JaxARC: A High-Performance JAX-based Environment for Abstraction and Reasoning Research
Abstract: The Abstraction and Reasoning Corpus (ARC) tests AI systems' ability to perform human-like inductive reasoning from a few demonstration pairs. Existing Gymnasium-based RL environments severely limit experimental scale due to computational bottlenecks. We present JaxARC, an open-source, high-performance RL environment for ARC implemented in JAX. Its functional, stateless architecture enables massive parallelism, achieving 38-5,439x speedup over Gymnasium at matched batch sizes, with peak throughput of 790M steps/second. JaxARC supports multiple ARC datasets, flexible action spaces, composable wrappers, and configuration-driven reproducibility, enabling large-scale RL research previously computationally infeasible. JaxARC is available at https://github.com/aadimator/JaxARC.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces JaxARC, a super-fast “practice environment” for training AI to solve ARC puzzles. ARC (Abstraction and Reasoning Corpus) is a set of small colored-grid puzzles where you have to figure out the rule that transforms an input grid into an output grid, using only a few examples. JaxARC is built to let AI agents learn these rules through trial and error much faster than before.
What questions are the researchers asking?
They focus on three simple questions:
- How can we make a training environment for ARC puzzles that runs thousands or millions of puzzles at the same time?
- Can we remove the slow parts of older systems so researchers can try big ideas in hours instead of weeks?
- Will this faster system still be flexible and easy to use for different kinds of experiments?
How did they do it?
ARC in simple terms
Imagine a pixel-art puzzle: you see a few examples of how an input picture turns into an output picture, and you must apply the same rule to a new input. The rule might be “fill the biggest red shape with blue” or “rotate a pattern,” but it’s not written down—you have to figure it out.
What is an RL environment?
Reinforcement Learning (RL) is like training a player in a video game:
- The “environment” is the game world (here, the ARC puzzle).
- The “agent” is the player making moves.
- The agent tries actions, gets a score (reward), and learns over time.
An RL environment needs to be fast so the agent can practice a huge number of times.
What makes JaxARC fast?
JaxARC uses JAX, a library that runs math operations in parallel on GPUs/TPUs and can “compile” code for speed.
Here are the key ideas, explained in everyday terms:
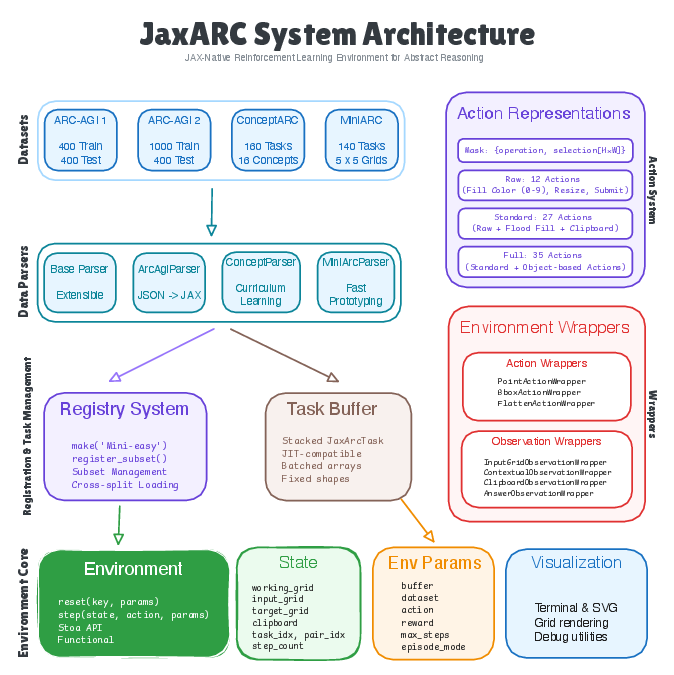
- Stateless, functional design: Think of a calculator with no memory. You give it the current puzzle state and an action, and it returns a new state without keeping secrets. This “no hidden memory” makes it easy to run many puzzles at once and to compile for speed.
- Batching and padding: ARC puzzles have different sizes. JaxARC pads all grids up to a fixed size (30×30), like putting small papers on a larger sheet with blank borders, plus a mask that says which parts are real. This lets the system process many puzzles in one big batch.
- JIT compilation: “Just-in-time” compilation turns slow step-by-step instructions into a fast, optimized program. It’s like pre-building a shortcut before you run.
- Action masks: Actions are “what operation to use” plus “where to apply it” on the grid. Internally, JaxARC turns different action types (like clicking a point or selecting a box) into a simple on/off mask so everything runs in the same fast format.
- Preloaded tasks: Puzzles are loaded once into memory, so there’s no waiting during training—like laying out all worksheets on the table before you start.
- Composable wrappers: You can add useful extra channels to what the agent sees (like the original input grid or the target grid) without slowing things down much or changing the core logic.
JaxARC also shapes rewards so learning isn’t impossible:
- Small rewards for getting closer to the target picture,
- A big bonus for a perfect solution,
- Tiny penalties to discourage wasting steps or guessing early.
What did they find, and why is it important?
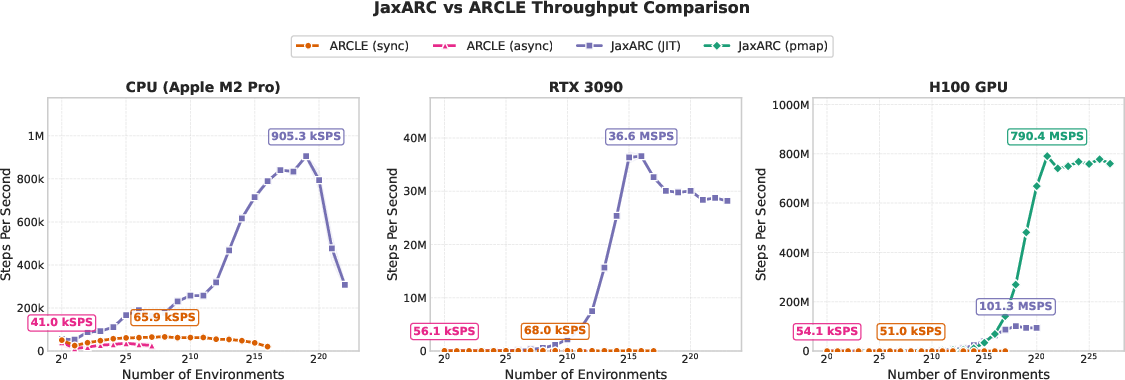
The main result: JaxARC is dramatically faster than previous Python-based environments (like ARCLE).
- At matched scales, it’s 38× to 5,439× faster, depending on the hardware.
- On a high-end GPU (NVIDIA H100), it reached about 790 million steps per second.
- This means experiments that used to take weeks can finish in hours.
Why this matters:
- Modern RL needs tons of practice steps. If the simulator is slow, you can’t try many ideas.
- With JaxARC, researchers can explore bigger models, do large-scale experiments, and iterate quickly.
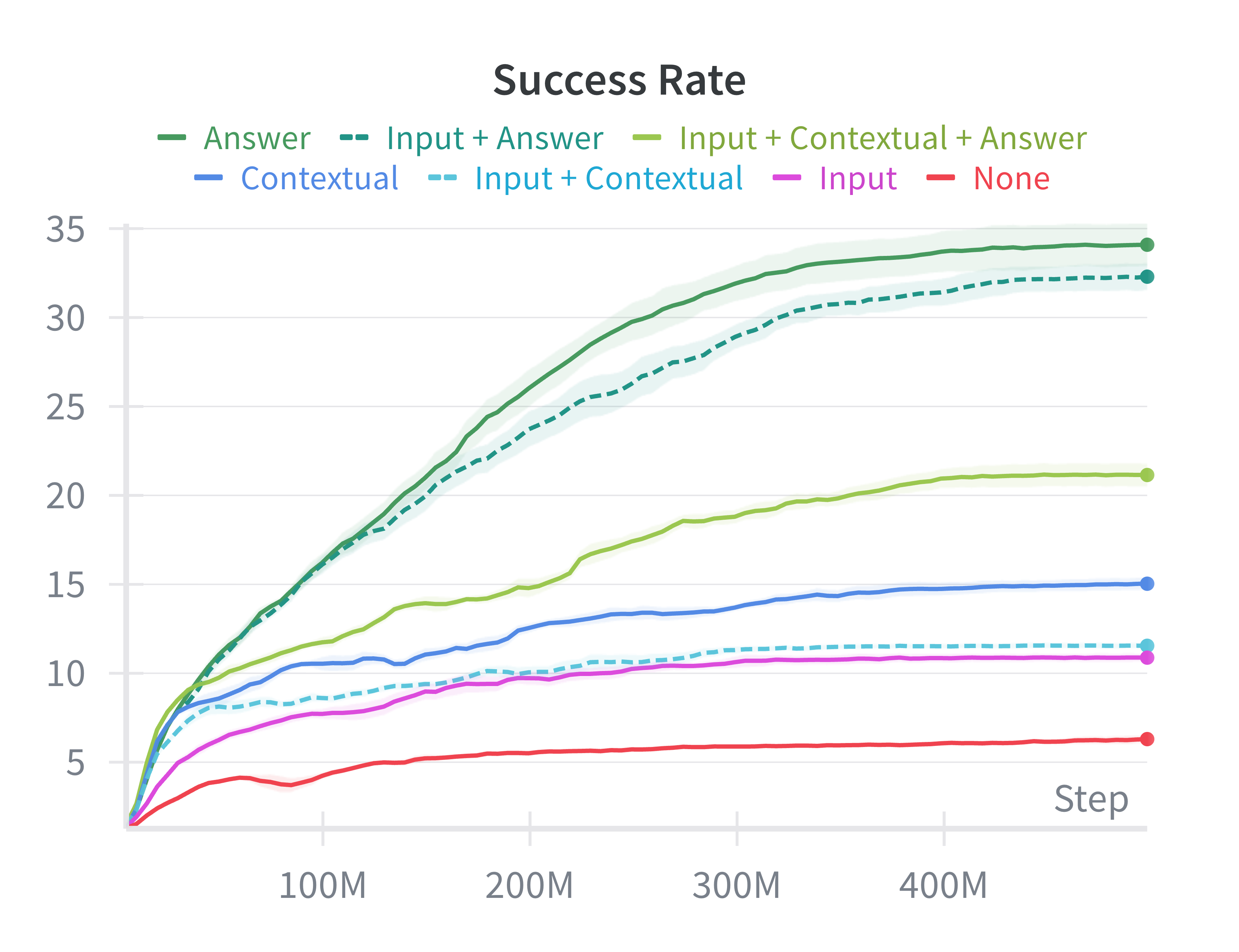
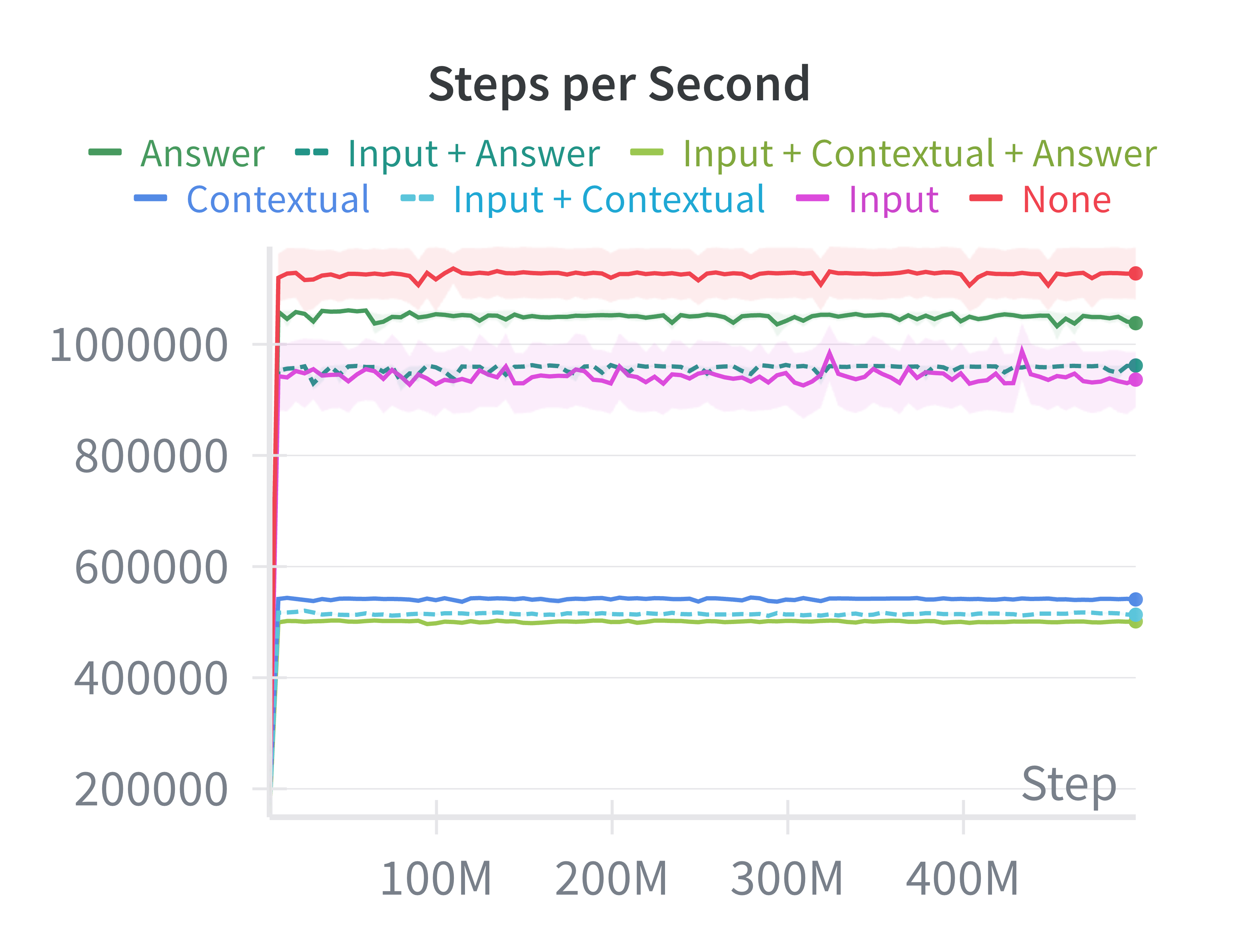
They also ran a simple training test with PPO (a popular RL algorithm) to see what the agent should “see”:
- When the agent is shown the target answer grid as part of its observation, it learns much better on the small ARC set they tested.
- Just giving the input or example pairs without the answer helps much less with a simple network.
- Adding lots of extra channels slows training a bit and doesn’t help unless the model is smart enough to use them.
- Takeaway: easy hints (like the target grid) boost learning for simple models; using demonstrations well probably needs smarter architectures.
Another useful result: runs are perfectly reproducible from a random seed, even across different hardware. That reduces confusion and makes research more reliable.
What could this change?
- Faster research cycles: People can try more algorithms, bigger models, and new ideas quickly, which is crucial for a hard challenge like ARC.
- Scalable studies: Things like meta-learning, architecture search, or population-based training become practical because the environment can handle huge numbers of steps.
- Better tools for reasoning research: By removing the speed barrier, the field can focus on the real challenge—teaching AI to learn abstract rules from very few examples.
- Community impact: JaxARC is open-source and integrates with other JAX RL tools, so others can build on it, test new ideas, and share reproducible results.
In short, JaxARC is a fast, flexible, and reliable platform that makes it much easier to push forward research on AI reasoning with ARC.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Generalization beyond MiniARC: Performance and learning are evaluated primarily on a single MiniARC task and a small MiniARC dataset; there is no evidence of scalability, correctness, or success on the full ARC-AGI benchmark or diverse ARC subsets. Actionable: run comprehensive benchmarks across full ARC datasets and harder tasks.
- Faithfulness of action semantics: The mask-based action system departs from ARCLE’s object-state model (e.g., rotation requires square bounding boxes; movement wraps within bounding boxes; flood fill uses a fixed 64-step iteration). It is unclear how these design choices affect solvability and alignment with canonical ARC puzzle semantics. Actionable: create automated equivalence tests against ARCLE/official ARC solutions and analyze cases where mask semantics break expected behavior.
- Flood-fill correctness: The fixed-iteration flood fill (64 steps) may fail on larger connected components or specific shapes; no correctness or worst-case analysis is provided. Actionable: prove bounds or empirically test flood-fill completeness across grid sizes and shapes, and adapt iteration depth dynamically.
- Handling of invalid actions: The environment does not document how invalid actions (e.g., non-square rotation selections, empty selection for flood fill) are penalized or handled, and whether this induces degenerate policies. Actionable: define, implement, and ablate penalties and transitions for invalid actions; verify stability under adversarial action sequences.
- Reward shaping reliability and leakage risks: The similarity reward is training-only, but interaction with wrappers (especially AnswerObservation) may leak target information; no formal analysis of leakage or shaping-induced bias is presented. Actionable: audit observation/reward pathways for leakage; ablate shaping coefficients systematically and measure effects on exploration, credit assignment, and generalization.
- Unrealistic “Answer” observation condition: PPO ablations show the AnswerObservation wrapper drives learning, but providing the target grid is unrealistic for ARC evaluation. The paper does not report performance without the answer channel at test time or on held-out tasks. Actionable: establish evaluation protocols that exclude answer channels; report train/test splits and generalization metrics without target hints.
- Underpowered architectures for contextual demos: Shallow CNNs fail to exploit contextual demonstration channels; no attempts at architectures tailored to few-shot rule induction (attention over demos, meta-learning) are reported. Actionable: implement cross-attention, memory-augmented networks, and meta-learning baselines; quantify gains from structured processing of demo pairs.
- Episode horizon sensitivity: The fixed 150-step limit is not justified or analyzed; some tasks may require longer sequences or benefit from adaptive termination criteria. Actionable: study horizon effects, dynamic termination policies, and curriculum strategies on sample efficiency and success.
- Lack of diverse algorithmic baselines: Only PPO is evaluated; there are no off-policy (e.g., SAC), planning, evolutionary, or neuro-symbolic baselines. Actionable: add a suite of baselines (off-policy RL, imitation learning from human trajectories, program synthesis hybrids) to contextualize environment utility.
- Missing generalization metrics: Success is measured via 100% pixel similarity on episodes, but there is no cross-task generalization evaluation (train/test splits, robustness to distribution shifts). Actionable: adopt ARC-AGI-style generalization protocols and report success on unseen tasks with standardized splits.
- Limited performance fairness baseline: Comparisons target ARCLE only; no high-performance alternatives (e.g., EnvPool-like C++ backends, Numba/Cython-accelerated ARCLE) are considered. Actionable: include stronger baselines to isolate JAX/XLA benefits from Python overhead artifacts.
- Throughput-only benchmarking: Results emphasize throughput; there is no analysis of latency for small batch sizes (beyond qualitative comments), compile-time costs, VRAM/RAM footprints, or energy efficiency. Actionable: report latency distributions, compilation time, memory use by batch size, and watts/SPS across devices.
- Determinism claims unverified across versions/devices: The paper asserts identical rollouts across CPU/GPU/TPU with the same seed, but provides no empirical tests across JAX/XLA versions, device counts, or parallelization strategies. Actionable: publish determinism test suites and document caveats (e.g., PRNG splitting, pmap/vmap order effects).
- Multi-device/multi-host scaling: pmap is used on a single H100; scaling across multiple devices/hosts (multi-node) and the associated communication overheads are not studied. Actionable: evaluate pjitt/sharded execution, multi-host scaling, and end-to-end training throughput with distributed learners.
- Task buffer memory constraints: Pre-stacking padded 30×30 tasks may incur high memory usage on full ARC; lazy parsing is mentioned but not characterized. Actionable: measure dataset memory footprints, device-host transfer patterns, and streaming strategies for large task corpora.
- Padding overhead and dynamic shapes: The 30×30 padding choice avoids dynamic shapes but may waste compute on small grids; no quantification of this overhead or exploration of alternatives (e.g., bucketing by size) is provided. Actionable: benchmark bucketing, ragged batching, or masked computation to reduce padding overhead.
- Action-space subset selection impact: The environment allows restricting operations, but its effect on solvability, sample efficiency, and policy learning is unknown. Actionable: map tasks to minimal operation subsets and conduct ablations on solvability and learning curves under reduced action spaces.
- Wrapper correctness and performance trade-offs: Wrappers are composable, but their computational overhead, potential information leakage, and compatibility with agent architectures are not measured beyond coarse throughput. Actionable: profile wrapper costs, test structured encodings (object lists, relational graphs, positional encodings), and evaluate performance/utility trade-offs.
- BrainGridGame compatibility and imitation learning: Operations are aligned to BrainGridGame to enable use of ARC-Interactive-History trajectories, but no experiments demonstrate successful imitation or behavior cloning. Actionable: run imitation learning baselines using the history dataset, verify operation alignment, and quantify policy performance improvements.
- PPO hyperparameter robustness: The PPO setup is fixed; there are no hyperparameter sweeps or sensitivity analyses, especially under different observation/action configurations. Actionable: conduct systematic hyperparameter studies to decouple environment improvements from algorithm tuning effects.
- Evaluation with realistic test conditions: Mode-aware rewards hide target similarity shaping during evaluation, but combined with various observation wrappers, the true evaluation regime (what the agent sees at test time) is not clearly defined. Actionable: specify and enforce evaluation-time observation restrictions and report test-only success metrics.
- Error handling and numerical stability: The paper does not discuss how the environment handles extreme cases (e.g., degenerate masks, full-grid operations on large batches) or XLA-related numerical/stability issues. Actionable: add stress tests for edge cases and document stability guarantees.
- Integration via monkey-patching: Stoix integration relies on monkey-patching, which may be brittle across releases. Actionable: provide a formal plugin or registry-based integration to ensure maintainability and compatibility with upstream changes.
- End-to-end training pipelines: While throughput is high, there is no evidence that end-to-end training (including data loading, logging, checkpointing) scales proportionally or remains stable at multi-million environment scales. Actionable: measure holistic pipeline throughput and failure modes during long-running experiments.
- Benchmark representativeness: ARCLE was configured with a 5×5 max grid and bounding-box actions; the representativeness of this setup relative to more complex ARC tasks is unclear. Actionable: standardize matched configurations across frameworks and report sensitivity to grid sizes and action parameterizations.
- Success metric limitations: Binary success at 100% pixel match may obscure partial progress, compositional rule induction, or near-miss behaviors. Actionable: introduce auxiliary metrics (rule identification accuracy, partial similarity trajectories, operation efficiency) to better capture reasoning progress.
- Curriculum and task difficulty: No curriculum or difficulty scaling is studied, though ARC tasks vary widely in complexity. Actionable: implement and evaluate curricula that ramp task difficulty, measure impacts on sample efficiency and final performance.
- Policy interpretability and reasoning traces: High-speed rollouts are provided, but there is no analysis of learned policies’ reasoning steps (e.g., operation sequences, subgoal formation). Actionable: instrument and analyze trajectories to identify emergent reasoning patterns or failure modes.
- Reproducibility across ecosystems: Claims of easy reproducibility via Hydra configs are promising, but there is no artifact (e.g., Docker/Nix) ensuring environment parity across systems. Actionable: release containerized reproducibility artifacts and CI tests validating identical results across hardware/software stacks.
Glossary
- Abstraction and Reasoning Corpus (ARC): A benchmark of few-shot visual reasoning puzzles used to evaluate inductive reasoning in AI systems. "The Abstraction and Reasoning Corpus (ARC) tests AI systems' ability to perform human-like inductive reasoning from a few demonstration pairs."
- Anakin architecture: A specific neural network architecture used in the Stoix FF-PPO baseline experiments. "Algorithm: Stoix FF-PPO (feed-forward PPO) with the Anakin architecture (1,024 parallel environments)."
- ARCLE: A Gymnasium-based reinforcement learning environment for ARC that established a standardized interface but is limited by Python performance. "ARCLE \citep{leeARCLEAbstractionReasonin2024} established the first standardized Gymnasium-based RL environment for ARC, framing its challenges in RL terms: sparse rewards, vast combinatorial action spaces, and extreme diversity requiring strong generalization."
- AsyncVectorEnv: A Gymnasium utility that parallelizes environment execution using multiple OS processes. "arcle-async: AsyncVectorEnv distributing environments across OS-level worker processes for parallel execution."
- Bounding-box actions: An action parameterization that selects rectangular regions via two corner coordinates plus an operation. "bounding-box actions expand the action space considerably but offer richer region selection."
- Brax: A JAX-based physics simulation library for continuous control tasks in RL. "Brax \citep{freemanBraxDifferentiablePhysics2021} focuses on continuous control."
- BrainGridGame: An interface for object-oriented grid operations that JaxARC’s actions are compatible with to enable imitation learning. "BrainGridGame-compatible operations"
- Cache thrashing: Performance degradation caused by frequent cache evictions at large batch sizes. "before degrading due to cache thrashing."
- Clip coefficient: The epsilon parameter in PPO that bounds policy updates to stabilize training. "clip coefficient "
- ContextualObservationWrapper: An observation wrapper that adds channels containing demonstration input-output pairs. "ContextualObservationWrapper: Adds demonstration pairs from the task as additional channels (+10 for default 5 pairs: each pair contributes 2 channels for input and output grids)."
- Entropy coefficient: A regularization weight in RL that encourages exploration by increasing policy entropy. "entropy coefficient 0.01"
- Feed-forward PPO (FF-PPO): A PPO variant that uses feed-forward networks (no recurrence) during training. "Stoix FF-PPO (feed-forward PPO)"
- Flood fill: An operation that fills a contiguous region starting from a seed cell. "Flood fill operations (10--19): Flood fill from a single selected cell with colors 0--9."
- Functional purity: A design property where APIs are stateless and composed of pure functions to enable transformations like JIT and vectorization. "JaxARC implements a purely functional API where reset and step are stateless pure functions"
- GAE (Generalized Advantage Estimation): A method for estimating advantages in RL that balances bias and variance. "GAE "
- Gymnax: A JAX RL library providing implementations of classic benchmark environments. "Gymnax \citep{gymnax2022github} provides JAX implementations of classic RL benchmarks"
- Gymnasium: A standardized RL environment API used for building and interacting with simulated tasks. "Gymnasium-based RL environment"
- Hydra: A configuration management framework used to define experiments via YAML files. "Hydra-based YAML configuration specifies datasets, action spaces, rewards, and wrappers."
- IPC overhead: The computational cost of inter-process communication that limits scalability. "per-step Python interpreter costs and IPC overhead dominate."
- JAX: A high-performance numerical computing library offering automatic differentiation, vectorization, and compilation to accelerators. "Built entirely in JAX \citep{jax2018github}, JaxARC leverages a functional, stateless architecture to enable automatic vectorization and XLA compilation on hardware accelerators (GPUs/TPUs)."
- JIT compilation: Just-in-time compilation of computations to optimized kernels for accelerators. "JIT-compiled rollout for performance"
- Jumanji: A JAX RL suite focused on combinatorial optimization tasks. "Jumanji \citep{bonnetJumanjiDiverseSuite2023} offers combinatorial optimization tasks"
- MAML: Model-Agnostic Meta-Learning, an algorithm enabling rapid adaptation to new tasks. "meta-learning algorithms like MAML \citep{finnModelagnosticMetalearningFast2017} requiring millions of episodes."
- Mask tensor: A binary tensor used to mark valid regions within padded grid arrays. "with mask tensors indicating valid regions."
- Meta-learning: Methods where models learn inductive biases to quickly adapt to new tasks from few examples. "meta-learning approaches \citep{beckTutorialMetaReinforcementLearning2025}"
- Monkey-patching: Dynamically modifying or extending library behavior at runtime without altering its source. "uses lightweight monkey-patching to inject JaxARC support into Stoix's environment discovery system"
- Multiprocessing: Parallel execution model using multiple processes to run environments concurrently. "multiprocessing AsyncVectorEnv"
- pmap: A JAX transformation that parallelizes computation across multiple devices. "jaxarc-pmap (multi-device parallelization on H100)"
- Population-based training: A method that evolves a population of models and hyperparameters during training. "JaxARC enables population-based training \citep{langeEvosaxJAXbasedEvolution2022}"
- PPO: Proximal Policy Optimization, a popular on-policy RL algorithm for training policies. "We conducted experiments to evaluate how different observation configurations affect PPO performance on MiniARC tasks."
- PRNG: Pseudo-random number generator mechanism in JAX that uses explicit keys for determinism. "through JAX's PRNG-based indexing."
- Pytrees: Nested container structures (lists, dicts, tuples) recognized by JAX for transformations. "All components are JAX pytrees, enabling JAX transformations (jit, vmap, pmap)."
- Reward shaping: Augmenting reward signals to guide learning and overcome sparsity. "JaxARC addresses ARC's sparse reward challenge through configurable reward shaping."
- Scan unroll factor: A parameter controlling loop unrolling in JAX’s scan primitive, affecting performance. "All JaxARC runs used scan unroll factor of 1."
- SiLU activation: A smooth nonlinearity (Swish) used in neural networks to improve performance. "SiLU activation"
- SLURM: A cluster workload manager used to schedule and run jobs like hyperparameter sweeps. "Scripts for launching SLURM-based hyperparameter sweeps are also included"
- Sparse rewards: Reward signals that occur infrequently, making exploration and credit assignment difficult. "sparse rewards, vast combinatorial action spaces"
- Stoa API: A standard interface for JAX-native environments enabling interoperability with RL libraries. "The API is built on top of the Stoa \citep{toledoStoaJAXnativeInterface2025} interface"
- Stoix: A JAX-native RL library providing algorithms and tooling that integrate with JaxARC. "JaxARC integrates seamlessly with Stoix \citep{toledoStoixDistributedSingleagent2024}, a JAX-native RL library"
- SyncVectorEnv: A Gymnasium utility that executes multiple environments sequentially in a single process. "arcle-sync: Gymnasium's SyncVectorEnv executing environments sequentially in a single process"
- TPU: Tensor Processing Unit, a specialized hardware accelerator for machine learning workloads. "XLA compilation on hardware accelerators (GPUs/TPUs)."
- vmap: A JAX transformation that vectorizes functions over batch dimensions for single-device parallelism. "jaxarc-jit (single-device vectorization via vmap)"
- XLA: Accelerated Linear Algebra compiler used by JAX to generate optimized kernels for CPUs, GPUs, and TPUs. "XLA compilation on hardware accelerators (GPUs/TPUs)."
- YAML: A human-readable data serialization format for configurations. "Hydra-based YAML configuration specifies datasets, action spaces, rewards, and wrappers."
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging JaxARC’s high-throughput, stateless JAX design, composable wrappers, reward shaping, and reproducible configuration-driven workflows.
- High-throughput ARC benchmarking for RL research labs (Academia, Software/AI)
- Use JaxARC to run billion-step experiments in hours instead of weeks, enabling rapid ablations, curriculum studies, and generalization tests across ARC subsets and observation configurations.
- Tools/workflows: Hydra-driven configs, Stoix integration via jaxarc-baselines, SLURM sweeps, vmap/jit rollouts, reproducible seeds across CPU/GPU/TPU.
- Assumptions/dependencies: Access to GPUs/TPUs; familiarity with JAX; sufficient device memory for large batch sizes.
- Population-based training, neural architecture search, and meta-RL at scale (Software/AI, Academia)
- Exploit JaxARC’s throughput to run EvoSAX, PBT, and MAML-style experiments requiring millions of episodes on ARC tasks.
- Tools/workflows: EvoSAX, Stoix PPO/MAML, configuration sweeps with reproducible seeds; Stoa API for plug-and-play across JAX RL libraries.
- Assumptions/dependencies: Algorithms implemented in JAX; careful reward shaping; monitoring to avoid overfitting to answer channels during training.
- Goal-conditioned policy training using answer observations (Academia, Education)
- Train policies with AnswerObservationWrapper to learn action sequences to reach specified goals, demonstrating goal-conditioned RL on grid tasks.
- Tools/workflows: Wrapper configurations (Answer/Input/Contextual), shallow CNN baselines to start, ablations on channel count.
- Assumptions/dependencies: Recognition that “answer-as-observation” boosts learning but does not represent true generalization; use for controlled studies and curricula.
- Deterministic, cross-hardware reproducibility in RL CI pipelines (Software/Engineering)
- Integrate JaxARC into continuous integration to validate RL algorithm behavior across CPU/GPU/TPU with identical seeds and configs.
- Tools/workflows: GitHub Actions or internal CI, config snapshots, seed logging, throughput/SPS tracking.
- Assumptions/dependencies: JAX version alignment; consistent driver/runtime; minimizing host-device transfer variance.
- Imitation learning from human trajectories aligned with BrainGridGame ops (Academia, Education)
- Use JaxARC’s BrainGridGame-compatible operations to perform behavioral cloning or inverse RL on the ARC-Interactive-History-Dataset.
- Tools/workflows: Data ingestion via parsers, policy training on recorded human solutions, evaluation with JaxARC visualization modes.
- Assumptions/dependencies: Availability and licensing of trajectory datasets; preprocessing alignment; selecting appropriate network capacity.
- Teaching and debugging with built-in visualization (Education, Academia)
- Deploy JaxARC’s terminal/SVG modes to visualize state transitions, rewards, and agent action masks for classroom demos and research debugging.
- Tools/workflows: RL-step and complete-task views, curriculum materials, side-by-side comparisons of wrappers/rewards.
- Assumptions/dependencies: Lightweight rendering (SVG) suitable for notebooks and dashboards; basic JAX literacy among learners.
- Standardized ARC Prize experimentation and submissions (Industry, Academia)
- Use JaxARC to run large-scale experiments, log reproducible configs/seeds, and prepare stronger competition entries with meta-learning and architecture search.
- Tools/workflows: Hydra configs for task subsets, reward shaping toggles (train-only similarity shaping), Stoix integration.
- Assumptions/dependencies: Adherence to ARC Prize evaluation protocols; careful train/eval mode handling to avoid target leakage.
- Design patterns for building other high-throughput JAX environments (Software, Robotics, Operations Research)
- Adopt JaxARC’s stateless functional API, fixed-shape padding, mask-based actions, and preloaded buffers to implement fast JAX envs for combinatorial optimization (e.g., scheduling, routing) and planning.
- Tools/workflows: Stoa API, parsers, registry, wrapper stacks; pmap/vmap-based vectorization.
- Assumptions/dependencies: Problem can be represented with fixed-size tensors; domain-specific reward shaping and action masks defined.
Long-Term Applications
These applications require further algorithmic advances (e.g., stronger architectures, meta-learning), scaling, or domain adaptation, but are enabled by the methods and performance characteristics introduced by JaxARC.
- Foundation “reasoning modules” trained on ARC integrated with multimodal LLMs (Software/AI)
- Train transferable abstract reasoning policies and plug them into tool-using LLMs for stepwise planning/manipulation tasks.
- Tools/products: Modular reasoning heads, adapters for action masking; “ARC-to-LLM” tooling for environment interaction.
- Assumptions/dependencies: Demonstrated transfer from ARC to broader tasks; interfaces for LLM-policy collaboration; safe deployment strategies.
- High-level planning in robotics via learned abstract transformations (Robotics)
- Use ARC as a proxy for compositional reasoning; translate learned operators to planning pipelines (task-level manipulation, route planning).
- Tools/products: JAX-native simulators using JaxARC design patterns, mask-based region operations for robot workspaces.
- Assumptions/dependencies: Robust sim-to-real transfer; perception-action grounding beyond grids; safety and reliability requirements.
- Neuro-symbolic hybrids for program synthesis guided by RL trajectories (Software/AI)
- Combine JaxARC-generated trajectories and reward signals with program synthesis systems to discover transformation rules in symbolic form.
- Tools/products: Trajectory-to-DSL mappers, bidirectional search guided by policy priors, auto-curricula.
- Assumptions/dependencies: Interoperable DSLs; tractable search spaces; interpretable rule discovery for verification.
- Adaptive tutoring systems that teach compositional reasoning through puzzles (Education)
- Build curricula and adaptive feedback loops using ARC-style tasks to train human learners and measure reasoning improvements.
- Tools/products: “ARC Studio” for teachers/students, automated difficulty progression, explainable visualizations of solution steps.
- Assumptions/dependencies: Valid educational outcomes from ARC-like tasks; alignment with standards; accessibility considerations.
- Model certification and reproducibility standards for generalization benchmarks (Policy, Standards)
- Establish reproducible, cross-hardware evaluation protocols (seeded configs, deterministic rollouts) as part of model auditing and research reporting standards.
- Tools/products: Benchmark-as-a-service platforms, compliance checklists, reproducibility badges.
- Assumptions/dependencies: Community and regulator buy-in; governance around dataset splits and evaluation secrecy.
- Domain-specific high-throughput RL environments for operational optimization (Healthcare, Energy, Finance, Logistics)
- Apply JaxARC’s architectural blueprint to build fast JAX envs for scheduling (OR), grid balancing (Energy), portfolio planning (Finance), and patient-flow optimization (Healthcare).
- Tools/products: JAX env kits with padded tensors and stateless APIs; mask-based actions tailored to domain constraints; policy training at billions of steps.
- Assumptions/dependencies: Accurate simulators; domain data and reward functions; compliance and safety constraints; interpretability requirements.
- Sustainable ML through compute-efficient experimentation (Policy, Operations)
- Reduce energy and cost footprints by shifting to high-throughput, compiled JAX environments that finish experiments faster.
- Tools/products: Energy dashboards linking SPS to power use, institutional guidance for accelerator procurement and scheduling.
- Assumptions/dependencies: Transparent energy metrics; responsible scaling; fair comparison methodologies.
- Human-AI collaboration tools for complex puzzle and planning tasks (Daily life, Software/AI)
- Build interactive assistants that propose stepwise transformations, visualizing “what-if” edits on grid-like problems (e.g., layout design, pattern creation).
- Tools/products: Web UIs leveraging JaxARC’s visualization and action masks; co-creation workflows with undo/redo and rule suggestions.
- Assumptions/dependencies: UX design for non-experts; generalization beyond ARC puzzles; privacy/security for user data.
- Certification and eval services for ARC-like reasoning capability (Industry, Platforms)
- Offer SaaS platforms that score models on standardized ARC suites, with reproducible seeds and transparent reports for customers evaluating reasoning prowess.
- Tools/products: Cloud-hosted JAX backends, customer dashboards, standardized metrics (success rate, steps-to-solve, similarity progression).
- Assumptions/dependencies: Market demand for reasoning evaluation; data governance; scalable cloud accelerators.
- Cross-disciplinary research on compositionality and abstraction in AI (Academia)
- Use JaxARC to systematically study inductive biases, architectures (ResNets/ViTs with attention), memory augmentation, and curricula for compositional reasoning.
- Tools/workflows: Large-scale ablation grids, wrapper libraries for contextual demos, meta-learning pipelines.
- Assumptions/dependencies: Continued algorithmic innovation; community benchmarks; careful separation of training vs evaluation signals to avoid leakage.
Collections
Sign up for free to add this paper to one or more collections.