- The paper proposes a supervised CASL framework that aligns sparse latent representations with human-understandable semantic concepts.
- It employs a three-stage methodology: sparse autoencoder-based disentanglement, linear mapping for concept alignment, and controlled latent intervention via CASL-Steer.
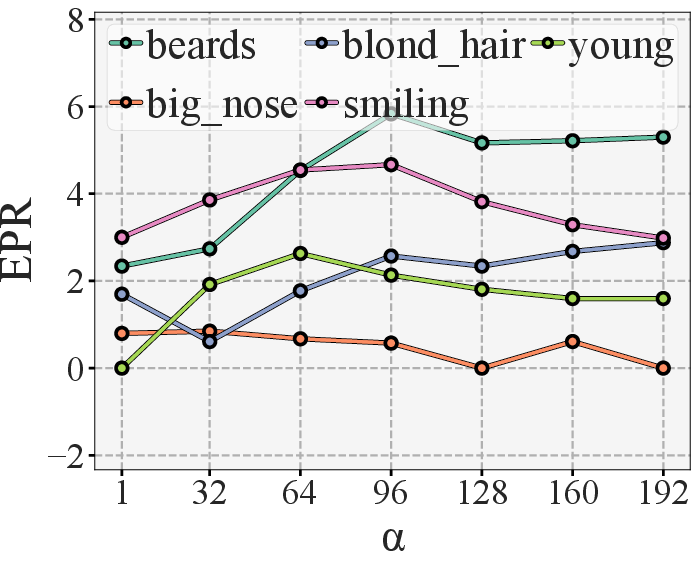
- Empirical results show higher Editing Precision Ratio (EPR), demonstrating improved semantic editing precision and attribute preservation compared to baseline models.
CASL: Concept-Aligned Sparse Latents for Interpreting Diffusion Models
Introduction
The paper "CASL: Concept-Aligned Sparse Latents for Interpreting Diffusion Models" (2601.15441) presents a novel framework, CASL, aiming to enhance the interpretability of semantic representations in diffusion models. Traditional Diffusion Model (DM) methodologies have showcased excellent generative capabilities, encapsulating rich semantic information within their latent space. However, the unsupervised methods typically employed to understand these representations are challenged by their inability to align individual neurons with human-understandable concepts, especially in vision-focused applications. To address these limitations, the authors of this paper propose a supervised technique that facilitates the alignment of sparse latent representations with semantic concepts.
Methodology
The proposed CASL framework is organized into three primary stages:
- Concept Disentanglement: Initially, CASL employs a Sparse Autoencoder (SAE) to disentangle U-Net activations into a structured sparse latent space. This step involves training the SAE to ensure the latent dimensions are interpretable and have reduced entanglement.
- Concept Alignment: Following concept disentanglement, the CASL framework establishes associations between the disentangled latent dimensions and human-defined semantic concepts. A lightweight linear mapping is trained to produce concept-aligned directions. This process is supervised, unlike previous unsupervised approaches, enabling more precise and consistent alignment with human cognition.
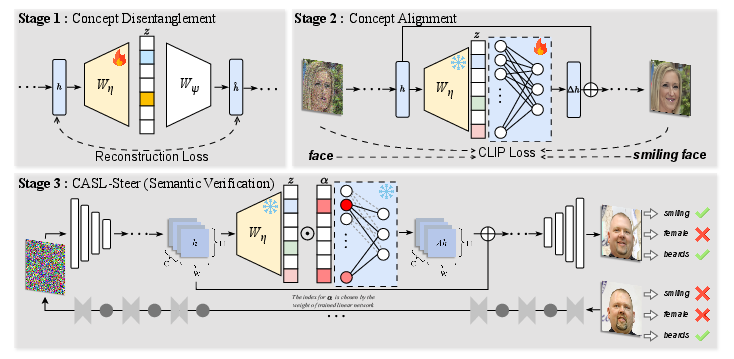
Figure 1: Overview of our proposed CASL framework. Stage 1 (Concept Disentanglement): A Sparse Autoencoder is trained on U-Net activations to obtain a structured sparse latent representation. Stage 2 (Concept Alignment): A lightweight linear mapping aligns selected latent dimensions with human-defined semantic concepts, producing concept-aligned directions. Stage 3 (CASL-Steer): A controlled latent intervention is applied along the aligned direction to verify its semantic effect, serving as a probing mechanism.
- CASL-Steer and Evaluation: CASL introduces CASL-Steer, a controlled intervention mechanism that verifies the semantic influence of concept-aligned latent directions without directly altering the resulting images. This is used as a causal probe to examine the effects of different semantic vectors in DM. The innovation here is the design of the Editing Precision Ratio (EPR), which measures the specificity of the concept influence and the preservation of unrelated attributes.
Results
The empirical evaluation involves several benchmarks and metrics. CASL demonstrates superior semantic editing precision over existing models, as indicated by higher EPR values.
Implications and Future Work
Practically, the CASL framework offers a significant step forward in making DMs more interpretable, facilitating controlled semantic manipulations without the need for extensive model retraining or modifications. Theoretically, it opens avenues for exploring supervised alignment strategies across various generative models, potentially extending to other domains beyond vision, such as audio and text.
Future research could focus on enhancing the scalability of CASL to more complex and multi-modal datasets, improving the granularity of semantic control, and extending the supervised alignment technique to unsupervised settings to reduce reliance on labeled datasets.
Conclusion
In conclusion, the CASL framework offers a robust methodology for aligning latent feature spaces in Diffusion Models with human-readable semantics, thereby enhancing interpretability. This research paves the way for more precise editing and control mechanisms in generative modeling, with substantial implications for both theoretical insights and practical applications in AI.