Abstract: 3D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time novel view synthesis. As an explicit representation optimized through gradient propagation among primitives, optimization widely accepted in deep neural networks (DNNs) is actually adopted in 3DGS, such as synchronous weight updating and Adam with the adaptive gradient. However, considering the physical significance and specific design in 3DGS, there are two overlooked details in the optimization of 3DGS: (i) update step coupling, which induces optimizer state rescaling and costly attribute updates outside the viewpoints, and (ii) gradient coupling in the moment, which may lead to under- or over-effective regularization. Nevertheless, such a complex coupling is under-explored. After revisiting the optimization of 3DGS, we take a step to decouple it and recompose the process into: Sparse Adam, Re-State Regularization and Decoupled Attribute Regularization. Taking a large number of experiments under the 3DGS and 3DGS-MCMC frameworks, our work provides a deeper understanding of these components. Finally, based on the empirical analysis, we re-design the optimization and propose AdamW-GS by re-coupling the beneficial components, under which better optimization efficiency and representation effectiveness are achieved simultaneously.
The paper introduces a decoupled optimization framework using Sparse Adam, Re-State Regularization (RSR), and Decoupled Attribute Regularization (DAR) to improve 3DGS.
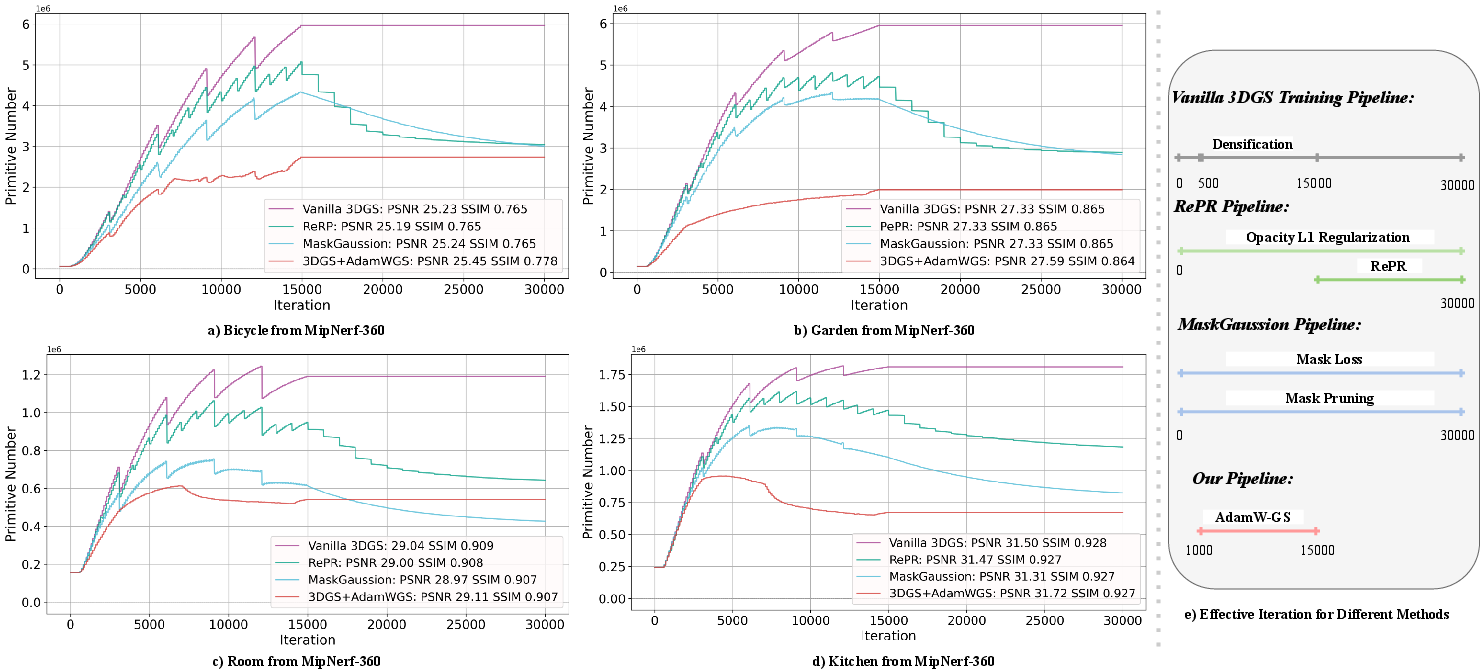
It demonstrates reduced primitive redundancy (over 40% fewer primitives) and faster training times while maintaining high-quality reconstruction metrics.
The method enables controllable regularization and effective pruning, offering robust, stable, and efficient optimization for explicit 3D scene representations.
Decoupling Optimization in 3D Gaussian Splatting (3DGS): Summary and Analysis of "A Step to Decouple Optimization in 3DGS" (2601.16736)
Introduction: Motivation and Context
The paper addresses fundamental deficiencies in the optimization of 3D Gaussian Splatting (3DGS) pipelines for novel view synthesis. Although 3DGS leverages explicit primitive-based radiance parameterizations and achieves state-of-the-art synthesis efficiency compared to implicit approaches, optimization protocols are inherited from deep neural networks without regard for the physical significance of scene primitives. Standard synchronous attribute updates and the use of the Adam optimizer, originally developed for DNNs, induce coupling effects: (i) update-step coupling (implicit optimizer state rescaling) and (ii) gradient coupling (regularization effectiveness governed by the optimizer’s second moment). These couplings obscure the role of optimizer states, often leading to inefficient updates and suboptimal regularization.
Methodological Overview: Decoupling the Optimization Mechanism
The authors conduct a rigorous analysis of coupling effects in 3DGS optimization, culminating in a decomposition of the process into three components:
Sparse Adam: Updates attributes of only visible primitives, effectively filtering out invisible ones and producing asynchronous optimization.
Re-State Regularization (RSR): Periodically rescaling the optimizer moments, allowing deliberate activation of regularization via explicit moment attenuation.
Decoupled Attribute Regularization (DAR): Reformulates attribute regularization decoupled from adaptive gradient moments, yielding more controllable and stable regularization intensity.
These components are systematically evaluated under both vanilla 3DGS and the stochastic 3DGS-MCMC framework. Coupling and decoupling effects are empirically studied on extensive benchmarks, including Mip-NeRF360, Tanks and Temples, and Deep Blending datasets.
Sparse Adam: Stability and Exploration Characteristics
Sparse Adam eliminates implicit updates for invisible primitives. Quantitative analysis shows it leads to a more stable primitive activation pattern (fewer dead primitives) and improved optimization efficiency. However, Sparse Adam in isolation results in less exploration and lower reconstruction metrics.
Figure 1: Primitive number evolution in four optimization strategies, with AdamW-GS demonstrating dominant redundancy removal behavior and controlled densification.
Adam’s synchronous updates—by contrast—maintain higher regularization activation (more moment rescaling, higher dead primitive count), but induce unnecessary optimizer state changes for invisible primitives.
Re-State Regularization (RSR): Moment Manipulation for Regularization Control
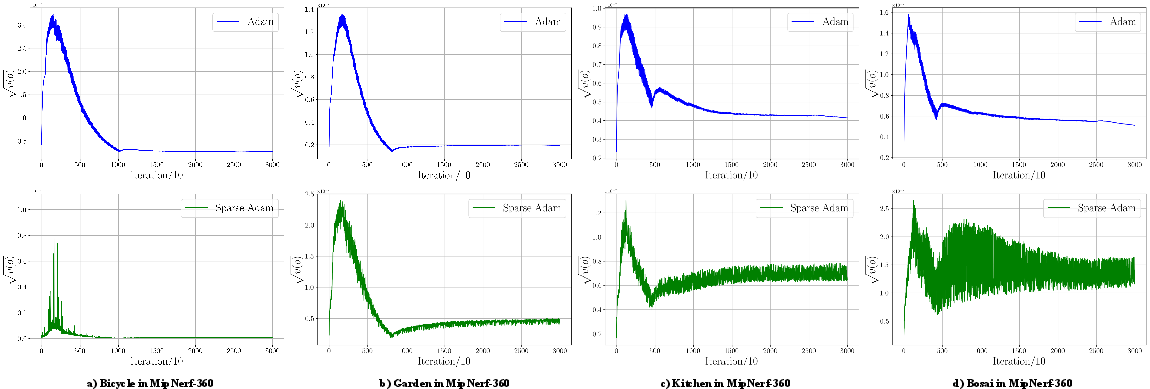
RSR systematically attenuates optimizer moments at uniform intervals via a milestone-style State Sampling Schedule (StSS). This intervention modulates attribute regularization strength by providing explicit control over optimizer state activation. Analysis reveals that moment rescaling via RSR can strongly amplify regularization, reducing redundant primitives without explicit pruning mechanisms.
Figure 2: Visualization of the second moment v across valid primitives. Adam-induced moment rescaling yields stronger regularization effects than Sparse Adam.
The standard 3DGS pipeline couples regularization losses (opacity/scaling L1) with adaptive gradients, rendering regularization intensity dependent on the optimizer’s second moment, and leading to either over- or under-effective regularization modulated by photometric loss gradients. DAR resolves this by explicitly decoupling gradients from moment statistics, employing a formulation in which regularization updates are rescaled independently—often as ∇R/v^. This approach yields reliable attribute control, robust to the magnitude of regularization, and allows per-primitive normalized penalties.
AdamW-GS: A Recoupled Optimization Protocol
Building on these insights, the authors propose AdamW-GS, an optimization framework that integrates Sparse Adam (asynchronous attribute updates), RSR (active moment control), and DAR (decoupled regularization) in a tightly coupled protocol. AdamW-GS can be flexibly instantiated for vanilla 3DGS, 3DGS-MCMC, and variants such as MaskGaussion, Taming-3DGS, and Deformable Beta Splatting.
Experimental Results: Reconstruction Quality and Efficiency
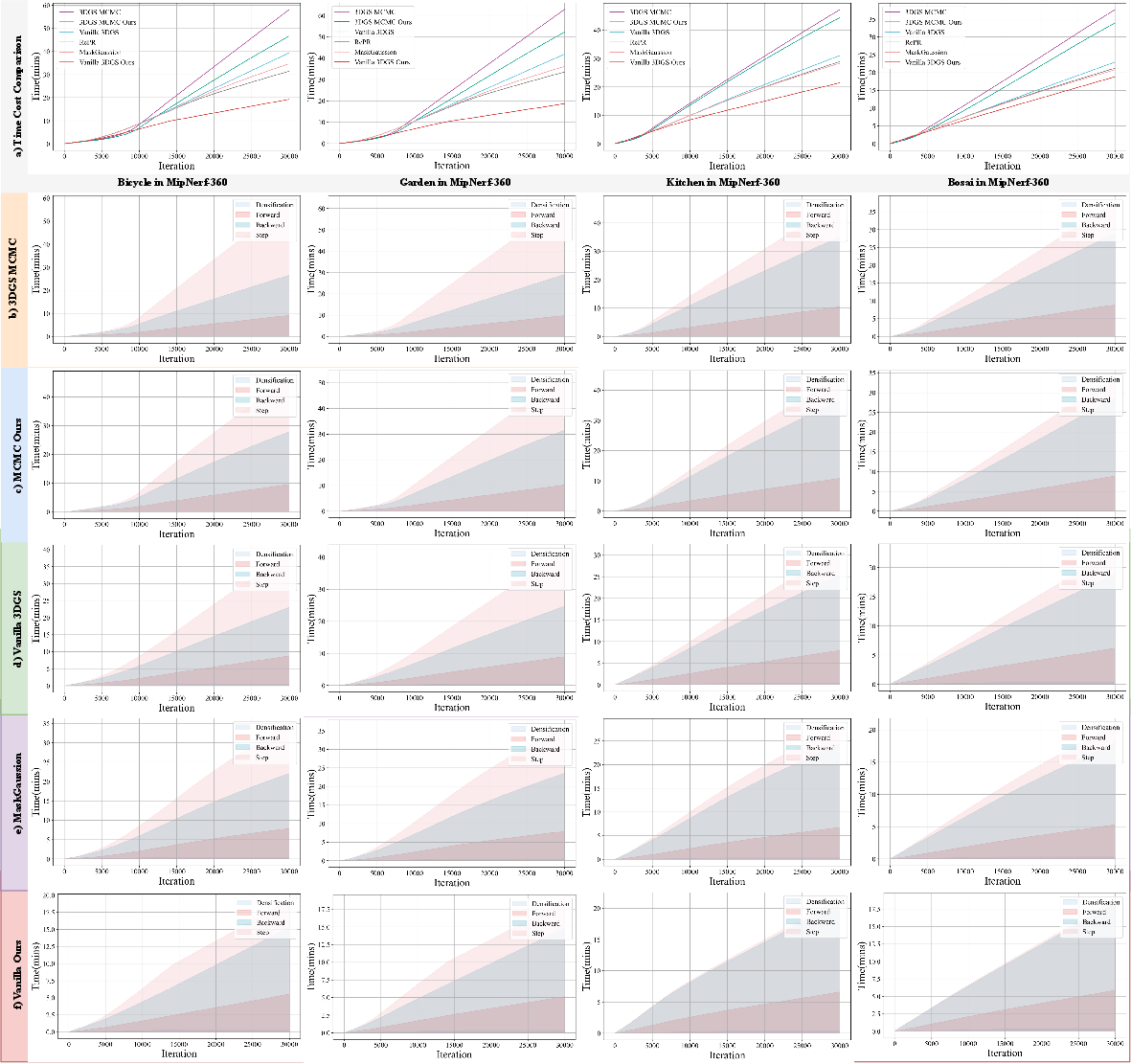
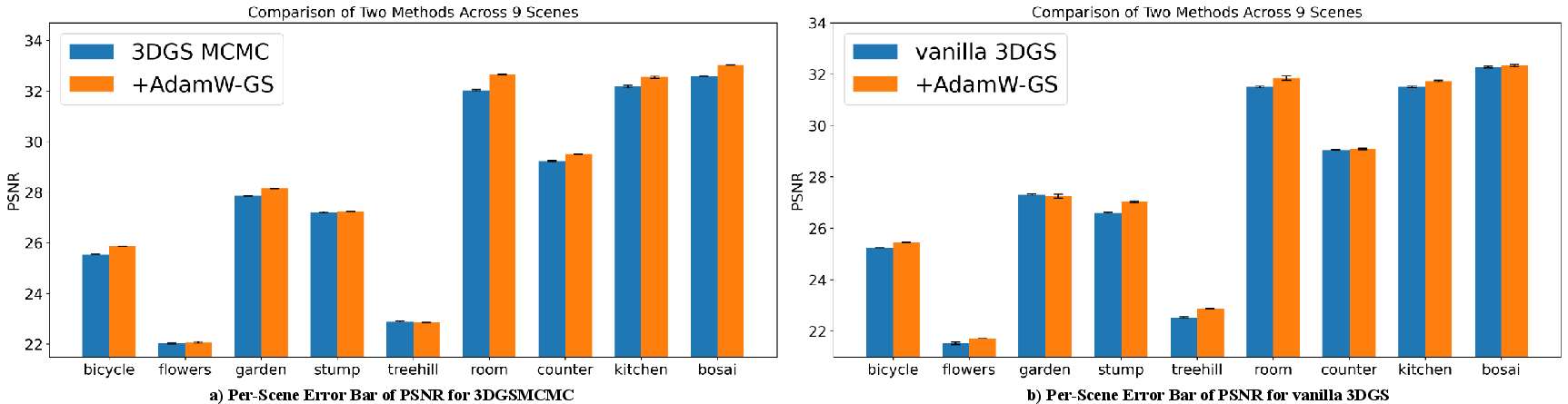
Experiments show that AdamW-GS achieves superior results on PSNR, SSIM, and LPIPS compared to vanilla pipelines, with drastic reductions in primitive redundancy (often >40% fewer primitives), requiring no explicit pruning. The method is robust across scene types and datasets, consistently exhibiting efficient optimization trajectories, faster training times, and improved quality.
Figure 3: Qualitative rendering results: AdamW-GS displays preserved scene details and effective redundancy removal.
Figure 4: Runtime cost comparison: AdamW-GS demonstrates significant acceleration due to moment control and reduced primitive counts.
Figure 5: Error bar plot for PSNR across nine scenes, demonstrating AdamW-GS’s low variance and consistently strong reconstruction.
Notably, learning-based pruning strategies (e.g., MaskGaussion) with AdamW-GS avoid destructive pruning behavior and realize additional performance gains. Taming-3DGS and Deformable Beta Splatting similarly benefit from the protocol, enabling memory savings and improved rendering.
Failure Modes and Limitations
While AdamW-GS provides substantial optimizational improvements, it does not address fundamental limitations of 3DGS pipelines themselves: boundary artifacts in under-constrained regions, persistent floaters, and lack of geometric priors. The method is less effective when the pipeline is heavily overfitting or in the presence of pronounced geometric outliers.
Figure 6: Visualization of failure cases including boundary artifacts, background blurriness, and geometric inconsistencies.
Implications, Extensions, and Future Directions
The decoupling approach revisits adaptive optimization in explicit 3D representations, critically addressing optimizer-state coupling that arises from naively inherited DNN protocols. AdamW-GS demonstrates that effective regularization and pruning can be integrated at the optimizer level, improving both quality and efficiency. Future avenues include:
Adaptive and data-driven schedules for RSR and DAR hyperparameters.
Generalization to other primitive types and radiance parameterizations.
Systematic exploration of additional strategies for boosting exploration without introducing instability.
Conclusion
This work systematically decouples core mechanisms in 3DGS optimization, resulting in AdamW-GS—an optimizer protocol that yields controllable regularization, removes redundancy without explicit pruning, and accelerates training. The methodology and empirical validation suggest that optimization-level interventions can yield substantial gains in explicit 3D scene representation. Further investigation into adaptive schedules and handling pipeline intrinsic failures may drive future 3DGS developments.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.