- The paper introduces DRPG, a modular framework that deconstructs reviewer feedback into atomic points to enable precise and evidence-based rebuttal generation.
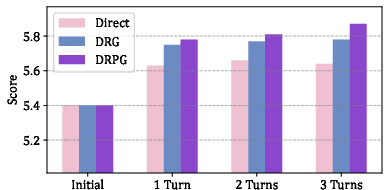
- The methodology leverages a Planner module that, with over 98% accuracy in candidate scoring, significantly outperforms both baseline and human-generated rebuttals.
- The framework enhances academic peer review by integrating efficient long-context retrieval and interpretable, adaptive planning to improve rebuttal quality.
DRPG: Agentic Framework for Academic Rebuttal Automation
Motivation and Context
The automation of academic rebuttal remains an understudied domain within the ecosystem of LLM applications for scientific workflows. While LLMs have demonstrated utility in idea generation, drafting manuscripts, and facilitating peer review, the process of constructing effective, targeted rebuttals faced by authors during conference reviews remains challenging for generic LLMs and existing ad-hoc pipelines. Two core challenges predominate: (i) long-context retrieval and evidence selection; (ii) argumentation and persuasive response planning relative to nuanced reviewer concerns. DRPG (Decompose, Retrieve, Plan, Generate) proposes a modular agentic framework to systematically address these limitations.
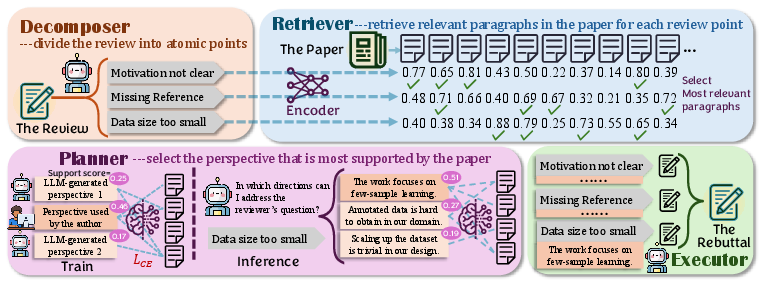
Figure 1: Overview of the DRPG framework detailing its four agentic components and workflow orchestration.
Framework Architecture
DRPG is composed of four tightly integrated modules designed to process reviews and generate rebuttals with high fidelity to both paper content and reviewer concerns:
- Decomposer: Deconstructs reviewer feedback into fine-grained, atomic points. This transformation is crucial for downstream retrieval and focused argumentation, addressing the fragmentation of multifaceted reviews.
- Retriever: Utilizes dense retrieval (BGE-M3 encoder) to pair each atomic point with the most relevant paper paragraphs, reducing input context by over 75% while preserving critical evidence needed for precise rebuttal construction.
- Planner: Proposes multiple candidate perspectives per review point via prompt-instructed LLMs, and selects the most defensible perspective by scoring supportedness using an MLP over concatenated encoder outputs of candidate perspectives and retrieved evidence. The framework differentiates between clarification and justification strategies and achieves over 98% accuracy in identifying human-validated rebuttal directions.
- Executor: Synthesizes the final rebuttal paragraph using selected points, retrieved evidence, and planned perspective, instantiated by either generic LLMs or specialized generators.
Technical Analysis of the Planner Module
The Planner is the unique component that enables DRPG to transcend template-driven or purely generative responses. By explicitly considering “clarification” (counteracting factual misunderstandings) and “justification” (defending the validity of choices against subjective critiques), the Planner generates and scores perspectives relative to paper content. Its architecture employs an encoder-MLP scoring function:
s(pers,p)=K1j=1∑KM(E(pers)∥E(pj))
where E(⋅) is the BGE-M3 text encoder and M is a multilayer perceptron. Training leverages human-annotated rebuttal trajectories to minimize cross-entropy over candidate sets. Ablation experiments demonstrate that omitting paper context, overinclusion (using full paper), or forgoing an MLP for simple vector similarity all degrade accuracy, supporting the claim that nuanced, content-sensitive planning is crucial for rebuttal quality.
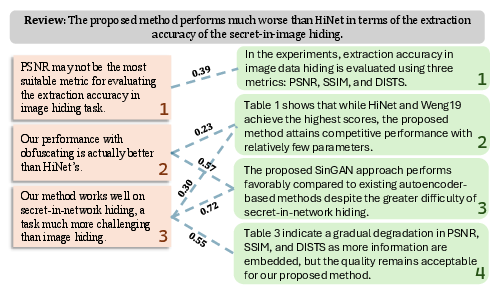
Figure 2: Example visualization of Planner perspective scoring showcasing nuanced claim–evidence relationships, with normalized scores for each candidate.
Experimental Results and Evaluation
A comprehensive experimental evaluation is conducted on the Re2 dataset, spanning 17,814 papers, 62,211 reviews, and 34,024 rebuttals from major CS conferences. DRPG is evaluated with four base LLMs (Qwen3-8B, GPT-oss-20B, Mixtral-8x7B, LLaMa3.3-70B) and compared against (i) direct LLM response, (ii) ablated agentic baselines, (iii) template-based Jiu-Jitsu pipeline, and (iv) human-authored rebuttals.
Key findings include:
Human Agreement and Explainability
Human studies (with Fleiss’ κ=0.598, Cohen’s κ=0.500) confirm substantial consistency among expert annotators and alignment of LLM-based evaluation with human judgment. Visualization of Planner scores provides interpretable rationales for perspective selection, bridging the gap between automated generation and human oversight.
Figure 4: Illustration of the annotation interface used for expert human study and evaluation validation.
Implications and Future Directions
From a practical standpoint, DRPG offers a scalable solution for the burgeoning volume of academic submissions, where thoughtful author–reviewer dialogues are increasingly laborious. The system’s modular decomposition, targeted evidence retrieval, and perspective-aware planning set a precedent for the integration of agentic LLM systems into peer review, with implications for improved fairness, efficiency, and author experience.
Theoretically, the Planner introduces an avenue for structured argumentation that blends retrieval-augmented generation with explicit reasoning, pertinent for high-stakes adversarial language tasks beyond rebuttal (e.g., scientific debate, legal argument synthesis).
Future work may focus on:
- Integration with “AI Scientist” systems for experimental augmentation, addressing limitations in conducting new analyses during rebuttal.
- Extending DRPG to other domains of adversarial professional communication.
- Mitigating potential model hallucinations and ensuring author verification before deployment.
Conclusion
DRPG establishes an effective agentic framework for academic rebuttal automation, integrating decomposition, evidence retrieval, strategic planning, and generation to deliver superior rebuttal quality. Its modular approach overcomes key limitations in context processing and persuasive argumentation, with empirical results and human alignment substantiating its claims. The implications span both practical peer review scaling and theoretical advances in agentic reasoning architectures, positioning DRPG as a reference for structured LLM workflows in scholarly communication (2601.18081).