- The paper presents Concept Component Analysis (ConCA) to recover log-posteriors representing latent concepts in LLMs, addressing limitations of SAEs.
- It employs a latent variable model with sparsity priors and regularization techniques like LayerNorm and GroupNorm for stable feature extraction.
- Empirical evaluations show ConCA achieves higher Pearson correlation, lower MSE, and robust performance across diverse tasks.
The paper "Concept Component Analysis: A Principled Approach for Concept Extraction in LLMs" (2601.20420) introduces a novel framework for extracting interpretable concepts from LLMs called Concept Component Analysis (ConCA). The paper addresses the limitations of existing sparse autoencoders (SAEs) and proposes a more theoretically grounded method for concept extraction.
Introduction
The deployment of LLMs in critical applications necessitates mechanistic interpretability and the extraction of human-understandable concepts from LLM representations. Despite empirical successes, sparse autoencoders (SAEs), commonly used for this purpose, suffer from theoretical ambiguities regarding the correspondence between LLM internal representations and human-interpretable concepts. This paper proposes Concept Component Analysis (ConCA), a framework that leverages a latent variable model to approximate LLM representations as a linear mixture of log-posteriors over latent concepts. The aim is to recover these log-posteriors in an unsupervised manner, offering clear advantages over traditional SAE methods.
Theoretical Foundations
The paper establishes a theoretical foundation by introducing a latent variable model where text data generation is governed by discrete latent variables representing human-interpretable concepts. Under certain mild assumptions, it is shown that LLM representations can be expressed as a linear mixture of log-posteriors of these latent concepts. This insight motivates ConCA, which is designed to invert this linear mixture, aiming at recovering the log-posterior of each concept in an unsupervised manner.
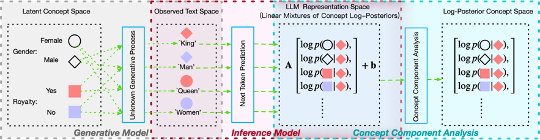
Figure 1: We introduce a latent variable generative model in which observed the input context x and next token y, arises from an unknown underlying process over latent concepts z.
Sparse ConCA: Design and Implementation
Recovering log-posteriors from LLM representations involves solving an ill-posed inverse problem. To address this, ConCA incorporates a sparsity prior, hypothesizing that only a subset of latent concepts are active for each text sample, and regularizes its solution space to mitigate the underdetermined nature of the task. Contrary to SAE methodologies, sparsity is placed on the exponentially transformed space to preserve concept activity levels. Various regularization techniques, such as LayerNorm and GroupNorm, are investigated for their effectiveness in stabilizing training and enhancing feature extraction.
Empirical Evaluation
ConCA is evaluated against SAE variants across multiple LLM architectures. The evaluation criteria include reconstruction loss and Pearson correlation between extracted features and supervised estimates of concept posteriors. Results demonstrate that ConCA outperforms SAEs in capturing and interpreting concept-level representations.
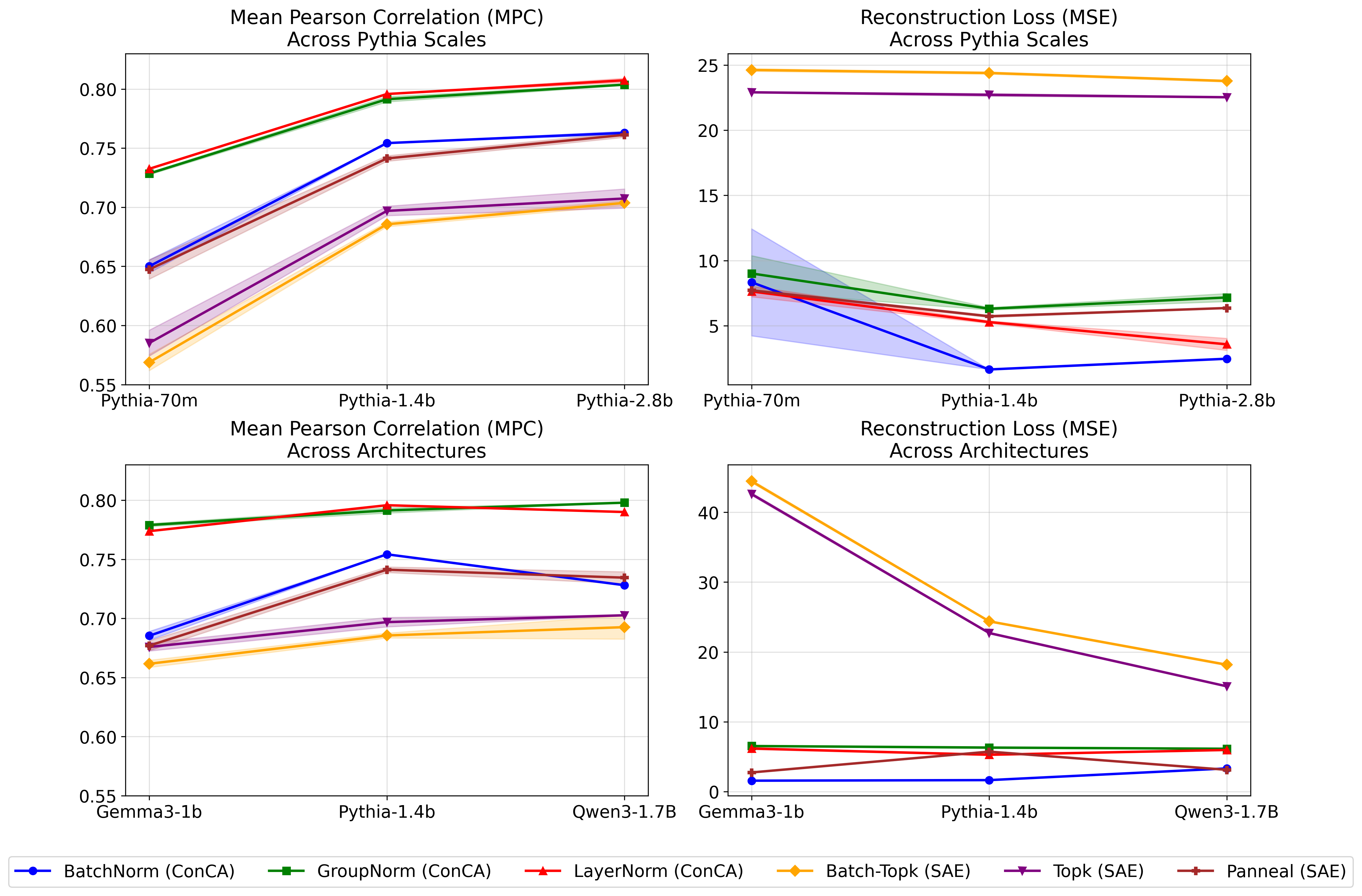
Figure 2: Comparison of SAE variants and the proposed ConCA variant across different scales and architectures. ConCA variants achieve higher Pearson correlation and lower MSE compared to SAE baselines.
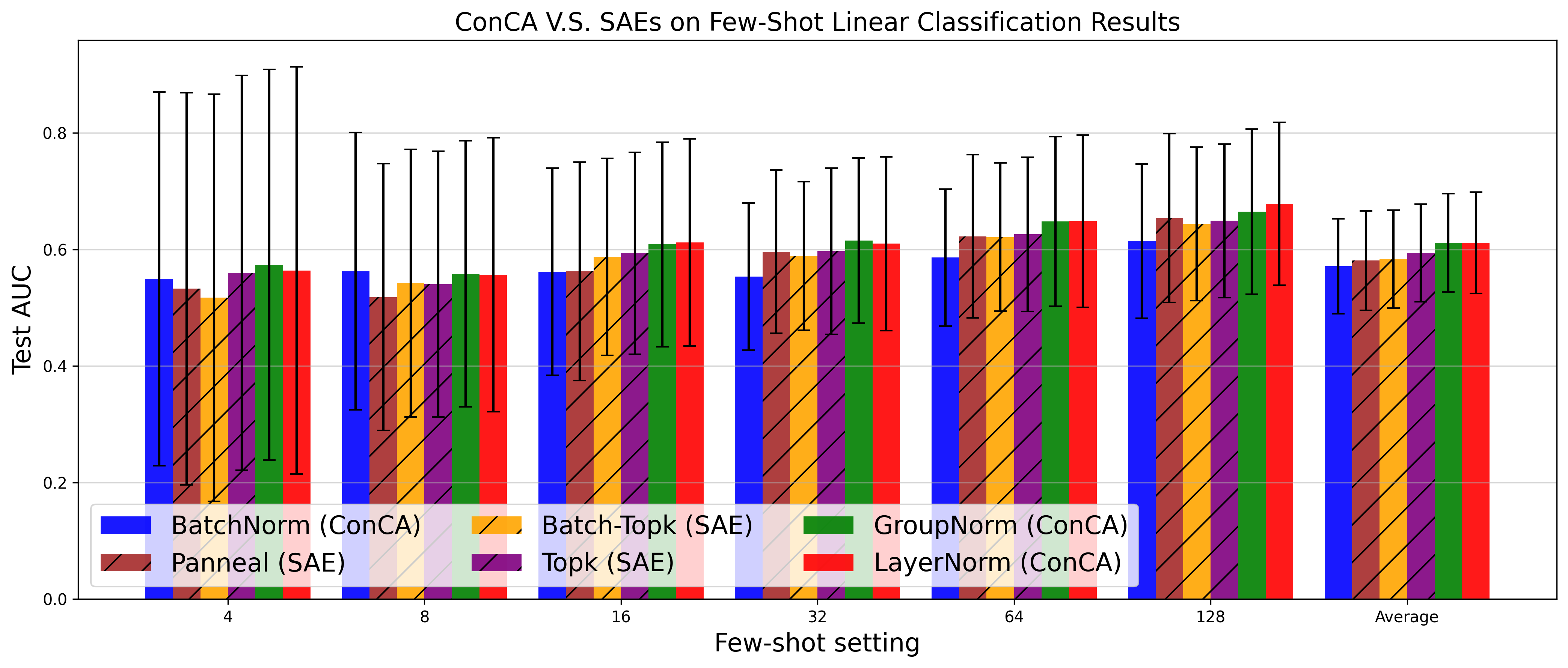
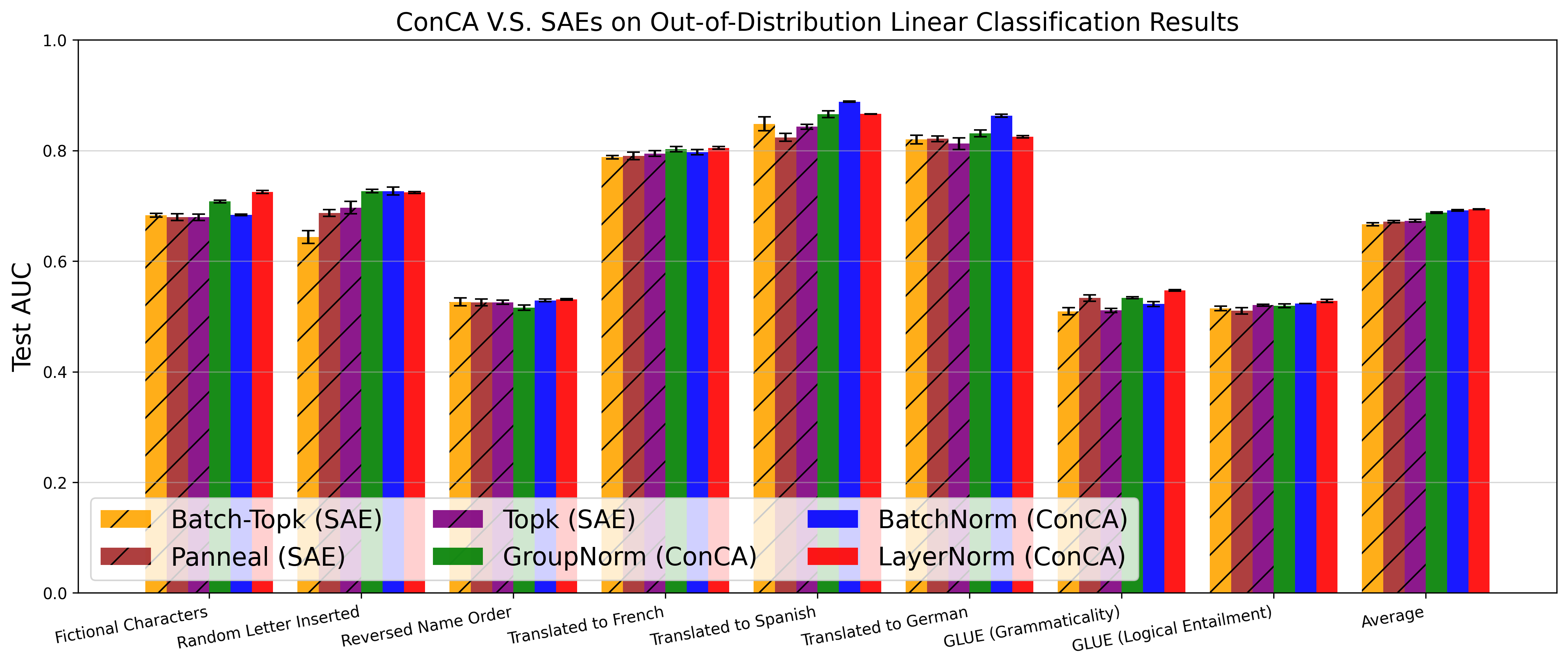
Figure 3: Test AUC of SAE variants and the proposed ConCA variants under different few-shot settings across 113 datasets (Top), and out-of-distribution tasks across 8 datasets (Bottom), respectively.
Discussion and Implications
The implications of ConCA span theoretical and practical dimensions. Theoretically, it offers a principled framework with clear mathematical grounding for interpreting LLM representations. Practically, ConCA provides a robust tool for feature extraction that holds promise in enhancing the interpretability of LLMs, making them more applicable to real-world tasks requiring transparency and accountability.
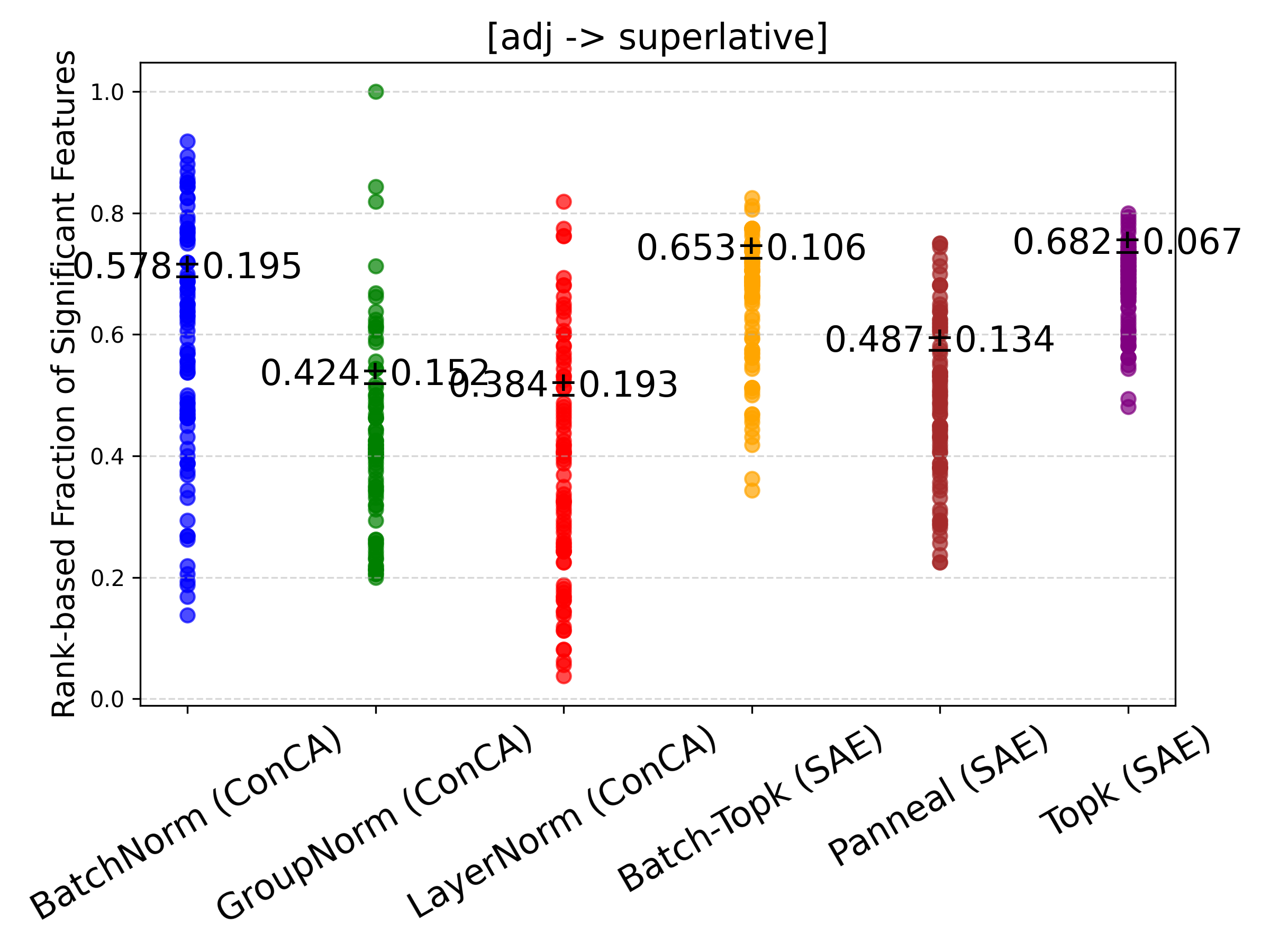
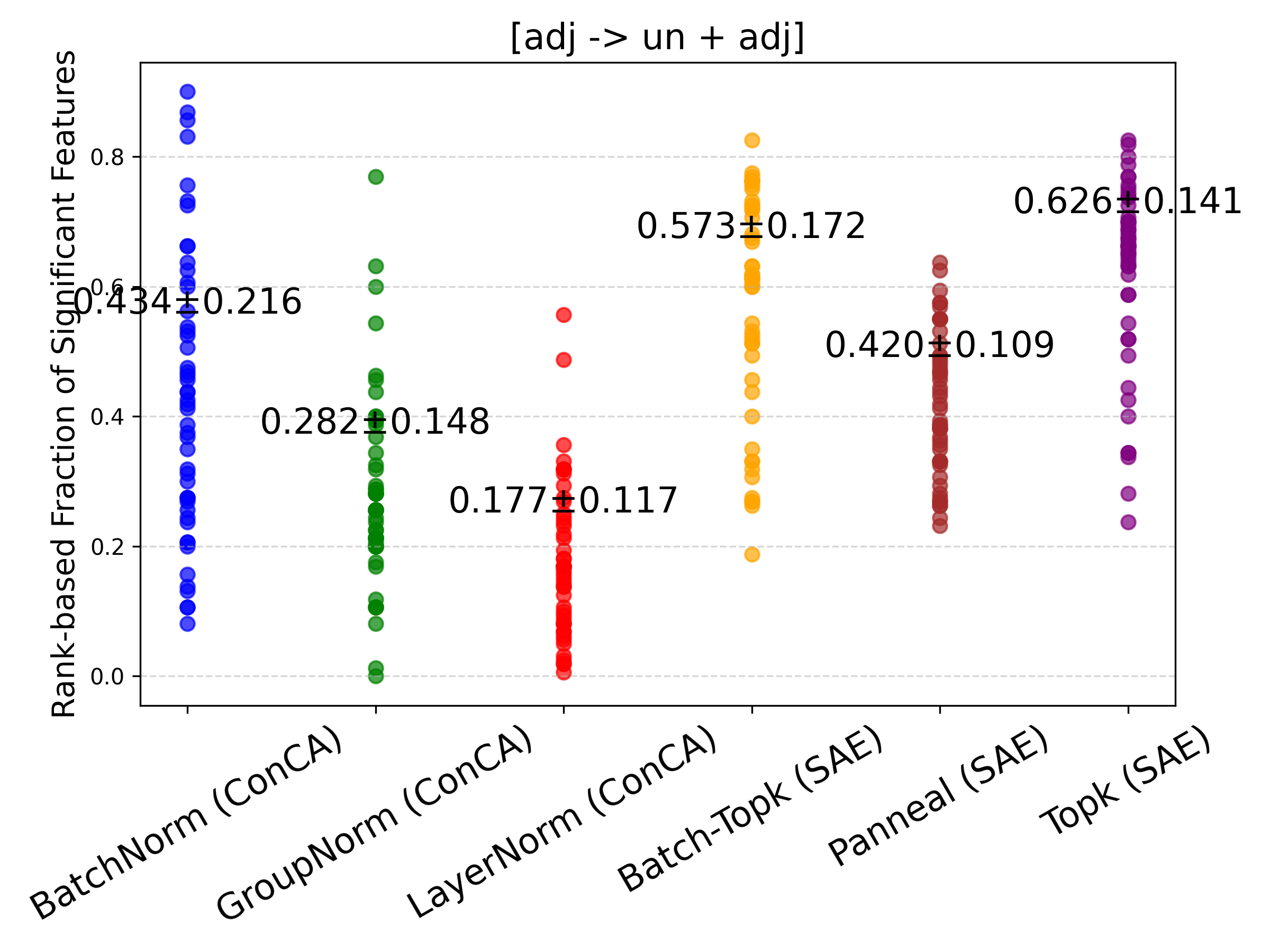
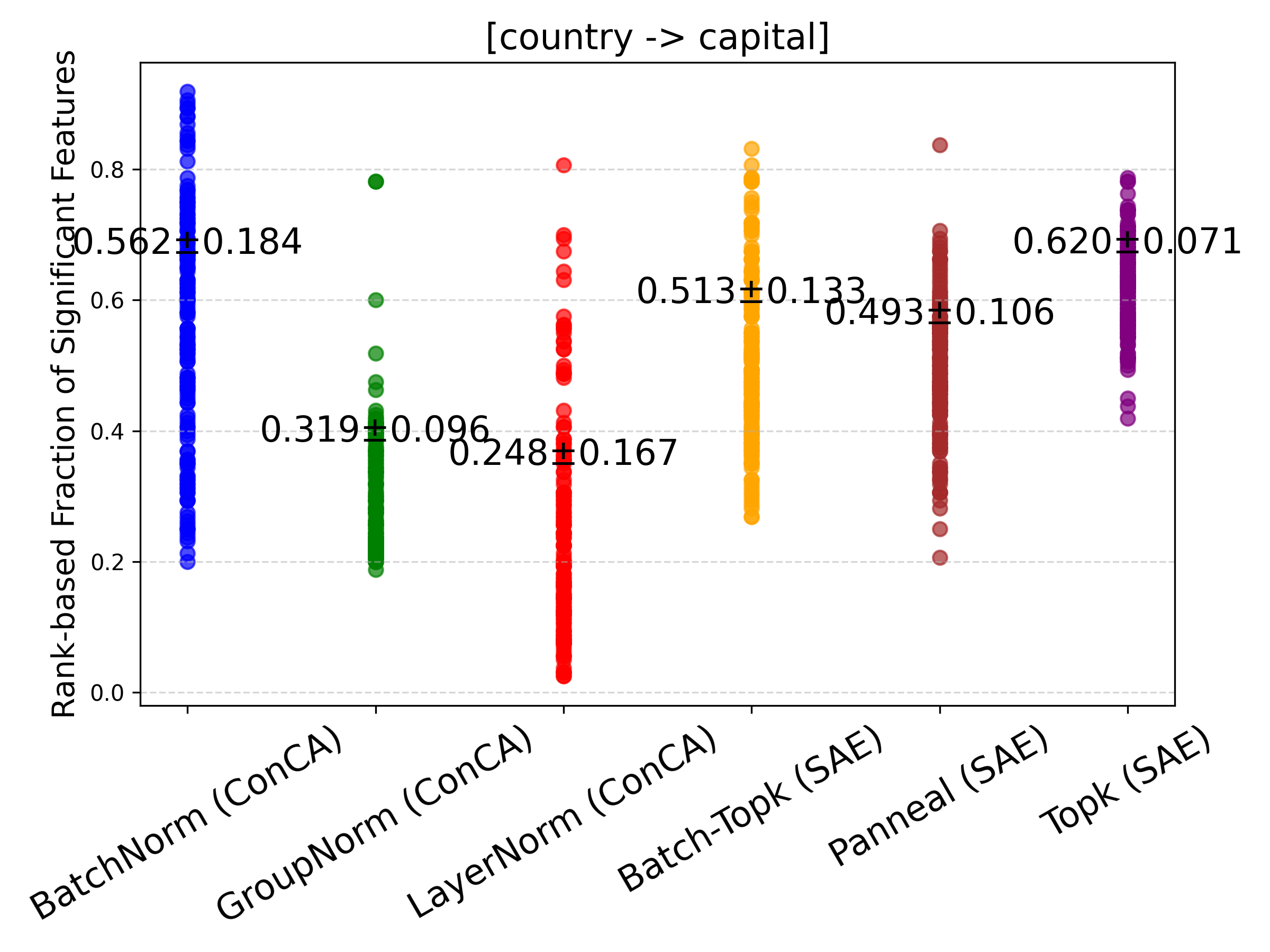
Figure 4: Rank-based fraction of features exhibiting significant changes between counterfactual pairs for SAE and ConCA variants. ConCA shows smaller feature variations, indicating more stable feature responses under counterfactual pairs.
Conclusion
In conclusion, Concept Component Analysis (ConCA) stands as a significant advancement in the field of interpretable AI, providing both a theoretical foundation and an effective empirical approach to concept extraction in LLMs. Future directions could investigate alternative regularization strategies and explore the potential of ConCA in even larger-scale applications.
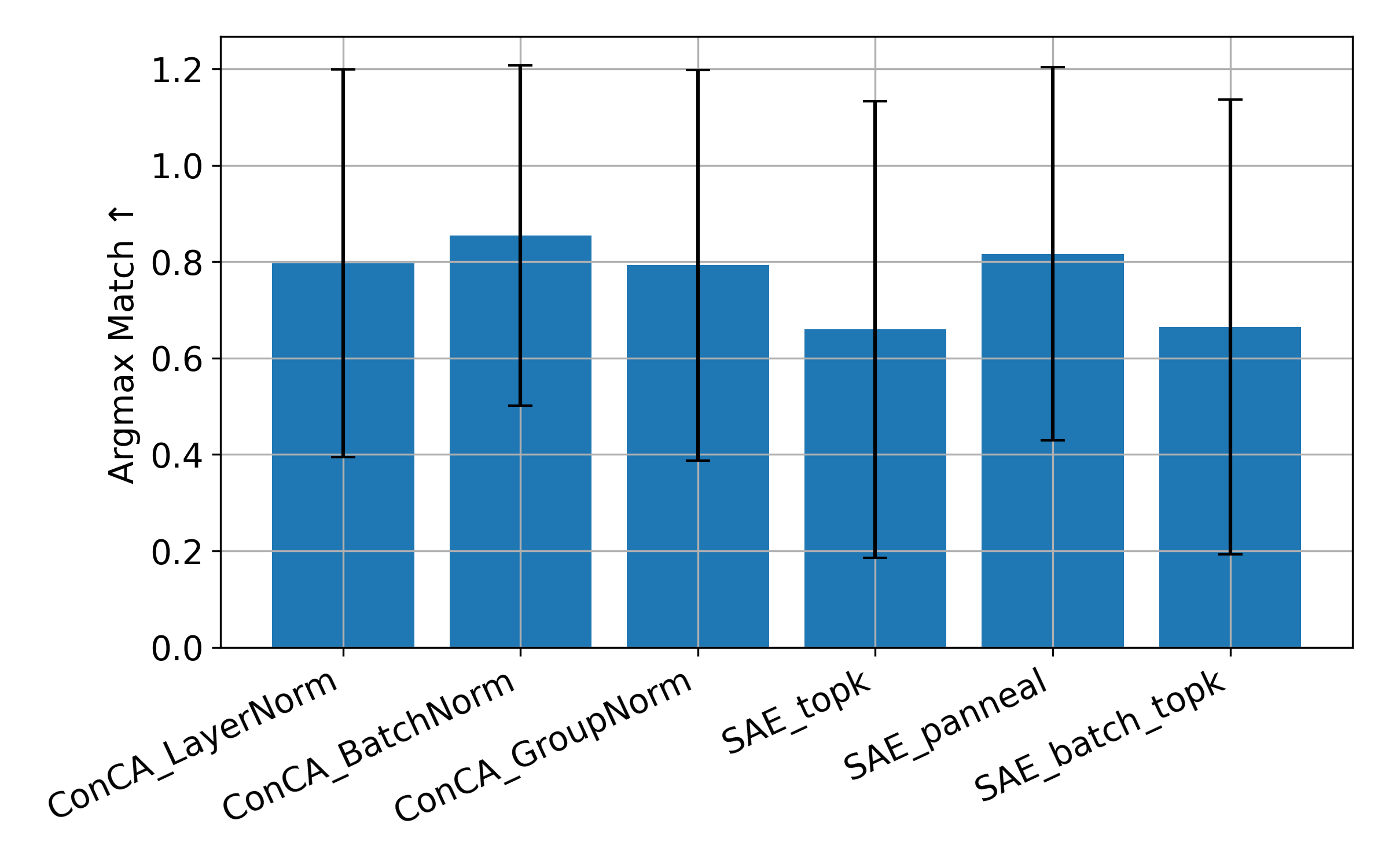
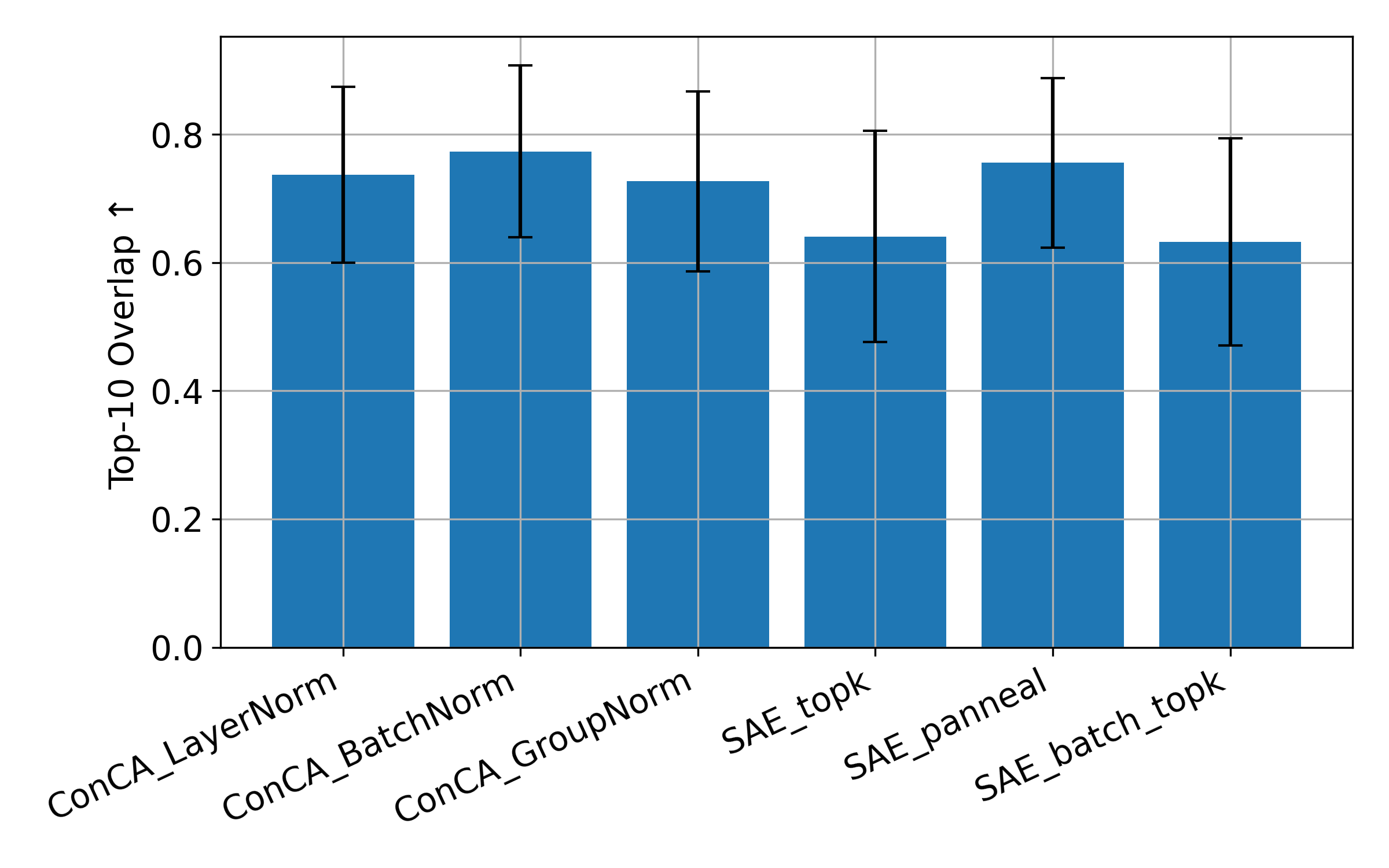
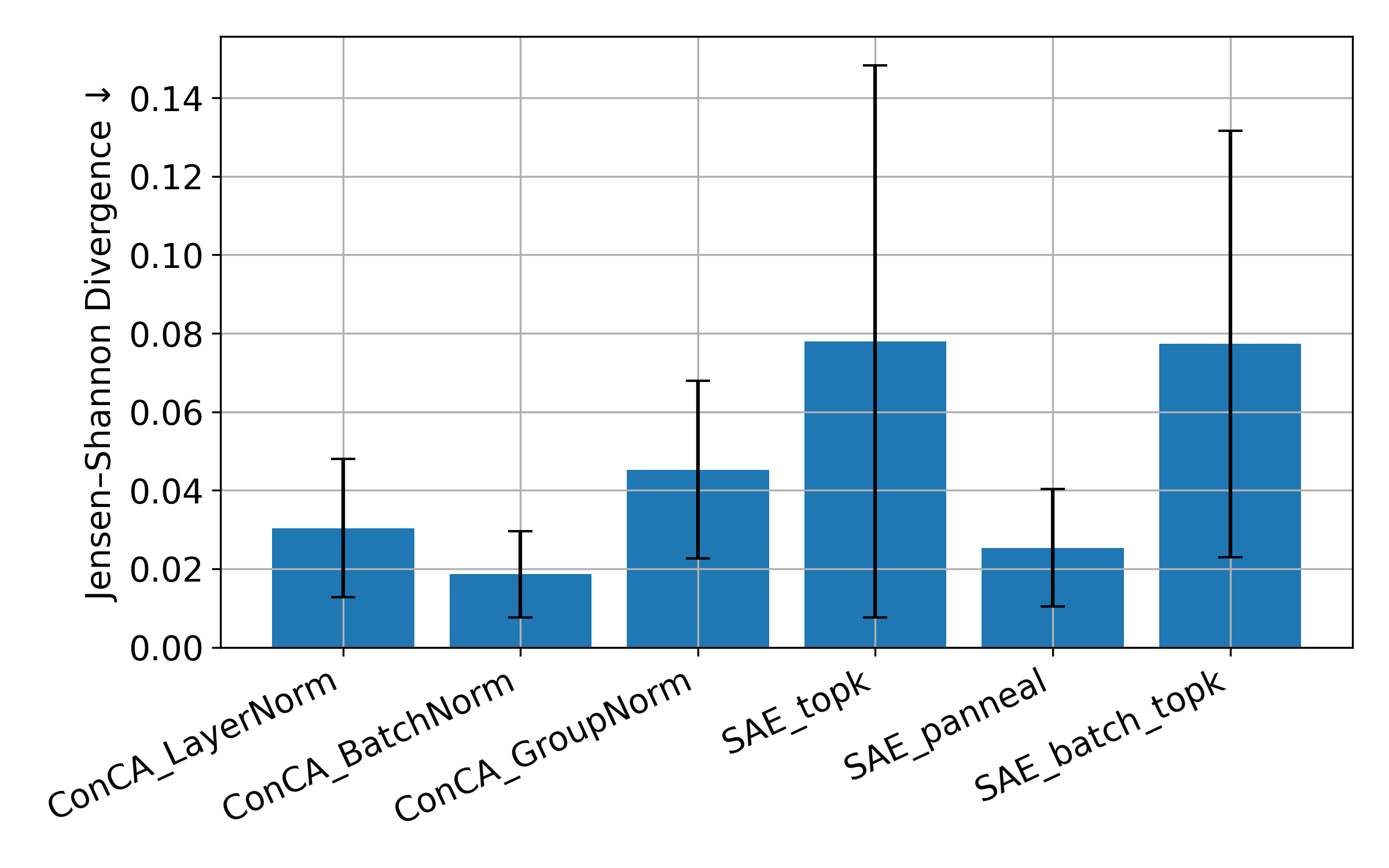
Figure 5: Activation patching comparison across ConCA and SAE variants on Pythia-70M using 10,000 cached hidden activations from The Pile.