- The paper introduces a novel tensor layout abstraction that integrates sharding (D), replication (R), and offsets (O) into a unified algebraic model for ML compilers.
- It demonstrates effective DSL support for explicit multi-granularity control, achieving throughput near cuBLAS benchmarks on GPUs and competitive performance on AWS Trainium.
- The work paves the way for scalable, cross-hardware kernel generation by simplifying the mapping of logical indices to diverse accelerator architectures.
Axe: A Unified Layout Abstraction for Machine Learning Compilers
Introduction and Motivation
The rapid evolution of deep learning—especially at the scale of LLMs and MoE architectures—demands system-level adaptability spanning device meshes, memory hierarchies, and increasingly heterogeneous hardware. Existing compiler infrastructure and DSLs offer fragmented solutions, often specialized for single domains (device-level tiling, distributed sharding, on-chip memory organization), with limited interoperability and non-uniform semantics. "Axe: A Simple Unified Layout Abstraction for Machine Learning Compilers" (2601.19092) introduces Axe Layout, a hardware-aware tensor layout abstraction that unifies mapping of logical tensor coordinates to physical hardware axes, providing an algebraic model compatible with GPU warps, memory banks, device-level sharding, and accelerator-specific features.
Axe Layout Abstraction
Axe Layout extends traditional shape-stride representations (e.g., NumPy/PyTorch) to a triple decomposition: D (shard), R (replica), and O (offset). Each implements explicit mapping between logical indices and multi-axis hardware coordinates. This generalization allows unify representations for sharding, tiling, replication, and offsets, across distributed and on-device contexts.
- D (Shard): Ordered list of iterators parameterized by extent, stride, and axis. Supports arbitrary factorization and assignment to axes including lanes, warps, memory, registers, and distributed device identifiers.
- R (Replica): Multiset of replication iterators, used to enumerate offsets in hardware space. Defines broadcasting and replication semantics orthogonal to logical indexing.
- O (Offset): Global per-axis offset vector, supporting localized data placement or resource reservation.
This can be formalized as a set-valued mapping L(x)={D(x)+r+O∣r∈R}, subsuming traditional dense, strided, and sharded layouts and enabling algebraic treatment of distributed and hierarchical tensor placement.
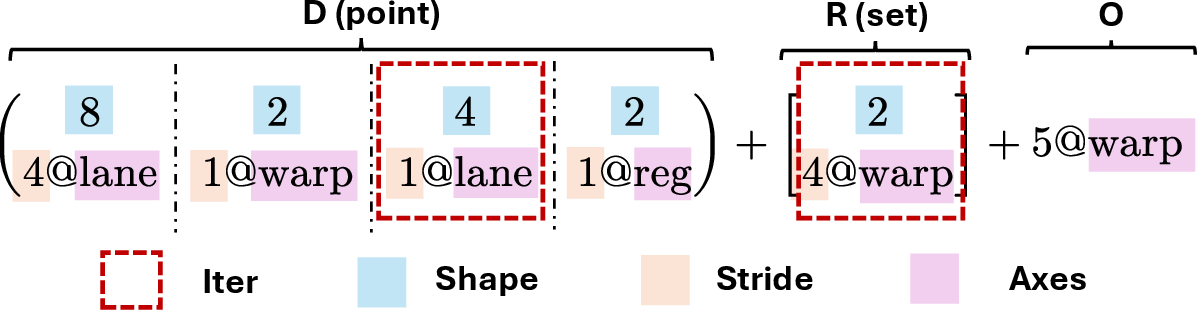
Figure 1: Elements of Axe Layout illustrating the mapping of logical indices via tuple decomposition into shard, replica, and offset.
Axe Layout allows precise, composable mapping of tensors across diverse hardware resources, supporting scenarios such as multi-warp partitioning, device-mesh sharding (2D mesh with shards/replicas), and native memory constructs (e.g., AI accelerator scratchpads, NVIDIA Blackwell tensor memory).
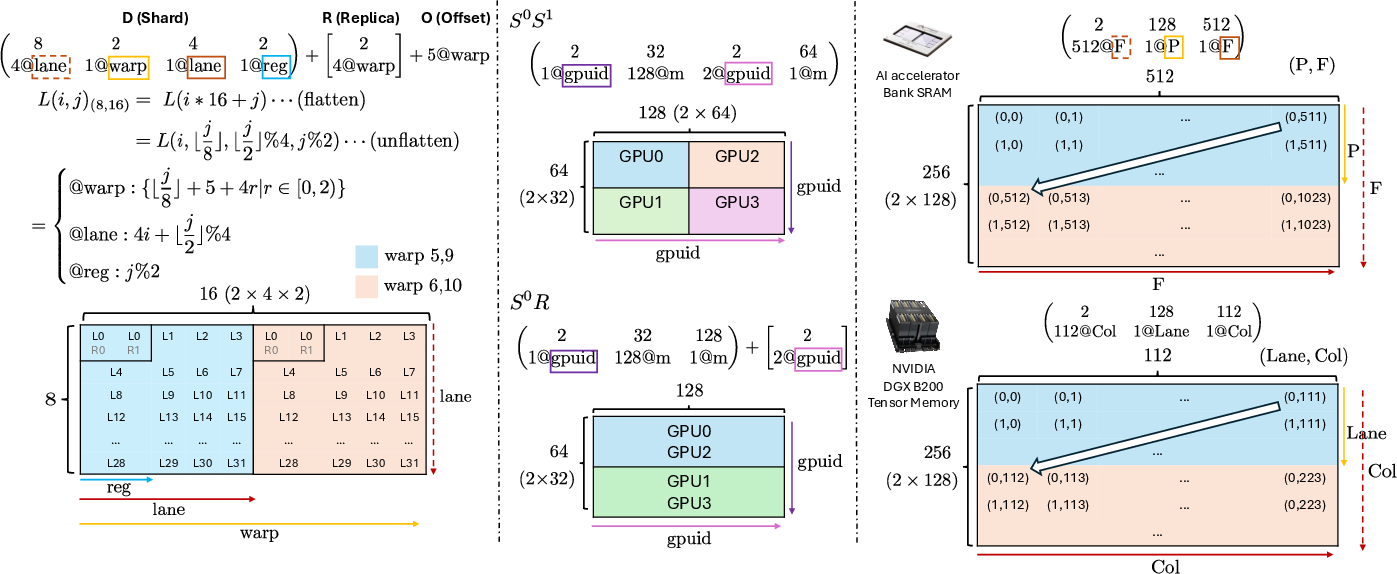
Figure 2: Examples of Axe layouts showcasing mapping of logical tensors to warps/registers, 2D device meshes, and hardware-specific memories.
Axe Compiler and Programming Model
Building on Axe Layout, the Axe compiler introduces a multi-granularity, distribution-aware DSL enabling both thread-local control and fine-grained collectives. Unlike existing systems (CuTeDSL, Triton), which fix control at thread- or block-level, Axe's abstraction natively embeds scope hierarchy (kernel, CTA, warpgroup, warp, thread). The DSL supports explicit specification of execution scopes, kernel-level composability, and scope slicing—essential for cross-hardware pipelines where specific warps handle specialized roles (e.g., load, GEMM, write-back).
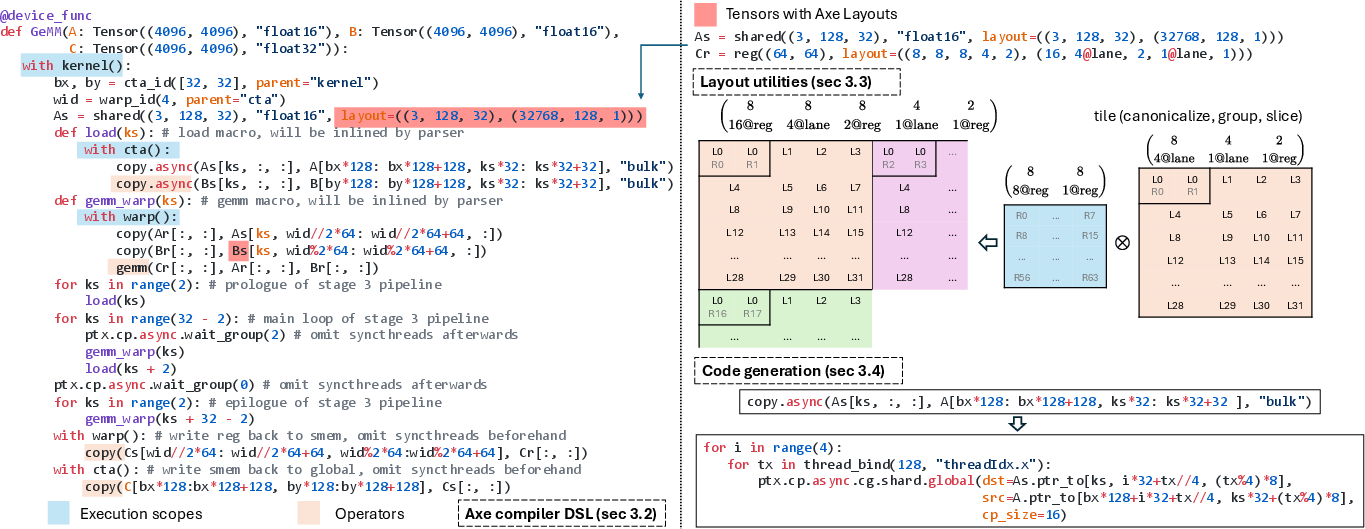
Figure 3: Axe compiler overview—highlighting DSL semantics, scope-driven tensor handling, and operator lowering via layout analysis.

Figure 4: Axe DSL snippet demonstrating explicit thread-level partitioning and binding.
Operators (copy, reduction, GEMM, pointwise, etc.) accept layout-driven configuration and schedule selection, abstracting away hardware-specific routines (LDG/STG, cp.async, all-gather) and delegating efficient code generation to the compiler via layout analysis.

Figure 5: Axe DSL with thread-block collective semantics for block-defined operators.
Axe formalizes layout canonicalization, grouping, tiling (via Kronecker products and axis-wise scaling), and slicing—essential for matching hardware constraints (SIMD/tensorized instructions) and region-specific code generation.
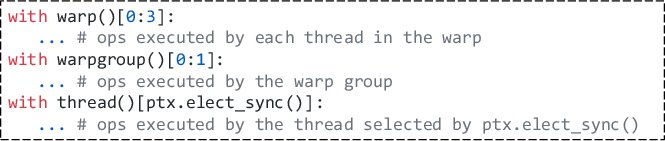
Figure 6: DSL scope slice API supporting hierarchical partitions of execution resources.
Layout operators (canonicalize, tile, slice) provide semantic equivalence checks, enable schedule matching, and facilitate decomposition of distributed tensor operations for code generation and cross-hierarchy lowering.

Figure 7: Python API for construction and manipulation of Axe Layout objects.

Figure 8: Distributed tensor signature for reduce-scatter, illustrating inter-device sharding representation in Axe.
Operator invocation leverages the explicit mapping and schedule configurations, facilitating asynchronous codegen (TMA copy), fine-grained pipelining, and hardware-native instruction selection without manual implementation.

Figure 9: Operator invocation with schedule configuration arguments, yielding fine-tuned compiler dispatch.
Experimental Evaluation
Axe's compiler is evaluated on NVIDIA B200 for FP16 and FP8 GEMM kernels. Across Qwen3, LLaMA-3.1, Gemma-2, and GPT-3 shapes, Axe attains at least 97% of cuBLAS throughput, matching or exceeding Triton's performance (which drops to 87% on adversarial shapes). FP8 blockwise GEMM matches DeepGEMM near 94% across tested configurations.
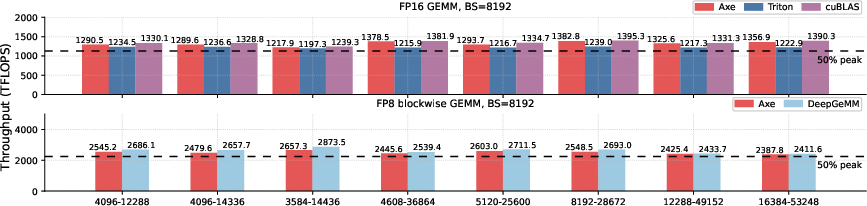
Figure 10: FP16 and FP8 GEMM throughput across weight shapes and batch size 8192 for B200—Axe performance adheres closely to device peak.
MoE Layer Latency
On fused FP16 MoE layers (Qwen3-30B), Axe demonstrates significant latency reduction—up to 1.36× over FlashInfer and 1.23× versus SGLang. These gains are attributed to fine-grained pipelines across group GEMMs enabled by layout-driven operator configuration.

Figure 11: Qwen3-30B MoE layer latency as a function of input token count; Axe achieves superior latency.
Axe's distributed tensor composition and sum operator dispatch yield optimal latency for GEMM + Reduce-Scatter workloads, reaching up to 1.40× speedup over Triton-distributed and cuBLAS+NCCL. This is enabled by single-kernel overlap of computation and communication, maximizing both bandwidth and Tensor Core utilization.

Figure 12: FP16 GEMM + Reduce-Scatter latency across multi-device setups and weight shapes; Axe delivers lowest latency.
Heterogeneous Backend Support
On AWS Trainium 1, Axe's FP16 GEMM kernel matches handcrafted NKI library performance, while Multi-head Attention exceeds vendor DSL throughput by 1.44× (max) and 1.26× (mean)—while reducing schedule and address calculation boilerplate substantially.
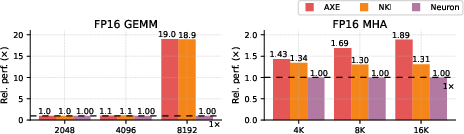
Figure 13: FP16 GEMM and Multi-head Attention test results on Trainium 1—Axe matches or beats native vendor libraries.
Axe Layout directly generalizes CuTe's integer-module shape-stride arithmetic via named axes, introducing R and O for set-valued mappings absent in single-valued predecessors. It diverges from linear (bit-linear) layouts in robustness to non-power-of-two shape decomposition (critical for modern architectures and distributed settings). Axe is tightly interwoven with advances in ML compilers and DSLs—building atop schedule/algorithm separation (Halide, TVM) and extending the abstraction to distributed device meshes (Mesh TensorFlow, GSPMD, Alpa, FlexFlow). Its layout algebra and canonicalization algorithms provide unique normal forms, significantly aiding compiler codegen and operator lowering.
Implications and Future Directions
Axe establishes a foundation for unifying tensor layout semantics across intra-GPU, inter-GPU, and AI accelerator hardware. By composing data and compute mappings via named axes, it removes artificial barriers between tiling, sharding, and distribution, promoting algebraic manipulation and automatic schedule selection. Practically, this enables rapid implementation of high-performance kernels on heterogeneous backends, with substantial reductions in development and tuning overhead. Theoretically, Axe paves the way for universal, layout-driven operator libraries and ML compiler infrastructure, facilitating seamless migration across hardware generations and deployment environments. Future research may extend Axe to more granular hardware primitives (local caches, cross-chip fabrics), integrate with automated schedule search, and enable dynamic runtime adaptation based on execution profiling.
Conclusion
Axe delivers a simple yet comprehensive layout abstraction for machine learning compilers, integrating logical tensor mapping with named hardware axes via shard, replica, and offset constructs. Its multi-granularity DSL and layout algebra support both high productivity and performance, unlocking efficient kernel codegen for modern and emerging accelerator platforms. Axe's evaluation demonstrates strong numerical results—matching and in several cases surpassing highly tuned vendor libraries—while simplifying kernel development and increasing portability. Its formalization and composability offer a robust substrate for continued evolution of ML systems at hardware-software boundaries.

