ARC Is a Vision Problem!
Abstract: The Abstraction and Reasoning Corpus (ARC) is designed to promote research on abstract reasoning, a fundamental aspect of human intelligence. Common approaches to ARC treat it as a language-oriented problem, addressed by LLMs or recurrent reasoning models. However, although the puzzle-like tasks in ARC are inherently visual, existing research has rarely approached the problem from a vision-centric perspective. In this work, we formulate ARC within a vision paradigm, framing it as an image-to-image translation problem. To incorporate visual priors, we represent the inputs on a "canvas" that can be processed like natural images. It is then natural for us to apply standard vision architectures, such as a vanilla Vision Transformer (ViT), to perform image-to-image mapping. Our model is trained from scratch solely on ARC data and generalizes to unseen tasks through test-time training. Our framework, termed Vision ARC (VARC), achieves 60.4% accuracy on the ARC-1 benchmark, substantially outperforming existing methods that are also trained from scratch. Our results are competitive with those of leading LLMs and close the gap to average human performance.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
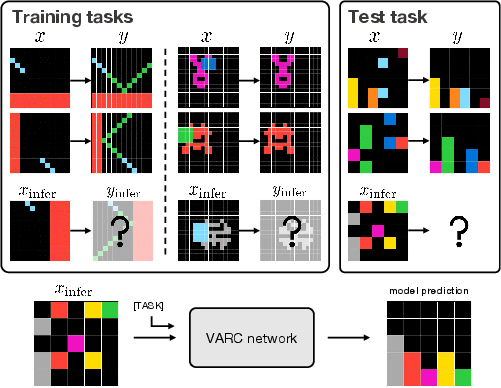
This paper asks a simple question: if ARC puzzles look like pictures, why don’t we solve them like pictures? ARC (Abstraction and Reasoning Corpus) is a set of tiny grid puzzles where you must figure out the rule that turns an input image into an output image (like “mirror this shape,” “make it symmetric,” or “let blocks fall like gravity”). Most recent systems treat ARC as a language problem, turning grids into text and using LLMs. This paper flips that idea and treats ARC as a vision problem. The authors build a model called Vision ARC (VARC) that learns to map one image to another, like a “photo editor” that’s good at spotting and applying patterns.
Objectives
The paper explores three main questions, explained simply:
- Can we solve ARC puzzles by looking at them directly, using computer vision, instead of turning them into text?
- What “visual instincts” (like understanding positions, scale, and local neighborhoods) help a model learn general rules from very few examples?
- Can a model trained only on ARC data (not on huge internet datasets) reach human-like performance on new, unseen puzzles?
Methods and Approach
Think of the model as a careful artist learning from small examples before tackling a new puzzle.
- Treat puzzles as image-to-image translation:
- Each grid is an “image” with colored pixels. The model’s job is to turn an input image into the correct output image, one pixel at a time, like coloring-by-numbers with rules.
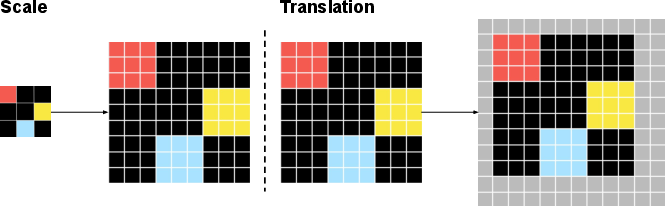
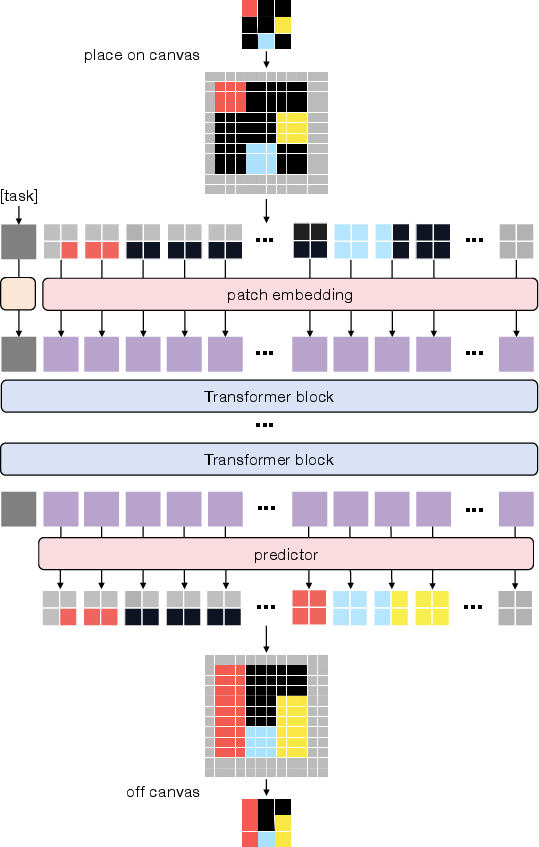
- Use a “canvas” to think visually:
- Instead of using the small raw grid directly, the input is placed onto a larger, fixed “canvas” (like drawing on a big notebook page). The model can shift (translate) or resize (scale) the input on the canvas. This teaches the model that the rule should still work if the pattern is moved or zoomed—a lot like how you recognize a face whether it’s close-up or far away.
- Vision Transformer (ViT) as the main tool:
- The ViT looks at the canvas in small squares called “patches” (similar to tiles on a floor). It processes these patches to learn local details and how patterns repeat across the image. This builds “visual priors”:
- Locality: nearby pixels often matter together.
- Translation invariance: rules shouldn’t change just because the picture is shifted.
- Scale invariance: rules shouldn’t change just because the picture is bigger or smaller.
- Positional understanding in 2D:
- The model learns where each patch is on the canvas with 2D coordinates, like knowing a tile’s row and column. This helps it reason about shapes and symmetry better than a simple 1D sequence.
- Two stages of learning:
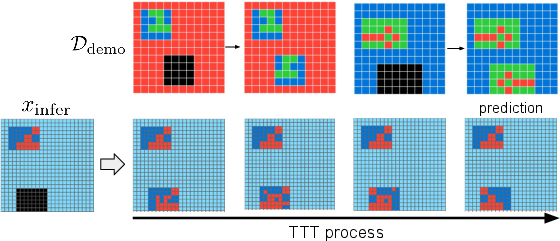
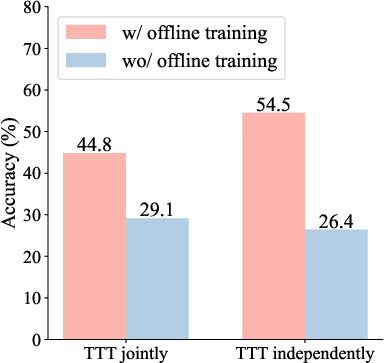
- Offline training: The model is trained from scratch on 400 ARC training tasks and extra examples generated from them (no internet pretraining). It learns general visual “common sense” from these.
- Test-time training: When it faces a brand-new puzzle with just a few examples (2–4), it quickly adapts to that specific task by practicing on those examples with simple transformations like flips, rotations, and color swaps. This is like warming up with the hints you’re given, right before answering.
- Multi-view inference:
- The model tries many slightly different “views” (different shifts and scales on the canvas). It then chooses the most consistent answer across views using majority voting—like asking many friends and going with the most agreed-on solution. This is especially helpful because even one wrong pixel can make the whole answer count as incorrect in ARC.
Main Findings and Why They Matter
- Vision-first works very well:
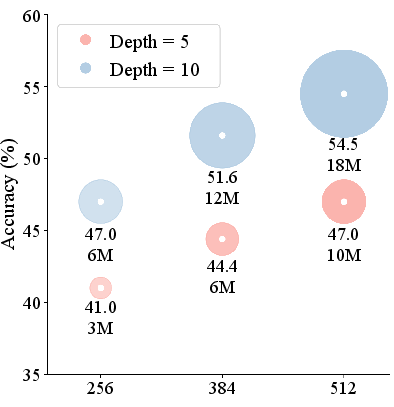
- VARC gets 54.5% accuracy on ARC-1 with a single 18-million-parameter model trained only on ARC data. By combining models (an ensemble of ViT and U-Net), accuracy rises to 60.4%, which matches average human performance reported for ARC-1 (around 60.2%).
- Beats other “trained-from-scratch” systems:
- VARC outperforms recent recurrent reasoning models (which also avoid internet pretraining) by around 10 percentage points on ARC-1.
- Competitive with big LLMs:
- Despite using far fewer parameters and no internet-scale training, VARC’s results are in the same ballpark as popular LLM-based methods reported at the time.
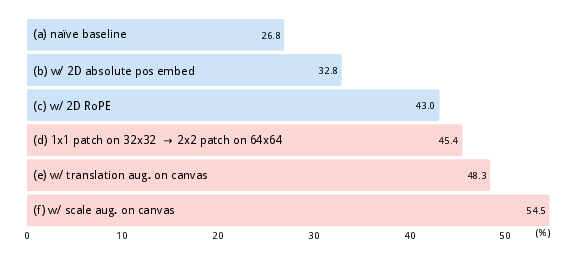
- Visual priors are critical:
- Adding the canvas, 2D positions, patch-based processing, and translation/scale augmentation together boosted accuracy by 27.7 points compared to a naive baseline. Scale augmentation alone gave a big jump because the ViT doesn’t naturally understand size changes without seeing them during training.
- Multi-view helps a lot:
- Checking many views and voting increased pass@1 accuracy from 35.9% to 49.8%, and supports the pass@2 evaluation used in ARC.
- The model seems to “look” in sensible ways:
- Attention visualizations show the model learns to focus on the right pixels to copy or extend patterns (like rays spreading in eight directions), and task embeddings cluster puzzles with similar ideas (like symmetry or logic-like coloring), suggesting it’s learning meaningful abstractions.
Implications and Impact
This work shows that ARC, though often treated like a language task, is naturally visual—and solving it using vision can be powerful. The key impact:
- Visual common sense matters: Models can learn abstract rules from pictures using simple, human-like visual instincts: position, locality, and invariance to shifts and scale.
- Strong results without huge data: A relatively small model, trained only on ARC, can reach human-level average performance on ARC-1, hinting that good design and test-time adaptation can beat sheer scale.
- Encourages multi-modal thinking: Humans use both words and images to reason. This paper adds a solid vision approach to ARC, opening doors for future systems that combine strong visual and linguistic reasoning.
- Future directions: Using richer visual priors, better architectures, and possibly image pretraining could push performance higher and make AI better at learning rules from just a few examples—more like how people do it.
In short, the paper reframes ARC as a vision problem and shows that seeing—and learning from what you see—can be just as important as reading, especially for puzzles built from pictures.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed to guide concrete follow-up work:
- Test-time training (TTT) scope and parameter updates are unspecified: clarify which parameters are adapted (task token only vs partial/full backbone), and ablate parameter-efficient adapters (e.g., LoRA, biases-only) vs full fine-tuning for stability, speed, and accuracy.
- Strong reliance on TTT for performance (and ~70s per task on a single GPU) raises efficiency concerns; quantify accuracy–latency trade-offs, compare to LLM/VLM inference times, and explore faster adaptation (e.g., implicit adaptation, feature modulation, cached meta-initializations).
- Heavy multi-view inference (510 random views) is a major accuracy driver; determine the minimal view budget, develop principled view selection, or replace with built-in equivariance (e.g., group-equivariant CNNs/Transformers, canonicalization) to avoid test-time ensembling.
- The method assumes translation/scale invariance via augmentation; analyze tasks where absolute position/size is part of the rule to see if these priors hurt performance, and explore adaptive or task-conditioned invariance rather than hard-coded invariance.
- Dependence on RE-ARC augmentation (∼400k pairs total) is not disentangled; report accuracy without RE-ARC, with fewer RE-ARC samples, and per-augmentation ablations to quantify gains and potential leakage or overfitting to the augmented distribution.
- ARC-2 generalization is weak (8.3/11.1); diagnose domain shift (task taxonomy, visual statistics, rule types), report per-category performance, and evaluate pretraining strategies (synthetic rule corpora, self-supervised image pretraining, meta-learning across procedurally generated tasks).
- Canvas design choices (size 64×64, background as color C+1, patch size 2×2) are fixed; test sensitivity to canvas size/aspect, background encoding (special token vs color), and patch size, and consider learnable/resizable canvases or spatial transformers for better scaling and placement handling.
- Color handling may induce spurious color dependence; incorporate and ablate color permutation during offline training (not only TTT), explore color-equivariant embeddings, and evaluate robustness to color relabeling on held-out tasks.
- Majority voting requires exact grid equality; investigate probabilistic aggregation (e.g., pixelwise uncertainty, structured CRF-like refinement), beam search in output space, or confidence calibration to reduce brittle all-or-nothing failure.
- Lack of object-centric inductive biases; assess whether slot/object-centric encoders, connected-component reasoning, or relational modules (graph networks) improve rules involving grouping, counting, symmetry, and connectivity.
- No explicit compositionality or program induction analysis; devise probes to test whether the model composes primitives (mirror, translate, flood-fill, count), and evaluate systematic generalization on ConceptARC or curated compositional splits.
- Overfitting for larger ViTs (66M) suggests limited data constraints; explore stronger regularization, meta-learning, synthetic data scaling, and pretraining on rule-rich synthetic corpora with held-out compositions.
- Task token conditioning is coarse; compare to demo-conditioned architectures (e.g., cross-attention over demonstration pairs, neural interpreters, hyper-networks) that condition directly on examples rather than learned per-task embeddings.
- Auxiliary-task strategy at TTT (separate tokens for flips/rotations/color permutations) is ad hoc; test shared-token adaptation with explicit equivariance constraints or group normalization, and quantify when separate vs shared tokens help.
- Single-view performance is far below multi-view; train with consistency regularization across augmentation views to close the train–test augmentation gap and reduce reliance on post-hoc view ensembling.
- Evaluation is centered on pass@2; report comprehensive pass@1, calibration, and seed sensitivity analyses, and quantify the contribution of each component (TTT, multi-view, ensemble) to pass@1 vs pass@2.
- Failure-mode taxonomy is missing; provide per-task and per-rule-type breakdowns (e.g., reflection, symmetry, gravity, counting, pattern extension), qualitative error categories, and diagnostic datasets to target specific weaknesses.
- Scalability beyond ARC constraints is untested; assess generalization to larger grids (>30×30), more colors, and variable aspect ratios, and evaluate performance under increased clutter and multiple objects.
- Iterative reasoning capacity is unclear; test tasks requiring unbounded or variable-length propagation (e.g., repeated growth, path tracing) and compare feedforward inference to learned iterative refinement modules at inference time.
- Robustness to small perturbations is unknown; evaluate sensitivity to noise, small spatial jitters, partial occlusions, or distractor patterns to gauge stability of the learned visual priors.
- Integration with language or multimodal cues is not explored; investigate whether lightweight textual hints, symbolic sketches, or meta-prompts can improve few-shot adaptation without internet-scale pretraining.
- Reproducibility and hyperparameter sensitivity for TTT are underreported; release and ablate TTT schedules (steps, LR, augmentations, auxiliary-task counts), early stopping criteria, and seed robustness to ensure stable deployment.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed with today’s tooling, leveraging the paper’s core methods: canvas-based image-to-image formulation, visual inductive biases (2D positional embeddings, patchification, translation/scale invariance), few-shot test-time training (TTT), and multi-view inference.
- Bold, few-shot visual post-processing for segmentation — healthcare, geospatial, robotics, software
- Enabled by: VARC’s image-to-image translation with 2D positional embeddings and TTT can learn dataset- or site-specific morphological rules (e.g., hole-filling, island removal, dilation/erosion) from 2–4 examples.
- Tool/workflow: “Auto-PostProc” module that fine-tunes on a handful of input/output mask pairs and plugs into existing segmentation pipelines (e.g., radiology, satellite imaging, warehouse robotics).
- Assumptions/dependencies: Transformations are deterministic and local/global-structure preserving; pixel/mask outputs are the desired endpoint; requires a GPU for ~1-minute TTT per task and 2–4 curated examples.
- Rapid, on-device customization of visual transforms — edge AI, privacy-preserving AI, enterprise IT
- Enabled by: Small ViT/U-Net backbones trained from scratch plus per-task TTT allow device-local adaptation without sending data to the cloud.
- Tool/workflow: “On-device TTT Runner” that learns user-specific visual mapping rules (e.g., private document redaction layouts, stylized overlays) from a few demos.
- Assumptions/dependencies: Device must support short fine-tuning; demos must be representative; memory footprint must fit device constraints.
- GUI and RPA layout retargeting from a few examples — software, productivity, accessibility
- Enabled by: Canvas formulation and translation/scale augmentation make the model robust to UI widget shifts while learning pixel-accurate transformations (e.g., dark-mode conversion, color remapping, grid alignment).
- Tool/workflow: “LayoutOps” plug-in that learns a UI-to-UI transform from 2–4 before/after screenshots and applies it across an app with multi-view voting for reliability.
- Assumptions/dependencies: UI is rendered as raster; changes are mostly systematic (not free-form redesigns); maintain task-specific tokens per app/theme.
- Few-shot defect-markup standardization in manufacturing inspection — manufacturing, quality control
- Enabled by: Image-to-image learning of rule sets that transform raw detections into standardized visual annotations (e.g., snapping to grid, symmetrizing bounding polylines).
- Tool/workflow: “DefectMark Normalize” that TTT-adapts per line or per client, with multi-view inference to reduce single-pixel failure risk in pass/fail decisions.
- Assumptions/dependencies: Defect post-process is predictable and grid-friendly; requires 2–4 exemplars of desired markup; latency budget permits TTT.
- Rapid prototyping of discrete-visual reasoning benchmarks — academia, ML benchmarking
- Enabled by: The VARC training recipe (task tokens, canvas, 2D positional embeddings, augmentation, TTT) provides a strong, reproducible vision-only baseline for few-shot reasoning tasks.
- Tool/workflow: “GridReason SDK” for researchers to create ARC-like tasks, run ablations (single- vs multi-view), and compare to LLM or recurrent baselines.
- Assumptions/dependencies: Tasks can be expressed as deterministic grid-to-grid mappings; access to ARC/RE-ARC or similar datasets.
- Curriculum and tooling for teaching visual concepts (symmetry, reflection, tiling) — education
- Enabled by: VARC demonstrates human-aligned concepts (symmetry, reflection, gravity) learned from few demos; teacher can craft micro-demos and see the model generalize.
- Tool/workflow: An interactive classroom app that visualizes attention maps and step-by-step improvements during TTT to explain abstract visual rules.
- Assumptions/dependencies: Classroom devices or a server GPU; curated small demo sets per concept.
- Content creation for pixel-art and iconography — creative tools, gaming
- Enabled by: Patchified canvas can learn stylistic pixel transforms (palette swaps, symmetry completions, border stylings) from a few before/after tiles.
- Tool/workflow: “Pixel-Style Learner” that TTT-adapts to an artist’s style and batch-applies it to sprite sheets; multi-view voting ensures consistent whole-sprite outputs.
- Assumptions/dependencies: Transformations are rule-like and reproducible; training exemplars must reflect the desired style variation.
- Robust grid/schematic normalization — EDA/PCB, CAD, mapping
- Enabled by: Translation/scale invariance and majority voting stabilize transformations on discrete diagrams (e.g., line thickening, symbol normalization, snap-to-grid).
- Tool/workflow: A normalization step in CAD/EDA/GIS pipelines that learns client-specific conventions with few demos.
- Assumptions/dependencies: Data are rasterized or rasterizable; rules are mostly geometric/structural, not semantic reinterpretations.
- Cognitive-science probes of visual abstraction — academia (cogsci, neuroscience)
- Enabled by: Task tokens and t-SNE analyses of learned task embeddings expose how visual rules cluster, providing a tool to design and diagnose human/AI experiments.
- Tool/workflow: “VARC Lab Pack” with scripts for creating matched human/AI tasks and visualizing attention and token embeddings during learning.
- Assumptions/dependencies: Ethical and reproducibility protocols; experimental control over task difficulty and concept overlap.
- Compute-efficient, language-free baseline for AGI evaluation — policy, standards, evaluation labs
- Enabled by: Demonstrated 60.4% on ARC-1 via small models trained from scratch; offers a non-internet-pretrained, vision-only baseline for capability audits.
- Tool/workflow: A standard evaluation harness that reports single- vs multi-view, pass@1 vs pass@2, and TTT configurations for fair cross-system comparisons.
- Assumptions/dependencies: Agreement on ARC variants and evaluation protocols; availability of compute for TTT but without massive pretraining.
Long-Term Applications
These applications are plausible but require further research, scaling, or integration (e.g., larger visual pretraining, multimodal reasoning, more complex data).
- Multimodal abstract reasoning agents (vision + language) — robotics, software, education
- Enabled by: Combine VARC’s visual inductive biases with LLMs’ symbolic reasoning to handle instructions plus visual demos (e.g., “mirror this pattern and count red tiles”).
- Tool/workflow: An agent that infers a transformation from a few pictures and natural-language hints, then verifies its outputs via multi-view checks.
- Assumptions/dependencies: Robust multimodal alignment; avoiding language hallucinations; safety and interpretability for closed-loop actions.
- Few-shot visual program induction for traditional image processing — vision, MLOps
- Enabled by: Treat transformations as latent programs learned from demos, then distill to executable operators (e.g., sequences of morphological ops) for auditability.
- Tool/workflow: “RuleDistill” that maps learned VARC behaviors into interpretable pipelines, enabling validation, certification, and fast runtime.
- Assumptions/dependencies: Reliable extraction of symbolic approximations; guarantees on equivalence and failure modes.
- Per-hospital/per-scanner adaptation in medical imaging — healthcare
- Enabled by: TTT adaptation to local acquisition artifacts and annotation styles for converting raw segmentations into clinically acceptable masks.
- Tool/workflow: A hospital-specific post-processing learner that undergoes periodic re-adaptation as scanners and protocols change.
- Assumptions/dependencies: Rigorous clinical validation; regulatory approval; privacy-preserving on-prem compute; robust monitoring for drift.
- Adaptive factory-line transformation learning — advanced manufacturing, robotics
- Enabled by: Continuous TTT to learn new quality rules or retooling adjustments from a handful of exemplars per product revision.
- Tool/workflow: An online adaptation service that proposes transformations, auto-evaluates with synthetic multi-view stresses, and defers edge cases to humans-in-the-loop.
- Assumptions/dependencies: Strong data and change-control pipelines; latency budgets; fallback to human review for ambiguous cases.
- Personalized UI assistants that learn workflows from a few demonstrations — productivity, accessibility
- Enabled by: Generalize from a user’s few annotated screens to automate recurrent visual tasks (resizing panels, theming widgets, rearranging dashboards).
- Tool/workflow: A desktop/phone assistant that records 2–4 “before/after” transformations and then applies them robustly across apps.
- Assumptions/dependencies: OS-level sandboxing and permissions; robustness to OS updates; explainability for user trust.
- Visual reasoning for 3D and physics-like tasks — simulation, gaming, robotics
- Enabled by: Extending canvas/visual priors to volumetric or multi-view inputs; learning discrete rule-like behaviors (e.g., pile stability, symmetry in 3D).
- Tool/workflow: “3D-VARC” for few-shot adaptation in voxel maps or depth frames (e.g., assembling blocks to target shapes).
- Assumptions/dependencies: Efficient 3D tokenization; scale/rotation priors in 3D; data and compute to support TTT at volume.
- Map/schematic translation across standards — geospatial, civil engineering, utilities
- Enabled by: Learn cross-standard visual translations (symbols, line codes, color schemes) from a small set of paired maps/schematics.
- Tool/workflow: A standards-bridging tool that outputs both raster and vector approximations with confidence scores.
- Assumptions/dependencies: Access to a few paired exemplars; handling of rare or ambiguous symbols; optional human review loop.
- Safety auditing and robustness stress-testing of visual reasoning systems — policy, safety, certification
- Enabled by: Multi-view inference and pixel-level correctness criteria provide stringent stress tests that can be standardized for non-language reasoning.
- Tool/workflow: A certification suite that probes invariances (scale, translation), adversarial color permutations, and consistency under minor perturbations.
- Assumptions/dependencies: Shared benchmark curation; consensus on pass/fail criteria and acceptable failure rates.
- Large-scale pretraining for abstract visual priors — core AI research
- Enabled by: Pretrain VARC-like backbones on curated synthetic corpora of abstract visual rules, then TTT on new tasks for stronger generalization than ARC-only.
- Tool/workflow: A “Synthetic Abstraction Pretrain” dataset generator (mix of symmetry/reflection/tiling/gravity motifs) with curriculum scheduling.
- Assumptions/dependencies: Avoiding overfitting to synthetic biases; measuring transfer to natural visual tasks and ARC-like benchmarks.
- Human-in-the-loop rule discovery and documentation — enterprise knowledge capture
- Enabled by: Surface attention maps, task-token clusters, and candidate rule summaries that humans can edit and ratify as internal standards.
- Tool/workflow: “RuleStudio” that captures few-shot demos, proposes visual rules, and exports human-readable specs plus runnable transforms.
- Assumptions/dependencies: Usable visualizations; alignment between learned rules and domain semantics; governance for change management.
- Educational assessment of non-verbal reasoning — education policy, testing
- Enabled by: Deploy ARC-like, language-agnostic tasks to assess students’ visual abstraction and generalization, with VARC as a reference scorer or item generator.
- Tool/workflow: A test suite that adapts difficulty via TTT signals (learnability from few demos) and logs interpretable failure modes.
- Assumptions/dependencies: Psychometric validation; accessibility; guardrails to prevent unintended bias or over-reliance on pattern familiarity.
Notes on cross-cutting assumptions and dependencies
- Problem fit: Best for deterministic image-to-image mappings on discrete or rasterizable grids; performance on natural, noisy images requires careful preprocessing or further pretraining.
- Data needs at deployment: 2–4 representative input/output demos per new task; the quality of demos drives generalization.
- Compute/latency: TTT typically ~70 seconds per task on a single GPU in the paper; production systems must budget this cost or amortize via caching and reuse of task tokens.
- Robustness: Multi-view inference substantially improves reliability in tasks where any single-pixel error invalidates the output; plan for this in deployment.
- Governance: In regulated settings (healthcare, aerospace), add human oversight, interpretability (rule distillation), and monitoring for distribution shifts.
Glossary
- Abstraction and Reasoning Corpus (ARC): A benchmark of few-shot abstract reasoning tasks over colored grids designed to study generalization and concept learning. "The Abstraction and Reasoning Corpus (ARC) is designed to promote research on abstract reasoning, a fundamental aspect of human intelligence."
- ARC-1: The first ARC benchmark split, commonly used for training and evaluation with 400 tasks. "VARC achieves 54.5\% accuracy on the ARC-1 benchmark, using a small model with only 18 million parameters."
- ARC-2: A newer ARC benchmark split used for further evaluation of systems’ generalization. "We also report final results on ARC-2~\cite{chollet2025arcagi2newchallengefrontier}."
- attention maps: Visualizations of attention weights showing which input positions a model focuses on when processing a query. "attention maps for a single pixel across different layers."
- canvas: A fixed-size image-like grid onto which inputs are placed and geometrically transformed to enable visual processing and augmentations. "We define the concept of a ``canvas''."
- CLEVR: A synthetic visual reasoning dataset designed to test compositional and relational reasoning in images. "such as VQA~\cite{antol2015vqa, zhang2016balancing, goyal2017making}, CLEVR~\cite{johnson2017clevr}, and Winoground~\cite{thrush2022winoground}."
- convolutional neural networks: Neural architectures that use convolutions to capture local spatial patterns; widely used in vision. "Beyond ViT, we also study the more classical vision-based architecture, \ie, convolutional neural networks \cite{6795724}."
- ensembling: Combining predictions from multiple models to improve overall accuracy and robustness. "Combining VARC models through ensembling \cite{krizhevsky2012imagenet} further improves accuracy to 60.4\%"
- image-to-image translation: Mapping an input image to an output image, often formulated as per-pixel prediction. "we formulate ARC within a vision paradigm, framing it as an image-to-image translation problem."
- inductive biases: Built-in assumptions or structural preferences in models that guide learning (e.g., locality, translation invariance). "Like convolution, it incorporates several critical inductive biases in vision: most notably, {locality} (\ie, grouping nearby pixels) and {translation invariance} (\ie, weight sharing across locations)."
- inductive reasoning: Inferring general rules from specific examples and demonstrations. "Representative methods may involve inductive reasoning \cite{wang2024hypothesis,berman2024record536, tang2024code,berman2024arcagi}"
- LLMs: Transformer-based models trained on massive text corpora, often used for few-shot reasoning via prompts. "Common approaches to ARC treat it as a language-oriented problem, addressed by LLMs or recurrent reasoning models."
- majority voting: Aggregating multiple outputs by selecting the solution that appears most frequently among predictions. "Predictions from different views are consolidated by majority voting \cite{akyurek2025surprising}."
- multi-view inference: Evaluating a model across many augmented versions (views) of the input and aggregating the results. "Analogously, we adopt multi-view inference to improve accuracy, where the views are sampled with different augmentations."
- nearest-neighbor interpolation: A resizing method that duplicates pixels without blending, preserving discrete values. "This is analogous to nearest-neighbor interpolation in natural images."
- pass@2 accuracy: A metric where a task is counted as correct if any of two submitted solutions is correct. "The ARC benchmark by default adopts the pass@2 accuracy metric: \ie, two different solutions can be produced for evaluation, and a task is considered correct if one is correct."
- patchification: Dividing an image into non-overlapping patches that serve as tokens for processing by a Transformer. "Conceptually, patchification can be viewed as a special form of convolution."
- per-pixel cross-entropy loss: A categorical loss computed independently at each pixel for image-to-image tasks. "The overall objective function is simply the per-pixel cross-entropy loss \cite{long2015fully}:"
- positional embeddings: Learnable vectors encoding spatial positions (absolute or relative) to inform attention mechanisms. "Formally, we adopt separable 2D positional embeddings, following \cite{chen2021empirical}:"
- Rotary positional embedding (RoPE): A positional encoding technique that encodes relative positions via rotations in attention. "This can be applied both to additive positional embeddings for encoding absolute positions and to the encoding of relative positions (\eg, RoPE \cite{su2023roformerenhancedtransformerrotary})."
- scale augmentation: Randomly resizing inputs during training to encourage robustness to size changes. "Scale augmentation: Given a raw input, we randomly resize it by an integer scaling ratio , duplicating each raw pixel into "
- scale invariance: A property where a model’s predictions remain stable under changes in the input’s scale. "These priors include 2D spatial locality, translation invariance, and scale invariance."
- semantic segmentation: Per-pixel classification of an image into semantic categories. "We frame the problem as per-pixel classification, analogous to the semantic segmentation problem \cite{long2015fully}."
- task token: A learnable embedding representing the current task that conditions the model’s predictions. "The network takes an image as input, conditioned on a task token associated with the task ."
- test-time training (TTT): Adapting a model on the given test task’s demonstrations before making predictions. "we perform test-time training \cite{bottou1992locallearning,joachims1999transductive,Sun2020TTT,akyurek2025surprising,wang2025hierarchicalreasoningmodel,jolicoeurmartineau2025morerecursivereasoningtiny} to adapt the model to the task"
- t-SNE: A technique for visualizing high-dimensional embeddings in a low-dimensional (typically 2D) space. "We visualize these 400 embeddings in the 2D space by t-SNE \cite{maaten2008visualizing}"
- translation augmentation: Randomly shifting inputs on the canvas to promote robustness to spatial translations. "Translation augmentation: given the scaled grid, we randomly place it on the fixed-size canvas."
- translation invariance: A property where a model’s outputs are unaffected by spatial shifts of the input. "These priors include 2D spatial locality, translation invariance, and scale invariance."
- transductive reasoning: Reasoning that leverages information from the specific test instances or tasks directly to make predictions. "Representative methods may involve inductive reasoning \cite{wang2024hypothesis,berman2024record536, tang2024code,berman2024arcagi}, transductive reasoning \cite{akyurek2025surprising, franzen2025productexpertsllmsboosting, puget2024arc}"
- U-Net: A convolutional encoder–decoder architecture with skip connections designed for image-to-image tasks like segmentation. "Specifically, we adopt the U-Net model \cite{ronneberger2015unetconvolutionalnetworksbiomedical}, a hierarchical convolutional network."
- Vision ARC (VARC): The paper’s proposed vision-centric framework that treats ARC as image-to-image translation. "Our framework, termed \mbox{Vision ARC} (VARC), achieves 60.4\% accuracy on the \mbox{ARC-1} benchmark"
- vision-LLMs (VLMs): Models that jointly process images and text for tasks involving both modalities. "These methods have evolved into modern vision-LLMs (VLMs, \eg, \cite{alayrac2022flamingo, li2022blip,liu2023visual}), in which images are converted into tokens and processed jointly with text."
- Vision Transformer (ViT): A Transformer architecture that operates on image patches instead of pixels, enabling global attention. "such as a vanilla Vision Transformer (ViT), to perform image-to-image mapping."
Collections
Sign up for free to add this paper to one or more collections.