- The paper introduces REVE, a novel EEG foundation model that employs a scalable transformer with 4D positional encoding and masked autoencoding.
- The model uses block masking and Flash Attention v2 for efficient training, achieving up to 17% improved linear probing performance on diverse EEG tasks.
- The work demonstrates strong cross-dataset generalization, supporting rapid adaptation for clinical diagnostics, BCI calibration, and neuroscience research.
REVE: A Foundation Model for EEG with Large-Scale Pretraining and Universal Adaptation
Introduction
The REVE model addresses the challenge of developing a robust foundation model for electroencephalography (EEG) that generalizes across heterogeneous datasets, electrode configurations, and recording protocols. Unlike prior EEG foundation models constrained to fixed montages or limited datasets, REVE introduces a novel 4D positional encoding and a scalable transformer-based architecture, pretrained on the largest EEG corpus to date—over 60,000 hours from 92 datasets and 25,000 subjects. The model is designed to support arbitrary spatial and temporal input structures, enabling transfer to unseen setups and tasks with minimal adaptation.
Model Architecture and Pretraining Framework
REVE employs a masked autoencoder (MAE) paradigm, processing multi-channel EEG data through a linear patch embedding, followed by a 4D spatio-temporal positional encoding. The positional encoding leverages the true 3D coordinates of electrodes and temporal patch indices, augmented with Gaussian noise for improved generalization. The model applies a block masking strategy, masking contiguous regions in both spatial and temporal dimensions to simulate realistic disruptions and encourage robust representation learning.
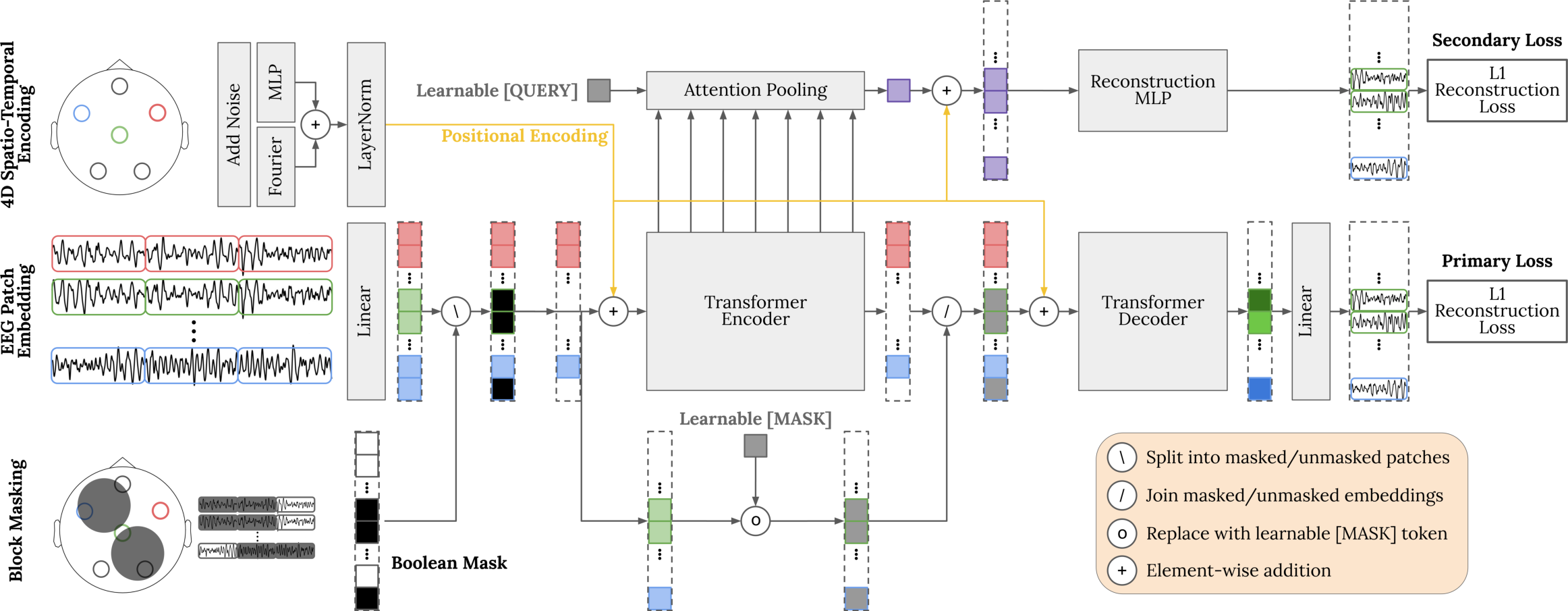
Figure 1: Overview of the REVE pretraining framework, illustrating patch embedding, 4D spatio-temporal position encoding, block masking, transformer encoding, and dual reconstruction objectives.
The transformer backbone incorporates RMSNorm and GEGLU activations for improved training stability and expressivity. Flash Attention v2 is used for efficient memory and compute scaling. During pretraining, the encoder reconstructs masked EEG segments, minimizing an L1 loss to mitigate the impact of noise. A secondary objective reconstructs masked patches from a global token obtained via attention pooling, promoting distributed and generalizable feature learning across all encoder layers.
4D Positional Encoding and Block Masking
The 4D positional encoding is a key innovation, enabling the model to process signals of arbitrary length and electrode arrangement. Each patch is assigned a position vector comprising (x,y,z,t), where (x,y,z) are the electrode coordinates and t is the temporal index. These are projected into a multi-frequency Fourier space, with all combinations of frequencies across dimensions, followed by sine and cosine transformations. This encoding is combined with a learnable linear projection, and the final positional vector is added to the patch embeddings.
Block masking is parameterized by masking ratio, spatial and temporal radii, and dropout settings, ensuring that the model learns to reconstruct signals under realistic disruptions rather than trivial random masking. Ablation studies confirm that block masking yields superior downstream performance compared to random masking, especially at moderate masking ratios.
Training Strategy and Scaling Laws
REVE is trained using StableAdamW with a trapezoidal learning rate schedule and Megatron-style initialization. Model scaling is achieved by adjusting depth, width, and attention heads while maintaining a fixed FFN ratio. Learning rate scaling follows empirically validated power laws, and data parallelism is used to maximize throughput. The pretraining corpus is curated to maximize diversity, with minimal filtering to preserve signal heterogeneity.
The model demonstrates strong scaling effects: larger architectures consistently yield richer embeddings and improved linear probing performance. Model souping—averaging weights from multiple fine-tuning runs—further enhances generalization, particularly in noisy or small-data regimes.
Downstream Task Evaluation
REVE is evaluated on 10 diverse downstream EEG tasks, including motor imagery classification, seizure detection, sleep staging, cognitive load estimation, emotion recognition, and mental disorder diagnosis. The model achieves state-of-the-art balanced accuracy across all benchmarks, with an average gain of 2.5% over the strongest prior foundation model (CBraMod). Notably, REVE's embeddings support high-quality linear probing, with up to 17% improvement over baselines, and generalize to unseen electrode configurations and longer input durations than used in pretraining.
The secondary loss function, which reconstructs masked tokens from a global representation, is shown to be particularly effective in frozen-feature scenarios, improving the quality of embeddings for zero-shot and few-shot applications.
Implementation Considerations
- Data Requirements: Pretraining requires access to large, heterogeneous EEG datasets with electrode position metadata. The preprocessing pipeline includes resampling, band-pass filtering, normalization, and amplitude clipping.
- Computational Resources: Training REVE-Base requires approximately 260 A100 GPU hours, with scaling to larger models demanding proportionally more compute.
- Model Adaptation: The 4D positional encoding enables direct transfer to new datasets and montages without retraining positional priors. Fine-tuning is performed via a two-step strategy: linear probing followed by full network adaptation, with LoRA for parameter-efficient updates.
- Deployment: The encoder can be used for feature extraction in clinical and BCI pipelines, supporting rapid calibration and cross-site deployment. The decoder is not released to mitigate privacy risks associated with raw EEG reconstruction.
Limitations and Future Directions
REVE requires input signals of at least one second and multiples thereof, which could be addressed via padding and causal masking. The Fourier-based positional encoding restricts embedding dimensions to specific values, necessitating truncation for other sizes. The pretraining corpus, while large, is demographically imbalanced and could benefit from targeted curation and selection. Future work should explore advanced SSL objectives, scaling laws for EEG models, and extension to other modalities (MEG, iEEG, OPM-MEG).
Implications and Prospects
REVE establishes a unified foundation for EEG analysis, enabling standardized embeddings, robust cross-dataset transfer, and efficient adaptation to new tasks and setups. The model's architecture and training strategy provide a blueprint for future foundation models in neurophysiology, with potential applications in clinical diagnostics, BCI calibration, and neuroscience research. The release of code, pretrained weights, and adaptation recipes is expected to accelerate progress in the field and facilitate the development of fair, scalable benchmarks.
Conclusion
REVE advances the state of the art in EEG foundation modeling by combining scalable masked autoencoding, flexible 4D positional encoding, and large-scale pretraining. The model demonstrates robust generalization across devices, montages, and tasks, supporting high-quality linear probing and transfer with minimal adaptation. These properties position REVE as a practical and extensible foundation for EEG analytics, with significant implications for clinical and research applications.