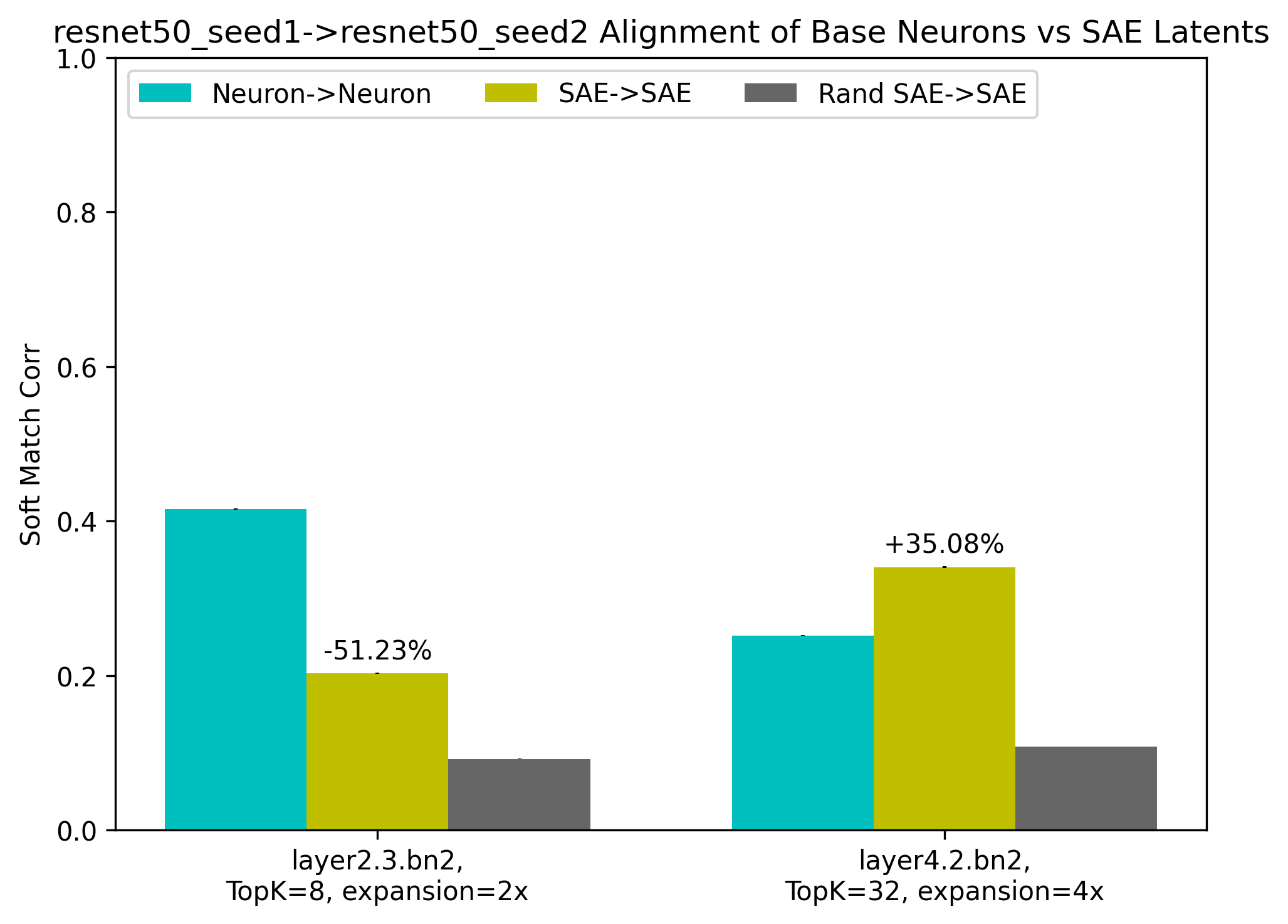
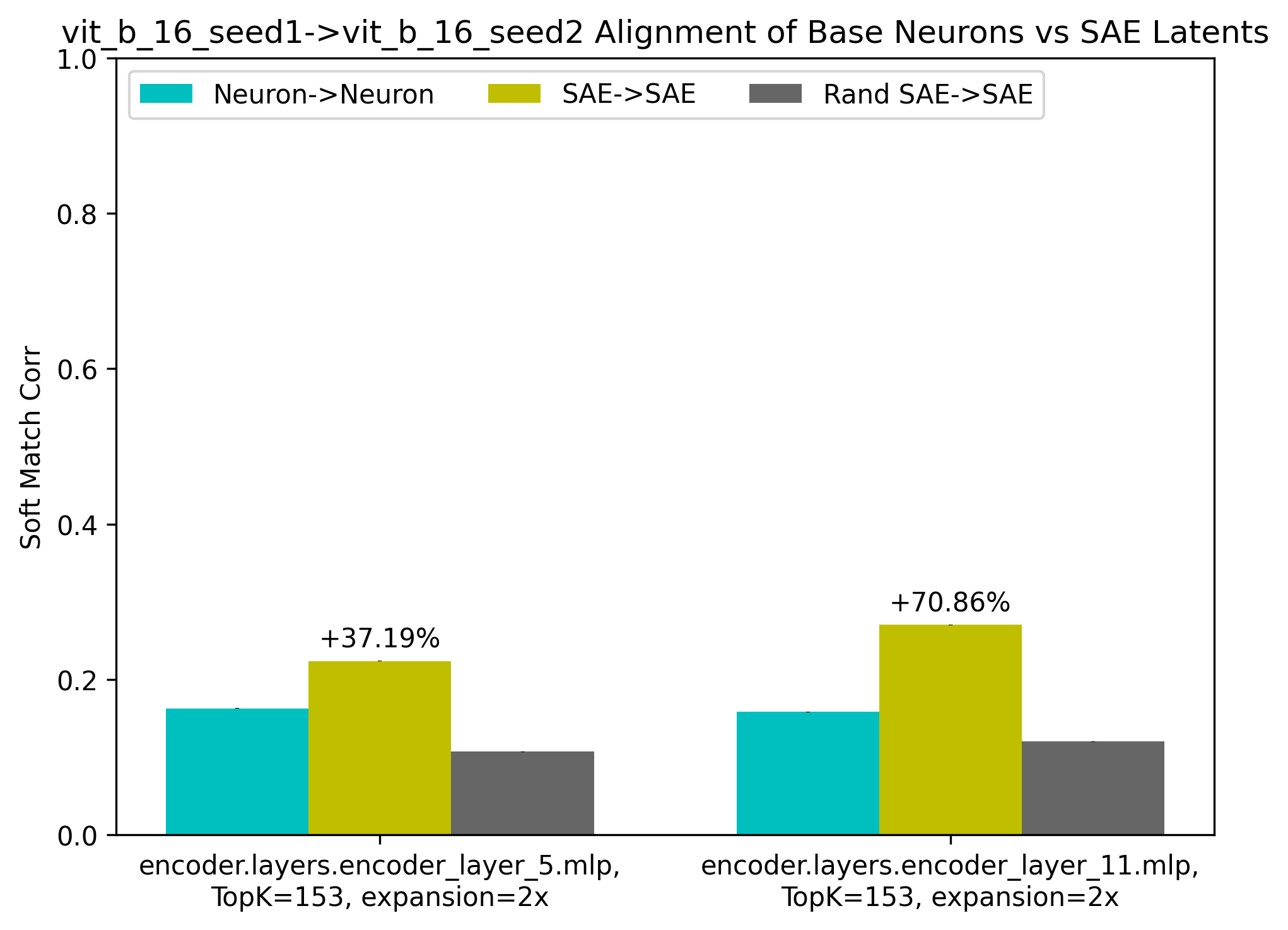
Figure 3: Soft-matching alignment between differently seeded DNNs (ResNet50 and ViT-B/16) trained on ImageNet.
Findings
- Depth-dependent Patterns: Disentanglement increases alignment notably in deeper layers, suggesting greater superposition at increased network depths.
- NeuroAI Implications: Extends to neural alignment with brain data from the NSD, demonstrating improved voxel predictivity via disentangled DNN representations.
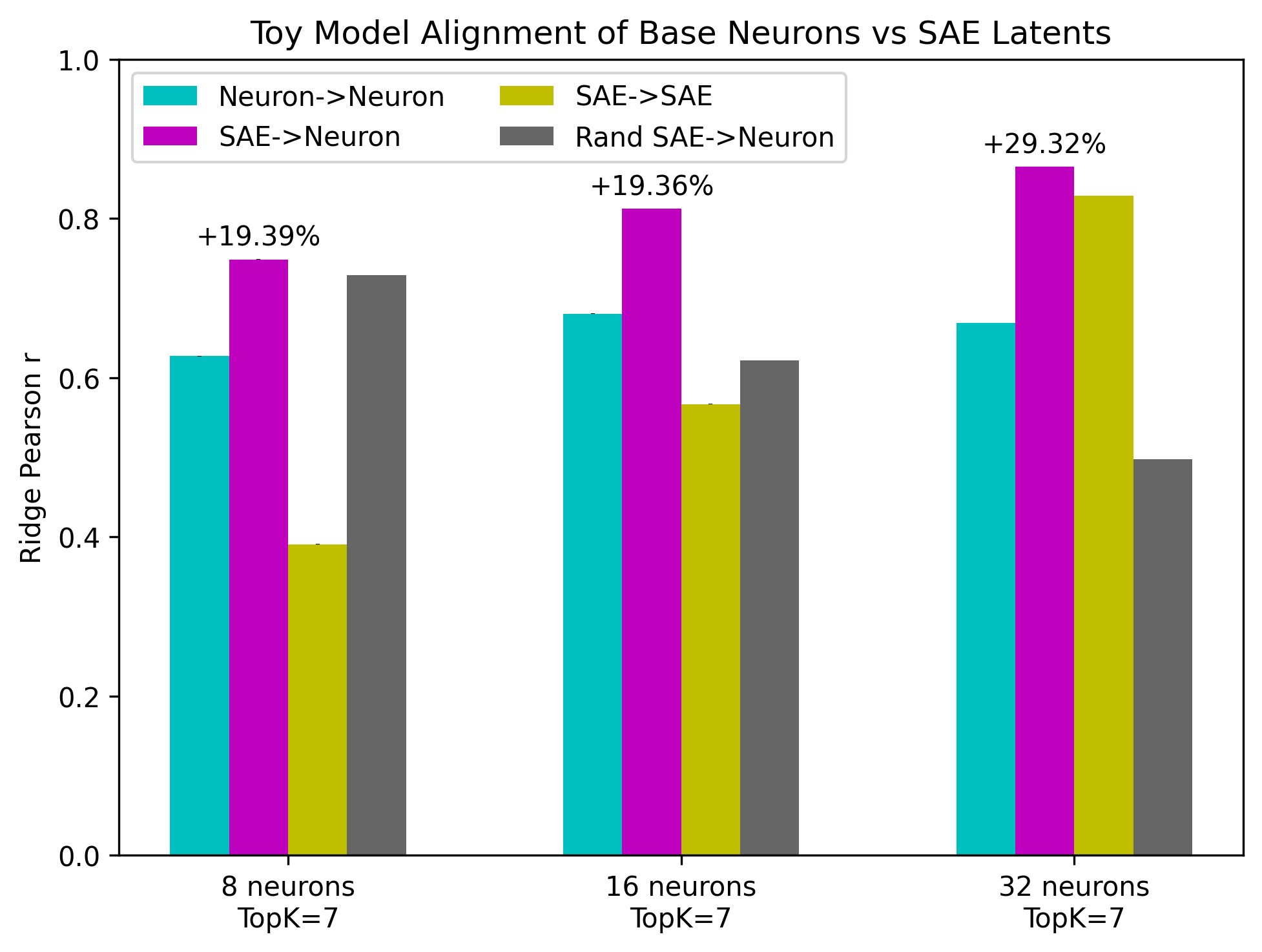
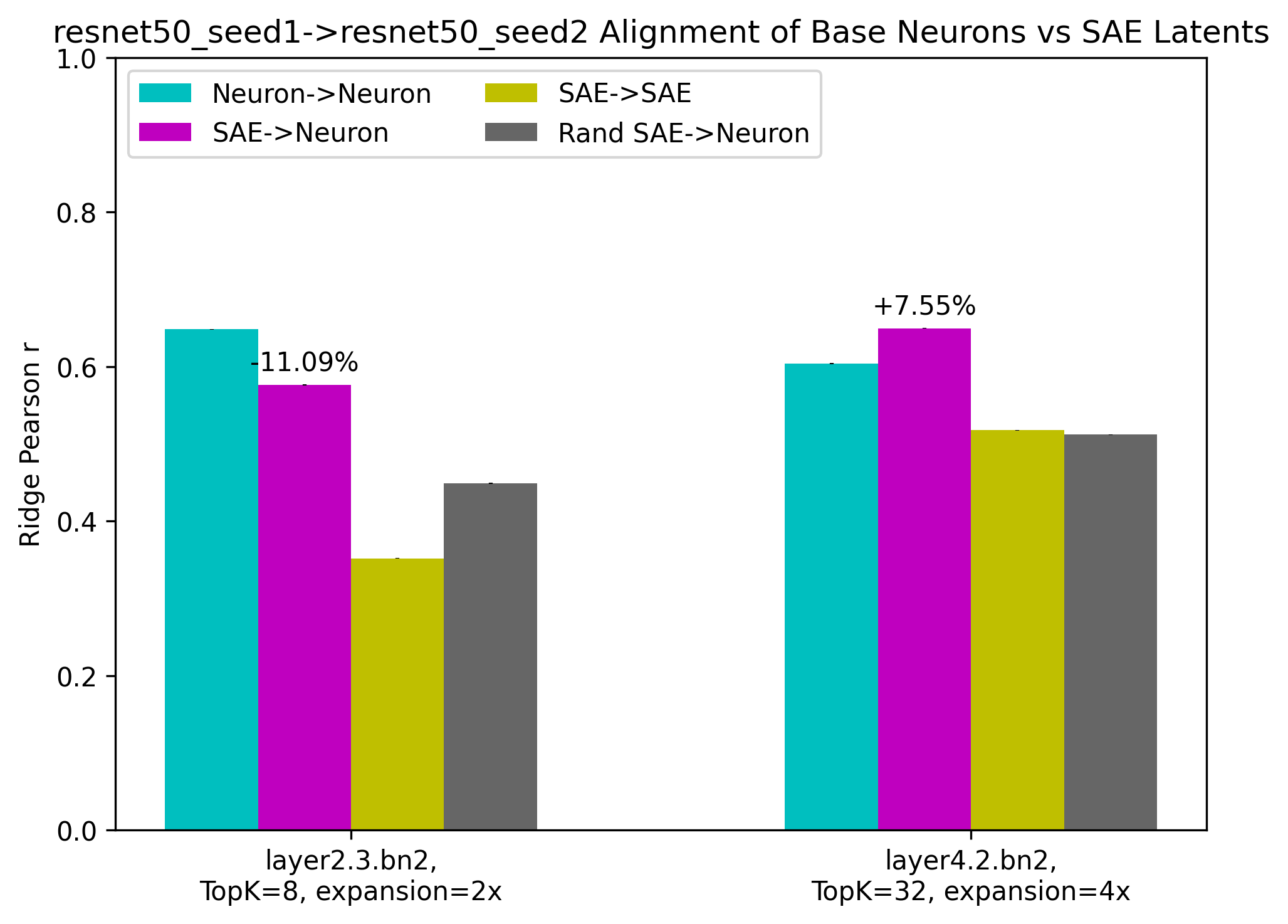
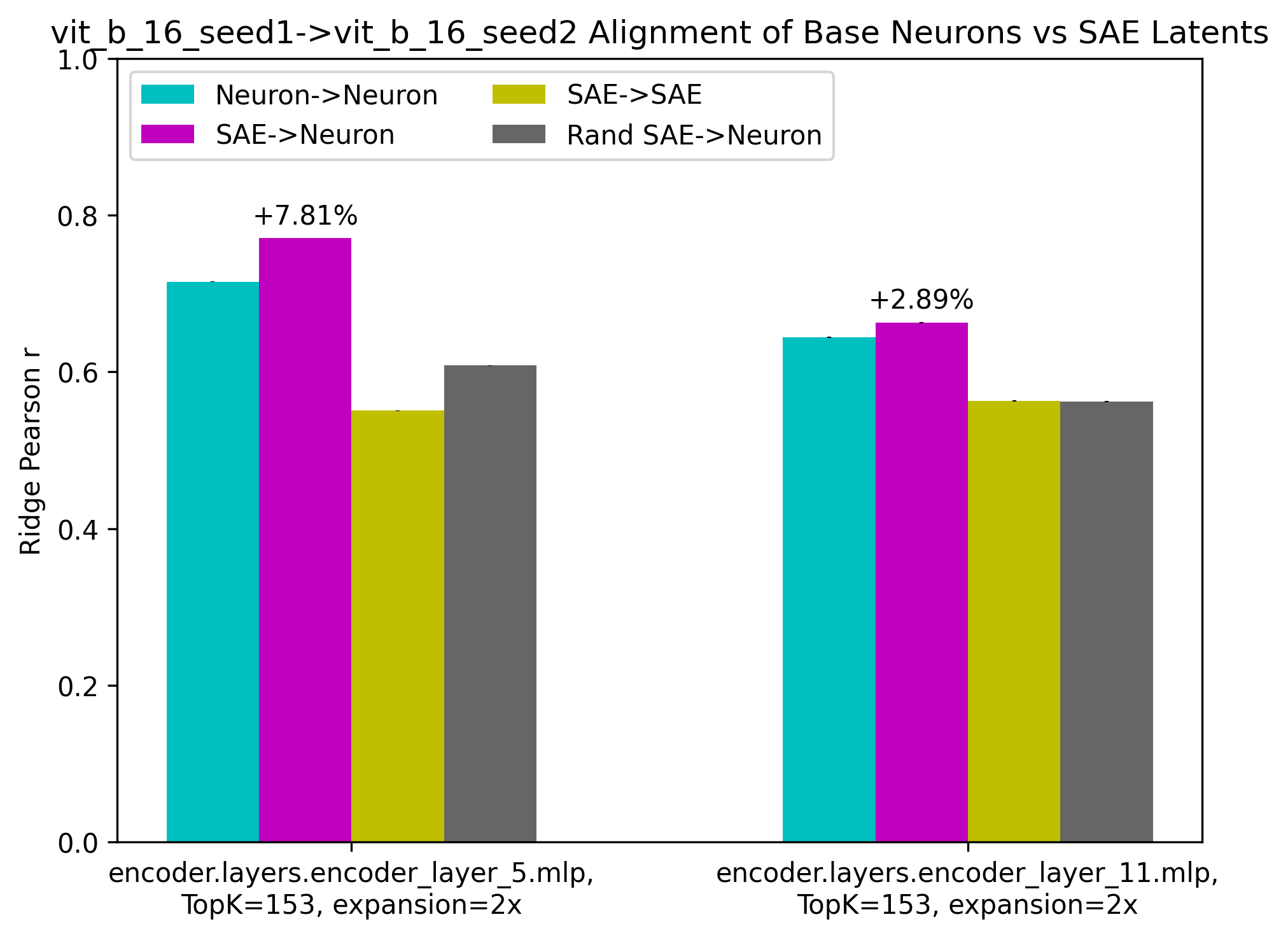
Figure 4: Regression correlation scores between the same toy models (top) and DNNs (bottom).
Discussion and Future Directions
The paper's findings imply that superposition arrangements can artificially deflate alignment scores, questioning conclusions drawn from existing metrics. Future research should address the underlying causes of different superposition arrangements, explore SAE advancements, and examine comprehensive DNN and brain datasets across various domains.
Limitations
- Superposition Characterization: Real model validation is limited due to unknown feature arrangements.
- SAE Constraints: Current SAE methodologies have limitations in feature consistency and identifiability.
- Scalability: Future work should expand to diverse architectures and broader datasets.
Prospective Research
- Representational Analysis: Integrating interpretability within representational studies to qualitatively assess shared features.
- Superposition Forces: Influence of training objectives and network architecture on superposition arrangements.
- Dictionary Learning: Encouraging its use in re-evaluating findings within NeuroAI.
Conclusion
This paper establishes a crucial link between superposition disentanglement and representational alignment, unveiling the need for revisiting previous metrics and theories in light of superposition's impact. These insights could redefine our understanding of neural representation similarities across synthetic and biological neural systems.

