Confidence-based Filtering for Speech Dataset Curation with Generative Speech Enhancement Using Discrete Tokens
Abstract: Generative speech enhancement (GSE) models show great promise in producing high-quality clean speech from noisy inputs, enabling applications such as curating noisy text-to-speech (TTS) datasets into high-quality ones. However, GSE models are prone to hallucination errors, such as phoneme omissions and speaker inconsistency, which conventional error filtering based on non-intrusive speech quality metrics often fails to detect. To address this issue, we propose a non-intrusive method for filtering hallucination errors from discrete token-based GSE models. Our method leverages the log-probabilities of generated tokens as confidence scores to detect potential errors. Experimental results show that the confidence scores strongly correlate with a suite of intrusive SE metrics, and that our method effectively identifies hallucination errors missed by conventional filtering methods. Furthermore, we demonstrate the practical utility of our method: curating an in-the-wild TTS dataset with our confidence-based filtering improves the performance of subsequently trained TTS models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making messy, real-world speech recordings cleaner and more useful for building text-to-speech (TTS) systems. The authors use a special kind of model called a generative speech enhancement (GSE) model to turn noisy speech into clean speech. But these models sometimes “hallucinate” — they make audio that sounds clean but has mistakes in what’s being said, or even sounds like the wrong person. The paper introduces a simple way to spot and filter out these mistakes using the model’s own “confidence” in what it generated.
What questions did the researchers ask?
- Can we use the GSE model’s own confidence scores to detect when it made errors, even if the audio sounds clean?
- Do these confidence scores match (correlate with) trusted “intrusive” quality checks that usually require a clean reference (which we don’t have for real-world data)?
- If we filter our dataset using these confidence scores, will the TTS systems we train afterward perform better?
How did they do it?
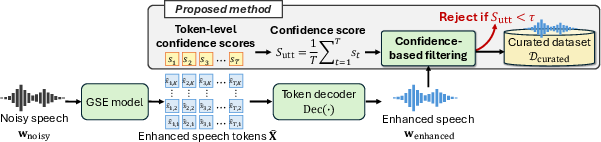
Generative speech enhancement, in simple terms
Imagine you have a noisy voice recording from the internet. A GSE model tries to “re-draw” that speech in a cleaner form. Instead of drawing a continuous waveform directly, the model builds the speech from a sequence of small pieces called “tokens” — like rebuilding a picture with LEGO bricks. These tokens are produced by an audio codec (a tool that compresses audio) called DAC, which uses multiple layers (called “quantizers”) to capture coarse-to-fine details. The first layer captures the most important parts of the sound; later layers add finer detail.
What is a “confidence score” here?
Every time the model chooses a token, it also knows how “sure” it was about that choice. This “sure-ness” is a probability. The authors turn these probabilities into a number called a log-probability (you can think of it like a score that gets higher when the model is more certain).
Here’s the key idea:
- For each moment in the audio, the model picks a token in the first (most important) layer and records how confident it was.
- They average these confidence scores over the whole utterance (the entire clip) to get one number for the clip: the “utterance-level confidence score.”
If this score is high, the model thinks it did a good job. If it’s low, the model probably struggled — which often means the cleaned audio may contain errors like missing sounds (phonemes), random nonsense sounds, or sounding like the wrong speaker.
Curation pipeline (cleaning the dataset)
The authors use a two-step process:
- Enhance the noisy speech using the GSE model (Genhancer).
- Filter out clips with low confidence scores (keep only those above a chosen threshold).
This way, they build a cleaner, higher-quality dataset to train TTS systems.
What did they find?
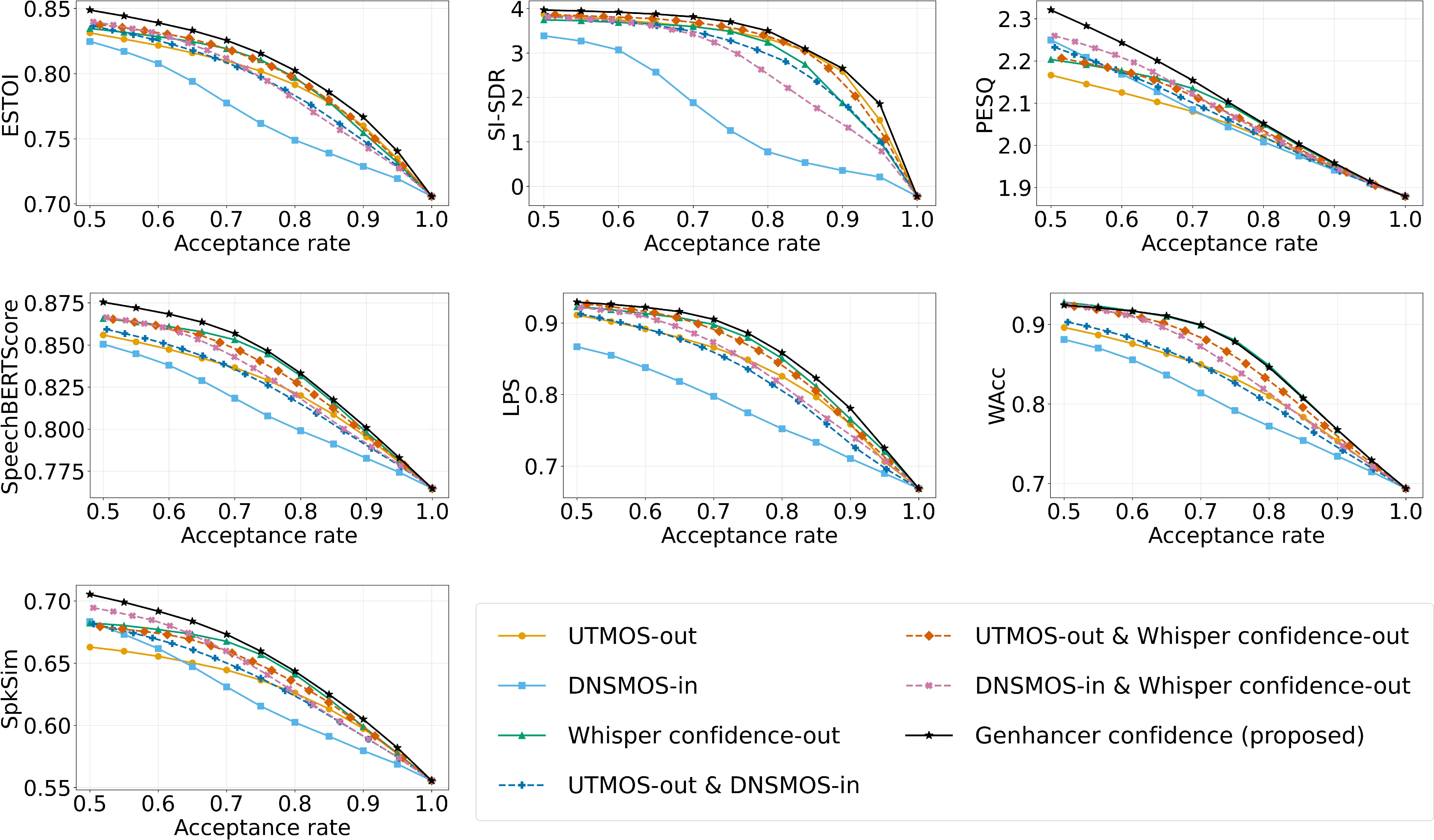
- Strong correlation with trusted metrics: Their confidence score matched very well with several “intrusive” quality metrics (like PESQ, ESTOI, and newer ones that detect content errors), even though their method didn’t need a clean reference. In other words, when intrusive checks said the audio was good, the confidence score tended to be high too.
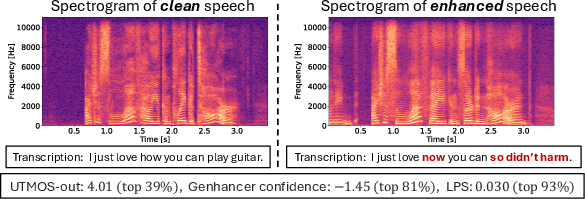
- Catches “hallucination” errors that others miss: Some popular non-intrusive metrics (like DNSMOS or UTMOS) can say audio “sounds nice” even if the content is wrong. The authors show cases where those metrics rated audio highly despite clear content errors, but their confidence score flagged it as risky.
- Better TTS results after filtering: They trained TTS models on datasets filtered by confidence scores. The TTS systems performed better — speech sounded more natural, overall quality improved, and word error rates from recognition were lower — when they kept only the top 70–80% of clips by confidence. Too much filtering (e.g., keeping only 50–60%) hurt performance because you lose too much data. This shows a clear trade-off: quality improves as you filter, but you still need enough data to train well.
- Consistent advantage across acceptance rates: When they varied how strict the filtering was, the confidence-based method generally beat other filtering approaches (including combinations of popular metrics) on most evaluation measures.
Why does it matter?
- Cleaner training data, better voice models: TTS systems get better when trained on high-quality, reliable speech. Filtering with confidence scores removes tricky, subtle errors that can poison training, leading to clearer, more accurate synthetic voices.
- Works “in the wild”: In real-life internet data, you don’t have clean versions to compare against. This method doesn’t need a reference — it uses the model’s own confidence — making it practical for large, messy datasets.
- Simple and effective: The confidence score is easy to compute and strongly tied to whether the enhancement likely worked. It’s a handy tool for screening huge datasets quickly.
- Future directions: This paper focuses on models that use discrete tokens. Next steps include adapting the idea for models that work with continuous features (a different way of representing audio), so the approach can cover more types of enhancement systems.
In short, the paper shows a smart, straightforward way to clean up real-world speech datasets by trusting the enhancement model’s own “gut feeling.” This makes TTS training data better and helps create more natural, accurate voices.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research:
- Generalization beyond discrete-token GSE: the method is limited to RVQ/DAC-based codecs and a single model (Genhancer); extension to continuous-latent GSE (diffusion/flow) remains untested and unspecified.
- Confidence definition choices: only the first quantizer’s token log-probabilities are used; no ablation on using other quantizers, weighted combinations across codebooks, entropy measures, or alternative aggregations (e.g., min/percentiles).
- Calibration of confidence scores: the influence of inference temperature, model calibration, and probability scaling on comparability across utterances, speakers, and domains is not analyzed; temperature scaling or calibration methods are not explored.
- Length, silence, and segmentation effects: averaging log-probabilities over time () may bias scores for long utterances or silent regions; voice activity detection (VAD)-aware or segment-level confidence is not examined.
- Threshold selection: filtering uses “top N%” heuristics; no principled thresholding (e.g., validation-based calibration, Bayesian risk minimization, mixture-model fitting on confidence distributions) is provided for new datasets.
- Error taxonomy and detection fidelity: hallucination errors (phoneme omissions, speaker inconsistency, nonsensical insertions) are not systematically labeled; precision/recall, ROC/AUC, and per-error-type detection rates are missing.
- Human validation: correlation with intrusive metrics is demonstrated on simulated EARS-WHAM, but no human listening tests on in-the-wild data validate that low confidence aligns with perceived GSE-specific errors.
- Domain and language robustness: evaluation is largely English and VoxCeleb/TITW-centric; performance across other languages, accents, recording conditions, and sampling rates is unknown.
- Model and feature dependence: confidence is computed from Genhancer with WavLM conditioning; the sensitivity to different GSE architectures, tokenizers/codecs (e.g., SoundStream/EnCodec), conditioning features, or inference strategies (parallel vs autoregressive) is not explored.
- ASR-content sensitivity: weaker correlation with WAcc suggests limited detection of word-level content errors; content-aware variants (e.g., joint confidence with ASR/phoneme LMs) are not investigated.
- Comparison baselines: SpeechLMScore and other strong non-intrusive predictors (e.g., MOSA-Net/Quality-Net variants) are not included as baselines for filtering; only Whisper confidence/CTC are evaluated.
- Computational cost and scalability: runtime, throughput, and GPU/CPU requirements for computing confidence at scale (100k+ hours) are not reported; practical deployment constraints remain unclear.
- Speaker coverage and fairness: filtering may disproportionately remove utterances from certain speakers/accents; per-speaker retention, speaker balance, and fairness impacts on multi-speaker TTS are not analyzed.
- Downstream TTS evaluation scope: only UTMOS, DNSMOS, and WER are reported; speaker similarity, prosody/expressiveness, style retention, and subjective MOS for the TTS models are not evaluated.
- Impact on speaker identity: although SpkSim correlation is shown for SE outputs, there is no measurement of speaker similarity for the trained TTS models or analysis of whether filtering improves speaker consistency in synthesis.
- Alternative use of confidence: using confidence as sample weights (soft selection) or curriculum scheduling for TTS training, rather than hard filtering, is not tested.
- Localized data editing: segment-level filtering (e.g., removing low-confidence regions within an utterance or partial resynthesis) is not explored; only utterance-level accept/reject decisions are made.
- Multi-metric fusion: while simple “reject-if-either-below-threshold” combinations are shown, optimal fusion (e.g., learned meta-predictors, stacking, calibration across metrics) is not developed.
- OOD detection and error attribution: it is unclear whether low confidence primarily reflects noise severity, domain mismatch, speaker idiosyncrasies, or codec artifacts; no analysis disentangles these factors.
- Sensitivity to training distribution: confidence may reflect the SE model’s training data biases; robustness when curating datasets with distributions different from the SE training data is not examined.
- Optimal acceptance-rate selection: the observed optimum (top 70–80%) is dataset- and model-specific; a general method to choose acceptance rates that maximize downstream TTS quality is not provided.
- Reproducibility and release: details on code, trained models, curated subsets, and scripts for computing confidence and thresholds are not clearly stated; public release plans are unspecified.
Glossary
- Bandwidth extension: Technique to restore or extrapolate high-frequency content to upsample audio bandwidth. "upsampled using bandwidth extension"
- Connectionist Temporal Classification (CTC): A sequence alignment and scoring framework used in ASR without frame-level alignments. "connectionist temporal classification (CTC) scores"
- DEMUCS: A discriminative deep learning model for real-time waveform-domain speech enhancement. "a discriminative SE model, DEMUCS~\cite{defossez2020real}"
- Descript Audio Codec (DAC): A neural audio codec that compresses audio using RVQ with multiple codebooks. "Descript Audio Codec (DAC)~\cite{kumar2023highfidelity}"
- DNSMOS: A non-intrusive, DNN-based speech quality predictor that estimates MOS. "a non-intrusive speech quality metric such as DNSMOS~\cite{2021dnsmos}"
- ESTOI: An intrusive intelligibility metric (Extended Short-Time Objective Intelligibility) comparing enhanced speech to a reference. "ESTOI, SI-SDR, and PESQ are traditional intrusive SE metrics for measuring speech signal similarity."
- Generative Speech Enhancement (GSE): Using generative models to synthesize clean speech from noisy inputs. "Generative speech enhancement (GSE) models show great promise in producing high-quality clean speech from noisy inputs"
- HiFi-GAN: A GAN-based neural vocoder for high-fidelity and efficient speech synthesis. "pre-trained HiFi-GAN vocoder (UNIVERSAL_V1)~\cite{Jungil2020HiFiGAN}"
- Intrusive SE metrics: Evaluation measures requiring a clean reference signal for comparison. "While intrusive SE metrics, such as PESQ~\cite{2021pesq}, SpeechBERTScore~\cite{saeki2024speechbertscore}, and LPS~\cite{2023lps}, can detect these errors by comparing the enhanced speech with a clean reference, they are impractical for in-the-wild dataset curation where such references are unavailable."
- Levenshtein Phoneme Similarity (LPS): A phoneme-level metric that detects content errors (e.g., hallucinations) using edit distance. "SpeechBERTScore and LPS are more recent metrics that evaluate the semantic fidelity of generated speech, with LPS specifically designed to detect hallucination errors in GSE."
- Matcha-TTS: A fast text-to-speech architecture based on conditional flow matching. "We used Matcha-TTS~\cite{mehta2024matcha}"
- Mean Opinion Score (MOS): A scalar measure of perceived audio quality, often predicted by learned models. "to predict a mean opinion score (MOS)."
- Parallel token prediction: An inference strategy that predicts tokens in parallel within each quantizer stage. "we adopt parallel token prediction, which generates all tokens within a single quantizer in parallel but sequentially across quantizers."
- Perceptual Evaluation of Speech Quality (PESQ): An intrusive objective metric approximating human judgments of speech quality. "ESTOI, SI-SDR, and PESQ are traditional intrusive SE metrics for measuring speech signal similarity."
- Residual Vector Quantization (RVQ): A quantization scheme that successively quantizes residuals using multiple codebooks. "Residual Vector Quantization (RVQ)~\cite{vasuki2006review}, which quantizes the residual from the previous quantizer, creating a hierarchical representation across codebooks, each with a vocabulary size of ."
- Scale-Invariant Signal-to-Distortion Ratio (SI-SDR): A reference-based metric measuring distortion while being invariant to scaling. "ESTOI, SI-SDR, and PESQ are traditional intrusive SE metrics for measuring speech signal similarity."
- Spearman's Rank Correlation Coefficient (SRCC): A nonparametric statistic that measures monotonic association between two variables. "We calculated Spearman's Rank Correlation Coefficient (SRCC)~\cite{spearman1987proof} between the non-intrusive metrics described above and the following intrusive SE metrics"
- SpeechBERTScore: A reference-aware metric for evaluating semantic fidelity of generated speech, inspired by NLP BERTScore. "SpeechBERTScore and LPS are more recent metrics that evaluate the semantic fidelity of generated speech, with LPS specifically designed to detect hallucination errors in GSE."
- UTMOS: A learned predictor of MOS focused on speech naturalness. "In this case, UTMOS-out shows a high score of 4.01 (top ), suggesting that filtering based on UTMOS-out has difficulty detecting such hallucination errors."
- Vocoder: A model that converts intermediate acoustic representations or tokens into waveform audio. "pre-trained HiFi-GAN vocoder (UNIVERSAL_V1)~\cite{Jungil2020HiFiGAN}"
- WAcc (Word Accuracy): An ASR accuracy metric equal to 1 minus WER. "word accuracy (WAcc, equal to ``'')"
- WavLM: A large-scale self-supervised speech representation model used as a feature extractor. "the layer-wise weighted sum of the pre-trained WavLM model~\cite{chen2022wavlm} to extract conditional features from noisy input."
- Whisper: A large ASR model whose per-word confidences serve as a non-intrusive intelligibility proxy. "While Whisper confidence-out filtering is competitive with our method on WAcc, its impact on other metrics is marginal."
- Word Error Rate (WER): A standard ASR metric measuring transcription errors via substitutions, deletions, and insertions. "the lowest WER (18.14\%) at ``top 70\%''."
Practical Applications
Practical Applications of the Paper’s Findings
Below are actionable applications derived from the paper’s confidence-based filtering method for generative speech enhancement (GSE) using discrete tokens. Each application includes sector alignment, example tools/workflows, and key dependencies or assumptions. They are grouped into immediate (deployable now) and long-term (requiring further development or scaling).
Immediate Applications
- Industry (Speech AI/TTS): Large-scale TTS dataset curation for voice assistants, audiobooks, gaming, and localization
- Workflow: Run a discrete token-based GSE model (e.g., Genhancer with DAC) on noisy speech; compute utterance-level confidence from token log-probabilities; retain the top N% by confidence; train TTS (e.g., Matcha-TTS/HiFi-GAN).
- Tools/products: “ConfidenceFilter” library/CLI, MLOps pipeline step for acceptance-rate tuning, dashboards showing score distributions.
- Dependencies/assumptions: Access to discrete token-based GSE with token probabilities; threshold calibration per dataset; compute capacity; risk of dataset bias if confidence correlates with speaker/noise types.
- Software/SaaS (Data Cleaning Services): Batch audio enhancement and confidence-scored curation as a service
- Workflow: Provide an API that returns enhanced audio and a confidence score; clients set thresholds to auto-accept/reject.
- Tools/products: Cloud API with “enhanced_audio + S_utt” response; quality dashboards; dataset exports with score metadata.
- Dependencies/assumptions: Licensing for DAC/Genhancer; privacy and compliance; stable inference settings (e.g., temperature) to keep scores comparable.
- Media/Entertainment (Dubbing/Post-production): Semi-automatic post-processing of field recordings with QA gating
- Workflow: Enhance recordings; use confidence timelines to flag low-confidence regions for manual review or re-record.
- Tools/products: DAW plugin showing per-segment confidence overlays; batch QC reports.
- Dependencies/assumptions: Temporal alignment of confidence to audio segments; human-in-the-loop capacity; acceptance of GSE in production pipelines.
- ASR/Voice Analytics (Enterprise/Research): Safer data preparation when enhancement is used upstream
- Workflow: If enhancement is applied before ASR/analytics, use confidence to filter out segments likely to contain hallucinations or speaker drift.
- Tools/products: Pre-processing filters integrated into ETL; mixed pipelines combining enhancement confidence with ASR confidence.
- Dependencies/assumptions: Recognition that GSE can change content; retention of raw audio for critical tasks; validation that S_utt correlates with content integrity for target domains.
- Voice Cloning Platforms: Speaker-consistent curation to improve clone fidelity
- Workflow: Use confidence to avoid training on enhancement-failed segments that introduce phoneme omissions or speaker inconsistency.
- Tools/products: Curator module that couples confidence with speaker-similarity checks; clone quality reports.
- Dependencies/assumptions: Low-confidence segments correlate with speaker drift; complementary speaker verification recommended.
- Teleconferencing and Recording Apps (Daily Life): Post-call/post-recording clean-up with user feedback
- Workflow: Enhance recordings; display an “enhancement confidence” indicator; suggest re-record or fallback to classical denoising when confidence is low.
- Tools/products: Mobile/desktop UI badges; batch clean-up; auto-fallback modes.
- Dependencies/assumptions: Offline or near-real-time processing acceptable; user adoption; clear messaging to avoid confusion.
- Academia (Speech Enhancement/TTS Research): Non-intrusive GSE quality metric for experiments and dataset curation
- Workflow: Use confidence scores to evaluate and filter GSE outputs without references; curate open datasets (e.g., Common Voice, VoxCeleb) for TTS studies.
- Tools/products: Open-source evaluation scripts; acceptance-rate vs. metric curves; reproducible curation pipelines.
- Dependencies/assumptions: Access to model internals to log token probabilities; consistency across models/codecs when comparing.
- Policy/Compliance (Organizational QA): Quality gates for synthetic voice training data
- Workflow: Require confidence-thresholded curation to reduce hallucination-induced artifacts in products; document thresholds and acceptance rates in data cards.
- Tools/products: Internal standards and audit trails; procurement checklists; quality certification badges.
- Dependencies/assumptions: Does not replace legal consent and privacy checks; needs governance to avoid biased filtering.
Long-Term Applications
- Healthcare (Hearing Aids/Telemedicine): Real-time confidence-aware enhancement to prevent hallucinated content in live interactions
- Workflow: Per-frame confidence gating; fallback to conventional denoising or prompt repetition when confidence drops.
- Tools/products: Low-latency confidence estimators; clinician-approved UX behaviors.
- Dependencies/assumptions: Efficient confidence estimation on continuous-latent GSE; strict latency/robustness requirements; clinical validation.
- Robotics (Human–Robot Interaction): Confidence-aware auditory processing on-device
- Workflow: Use enhancement confidence to decide when to rely on enhanced audio, request clarification, or adjust robot behavior.
- Tools/products: Embedded GSE with confidence output; multimodal fusion (audio + vision) to handle low-confidence segments.
- Dependencies/assumptions: On-device compute constraints; robust operation in diverse environments; safety considerations.
- Standardization and Certification (Sector-wide QA): Non-intrusive GSE quality metrics as part of dataset certification
- Workflow: Include confidence-based metrics (and LPS-like proxies) in standards for TTS/voice systems; publish test suites.
- Tools/products: Benchmarking frameworks; public tooling; certification processes for “confidence-curated” datasets.
- Dependencies/assumptions: Community consensus; transparent, reproducible scoring; cross-model comparability.
- Continuous-Latent GSE Coverage: Universal confidence estimation beyond discrete token models
- Workflow: Extend confidence measures to diffusion/flow-matching models (continuous latent spaces) for broader applicability.
- Tools/products: Calibrated estimators of output likelihood/uncertainty; validation datasets and methodologies.
- Dependencies/assumptions: New theory/practice for continuous confidence; calibration across noise types and domains.
- Active Data Curation Loops at Scale (Large TTS Training): Automated acceptance-rate optimization for quality–quantity trade-offs
- Workflow: Use threshold curves to set per-speaker or per-domain acceptance targets; auto-tune for billions of parameters and 100k+ hours.
- Tools/products: MLOps orchestration; data quality monitoring; optimization services.
- Dependencies/assumptions: Rich telemetry; budget for retraining; careful bias auditing to preserve diversity.
- Multi-metric Quality Control: Robust filtering via confidence + ASR confidence + speaker similarity + prosody/semantic checks
- Workflow: Combine signals to minimize false accepts/rejects and mitigate bias; tailored filters per downstream task (TTS, ASR, analytics).
- Tools/products: Integrated quality pipeline; explainable decisions; bias and fairness dashboards.
- Dependencies/assumptions: Higher compute cost; careful calibration; governance around fairness.
- Consumer Recording Assistance (Proactive): Live guidance during recording based on predicted enhancement confidence
- Workflow: Traffic-light UI that advises mic placement/environment changes; segment-level retake prompts.
- Tools/products: On-device predictors (without full GSE); UX experimentation; creator tools.
- Dependencies/assumptions: Surrogate models to predict post-hoc enhancement confidence; user acceptance.
- Finance/Call Centers (Compliance/Analytics): Confidence-aware audio QA for analytics pipelines
- Workflow: Flag segments likely corrupted by enhancement; route to human review; prevent false insights in compliance dashboards.
- Tools/products: Call pipeline integrations; triage queues; audit trails.
- Dependencies/assumptions: Policy alignment; scalable processing; secure handling of sensitive data.
- Data Marketplaces (Quality-Tiered Datasets): Offer confidence-curated speech datasets with transparent score distributions
- Workflow: Publish datasets labeled by confidence tiers and acceptance rates; align pricing to quality levels.
- Tools/products: Dataset data cards; reproducibility guarantees; buyer-facing dashboards.
- Dependencies/assumptions: Legal clearance; demand and pricing models; standard scoring protocols.
Notes on feasibility across applications:
- The method assumes discrete token-based GSE with accessible token log-probabilities (e.g., DAC/RVQ quantizers); adoption by continuous-latent models requires further research.
- Confidence depends on inference settings (temperature, quantizer selection) and may need per-domain calibration.
- Confidence filtering can introduce biases (e.g., against certain speakers/noise profiles); multi-metric checks and bias monitoring are recommended.
- Strong correlations are observed with intrusive metrics, but some content metrics (e.g., WAcc) may require complementary signals (ASR confidence).
Collections
Sign up for free to add this paper to one or more collections.

