- The paper introduces a diffusion-based framework that employs multimodal prompts for flexible audio extraction and removal, unifying traditional LASS operations.
- It integrates text and vocal imitation conditioning through a joint latent representation, effectively overcoming ambiguities inherent in language-based queries.
- Empirical results demonstrate superior performance in both extraction (e.g., improved SDRi) and removal metrics compared to mask-based models on diverse benchmarks.
Generative Audio Separation via Multimodal Prompting with PromptSep
Introduction and Motivation
PromptSep addresses critical limitations in language-queried audio source separation (LASS) systems by introducing a diffusion-based framework that supports both extraction and removal operators and multimodal prompting via text and vocal imitation. Traditional LASS models are constrained to single-source extraction via textual queries, frequently hampered by ambiguous or abstract language descriptions and unable to generalize to flexible multi-operator scenarios required in practical workflows, such as targeted sound removal. PromptSep leverages latent diffusion mechanisms and an augmented conditioning pipeline to enable open-vocabulary source separation with a superior query interface.
PromptSep Model Architecture
PromptSep employs a latent diffusion model (DiT) architecture incorporating three conditioning channels: text prompt, vocal imitation, and mixture audio. The input mixture is encoded via a pretrained DAC-style VAE into a 128-dimensional continuous latent sequence at 40 Hz temporal resolution. Text prompts are encoded using FLAN-T5, capturing both succinct keywords and extended descriptions. Vocal imitation signals are processed in the same latent space, enabling seamless integration. Conditioning is effected via in-place additive mechanisms following single-layer MLP projections, aligning all modalities in the time-frequency latent domain.
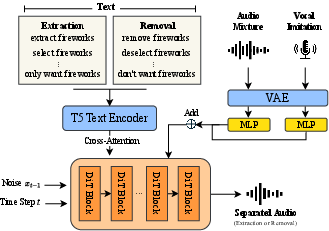
Figure 1: The PromptSep architecture employing joint text and vocal imitation conditioning for flexible source separation and removal across modalities.
Classifier-free guidance (CFG) is implemented via stochastic dropping of conditioning signals during training with calibrated drop rates (10% for text and mixture, 90% for imitation), promoting robust generalization and discouraging overfitting especially on imitation. The v-prediction paradigm and DPM-solver++ inference strategies are adopted to optimize generation fidelity.
Multimodal Prompting: Text and Vocal Imitation
PromptSep extends standard LASS by introducing multimodal query interfaces:
- Text Description: The model supports variable-length text prompts, including user-generated natural language or templated queries synthesized via LLMs (GPT-5), encompassing both extraction and removal operators. Text operators are generalized for mixtures with arbitrarily many sources and synthesized to match real-world phrasing diversity.
- Vocal Imitation: PromptSep enables users to specify target sounds by mimetic vocal samples, exploiting perceptual intuitiveness and bypassing textual ambiguity. The training regimen uses extensive data augmentation, including 87K temporally-aligned effect-imitation pairs generated via Sketch2Sound, combined with real samples from VimSketch and augmented with pitch/time shifts and ambient noise overlays.
The framework supports each condition separately and, at inference, both jointly; however, joint text-imitation conditioning effects are reserved for future work.
Unified Extraction and Removal Operators
Previous architectures restrict separation to extraction, fixing the output to the specific sound source(s) designated in the query. PromptSep generalizes the operational space by supporting removal, generating a residual mixture with specified sound(s) omitted. Conditioning for removal uses negative operators in natural language, with the model trained on synthetically composited mixtures where one or more sources are designated for removal. This unified treatment of extraction and removal via generative modeling offers a more powerful and expressive interface over traditional mask-based models, which often suffer from leakage and consistency issues when handling removal.
Data Simulation and Synthetic Pretraining
To address the lack of large, paired vocal imitation–sound effect datasets, PromptSep leverages the Sketch2Sound model for data generation, producing temporally-aligned acoustic pairs from reference imitations and textual prompt combinations. Synthetic mixing schemes randomly combine $2$–$5$ sources per mixture at a range of SNRs, with careful stratification on target selection. Training is performed exclusively on single-modal conditions, matching real user workflow paradigms.
Evaluation utilizes multiple domain-specific benchmarks, including AudioCaps, ESC50, FSD-Mix, ASFX, and VimSketchGen-Mix, with ASFX providing an out-of-domain measure.
Objective and Subjective Results
PromptSep achieves competitive and superior performance on extraction and removal metrics across all datasets:
- Extraction: On the challenging out-of-domain ASFX set, PromptSep demonstrates top scores in SDRi ($5.65$), F1 Decision Error ($0.60$), CLAPScoreA ($0.66$), and FAD ($3.19$), exceeding all baselines except for a marginal deficit in raw CLAPScore.
- Removal: In removal operations, PromptSep consistently outperforms baselines, e.g., F1 ($0.75$), FAD ($3.81$) on ASFX, while negative operator prompting yields higher decision localization and audio quality than mask-based baseline proxies.
- Vocal Imitation: Imitation-based conditioning markedly outperforms pitch and RMS-only approaches, with key metrics such as SDRi ($9.99$ vs. $7.17$), F1 ($0.95$ vs. $0.84$), and lower FAD, indicating that raw imitation signals encode richer discriminative information for separation in complex mixtures.
Subjective evaluation affirms these findings: mean opinion scores for relevance (REL) and overall quality (OVL) demonstrate clear preference for PromptSep over mixture and baseline separated outputs, with REL/OVL approaching ground truth boundaries, especially in removal scenarios.
Implementation and Deployment Considerations
PromptSep’s architecture is conducive to scalable training and real-time inference given the VAE-based latent compression and transformer-based generation step, with moderate GPU requirements for model deployment at 44.1 kHz sample rate and 10-second input mixing horizon. The system’s multimodal interface is compatible with both text-based and audio-based UX paradigms, supporting integration into content creation, interactive sound design, and audio post-processing environments.
Data simulation strategies and augmentation pipelines are critical for building robust generalization. Future work should explore joint text-imitation conditioning, active learning for operator template synthesis, and increased temporal context windows.
Implications and Future Directions
PromptSep signals a transition from masked separation toward unified, generative approaches facilitating flexible user-intent specification and high-fidelity output. The framework's sensitivity to multimodal cues—especially vocal imitation—suggests substantial potential for interactive audio manipulation, content-indexed audio editing, and multimodal retrieval in production settings.
The success of generative removal operators invites further research in zero-shot operation synthesis and cross-modal transfer learning, with possible generalization to video-driven and graph-based sound separation scenarios. Integration with retrieval-augmented generation and multimodal foundation models may expand the expressive capability of controllable audio source separation.
Conclusion
PromptSep establishes a robust paradigm for generative audio source separation, supporting both extraction and removal within a multimodal prompting framework. The demonstrated empirical advantages and architectural flexibility mark a significant advance in the LASS field, especially for user-facing applications. The modular conditioning scheme and extensible operator space provide a promising foundation for future multimodal separative models and broadened audio manipulation capabilities.