Cognitive Load Estimation Using Brain Foundation Models and Interpretability for BCIs
Abstract: Accurately monitoring cognitive load in real time is critical for Brain-Computer Interfaces (BCIs) that adapt to user engagement and support personalized learning. Electroencephalography (EEG) offers a non-invasive, cost-effective modality for capturing neural activity, though traditional methods often struggle with cross-subject variability and task-specific preprocessing. We propose leveraging Brain Foundation Models (BFMs), large pre-trained neural networks, to extract generalizable EEG features for cognitive load estimation. We adapt BFMs for long-term EEG monitoring and show that fine-tuning a small subset of layers yields improved accuracy over the state-of-the-art. Despite their scale, BFMs allow for real-time inference with a longer context window. To address often-overlooked interpretability challenges, we apply Partition SHAP (SHapley Additive exPlanations) to quantify feature importance. Our findings reveal consistent emphasis on prefrontal regions linked to cognitive control, while longitudinal trends suggest learning progression. These results position BFMs as efficient and interpretable tools for continuous cognitive load monitoring in real-world BCIs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Cognitive Load Estimation Using Brain Foundation Models and Interpretability for BCIs”
What is this paper about?
This paper is about figuring out how “mentally busy” someone is—also called cognitive load—by reading their brain signals in real time. The researchers use EEG (small sensors on the scalp that pick up tiny electrical signals from the brain) while people fly a plane in virtual reality. They test new AI models called Brain Foundation Models (BFMs), which are big pre-trained neural networks designed to understand brain signals, and they also make sure the AI’s decisions can be explained in brain terms that make sense.
The big questions the researchers asked
They set out to answer a few simple but important questions:
- Can a large, pre-trained AI model for brain signals estimate how mentally loaded someone is during a task?
- Will this work across different people and different EEG headsets (with slightly different sensor layouts)?
- Can the model work over longer time periods, not just short clips?
- Can we explain which brain regions matter most for the model’s decisions?
How they did it (in simple terms)
First, a quick picture:
- Think of EEG sensors as tiny microphones on your head that listen to the brain’s electrical “whispers.”
- Cognitive load is like how hard your brain is working at a given time—similar to how your muscles feel when lifting something heavy vs. light.
- Brain Foundation Models are like “general-purpose brains” for EEG: they’ve learned from lots of EEG data already, so they can recognize useful patterns out of the box, then be lightly adjusted for a new task.
Where the data came from
- 30 people used a VR flight simulator over 5 days.
- They did short flight tasks (about 2 minutes each) with different difficulty levels (e.g., wind, turbulence, poor visibility).
- EEG data came from caps with 26–32 electrodes (slightly different setups across groups).
- The “truth” score for cognitive load came from a training system that combines how hard the task was, how skilled the person was, and how they performed—like a coach’s score for how much effort someone had to use.
Turning brain signals into useful clues
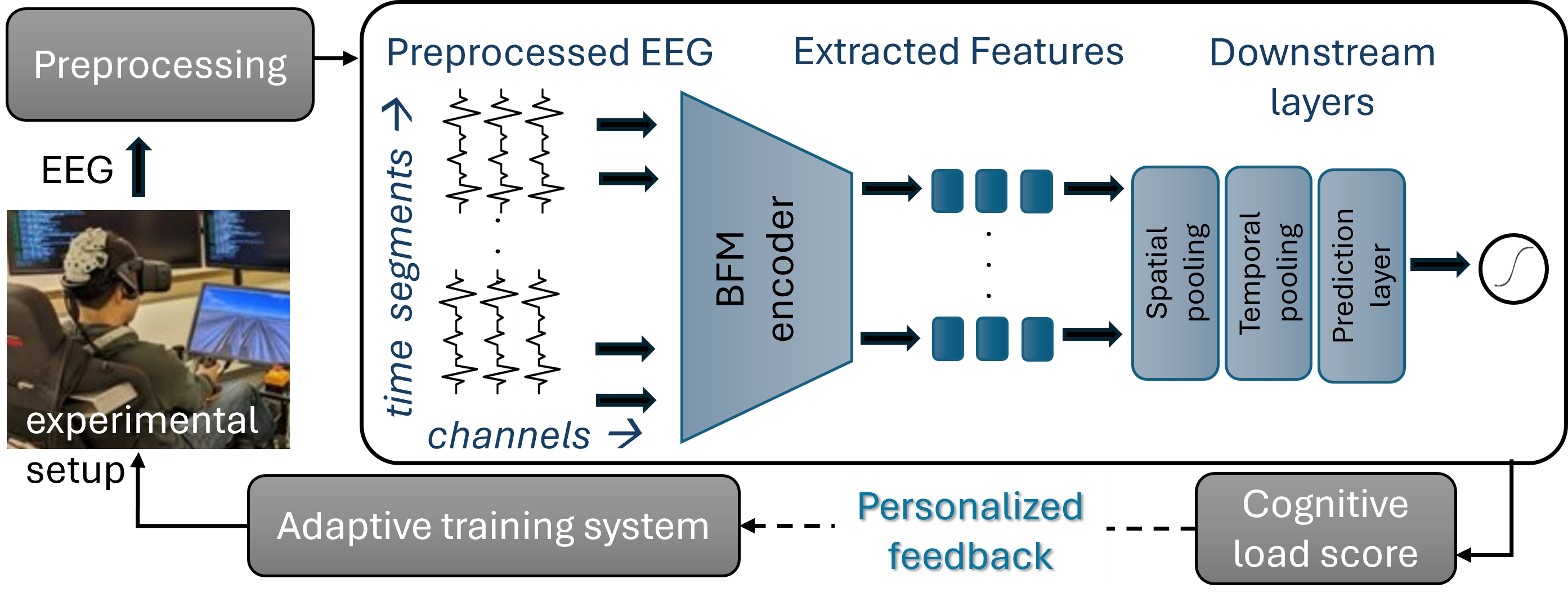
- They cleaned the EEG (removed noise), then split each 90-second slice into overlapping chunks of 16 seconds.
- They ran these chunks through two Brain Foundation Models (LaBraM and CBraMod). These models turn messy EEG signals into compact “features” that summarize what’s happening in the brain each second, at each electrode.
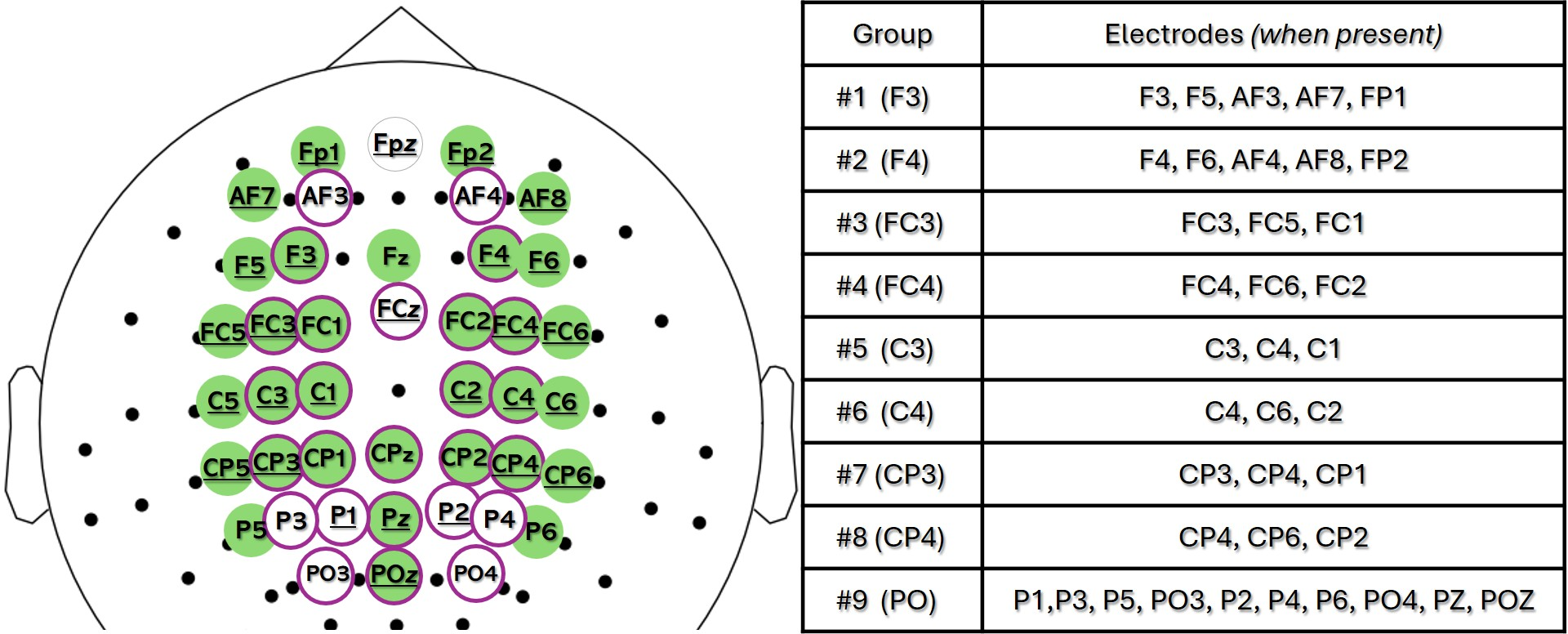
- Because different people had different cap layouts, they grouped electrodes into 9 brain regions (like “front,” “side,” “back”) and averaged within each region—this makes the data consistent and more brain-meaningful.
Teaching a model to estimate mental effort
- After getting the features, they tried simple models (like a basic linear layer), and slightly more complex ones (like a small neural network or an SVM) to predict the continuous cognitive load score.
- They tested models on people they hadn’t trained on, to make sure the models would work for new users.
Making the model explain itself
- They used a technique called Partition SHAP to see which brain regions mattered most to the model’s predictions.
- An analogy: if a song sounds a certain way, you can mute instruments one by one to see which ones change the sound the most. Partition SHAP does something similar with model inputs and handles the fact that EEG signals from nearby sensors are related.
What they found and why it matters
Here are the main takeaways, explained simply:
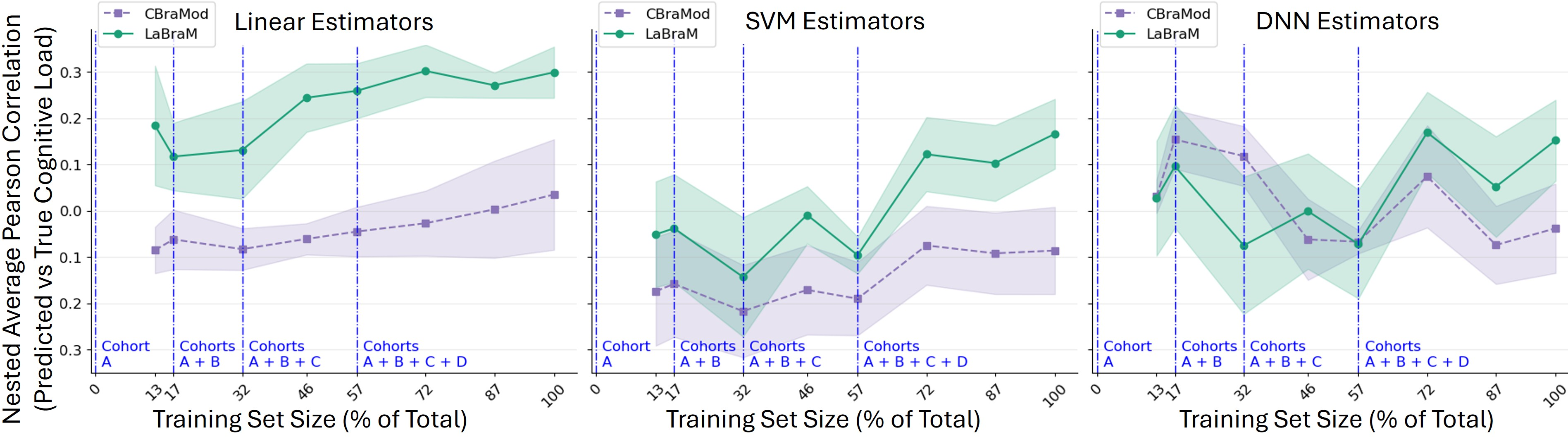
- Brain Foundation Models worked best. LaBraM, especially, beat older methods (like classic frequency features and end-to-end deep models trained from scratch).
- Simple can be powerful. Surprisingly, a straightforward linear layer on top of LaBraM’s features did very well. That’s good news for speed and reliability.
- Grouped brain regions help. Averaging sensors into 9 brain areas (instead of keeping only one sensor per area) made predictions better and more stable across different headsets.
- It scales to real life. The system can run in under a second on a regular computer while using longer context (minutes, not just seconds), which is useful because cognitive load changes slowly.
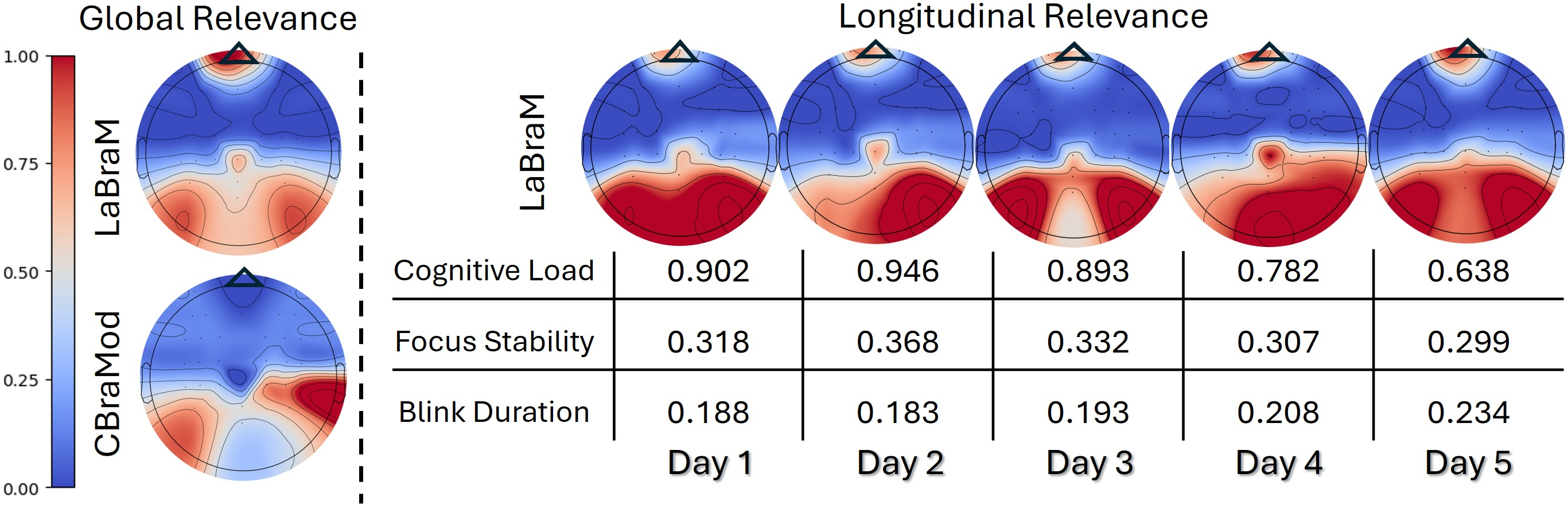
- The brain maps make sense. The explainability tool showed that the model focused on:
- Prefrontal (front) areas linked to planning and mental control.
- Parietal–occipital (top–back) areas linked to visual attention and working memory.
- Learning over days showed healthy trends. Over five days, participants’ estimated cognitive load went down (they got more efficient), the model’s attention to prefrontal areas went up (more expert-like control), and eye-related signals suggested they were more relaxed.
Why this matters:
- It shows that large, pre-trained EEG models can “transfer” their knowledge to a new, realistic task (VR flight) and give reliable, understandable results across different people and devices.
Why this could be useful in the real world
This research points to practical, human-helping tools:
- Smarter learning: A tutoring or training system could sense when you’re overloaded and adjust difficulty, pace, or feedback.
- Safer training: Flight, driving, or medical simulators could monitor mental load and reduce risk by adapting the task.
- Better games and apps: Games could auto-tune difficulty to keep you engaged but not overwhelmed.
- Trustworthy AI: Because the model highlights meaningful brain regions, users and experts can understand and trust what the system is doing.
In short, the paper shows that Brain Foundation Models can estimate mental effort accurately, quickly, and in a way that lines up with how the brain actually works—making real-time, brain-aware systems more possible and more reliable.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to guide actionable follow-up research.
- Dataset/task generalizability: Evaluation is confined to a VR flight simulator with 30 participants over 5 days; generalization to other tasks, environments, and populations remains untested.
- Small and homogenous test set: Cross-subject evaluation relies on a single cohort (E) with only 5 participants, raising concerns about stability, variance, and selection bias of reported correlations.
- Cross-cohort confounds: Cohorts A–E were collected sequentially with evolving hardware and protocols; observed trends (e.g., performance gains) may be confounded by acquisition improvements rather than true learning effects.
- No external/ cross-dataset validation: The models are not tested on publicly available EEG datasets or held-out external cohorts to assess robustness to real-world domain shift.
- Label validity and noise: The ATS composite “cognitive load” label is not validated against standard subjective (e.g., NASA-TLX), physiological (e.g., pupillometry, HRV), or independent expert ratings; label reliability and noise characteristics are not quantified.
- Potential circularity in labels: Because ATS integrates performance and task difficulty, it is unclear whether the model predicts cognitive load per se or correlates of performance/difficulty; disentangling these components is not addressed.
- Temporal alignment of labels: The possible lag between neural responses and ATS-derived labels is not modeled; label smoothing, delay compensation, or time-alignment sensitivity analyses are absent.
- Limited online/real-time evidence: Although “real-time” inference is claimed, end-to-end latency (including the 90 s context), throughput, and memory footprint are not quantified, and no live, closed-loop deployment is demonstrated.
- Fixed context/windowing choices: The choice of 16 s windows and 90 s segments is not justified via sensitivity analyses; impact of shorter/longer windows on responsiveness and accuracy is unknown.
- Frozen vs. fine-tuned BFMs: Despite stating that fine-tuning a subset of BFM layers improves accuracy, the paper mainly uses frozen encoders; there is no systematic ablation specifying which layers to tune, how many parameters, and the resulting gains/overfitting risks.
- Downstream model breadth: Only Linear, SVM, DNN, and a limited LSTM comparison are considered; more expressive or uncertainty-aware regressors (e.g., Gaussian processes, Bayesian neural nets) are not explored.
- Narrow hyperparameter search and model selection: Limited hyperparameter sweeps and absence of early stopping/regularization ablations may understate achievable performance or exaggerate stability.
- Evaluation metrics: Reliance on Pearson correlation alone omits magnitude-based (RMSE/MAE), agreement (CCC), calibration, and time-resolved tracking metrics that better characterize continuous estimation performance.
- Statistical testing: No statistical significance testing, effect sizes, or corrections for multiple comparisons are reported for performance or SHAP differences across regions/days.
- Montage harmonization trade-offs: Reducing electrodes to 9 anatomical regions via group-averaging may mask fine-grained spatial patterns; no sensitivity analysis on the number/definitions of regions or alternative mapping strategies (e.g., interpolation, graph alignment).
- Pooling design space: Spatial/temporal pooling is limited to simple averaging and intersections; learnable pooling, attention-based aggregation, or graph neural network formulations are not investigated.
- Interpretability scope and rigor: Partition SHAP usage is not fully specified (perturbation scheme, hierarchical tree structure, background distribution) and lacks stability checks, sensitivity analyses, and comparisons to alternative XAI methods (e.g., LRP, integrated gradients).
- Artifact confounds in explanations: Frontal SHAP saliency could be influenced by ocular/EMG artifacts or VR headset contact; the study does not apply ICA/SSP/EOG regressors or controlled artifact benchmarks to rule out non-neural sources.
- Spectral and temporal interpretability: SHAP analyses focus on spatial maps; frequency-band and time-resolved contributions (e.g., theta/alpha changes or transient dynamics) are not examined.
- Noise/motion robustness: Effects of head motion, sweat, dry-electrode impedance fluctuations, and VR-induced artifacts are not quantified; robustness to realistic noise or data augmentation strategies remains unexplored.
- Hardware variability robustness: While multiple cap configurations are pooled, generalization to substantially different systems (e.g., wet electrodes, other amplifiers, mobile EEG) is not validated.
- Personalization and adaptation: Few-shot subject-specific adaptation, domain-adversarial training, or calibration strategies to improve per-user performance are not assessed.
- Multimodal fusion: Although eye-tracking and other biosignals are collected, the paper does not quantify the incremental value of EEG BFMs over, or in combination with, eye gaze, HRV/ECG, or behavioral streams.
- Longitudinal causal interpretation: Declining cognitive load and increasing prefrontal relevance are interpreted as learning progression without controlling for day/session confounds (e.g., fatigue, circadian effects); causal analyses are absent.
- Pretraining choices in BFMs: The impact of pretraining objectives, dataset diversity, and context length on downstream cognitive load performance is not dissected; only two BFMs (LaBraM, CBraMod) are evaluated.
- Uncertainty quantification: The system does not estimate prediction uncertainty (e.g., conformal prediction) to support reliable decision-making in adaptive BCIs.
- Reproducibility and openness: Data and code availability, preprocessing pipelines, and random seeds are not provided, limiting independent replication and benchmarking.
- Ethics and deployment constraints: Privacy, consent, on-device processing requirements, and energy/battery considerations for continuous cognitive monitoring are not discussed.
Glossary
- Adaptive Training System (ATS): A scoring and labeling framework used in VR pilot training to quantify task performance and cognitive load. "Adaptive Training System (ATS) for Pilots"
- Band-pass filter: A signal processing filter that passes frequencies within a specified range and attenuates frequencies outside that range. "band-pass filtered within Hz"
- Brain-Computer Interfaces (BCIs): Systems that translate brain activity into commands to interact with external devices or software. "Brain-Computer Interfaces (BCIs)"
- Brain Foundation Models (BFMs): Large pre-trained neural models for biosignals that learn generalizable representations of brain activity. "Brain Foundation Models (BFMs)"
- CBraMod: A specific brain foundation model that uses criss-cross attention and frequency-domain encoders for EEG decoding. "CBraMod combines temporal and frequency-domain encoders with convolutional positional embeddings and 12 transformers with criss-cross attention."
- Cognitive load: The mental effort required to perform a task, often estimated from physiological signals like EEG. "Cognitive load estimation plays a pivotal role"
- Conditional positional encoding: A positional encoding scheme that conditions on input characteristics; can be asymmetric. "asymmetric conditional positional encoding"
- Cosine annealing scheduler: An optimization scheduling technique that gradually decreases the learning rate using a cosine function. "with Adam optimizer with a cosine annealing scheduler"
- Criss-cross attention: An attention mechanism that captures dependencies along both horizontal and vertical dimensions. "12 transformers with criss-cross attention"
- Electroencephalography (EEG): A non-invasive technique for recording electrical activity of the brain via scalp electrodes. "Electroencephalography (EEG) offers a non-invasive, cost-effective modality"
- EEGConformer: A deep learning architecture leveraging convolutional-transformer hybrids for EEG decoding. "EEGConformer require retraining per dataset and offer limited flexibility with marginal gains."
- EEGNet: A compact convolutional neural network architecture tailored for EEG-based BCIs. "fixed models like EEGNet and EEGConformer require retraining per dataset"
- Functional connectivity: Statistical dependencies between brain regions’ signals used to infer network interactions. "functional connectivity"
- Global pooling: A feature aggregation strategy that combines all time steps or spatial features into a single vector. "Global pooling: Aggregates all time steps into a single vector."
- Group-average (spatial pooling): Averaging electrode features within predefined anatomical regions to reduce variability and preserve neuroanatomical relevance. "Group-average: Electrode features were averaged within 9 anatomically defined regions"
- L1 sparsity constraint: A regularization technique encouraging sparse model weights via L1 penalty. "with an sparsity constraint"
- LaBraM: A large brain foundation model using convolutional encoders and transformers with self-attention for EEG representation learning. "LaBraM employs a convolutional temporal encoder, spatio-temporal trainable positional embeddings, and 12 transformers with self-attention."
- Longitudinal analysis: An approach that examines data across multiple time points to assess trends or progression. "A longitudinal analysis across multiple days revealing learning progression"
- Mean pooling: Temporal aggregation by averaging features across time windows. "Mean pooling: Computes the average across time."
- Mean-standard deviation (MeanStd) pooling: Temporal aggregation that concatenates mean and standard deviation to capture central tendency and variability. "Mean-standard deviation (MeanStd): Stacks mean and standard deviation over time"
- Montage: The configuration or layout of EEG electrodes on the scalp. "with channels varied per montage."
- Nested cross-validation (CV): A validation scheme with inner and outer loops to tune hyperparameters and assess generalization without leakage. "we used nested cross-validation (CV)"
- Notch filter: A filter that removes a narrow band of frequencies, often used to suppress powerline noise. "with a 60 Hz notch filter"
- Owen values: A game-theoretic measure related to Shapley values for hierarchical or partitioned features. "to compute Owen values"
- Parieto-occipital: Referring to brain regions spanning the parietal and occipital lobes involved in visual and spatial processing. "parieto-occipital areas linked to visual working memory"
- Partition SHAP: A model-agnostic explainability method that accounts for feature correlations via hierarchical partitions. "we apply Partition SHAP (SHapley Additive exPlanations) to quantify feature importance."
- Pearson correlation: A statistic measuring linear correlation between predicted and ground-truth continuous values. "evaluating performance via Pearson correlation"
- Positional embeddings (spatio-temporal): Learned vectors that encode position and time information to inform sequence models. "spatio-temporal trainable positional embeddings"
- Power spectral density (PSD): A representation of signal power across frequency bands, commonly used in EEG feature extraction. "power spectral density"
- Prefrontal regions: Frontal brain areas associated with cognitive control, decision-making, and executive function. "prefrontal regions linked to cognitive control"
- Radial Basis Function (RBF) kernel: A kernel function used in SVMs to map inputs into a higher-dimensional space for non-linear classification or regression. "with a fixed Radial Basis Function kernel (RBF) kernel."
- Self-attention: A mechanism in transformers that computes attention weights within a sequence to model dependencies. "12 transformers with self-attention"
- Self-supervised objectives: Training objectives that derive supervision from the data itself to learn representations without labeled targets. "via self-supervised objectives toward generalizable representations of brain activity."
- Shapley values: Game-theoretic attribution values that fairly distribute a model’s output among its input features. "an efficient approximation of Shapley values."
- Temporal pooling: Aggregating features over time to standardize input length or emphasize longer-term patterns. "Temporal pooling was applied after spatial pooling to aggregate features over time."
- Topomap: A spatial visualization (topographical map) of EEG feature relevance or activity across the scalp. "Topomap of SHAP feature relevance"
- Transformers: Sequence models based on attention mechanisms used for learning temporal and spatial dependencies. "12 transformers"
- Virtual Reality (VR): Immersive simulated environments used for training and experimentation. "a Prepar3D VR-based flight simulator"
- Working memory: A cognitive system for temporarily holding and manipulating information during tasks. "linked to working memory"
Practical Applications
Immediate Applications
Below are deployable use cases that can be implemented with current research-grade EEG hardware and the paper’s pipeline (BFMs for feature extraction, spatial group-averaging, temporal pooling, simple downstream estimators, and Partition SHAP interpretability). Each item includes sectors, possible tools/products/workflows, and feasibility notes.
- Neuroadaptive VR training modules for high-stakes domains
- Sectors: aviation, defense, industrial safety, healthcare (simulation), education (skills training)
- What: Integrate the paper’s real-time cognitive load estimator into VR training (e.g., flight simulators) to adapt task difficulty, pacing, and feedback based on user load using ~16 s windows and <1 s CPU inference latency.
- Tools/products/workflows: SDK/plugin for Unity/Unreal VR training platforms; “Cognitive Load Controller” that consumes BFM features and adjusts training parameters; dashboard tracking multi-day learning progression.
- Assumptions/dependencies: Requires research-grade, multi-channel dry EEG caps with coverage of frontal/parietal regions; ATS-like or performance-derived labels for calibration/validation; tolerance for 16 s+ latency; stable data quality in motion-rich VR settings.
- Instructor and learning-ops dashboards for cognitive progression
- Sectors: education, corporate L&D, simulation centers
- What: Use the longitudinal pipeline to visualize declining load over sessions and SHAP maps highlighting growing prefrontal relevance, signaling skill acquisition and cognitive efficiency.
- Tools/products/workflows: Web dashboard showing daily/weekly cognitive load trends, SHAP topomaps per cohort, learning milestones; alerts when learners remain overloaded/underloaded.
- Assumptions/dependencies: Access to session-level EEG; privacy-preserving aggregation across learners; clear policies on data use.
- Model auditing and neurophysiological validation for EEG AI
- Sectors: software/AI tools, healthcare research, safety-critical training
- What: Apply Partition SHAP to confirm models emphasize prefrontal and parietal regions during cognitive tasks; use as an acceptance test and drift detector.
- Tools/products/workflows: “SHAP Audit” tool that runs domain-aware Partition SHAP on frozen BFM encoders and downstream models; weekly reports flagging shifts in regional importance.
- Assumptions/dependencies: Additional compute for SHAP evaluations (batch/offline preferred); domain trees for Partition SHAP aligned to the 9-region grouping.
- Cross-device EEG harmonization for multi-cohort studies
- Sectors: academia, CROs, neurotech startups
- What: Deploy the group-average channel alignment to standardize features across different caps/montages in multi-year or multi-site studies.
- Tools/products/workflows: Open-source preprocessing library that maps heterogeneous montages into 9-region representations; plug-ins for MNE/PyTorch pipelines.
- Assumptions/dependencies: Adequate regional electrode coverage in each cap; metadata on channel locations; no drastic differences in hardware noise.
- Out-of-the-box cognitive load analytics for HCI experiments
- Sectors: human factors, UX research, software usability
- What: Use LaBraM-based features with a linear head to quantify user load during UI tests and A/B experiments; rapidly compare designs’ cognitive demands.
- Tools/products/workflows: Lightweight Python API (PyTorch) for feature extraction and regression; batch-processing scripts to correlate load with task performance.
- Assumptions/dependencies: Short per-task windows (≥16 s) and stable EEG; minimal per-user calibration or a small adaptation set.
- Esports and skill training feedback
- Sectors: sports tech, gaming, coaching
- What: Provide feedback on workload during drills or scrims to optimize practice blocks and recovery, using real-time inference.
- Tools/products/workflows: Overlay HUD or companion app showing current load; session summaries indicating overload/underload periods.
- Assumptions/dependencies: Will require research-grade EEG and motion artifact handling; acceptance by users and teams regarding wearability.
- Cognitive load–aware workstation assistants
- Sectors: enterprise software, productivity tools
- What: In controlled lab or pilot deployments, modulate notifications, break reminders, or task chunking based on measured load.
- Tools/products/workflows: Desktop agent that consumes EEG stream and triggers focus modes or break prompts; logs for personal reflection and coaching.
- Assumptions/dependencies: Willingness to wear EEG during desk work; strict privacy controls; latency (16 s windows) acceptable for non-time-critical adjustments.
Long-Term Applications
These require further research, scaling, validation, hardware miniaturization, or regulatory/ethical frameworks before broad deployment.
- Generalizable cognitive telemetry for workforce safety and scheduling
- Sectors: manufacturing, logistics, transportation, energy
- What: Use continuous cognitive load analytics to prevent overload-related errors, optimize shift schedules, and inform staffing.
- Tools/products/workflows: Wearable EEG + multimodal (HRV/eye tracking) packs; fleet dashboards; fatigue/overload alerts integrated with safety SOPs.
- Assumptions/dependencies: Robust performance on mobile wearables with fewer channels; artifact resilience; union/worker council approvals; strong privacy and consent frameworks.
- Driver and pilot state monitoring for adaptive automation
- Sectors: automotive (ADAS), aviation (cockpits), rail/maritime
- What: Adapt automation handovers, warning strategies, or interface complexity based on driver/pilot cognitive load.
- Tools/products/workflows: On-headset or seat-embedded EEG; in-cabin multimodal fusion; safety cases and HARA (hazard analysis and risk assessment).
- Assumptions/dependencies: Automotive-grade sensors; regulatory certification; low-latency windows (shorter than 16 s) without sacrificing reliability.
- Personalized, neuroadaptive education at scale (LMS integration)
- Sectors: EdTech, MOOCs, K–12/HE
- What: Continuous adjustment of content difficulty, pacing, and assessments using learner cognitive load measured by BFMs; longitudinal learning analytics.
- Tools/products/workflows: LMS plugins and teacher dashboards; APIs for content engines; privacy-preserving cohort analytics.
- Assumptions/dependencies: Acceptable consumer hardware (lighter EEG) or high-quality proxies via multimodal fusion; extensive validation beyond flight-sim tasks; equity and accessibility considerations.
- Clinical decision support for cognitive fatigue and rehabilitation
- Sectors: healthcare, neurology, mental health
- What: Use interpretable load metrics to titrate cognitive therapy intensity, monitor chemo brain, post-concussion recovery, or neurodegenerative disease progression.
- Tools/products/workflows: Clinical dashboards with SHAP-derived regional relevance; EHR integration; remote monitoring kits for home use.
- Assumptions/dependencies: FDA/CE approvals; large, condition-specific validation cohorts; clinical utility studies; interpretable outputs necessary for clinicians.
- Neuroergonomic design and evaluation of complex interfaces
- Sectors: aerospace, defense, industrial control rooms, medical devices
- What: Employ load maps and SHAP insights to redesign control layouts, alerts, and workflows; validate that prefrontal/parietal demands are appropriate.
- Tools/products/workflows: Design iteration cycles instrumented with EEG; heatmaps of cognitive demand across tasks; before/after ROI analyses.
- Assumptions/dependencies: Acceptance of EEG-in-the-loop evaluations; stable mapping from lab findings to field contexts.
- Embedded BFM inference in XR headsets and wearables
- Sectors: XR hardware, consumer neurotech
- What: On-device, privacy-preserving cognitive load estimation using optimized BFM encoders and short-window adaptations.
- Tools/products/workflows: TinyML/edge ports of LaBraM-like encoders; hardware acceleration; device-level privacy controls.
- Assumptions/dependencies: Smaller sensor arrays with adequate frontal/parietal coverage; proven generalization to consumer-grade signals.
- Standardization and policy frameworks for cognitive load data
- Sectors: policy/regulation, standards bodies, HR/compliance
- What: Define data schemas, fairness audits, consent protocols, and usage restrictions for “cognitive telemetry” in work and education.
- Tools/products/workflows: Compliance toolkits leveraging SHAP audits; standardized reporting on model focus (e.g., frontal emphasis) and performance; third-party certification.
- Assumptions/dependencies: Multi-stakeholder consensus; enforceable governance; alignment with GDPR/CCPA and health data rules.
- Foundation-model–based BCI platforms beyond cognitive load
- Sectors: software/AI, neurotech R&D
- What: Reuse BFMs as a general EEG backbone for emotion, attention, drowsiness, workload switching, or intention decoding via lightweight fine-tuning.
- Tools/products/workflows: Modular APIs exposing per-channel, per-second embeddings; task adapters; plug-and-play interpretability.
- Assumptions/dependencies: Large, diverse pretraining corpora; robust transfer across tasks and devices; community benchmarks and best practices.
- Consumer wellness and focus coaching
- Sectors: consumer health, productivity apps
- What: Personalized pacing, break recommendations, and focus coaching in study/work contexts using simplified sensors and multimodal fusion.
- Tools/products/workflows: Mobile apps with feedback loops; privacy-first on-device inference; gamified habit formation.
- Assumptions/dependencies: Accuracy with low-channel or dry consumer headbands; clear user value vs. friction; rigorous privacy and transparency.
Notes on feasibility across applications:
- Generalization and calibration: The paper shows improved cross-subject performance with BFMs and group-average pooling, but non-flight tasks and consumer-grade hardware need additional validation. Shorter windows may be needed for certain real-time uses.
- Interpretability and trust: Partition SHAP provides model-agnostic, region-level auditability; periodic audits should be standard, especially in regulated or safety-critical settings.
- Hardware and signal quality: Many applications hinge on reliable frontal/parietal coverage, motion artifact suppression, and consistent channel mapping.
- Ethics and privacy: Cognitive telemetry is sensitive; usage must include informed consent, minimal data retention, purpose limitation, and employee/learner protections.
Collections
Sign up for free to add this paper to one or more collections.