FreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
Abstract: Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.









































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
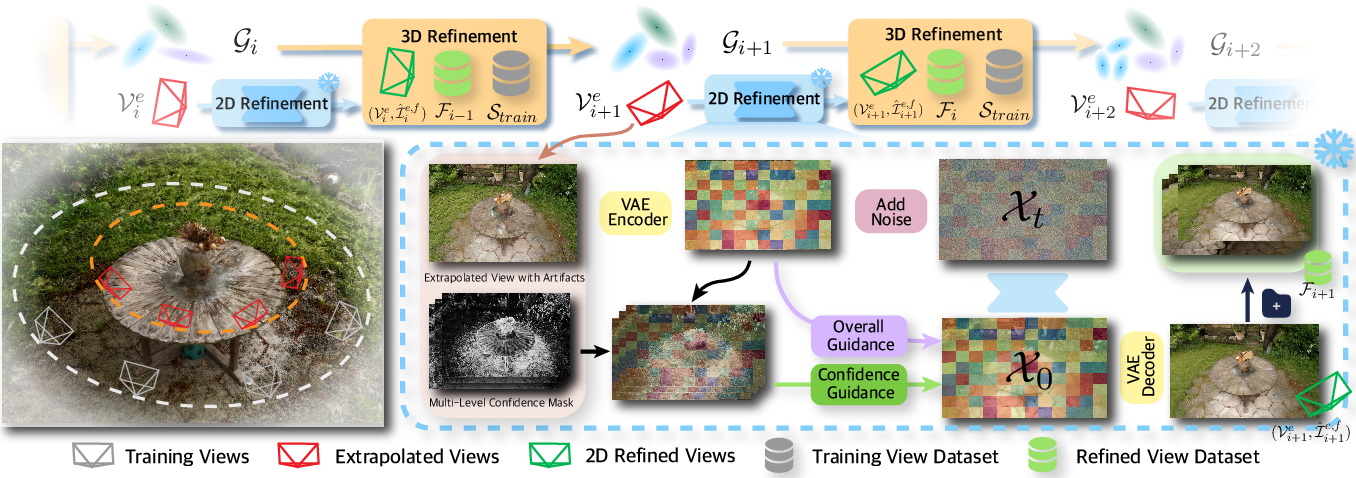
This paper introduces FreeFix, a method that helps make 3D scenes look better when viewed from new angles, especially from viewpoints that weren’t used during training. It improves a popular 3D technique called 3D Gaussian Splatting without retraining or fine-tuning any big image generation models (diffusion models). In short, FreeFix cleans up visual mistakes in new views using a smart “image fixer” and then updates the 3D scene so future views look more consistent.
Goals and Questions
The paper focuses on three simple questions:
- How can we fix messy or blurry parts in new views of a 3D scene when we don’t have many training photos?
- Can we use powerful pre-trained diffusion models “as-is” (without fine-tuning) and still get high-quality, consistent results?
- How do we tell the model which parts of the image to trust and which parts need fixing, so it doesn’t change good areas or introduce new errors?
How FreeFix Works
Think of a 3D scene as a collection of tiny, soft blobs (called “Gaussians”) that together form surfaces and colors—this is 3D Gaussian Splatting. Now imagine you’re moving a virtual camera to a new spot far from where original photos were taken. The scene might look wrong there: flickers, holes, or stretched textures. FreeFix fixes this in three key steps:
- Interleaved 2D–3D refinement
- Step 1: Render an image from the new viewpoint using the current 3D scene.
- Step 2: Feed that rendered image into a powerful pre-trained image diffusion model (like SDXL or FLUX). This model acts like a “smart paintbrush” that removes artifacts and restores details.
- Step 3: Take the improved image and use it to update the 3D scene. Now the scene itself gets better.
- Repeat this along a smooth camera path so each newly fixed view helps the next one stay consistent.
- Confidence maps (which pixels to trust)
- The system creates a per-pixel “confidence” map—basically, a score for how sure the 3D renderer is about each part of the image.
- High-confidence areas are likely correct and should be preserved; low-confidence areas are where the diffusion model should be more creative to fix errors.
- This targeted guidance tells the diffusion model where to repaint and where to keep things as they are.
- Multi-level guidance across denoising
- Early in the diffusion process, the model builds the overall structure, so FreeFix uses broader guidance to keep the big shapes right.
- Later, when fine details are added, the guidance becomes stricter, focusing only on uncertain spots so textures and edges look sharp and consistent.
- An extra “overall guidance” nudge keeps low-texture regions (like sky or ground) from drifting or becoming blurry across views.
Main Findings and Why They Matter
- Better quality without fine-tuning: FreeFix improves the appearance of new views to match or even beat methods that require costly fine-tuning of diffusion models.
- More consistent frames: Because each refined image is fed back into the 3D scene, future views stay visually consistent. This avoids flickering or sudden changes when moving the camera.
- Works across different scenes: Using strong, general-purpose image diffusion models “as-is” keeps FreeFix flexible for many types of scenes (indoor rooms, outdoor landscapes, street driving).
- Competitive results: Tested on well-known datasets (LLFF, Mip-NeRF 360, Waymo), FreeFix outperforms other no-finetune methods and is comparable to, or better than, fine-tuned systems in many cases.
These results matter because they show you can get high-quality, stable 3D view synthesis without the heavy cost and risk of retraining big models, which often makes them less general.
Impact and What This Means
FreeFix makes it more practical to build realistic, explorable 3D scenes from limited photos:
- For AR/VR, games, and virtual tours, it means smoother, cleaner camera moves and fewer visual glitches.
- For autonomous driving simulation and mapping, it provides better visuals from viewpoints that weren’t captured, helping testing and planning.
- It reduces the need for expensive dataset collection and model fine-tuning, making advanced 3D rendering more accessible.
Limitations and future directions:
- If a new view is extremely uncertain (almost everything is low confidence), fixing it can still be hard.
- Updating the 3D scene step-by-step can be slow; speeding up this process is a good next step.
- Adding smarter guidance or lightweight consistency checks could further improve results.
Overall, FreeFix shows that with smart per-pixel guidance and an interleaved 2D–3D loop, pre-trained image diffusion models can significantly upgrade 3D Gaussian Splatting—without retraining—bringing high-quality, consistent novel views closer to everyday use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for future research.
- Convergence and stability analysis
- No theoretical or empirical analysis of convergence behavior for the interleaved 2D–3D optimization; conditions under which the process stabilizes or diverges are unknown.
- Lack of diagnostics or safeguards against error accumulation (e.g., geometry/color drift) over long extrapolated trajectories.
- Computational efficiency and scalability
- Computational/memory cost of computing Fisher-information-based per-pixel certainty maps in 3DGS is not quantified; scaling to scenes with millions of Gaussians or high-resolution outputs is unclear.
- End-to-end runtime breakdown (diffusion denoising + repeated 3DGS updates) and comparisons to fine-tuned/VDM baselines are absent; unclear how the method scales with trajectory length m and scene complexity.
- No scheduling or budget-aware strategy for when to trigger 2D refinements vs 3D updates to reduce iterations.
- Guidance design and hyperparameterization
- The multi-level certainty scheme relies on hand-tuned values; no method to adaptively learn or select per scene, view, or timestep.
- “Overall guidance” blending with opacity in early steps uses a fixed hyperparameter and a fixed schedule; no principled or adaptive scheduling strategy is provided or evaluated.
- Multiplying certainty with opacity may suppress needed edits in low-opacity yet important regions (e.g., semi-transparent boundaries, thin structures); alternative compositions are not explored.
- Reliability of Fisher-information-based certainty
- Sensitivity of the certainty map to noisy or biased gradients in 3DGS is not analyzed; robustness under different renderer settings (e.g., anti-aliasing, splat sizes) is unclear.
- Comparative study of certainty vs alternative uncertainty proxies (e.g., ensemble models, test-time augmentation, Jacobian norm regularization, photometric variance) is missing.
- Diffusion backbone choices and control
- Limited backbone coverage (SDXL, Flux, SVD); generality across other IDMs/VDMs (e.g., SD 1.5/3.0, PixArt-α, Llama-Gen, consistency models) is not established.
- No analysis of prompt sensitivity, negative prompts, or IP-Adapter/ControlNet-style conditioning to preserve scene semantics and suppress hallucinations.
- The paper asserts per-pixel guidance is impractical for modern VDMs due to temporal downsampling but does not empirically test workarounds (e.g., latent-space mask projection, framewise control channels, patch-wise VDM refinement).
- 3D consistency and geometry integrity
- Quantitative 3D consistency metrics (e.g., depth/normal consistency across views, re-projection errors, geometric fidelity against LiDAR/GT meshes) are not reported.
- Strategy to prevent geometry corruption in regions where the IDM hallucinates structurally implausible content is limited to a lower loss weight; no spatially adaptive weighting or hallucination detection.
- No mechanism to backtrack or correct earlier refined views if later views reveal inconsistencies (e.g., occlusion ordering errors uncovered by new viewpoints).
- Robustness and failure modes
- Sensitivity to pose errors and calibration noise is not studied; impact on certainty estimation and interleaved optimization remains unknown.
- Performance under extreme sparsity, large extrapolation distances, and highly reflective/transparent or textureless surfaces is not systematically evaluated.
- Dynamic or non-rigid scenes are out of scope; how to handle moving objects and temporal changes is an open question.
- Evaluation breadth and metrics
- Waymo evaluation lacks GT; reliance on KID alone under-constrains fidelity/consistency assessment; no temporal consistency metrics (e.g., reprojection LPIPS, cycle consistency) or user studies.
- No controlled study on how results vary with training-view sparsity, extrapolation distance, or trajectory continuity; the role of continuous vs disjoint view ordering is not explored.
- Absence of perceptual/semantic realism evaluations (e.g., CLIP-score consistency with inputs, human preference tests).
- Optimization objectives and integration strategy
- The 3D refinement loss uses global weights for generated views but not spatially masked weights tied to per-pixel certainty; potential overfitting to unreliable IDM regions remains.
- Only L1+SSIM losses are used; impact of adding perceptual/adversarial or geometry-aware losses (e.g., normal/depth consistency, silhouette constraints) is not studied.
- Color-bias correction via per-view affine transforms is heuristic; no analysis of its limits (e.g., complex color casts) or learning a globally consistent color space.
- Generalization and domain coverage
- Experiments focus on LLFF, Mip-NeRF 360, and Waymo; robustness to out-of-domain scenes (e.g., industrial, medical, nighttime, low-light, snow/rain) is not validated.
- The method claims preserved generalization via no finetuning, but failure modes under strong domain shift (e.g., stylized or highly specialized domains) are not characterized.
- Representation and modality extensions
- Applicability beyond 3DGS to other 3D representations (e.g., NeRF variants, meshes, point clouds) is untested; general recipe for transferring certainty computation is unspecified.
- Use of additional modalities (depth, normals, semantics) for stronger cross-view constraints or for guiding diffusion is unexplored.
- Long-horizon consistency
- Cumulative drift over long sequences is not quantified; no strategies like periodic keyframe anchoring, bidirectional passes, or global bundle-like refinement in appearance space are evaluated.
- Reproducibility details
- Critical details are deferred to the supplement (e.g., Fisher derivation, training sampling strategy, schedules), limiting immediate reproducibility and fair comparison; standardized benchmarks/splits for extrapolation trajectories are not established.
Practical Applications
Immediate Applications
Below are practical, deployable-now use cases that draw directly from the paper’s method (FreeFix), findings, and innovations. Each item notes the sector, potential tools/workflows, and key assumptions or dependencies.
- Free-viewpoint XR experiences from sparse captures
- Sector: media/entertainment, tourism, education
- Tools/workflows: a plugin that wraps FreeFix around 3D Gaussian Splatting (3DGS) or NeRF pipelines in Unity/Unreal; batch process of sparsely captured scenes to refine extrapolated viewpoints; export to VR/AR viewers
- Assumptions/dependencies: scene largely static; accurate camera poses; access to pretrained image diffusion models (IDMs) like SDXL/Flux; GPU capacity; proper licensing of IDM weights; continuous camera trajectory sampling for interleaving
- Post-processing “artifact cleanup” for 3DGS deliverables
- Sector: software/content creation (VFX, games), visualization
- Tools/workflows: CLI/library that ingests a trained 3DGS and runs the interleaved 2D–3D FreeFix refinement with multi-level confidence guidance; integrates refined frames back into the scene
- Assumptions/dependencies: initial 3DGS is trained; hyperparameters (e.g., γc, β) tuned to content; affine color correction enabled to avoid accumulated bias
- Consumer mobile 3D scanning with fewer photos
- Sector: consumer AR, e-commerce
- Tools/workflows: smartphone capture apps upload sparse images; cloud pipeline runs 3DGS training and FreeFix refinement; deliver a better model for AR product placement or 3D listings
- Assumptions/dependencies: reliable camera calibration/EXIF; cloud GPUs; content safety policies when hallucinations fill missing regions
- E-commerce product 3D spin with improved consistency
- Sector: retail/e-commerce
- Tools/workflows: web service that converts a small photo set to 3DGS and uses FreeFix to stabilize extrapolated views; WebGL viewer for real-time product rotation
- Assumptions/dependencies: small object-centric scenes; correct background handling (weak textures may require stronger overall guidance early in denoising)
- Autonomous driving simulation and data augmentation from limited street passes
- Sector: automotive
- Tools/workflows: refine extrapolated street views in sparse datasets (Waymo-like) for simulation, perception pretraining, and scenario prototyping; integrate FreeFix outputs into sim engines
- Assumptions/dependencies: mostly static scenes; strict internal validation to prevent generative artifacts from biasing downstream training; clear provenance markers
- Robotics simulation and occlusion-aware planning
- Sector: robotics
- Tools/workflows: use per-pixel certainty maps to identify uncertain regions in rendered views, guiding synthetic viewpoint generation and scenario rehearsal; integrate with Gazebo/ROS visualization
- Assumptions/dependencies: static or quasi-static environments; mapping of confidence outputs to robot coordinate frames; safety gates when generative hallucinations are present
- Capture guidance and quality assurance for photogrammetry/digital heritage
- Sector: AEC (architecture, engineering, construction), cultural heritage
- Tools/workflows: certainty maps highlight low-confidence regions to steer additional image capture or sensor deployment; dashboard for QA
- Assumptions/dependencies: robust camera calibration; confidence computation (Fisher-information–based) aligned with the renderer; operational workflows for recapture
- Academic benchmarking and teaching modules
- Sector: academia
- Tools/workflows: reproducible baseline for interleaved 2D–3D refinement without fine-tuning; assignments comparing opacity vs certainty guidance; ablation on IDM backbones
- Assumptions/dependencies: access to datasets (LLFF, Mip-NeRF 360, Waymo-like); open/compatible IDM licenses (e.g., Flux/SDXL)
- Visual inspection dashboards for 3D model health
- Sector: software tooling, digital twin ops
- Tools/workflows: integrate certainty maps to flag potential failure cases (e.g., thin structures, weak textures) before deployment to viewers or simulations
- Assumptions/dependencies: thresholds calibrated per scene type; human-in-the-loop review recommended
Long-Term Applications
Below are forward-looking use cases that require further research, scaling, or engineering—often hinging on improved models (e.g., video DMs), broader scene types (dynamic scenes), and stronger guarantees around consistency and provenance.
- Real-time, on-device refinement for mobile AR
- Sector: consumer AR, software
- Tools/workflows: distilled IDMs and optimized 3DGS with hardware acceleration; interactive artifact fixing during user capture; immediate feedback via certainty maps
- Assumptions/dependencies: efficient on-device IDMs (low-latency, low-memory), GPU/NPUs on phones/AR headsets, model compression and caching; battery considerations
- Dynamic scene support with consistent temporal guidance
- Sector: live events, telepresence, sports broadcasting
- Tools/workflows: extend interleaving to dynamic 3DGS; use video diffusion backbones that accept per-pixel guidance (or new mechanisms that avoid temporal down-sampling); motion-aware certainty estimation
- Assumptions/dependencies: robust tracking of moving entities; temporally stable guidance; advances in VDM architectures to accept high-resolution, per-pixel masks
- City-scale digital twins with reduced capture density
- Sector: AEC, smart cities, infrastructure/energy
- Tools/workflows: large-batch pipelines that process districts; confidence-driven capture planning; progressive refinement with periodic recapture
- Assumptions/dependencies: scalable compute; storage and data governance; careful QA to prevent generative hallucinations from corrupting geospatial fidelity; integration with GIS
- Active exploration and view planning in robotics using certainty
- Sector: robotics, autonomous inspection
- Tools/workflows: certainty maps drive next-best-view selection; combine with SLAM to minimize uncertainty while reducing capture effort
- Assumptions/dependencies: closed-loop control; real-time certainty computation; robust SLAM under sparse observations; safe fallback when hallucination risk is high
- Large-scale autonomous driving training and simulation augmentation
- Sector: automotive
- Tools/workflows: standardized FreeFix-like preprocessing for street datasets; scenario editors with controllable refinements; audit trails and watermarks on generative edits
- Assumptions/dependencies: domain gap management; validation suites to detect harmful hallucinations (e.g., phantom pedestrians); policies on generative content in safety-critical training
- Professional editor products for 3D artifact fixing
- Sector: software tooling, creative industries
- Tools/workflows: “FreeFix Studio” as a standalone application or Blender/Maya add-on; interactive per-pixel mask visualization; batch pipelines for studios
- Assumptions/dependencies: UX for mask tuning (γc scheduling, β control); project provenance; plugin APIs for major DCC tools
- Standards, provenance, and regulatory guidance for generative refinement
- Sector: policy/regulation
- Tools/workflows: watermarking and provenance metadata (C2PA-like) in refined outputs; model cards for refinement pipelines; acceptance criteria in safety-critical domains
- Assumptions/dependencies: cross-industry agreements on disclosure; compliance testing; clear differentiation between reconstruction vs hallucination
- Healthcare and scientific visualization training (with strong controls)
- Sector: healthcare, scientific imaging
- Tools/workflows: use FreeFix-like methods to improve 3D visualization of non-sensitive training phantoms or benchtop setups; certainty maps to mark low-fidelity areas
- Assumptions/dependencies: stringent domain adaptation (medical textures are out-of-domain for web-trained IDMs); regulatory review; prohibition of generative edits to diagnostic data
- Edge/cloud hybrid services for enterprise digital twins
- Sector: industrial IoT, operations
- Tools/workflows: capture at edge, refinement in cloud, incremental updates; confidence thresholds trigger re-capture or defer updates
- Assumptions/dependencies: reliable connectivity; orchestration of compute bursts; versioning and rollback when refinements degrade fidelity
Cross-cutting assumptions and dependencies
- Pretrained IDM availability and licensing (e.g., SDXL, Flux), and compatibility with per-pixel guidance in the latent space
- GPU compute budgets; throughput constraints of interleaved 2D–3D refinement (the paper notes slow convergence and multi-step updates)
- Accurate camera intrinsics/extrinsics and scene staticity; dynamic scenes currently need further research
- Reliability of Fisher-information–based certainty maps and multi-level mask scheduling (γc, β) per scene/domain
- Provenance, auditability, and disclosure when generative hallucinations are introduced—especially in safety-critical or regulated settings
- Human-in-the-loop review for low-confidence regions and failure cases where extrapolated views have minimal credible guidance
Glossary
- 3D Gaussian Splatting: A real-time 3D scene representation that models scenes as collections of volumetric Gaussians for rendering novel views. "Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis"
- 3D priors: Assumptions or constraints derived from 3D geometry used to regularize reconstruction and training. "The regularization terms are often derived from 3D priors"
- 3D VAE: A variational autoencoder with spatiotemporal latent representation used by some video diffusion models to encode/decode video, often with temporal down-sampling. "recent advanced VDMs \cite{yang2024cogvideox, kong2024hunyuanvideo, wan2025wan} utilize 3D VAE as their encoder and decoder"
- Affine matrices: Linear transformations with translation used to correct color biases via per-view optimization. "we define two optimizable affine matrices and "
- Certainty mask: A numerically stable confidence weighting map (complement of uncertainty) used to guide diffusion denoising. "The certainty mask we propose is numerically stable and robust against various types of artifacts."
- Confidence map: A per-pixel map indicating reliable regions in a rendered view to guide targeted denoising. "a per-pixel confidence map rendered from the 3DGS highlights regions requiring further improvement by the 2D DM"
- Covariance (matrix): A matrix defining the shape and orientation of each 3D Gaussian for rendering. "The covariance of 3D Gaussians is defined as "
- Denoising score matching: The training objective for diffusion models that aligns noisy inputs with clean data via a learned score function. "DMs utilize a learnable denoising model to minimize the denoising score matching objective:"
- Diffusion models (DMs): Generative models that iteratively denoise inputs to synthesize realistic images or videos. "Recent approaches leverage generative models, such as diffusion models, to provide additional supervision"
- Fisher information: A measure of how much an observation informs model parameters, used here to derive confidence over rendered views. "The confidence scores are derived from Fisher information"
- GANs (Generative Adversarial Networks): Generative models using a generator and discriminator to produce realistic images. "Early works explored using Generative Adversarial Networks (GANs) to improve rendering quality"
- Generalization–fidelity trade-off: The tension between a model’s ability to generalize broadly and to produce highly faithful reconstructions. "Given the generalizationâfidelity trade-off, we ask: can extrapolated view rendering be improved with DMs without sacrificing generalization?"
- Hessian matrix: The second-order derivative matrix used to approximate uncertainty from Fisher information. "can be approximately derived as a Hessian matrix"
- Image diffusion models (IDMs): Diffusion models specialized for images, used as the backbone for refinement without temporal attention. "Due to the above reasons, we select IDMs as the backbone in FreeFix."
- Image-Based Rendering (IBR): Techniques that synthesize new views by reusing and interpolating existing images. "Image-Based Rendering \cite{shum2007image}"
- Inpainting: Filling in or reconstructing missing or corrupted regions of an image using generative guidance. "using DMs for inpainting"
- KID (Kernel Inception Distance): A metric for measuring distributional similarity between generated and real images without ground truth pairs. "we utilize KID \cite{binkowski2018demystifying} for quantitative assessments."
- Latent space: The compressed representation used internally by autoencoders/diffusion models for denoising and guidance. "the resized confidence map that aligns with the shape of the latent space"
- Light Field Rendering: A classic image-based technique that synthesizes views using light field data. "Light Field Rendering \cite{levoy2023light}"
- LiDAR: A depth-sensing technology using laser pulses to capture 3D structure, often used as geometry priors. "using sparse LiDAR inputs"
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric for image similarity based on deep features. "include the evaluation of PSNR, SSIM, and LPIPS \cite{zhang2018unreasonable}"
- Multi-Plane Image (MPI): A layered, planar scene representation used for view synthesis. "Multi-Plane Image \cite{zhou2018stereo, tucker_single-view_2020}"
- Multi-view consistency: The property that generated content remains coherent across different viewpoints. "the key challenge here is determining what part of the rendered image should be used as guidance for the DM, and how to maintain multi-view consistency."
- Neural Radiance Fields (NeRF): A neural volumetric representation that maps 3D coordinates and viewing directions to color and density. "Neural Radiance Fields (NeRF) \cite{mildenhall2021nerf} and 3D Gaussian Splatting (3DGS) \cite{kerbl20233d} have achieved high-fidelity rendering"
- Novel view synthesis (NVS): The task of generating images of a scene from unseen viewpoints. "Novel view synthesis (NVS) is a fundamental problem in 3D computer vision"
- Opacity mask: A guidance map based on rendered opacity used to steer diffusion, though often insensitive to artifacts. "ViewExtrapolator \cite{liu2024novel}, which uses opacity masks as guidance,"
- Per-pixel confidence guidance: Fine-grained guidance for diffusion denoising based on confidence values for each pixel. "combined with per-pixel confidence guidance for fine-tuning-free image refinement."
- PSNR (Peak Signal-to-Noise Ratio): A reconstruction fidelity metric comparing signal strength to error. "include the evaluation of PSNR, SSIM, and LPIPS"
- Regularization terms: Additional loss components used during training to enforce desired properties or priors. "Existing approaches fall into two categories: adding regularization terms during training"
- SO(3): The group of 3D rotations representing orientation matrices used in Gaussian parameterization. "where "
- SSIM (Structural Similarity Index): A perceptual image quality metric assessing structural similarity. "include the evaluation of PSNR, SSIM, and LPIPS"
- Temporal attention mechanism: Attention across time in video models that improves consistency but increases computation. "the temporal attention mechanism also introduces a computational burden"
- Temporal down-sampling: Reducing temporal resolution in video encoders/decoders, hindering per-pixel guidance. "which performs temporal down-sampling, making it challenging to apply per-pixel confidence guidance."
- Uncertainty map: A rendering of model uncertainty (from Fisher information) indicating unreliable regions. "render the attribute ${\bar{C}_{V}; {G}$ in volume rendering to obtain the uncertainty map."
- VAE (Variational Autoencoder): A generative encoder–decoder model that maps data to and from a latent distribution. "We denote the rendered image after VAE encoding as "
- Video diffusion models (VDMs): Diffusion models designed for video that leverage temporal attention for consistent frames. "While VDMs \cite{wang_planerf_2023, wan2025wan, yang2024cogvideox, kong2024hunyuanvideo} can inherently handle this"
- Volume rendering: The process of integrating contributions of volumetric elements along camera rays to form images. "where and represent viewpoint and 3DGS respectively, while denotes the volume rendering results"
- Warping: Reprojecting pixels between views using geometry or depth to enforce consistency. "warping pixels from to "
- Interleaved refinement strategy: Alternating 2D diffusion-based refinement and 3D updates to improve consistency iteratively. "We present an interleaved 2Dâ3D refinement strategy"
Collections
Sign up for free to add this paper to one or more collections.

