- The paper shows that MLP activations form a sparse, efficient basis for tracing circuits, outperforming traditional MLP outputs on subject-verb agreement tasks.
- The authors employ the advanced RelP attribution method, which reduces representation size while maintaining high faithfulness and completeness metrics.
- Their methodology generalizes across paired and unpaired datasets, enabling scalable, transparent, and cost-effective model interpretability.
Review of "LLM Circuits Are Sparse in the Neuron Basis" (2601.22594)
Introduction
The paper "LLM Circuits Are Sparse in the Neuron Basis" introduces a compelling paradigm shift in understanding the interpretability of neural network computations in transformer LLMs. The authors challenge the prevailing assumption that neuron circuits, particularly those in MLP activations, are denser and less interpretable compared to sparse autoencoders (SAEs). They propose an innovative framework that leverages neuron-based representations, arguing that MLP neurons provide a sparse and efficient feature basis for circuit tracing.
The study is grounded in methodologies that challenge previous baselines, employing advanced attribution methods like RelP over traditional techniques such as Integrated Gradients (IG). By focusing on model internal computations at the neuron level, the authors aim to advance the automation of interpretability without incurring additional computational costs.
Methodology
The authors apply their hypothesis to several benchmarks, notably the subject-verb agreement (SVA) benchmark, to empirically substantiate the sparsity and faithfulness of neuron-based representations in tracing model circuits. The proposition is evaluated over multiple dimensions of model representation, including MLP activations, MLP outputs, attention outputs, and residual streams.
A pivotal aspect of the methodology is the deployment of RelP, a novel gradient-based attribution method that demonstrated superior performance compared to IG. This method reduces computational overhead while maintaining high fidelity in attribution accuracy, closing critical gaps previously observed in neuron sparsity compared to SAE features.
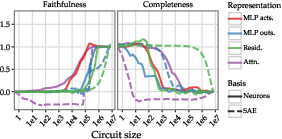
Figure 1: Faithfulness and completeness for different choices of representation in the model (residual stream, attention, MLP activations, or MLP outputs) and basis (neurons or SAE) when applying Integrated Gradients, averaged over the 4 SVA tasks with paired data.
The experimental framework also explores representation choices through zero and mean ablation approaches with paired and unpaired dataset configurations, highlighting the robustness of neuron-based circuit tracing across diverse data settings.
Experimental Findings
The research presents four core results:
- MLP Activations as a Sparse Basis: Empirical evaluation on SVA tasks reveals that circuits derived from MLP activations are noticeably smaller yet maintain robustness in faithfulness and completeness metrics, surpassing traditional MLP outputs.
- Effectiveness of RelP: The RelP method systematically decreases the representation size needed for neuron-based circuits, offering significant improvements over IG across the investigated tasks (Figure 2).
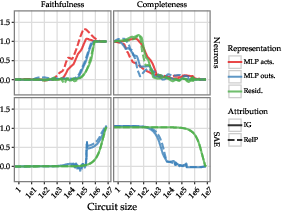
Figure 2: Faithfulness and completeness for Integrated Gradients vs.~RelP, for different choices of representation in the model and basis (neurons or SAE), averaged over the 4 SVA tasks with paired data.
- Generalizability to Unpaired Data: The proposed methods maintain performance advantages in unpaired data scenarios, underscoring their applicability to real-world datasets where counterfactual examples are unavailable (Figure 3).
Figure 3: Faithfulness and completeness for Integrated Gradients vs.~RelP, for different choices of representation in the model and basis (neurons or SAE), averaged over the 4 SVA tasks with unpaired data.
- Comprehensive Edge Analysis: The study extends its scope to edge-based analysis, proving that neuron connections evaluated through RelP maintain high faithfulness, optimizing both node and edge gravity in circuits.
Case Studies and Implications
Significantly, the work explores case studies like multi-hop reasoning for state capitals, illustrating how neuron activation patterns can be deciphered to understand complex reasoning processes within models. This supports the potential for manipulating or steering targeted model behaviors effectively, opening pathways for practical oversight and dynamic model interaction.
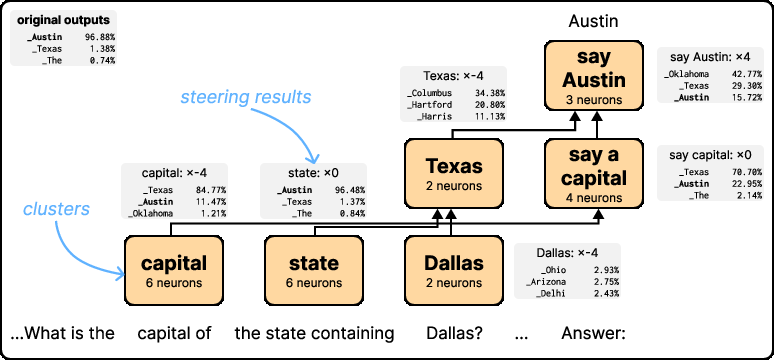
Figure 4: Schematic of 23 key neurons in the 'Texas' circuit, their interactions, and the effects of steering groups of them.
The implications extend beyond interpretability; the proposed neuron-based approach facilitates a scalable, efficient way to probe deep learning models without re-training or additional overheads. This not only democratizes model debugging and oversight but also provides a foundation for developing AI systems that can be fine-tuned or adjusted post-deployment based on specific task requirements.
Conclusion
This paper makes significant strides in computational interpretability within AI, proposing a tractable, neuron-centric framework that balances the granularity and accessibility of feature space analysis in transformers. By advocating for the utility of MLP activations over conventional SAE structures, the authors pave the way for more transparent and controllable AI systems, potentially influencing future model training and interpretability research paradigms.
