FixingGS: Enhancing 3D Gaussian Splatting via Training-Free Score Distillation
Published 23 Sep 2025 in cs.CV | (2509.18759v1)
Abstract: Recently, 3D Gaussian Splatting (3DGS) has demonstrated remarkable success in 3D reconstruction and novel view synthesis. However, reconstructing 3D scenes from sparse viewpoints remains highly challenging due to insufficient visual information, which results in noticeable artifacts persisting across the 3D representation. To address this limitation, recent methods have resorted to generative priors to remove artifacts and complete missing content in under-constrained areas. Despite their effectiveness, these approaches struggle to ensure multi-view consistency, resulting in blurred structures and implausible details. In this work, we propose FixingGS, a training-free method that fully exploits the capabilities of the existing diffusion model for sparse-view 3DGS reconstruction enhancement. At the core of FixingGS is our distillation approach, which delivers more accurate and cross-view coherent diffusion priors, thereby enabling effective artifact removal and inpainting. In addition, we propose an adaptive progressive enhancement scheme that further refines reconstructions in under-constrained regions. Extensive experiments demonstrate that FixingGS surpasses existing state-of-the-art methods with superior visual quality and reconstruction performance. Our code will be released publicly.
The paper introduces a training-free score distillation mechanism that dynamically guides 3D Gaussian Splatting to reduce artifacts in sparse-view reconstructions.
It incorporates an Adaptive Progressive Enhancement strategy that leverages unreliable viewpoints to improve detail and cross-view consistency.
Experimental results show superior performance over baselines with notable PSNR improvements and robust fidelity across multiple datasets.
FixingGS: Enhancing 3D Gaussian Splatting via Training-Free Score Distillation
Introduction and Motivation
The paper introduces FixingGS, a framework designed to address the limitations of 3D Gaussian Splatting (3DGS) in sparse-view 3D reconstruction and novel view synthesis. While 3DGS achieves high-quality results with dense multi-view inputs, its performance degrades significantly under sparse-view conditions, manifesting as artifacts and incomplete reconstructions. Prior works have attempted to mitigate these issues using regularization strategies or by leveraging generative priors, particularly diffusion models. However, these approaches often suffer from multi-view inconsistency and require labor-intensive training or fine-tuning of diffusion models. FixingGS proposes a training-free score distillation mechanism that fully exploits pre-trained diffusion models, providing more reliable and consistent guidance for 3DGS optimization.
Analysis of Previous Methods
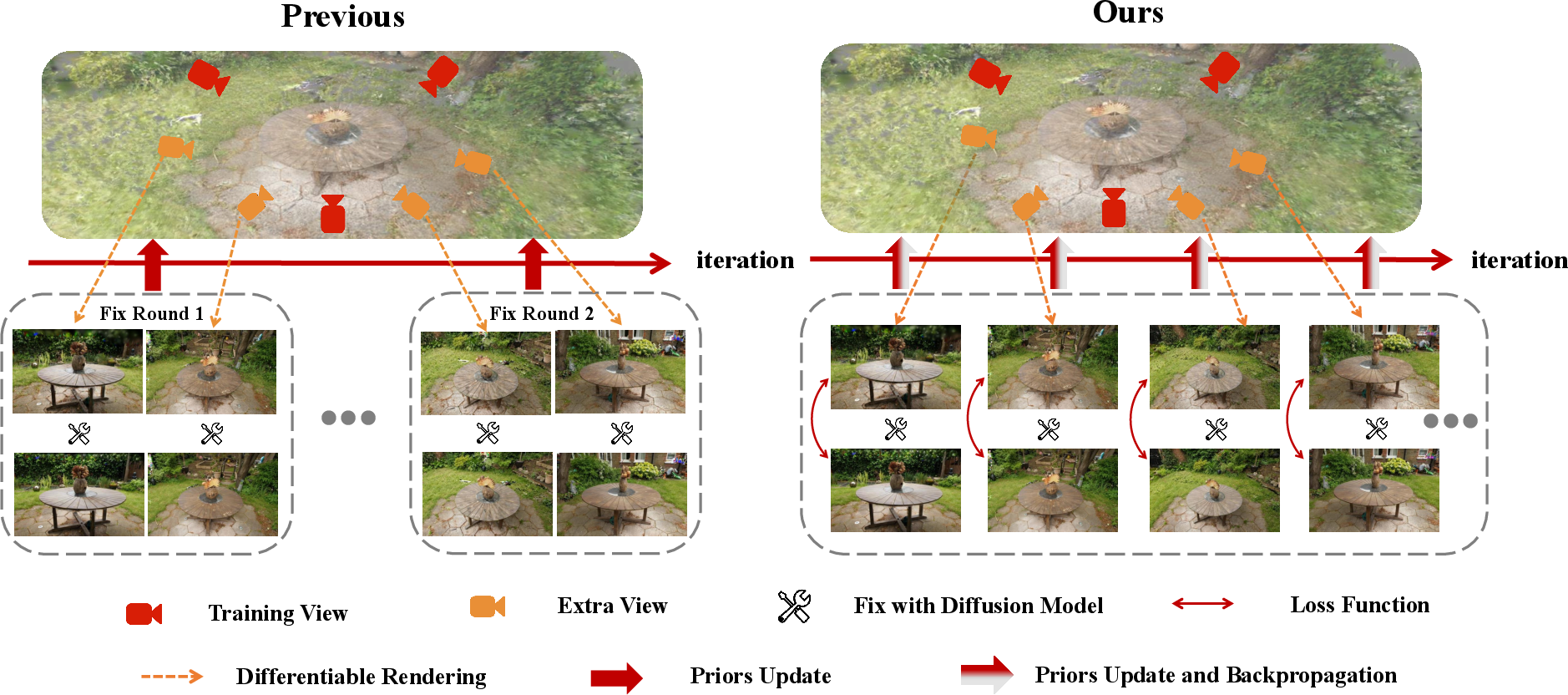
Existing 3DGS enhancement methods with diffusion priors typically update diffusion-generated pseudo ground truths at fixed intervals, using them as supervision for ongoing optimization. This protocol introduces lagged and potentially misleading priors, especially in under-constrained regions, resulting in multi-view inconsistency and ambiguous reconstructions. The schematic comparison in (Figure 1) illustrates this issue: previous methods maintain static priors between update rounds, whereas FixingGS dynamically distills priors throughout the optimization process.
Figure 1: Schematic diagram contrasting static prior updates in previous methods with dynamic distillation in FixingGS, leading to improved guidance and reconstruction.
Methodology
Training-Free Score Distillation
FixingGS leverages a pre-trained diffusion model (e.g., Difix) without additional training or fine-tuning. The core idea is to continuously distill diffusion priors during 3DGS optimization, enforcing cross-view consistency and enabling effective artifact removal and inpainting. The score distillation loss is formulated as:
where g(θ,c) is the differentiable rendering from 3DGS parameters θ at camera pose c, Dϕ is the diffusion model, and y is the clean reference image. The process is fully differentiable, allowing direct optimization of 3DGS parameters via backpropagation.
Adaptive Progressive Enhancement (APE)
To further address unreliable priors in severely under-constrained regions, FixingGS introduces an adaptive progressive enhancement (APE) strategy. APE identifies unreliable viewpoints based on PSNR thresholds and leverages multiple reference views, applying pose perturbations toward the target viewpoint. This dynamic approach strengthens supervision and improves reconstruction quality, as detailed in the provided algorithm. The main difference between FixingGS and prior methods such as Difix3D+ is illustrated in (Figure 2).
Figure 2: Comparison between Difix3D+ and FixingGS, highlighting continuous distillation and improved cross-view consistency.
Experimental Results
Quantitative and Qualitative Evaluation
FixingGS is evaluated on DL3DV-10K and Mip-NeRF 360 datasets, using PSNR, SSIM, and LPIPS metrics. The method consistently outperforms state-of-the-art baselines, achieving at least 0.7dB and 0.5dB PSNR improvements on DL3DV-10K and Mip-NeRF 360, respectively. Qualitative results demonstrate sharper reconstructions, reduced artifacts, and better preservation of high-frequency structures compared to baselines such as 3DGS, FSGS, GenFusion, and Difix3D+. Representative visual comparisons are shown in (Figure 3) and (Figure 4).
Figure 3: Qualitative comparison on DL3DV-10K, showing superior artifact removal and detail preservation by FixingGS.
Figure 4: Visual comparisons on Mip-NeRF 360, highlighting improved reconstruction fidelity and consistency.
Additional visual results on both datasets further corroborate the advantages of FixingGS (Figure 5, Figure 6).
Figure 5: More visual comparisons on Mip-NeRF 360, demonstrating robustness across diverse scenes.
Figure 6: More visual comparisons on DL3DV-10K, illustrating consistent improvements in challenging scenarios.
Ablation Study
Ablation experiments validate the contributions of both the distillation mechanism and APE. Removing either component results in notable declines in all metrics and increased artifacts, as shown in (Figure 7).
Figure 7: Qualitative ablation results, with red bounding boxes highlighting differences due to component removal.
Implementation Considerations
FixingGS is implemented in PyTorch and trained for 6,000 steps on a single NVIDIA RTX 3090 GPU. The dynamic distillation introduces moderate training-time overhead compared to static prior update methods, but yields substantial improvements in reconstruction quality. The method does not require inference-time enhancement, simplifying deployment. The effectiveness of FixingGS is contingent on the quality of the pre-trained diffusion model; integration with stronger or domain-specific priors is a promising direction for future work.
Theoretical and Practical Implications
FixingGS demonstrates that training-free score distillation from pre-trained diffusion models can substantially improve sparse-view 3DGS reconstruction, overcoming the limitations of static prior updates and multi-view inconsistency. The adaptive progressive enhancement further refines results in under-constrained regions, suggesting that dynamic, reference-rich supervision is critical for high-fidelity novel view synthesis. The approach generalizes across diverse datasets and scene types, indicating broad applicability in VR/AR, robotics, and autonomous driving.
Future Directions
Potential future developments include:
Integration with more advanced or domain-adapted diffusion models to further enhance reconstruction quality.
Optimization of the distillation process for reduced computational overhead.
Extension to other explicit or implicit 3D representations beyond Gaussian Splatting.
Exploration of joint optimization frameworks combining generative priors with geometric constraints.
Conclusion
FixingGS presents a robust, training-free framework for enhancing 3D Gaussian Splatting under sparse-view conditions. By dynamically distilling diffusion priors and adaptively enhancing unreliable viewpoints, the method achieves superior reconstruction fidelity and multi-view consistency compared to existing approaches. The results underscore the value of fully leveraging pre-trained generative models for 3D scene reconstruction, with significant implications for practical deployment and future research in generative 3D vision.