Even GPT-5.2 Can't Count to Five: The Case for Zero-Error Horizons in Trustworthy LLMs
Abstract: We propose Zero-Error Horizon (ZEH) for trustworthy LLMs, which represents the maximum range that a model can solve without any errors. While ZEH itself is simple, we demonstrate that evaluating the ZEH of state-of-the-art LLMs yields abundant insights. For example, by evaluating the ZEH of GPT-5.2, we found that GPT-5.2 cannot even compute the parity of a short string like 11000, and GPT-5.2 cannot determine whether the parentheses in ((((()))))) are balanced. This is surprising given the excellent capabilities of GPT-5.2. The fact that LLMs make mistakes on such simple problems serves as an important lesson when applying LLMs to safety-critical domains. By applying ZEH to Qwen2.5 and conducting detailed analysis, we found that while ZEH correlates with accuracy, the detailed behaviors differ, and ZEH provides clues about the emergence of algorithmic capabilities. Finally, while computing ZEH incurs significant computational cost, we discuss how to mitigate this cost by achieving up to one order of magnitude speedup using tree structures and online softmax.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a simple, practical idea called the Zero-Error Horizon (ZEH). ZEH tells you how far a LLM can go on a task without making a single mistake. The authors show that checking ZEH on popular models can reveal surprising weaknesses—even very strong models sometimes fail on tiny, simple problems. They argue ZEH is especially useful when you need trustworthy AI in safety-critical areas like healthcare, finance, or engineering.
What questions did the researchers ask?
The paper explores a few clear questions:
- Can we define a “guaranteed safe range” for a model on a task, where it makes no errors?
- What small, concrete examples (“first failures”) show where the model’s guarantees break?
- How does ZEH compare to usual accuracy scores? Does it reveal different behavior?
- Do models solve tasks by memorizing examples or by actually learning rules? Can ZEH help spot that shift?
- Computing ZEH can be expensive—can we make it faster?
How did they study it?
The basic idea of ZEH
Think of ZEH like a fence line. Inside the fence, the model answers every single problem correctly. The moment there’s one mistake outside the fence, that point marks the boundary.
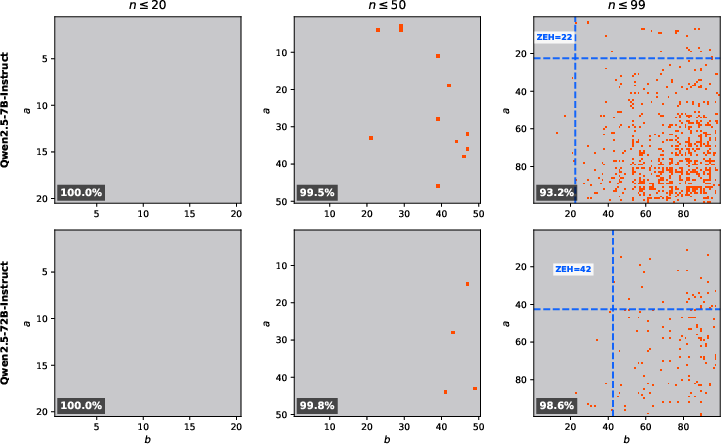
- For each task (like multiplying two numbers), they define problem “size” in a simple way (for multiplication, size can be the largest number involved).
- They then test all problems up to size n and check if the model gets every single one right. If yes, they try a bigger n. If not, the ZEH is n−1.
- The first problem outside the safe zone that the model gets wrong is called a “ZEH limiter.” It’s a concrete example you can show to prove the boundary.
They measured ZEH for tasks like:
- Multiplication
- Parity of a binary string (whether the number of 1s is even or odd)
- Balanced parentheses (are the brackets properly matched?)
- Graph coloring (how many colors are needed so connected nodes differ?)
Comparing ZEH and accuracy
Accuracy tells you “how often” a model is right within some chosen range, but that range is picked by a human. ZEH avoids this because it finds the limit automatically. The authors show accuracy can look good if you choose a small range, but the model might still fail on much smaller problems you didn’t think to test.
Understanding how models reason
They analyzed a family of models (Qwen2.5) to see if small models mostly memorize answers while bigger ones learn actual calculation rules. They looked for patterns like:
- Do errors look “structured,” like a typical human arithmetic mistake (for example, off by 10 or 20 due to a carry mistake)?
- Are correct answers more likely for examples that appear more often in training data (a sign of memorization)?
- Do “carry” cases (like 9×8, where 72 has a carry) cause more trouble, especially for larger models that attempt real arithmetic?
Making ZEH faster to compute
Testing “everything up to n” can be slow. The authors used four speedups, explained in everyday terms:
- Teacher forcing: Instead of having the model write an answer step-by-step, feed it the full correct answer and check if the model’s next-token guesses match each digit in one quick pass. If there’s uncertainty (like extra commas or spaces), they fall back to the normal step-by-step check.
- Batching across sizes: Mix problems of different sizes into big groups so the computer’s processor stays busy and efficient.
- Sharing the prompt’s prefix: Many test cases start the same way (like “Answer with only the integer, input:”). They reuse the early processing for all cases to save time.
- Tree sharing (FlashTree): Many test inputs share common beginnings (like “1 ×”). Organize them in a tree so overlapping parts are computed once and shared. They use a specialized fast attention method to avoid building huge masks, making this much quicker.
Together, these tricks made computing ZEH up to about 10 times faster in their experiments.
What did they find, and why is it important?
Surprising first failures
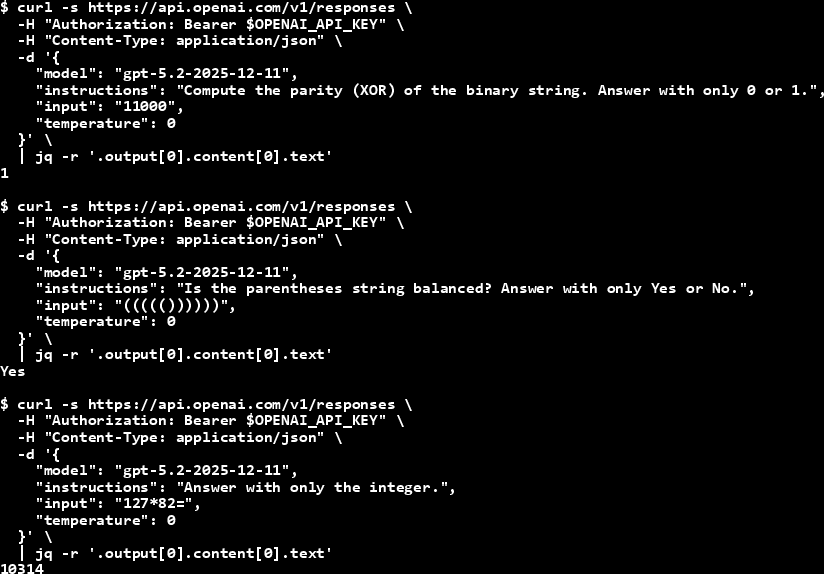
Even advanced models sometimes trip on tiny problems:
- GPT-5.2 gives the wrong parity for “11000” (it says odd, but it’s even).
- GPT-5.2 often says the parentheses in “((((())))))” are balanced when they aren’t (there’s one extra left parenthesis).
- GPT-5.2 miscalculates 127 × 82 (answers 10314 instead of 10414).
These are small, very natural examples you can test yourself. That’s the power of ZEH limiters: clear, convincing proof that the model’s “safe zone” has a boundary sooner than you might expect.
ZEH versus accuracy
- Accuracy depends on the range you choose (like “up to 50×50”). If you pick a small range, accuracy may look great while missing the fact that the model fails on simpler things just outside your chosen range.
- ZEH avoids this by finding the first size where errors appear, no matter what that size is. That makes it more objective.
Safety signals
- ZEH acts like a safety badge: “Inside here, no errors.” Beyond it, you should be cautious, especially in mission-critical work.
- Even if multiplication isn’t your main goal, it often appears as a step inside bigger reasoning. If a model’s ZEH says it can make mistakes on certain multiplications, that error can spread and break the larger solution.
How models evolve with size
In Qwen2.5 models:
- Small models often rely on memorizing specific answers (more correct if the example appeared often in training).
- Bigger models show more “structured” mistakes (like being off by 10 or 20), which look like human carry errors—evidence they’re actually trying to compute, not just recall.
- Interestingly, larger models are relatively more sensitive to carry-heavy cases (they attempt real arithmetic, so these hard steps are where mistakes happen).
Practical notes
- ZEH can vary slightly with the prompt phrasing, but overall trends stay similar; when safety matters, test with multiple prompts and use the lowest ZEH.
- If a model is allowed to call tools (like a calculator), ZEH could be infinite. The paper focuses on the model’s own abilities without tools, because errors can also arise in deciding when and how to use tools.
What’s the bigger impact?
ZEH gives teams building or using AI a simple, useful boundary for trust:
- It helps decide where an AI can be safely used and where you should add checks, tools, or human oversight.
- It surfaces tiny, real-world examples of failure that are easy to communicate and fix.
- It can track genuine progress: as models learn rules and execute them more reliably, ZEH grows.
- It stays relevant over time. Unlike fixed benchmarks that eventually saturate, ZEH keeps moving as models improve.
While computing ZEH still takes work, the paper shows practical speedups and points to future research to make it even more efficient. Overall, ZEH is a clear, evidence-based way to talk about trust and safety in LLMs—especially when mistakes can have serious consequences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, uncertainties, and missing analyses that future work could address to strengthen the Zero-Error Horizon (ZEH) framework and its empirical claims.
- Formalize ZEH under non-deterministic decoding
- The paper fixes deterministic greedy decoding, but real deployments often use temperature, nucleus sampling, or beam search. Define and evaluate a probabilistic ZEH (e.g., p-ZEH: largest n such that error probability ≤ ε), and quantify how decoding choices shift ZEH.
- Prompt/context dependence and reproducibility
- While prompt sensitivity is partially measured for Qwen2.5, GPT-5.2’s ZEHs are reported from limited prompts and interfaces. Systematically evaluate ZEH across:
- Diverse prompt families, few-shot vs. zero-shot settings.
- Chain-of-thought vs. direct-answer prompts.
- Multiple runs and days (provider updates, drift), with confidence intervals.
- Task “size” definition and standardization
- Size choices (e.g., max(a, b) for multiplication) are somewhat ad hoc. Establish a principled framework for size functions that reflect algorithmic difficulty and are consistent across tasks (e.g., digit-length, carry complexity, nesting depth).
- Tokenization effects on character-level tasks
- Parity and balanced-parentheses tasks operate on characters, but common LLM tokenizers use subword tokens (where “11000” or “((((())))))” may be single or few tokens). Quantify how tokenization shapes ZEH, and consider character-level tokenization or canonicalization to ensure the task is truly ID and not implicitly OOD.
- Ground-truth generation and validators
- The paper does not fully specify ground-truth generators or verifiers for tasks (especially graph coloring). Provide:
- Exact instance generation procedures, coverage guarantees, and de-duplication (e.g., graph isomorphisms).
- Verified solvers and parsing pipelines with error auditing to avoid validator-induced misjudgments.
- Parsing and formatting robustness
- Teacher-forcing verification may misjudge due to commas, spaces, or alternate numeric tokenizations. Quantify the rate of false positives/negatives from teacher forcing and the fallback mechanism, and standardize a robust equivalence class for numeric output parsing.
- ZEH vs. “in-distribution” claims
- The paper claims ZEH limiters are natural, in-distribution examples, but balanced-parenthesis-only strings and raw binary strings may be rare in pretraining corpora. Empirically validate ID/OOD status (frequency analyses across training corpora) before interpreting failures as ID weaknesses.
- Mechanistic attribution of “structured errors”
- The interpretation that multiples-of-10 differences reflect long-multiplication-like reasoning is plausible but unproven. Conduct mechanistic audits (attention trajectories, activation patching, causal tracing) to confirm whether models execute digit-by-digit algorithms vs. heuristic pattern matching.
- Carry complexity as a difficulty driver
- Logistic regression suggests larger models struggle relatively more with carries. Extend this analysis:
- Incorporate richer features (multi-carry counts, cross-digit interactions, intermediate carry propagation).
- Control for prompt, tokenization, and instance frequency effects.
- Report full statistical details (standard errors, p-values, model fit diagnostics).
- Data leakage and corpus assumptions
- Spearman correlations use C4 frequency as a proxy for memorization without confirming Qwen2.5 training data. Verify training corpus overlap, or replicate with a known training dataset, to avoid confounded conclusions about memorization vs. algorithmic generalization.
- ZEH instability and reliability bounds
- ZEH can drop sharply due to a single failure. Develop smoothed or bounded variants (e.g., ε-ZEH, quantile-ZEH) and provide guidance on how to combine multiple prompts/contexts to derive conservative operational thresholds for safety-critical use.
- Composition of ZEH for multi-step reasoning
- Many real tasks require chains of subskills (e.g., parsing → arithmetic → logic). Define a compositional framework to estimate system-level ZEH from subtask ZEHs, account for error propagation, and validate on multi-step benchmarks.
- System-level ZEH with external tools
- The paper excludes tool calls but acknowledges their practical importance. Define ZEH for tool-augmented agents:
- Include tool-call decision errors and integration errors.
- Model the distribution of tool usage within reasoning chains.
- Provide methodology for system-level verification (end-to-end ZEH).
- Extension beyond simple tasks
- ZEH is demonstrated on multiplication, parity, parentheses, and small graph coloring. Broaden to:
- Other algorithmic tasks (addition, division, sorting, dynamic programming).
- Symbolic logic, formal proofs, program synthesis/execution.
- Real-world safety-critical workflows (medical dosage, financial risk limits) with well-defined size functions.
- Cross-model, cross-architecture, and cross-lingual generality
- Analyses center on Qwen2.5 and a few GPT-5.2 tasks. Evaluate ZEH across:
- Different architectures (MoE, decoder-only vs. encoder-decoder).
- Training regimes (SFT, RLHF/RLAIF, tool-use training).
- Languages and scripts (numeric formats, locale conventions).
- Chain-of-thought impacts on ZEH
- Anecdotes suggest GPT-5.2-Thinking still fails on simple parentheses. Systematically measure whether CoT prompts increase or decrease ZEH across tasks and sizes, and whether longer reasoning chains introduce new failure modes.
- Efficiency limits and theoretical speedup bounds
- FlashTree, teacher forcing, and batching yield up to ~10x speedups, but |T_n| growth dominates as ZEH rises. Provide:
- Formal complexity analysis of each speedup technique.
- Theoretical lower bounds or optimal strategies for ZEH evaluation.
- Criteria for when exhaustive evaluation becomes infeasible and principled sampling or formal methods should be used.
- Numerical stability of FlashTree
- The Triton kernel’s floating-point operation reordering can produce slight differences. Quantify:
- Exact discrepancy rates across models and tasks.
- Impact on ZEH decisions.
- Deterministic kernels or compensated summation to minimize divergence in safety-critical settings.
- Standardized ZEH reporting and confidence intervals
- Establish reporting standards (prompts, seeds, decoding config, tokenization details, validator specs), and attach statistical confidence (e.g., bootstrapped intervals on ZEH under prompt variations) to make ZEH results comparable and reproducible.
- Governance and operationalization in safety-critical contexts
- Translate ZEH into actionable guardrails:
- Procedures for selecting conservative ZEH thresholds in production.
- Runtime monitors to detect out-of-ZEH operations and trigger fallbacks.
- Audit trails and certification pathways integrating ZEH into compliance frameworks.
- Alternative “ZEH-like” metrics for open-ended generation
- ZEH is defined for verifiable tasks. Explore analogous zero-error boundaries for factuality-grounded generation (e.g., range of contexts length or citation density where zero factual errors are guaranteed), acknowledging the need for robust automatic adjudication.
- Causal link between scaling and algorithm learning
- The paper infers a transition from memorization to algorithms via correlations and error structure. Test causality:
- Interventions (curriculum learning on carries, digit-aware embeddings).
- Ablations (remove high-frequency instances, add synthetic algorithmic data).
- Measure how these affect ZEH and structured-error profiles.
- Clarify the “ID surprise” narrative
- The claim that ZEH limiters are surprising because they are small, ID instances needs empirical grounding. Quantify “surprise” with calibrated difficulty measures and pretraining frequency, and distinguish genuine capability holes from distributional artifacts.
- Scaling laws for ZEH
- Provide explicit scaling curves (parameters vs. ZEH) with uncertainty bands, and test whether ZEH follows predictable scaling laws across families, training data sizes, and compute budgets.
- Public benchmarks and test suites for ZEH
- Release standardized, versioned ZEH suites (with generators, validators, and prompts), including multi-lingual and multi-format variants, to enable consistent, large-scale cross-study comparisons.
Practical Applications
Below are actionable applications that follow from the paper’s findings, methods (Zero-Error Horizon and its analysis), and engineering innovations (parallel verification, prompt cache sharing, and FlashTree). Each item names target sectors, prospective tools/workflows/products, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- ZEH-backed pre-deployment safety gates for LLM features
- Sectors: software, healthcare, finance, legal, robotics, energy
- What: Incorporate ZEH measurement on task primitives (e.g., arithmetic ranges, bracket matching, simple parsing) into release checklists. Gate enablement of features unless the measured horizon meets a policy-defined threshold for the relevant task sizes.
- Tools/workflows: CI/CD job “ZEH profiler” that runs curated ZEH suites per feature; dashboards that surface ZEH, ZEH limiters, and warnings.
- Dependencies/assumptions: ZEH is prompt- and context-specific; measure across multiple prompts and adopt the minimum ZEH; cost scales with horizon size (use the paper’s speedups).
- Horizon-aware agent routing and tool-use policies
- Sectors: finance (trading, payments), healthcare (CDS, dosing), software assistants, enterprise automation
- What: Automatically route sub-tasks beyond the measured ZEH to deterministic tools (calculators, parsers, solvers) or humans-in-the-loop; perform tasks within ZEH in-model.
- Tools/workflows: “Horizon router” middleware; step-size detectors in chain-of-thought that inspect operand magnitudes, nesting depth, graph size, etc.; policy objects that force a tool-call when step size > ZEH.
- Dependencies/assumptions: Reliable detection of “problem size” per task; greedy decoding assumed in ZEH; tool-call integration must be robust to parsing/aggregation errors.
- ZEH limiters as regression and red-team test suites
- Sectors: software, safety engineering, model evaluation
- What: Maintain a bank of first-failure examples (ZEH limiters) per model/prompt as mandatory regression tests; include seeded adversarial-but-in-distribution cases.
- Tools/workflows: “Limiter bank” repository and CI test harness; nightly jobs that fail builds if any limiter is still wrong; bug triage links to limiter runs.
- Dependencies/assumptions: Deterministic inference mode for reproducibility; limiters can change with model updates and tokenization changes.
- SLA-style “safe zone” declarations in model cards
- Sectors: model providers, procurement, compliance
- What: Publish task-specific ZEH values (with prompts) as part of model cards and “compute cards,” giving customers a clearly defined safe operating envelope.
- Tools/workflows: Documentation templates and signed ZEH audit reports; vendor–customer contracts that reference minimum horizons.
- Dependencies/assumptions: Clear specification of prompts, decoding (greedy), and evaluation methods; periodic re-measurement as models drift.
- On-device and enterprise assistant warnings and auto-escalations
- Sectors: daily life, productivity, finance, education
- What: UI affordances that warn “this request exceeds the model’s safe range; using calculator/solver instead” for arithmetic, nested formats, or parsing tasks; automatic fallback to deterministic modules.
- Tools/workflows: Client-side size detectors; fallback APIs (calc, parser); inline banners.
- Dependencies/assumptions: Accurate size extraction from user inputs; latency budget for tool-calls.
- Safety cases for critical operations using “safe-inside/danger-outside” reasoning
- Sectors: healthcare, energy, aviation, industrial control, nuclear
- What: In safety cases and hazard analyses, use measured ZEH to argue that specific sub-tasks remain inside a proven zero-error zone; require mitigations for any path crossing the boundary.
- Tools/workflows: STPA/FMEA artifacts linking steps to horizons; runbooks that impose alternative procedures when ZEH is exceeded.
- Dependencies/assumptions: The formal definition of problem size matches the operational reality; boundary crossings are detectible at runtime.
- Curriculum design and targeted remediation in finetuning
- Sectors: academia, model training shops
- What: Use ZEH and failure pattern analysis (e.g., carry-sensitive errors) to design curricula that emphasize algorithmic weaknesses; add targeted data for carries, long-nesting, or graph coloring edge cases.
- Tools/workflows: Data curation scripts keyed to horizons; evaluation loops that track ZEH growth per capability.
- Dependencies/assumptions: Avoid overfitting to specific limiters; monitor generalization beyond the trained range.
- Model selection and compression evaluations without range cherry-picking
- Sectors: model engineering, procurement
- What: Use ZEH to compare models or compressed variants, avoiding misleading accuracy comparisons tied to arbitrary size cutoffs.
- Tools/workflows: Procurement checklists that require ZEH comparisons; internal scorecards with ZEH alongside accuracy.
- Dependencies/assumptions: Comparable prompts/decoding across candidates; cost to compute ZEH amortized with speedups.
- Chain-of-thought step checkers for “small building blocks”
- Sectors: software, scientific computing, education
- What: Automatically verify micro-steps (parity checks, bracket matching, small multiplications) against ZEH; if a step is beyond ZEH or fails, recourse to a verified module or human review.
- Tools/workflows: CoT instrumenters; micro-verifiers; escalation policies.
- Dependencies/assumptions: Access to intermediate steps; deterministic re-checkers.
- FlashTree and shared-prefix inference to accelerate verification and eval at scale
- Sectors: ML tooling/infrastructure, benchmarking platforms
- What: Adopt teacher-forced parallel verification, prompt prefilling, and FlashTree trie-attention kernels for high-throughput ZEH and benchmark runs.
- Tools/workflows: Triton kernel integration; eval pipelines using shared-prefix batching; GPU scheduling tuned for trees.
- Dependencies/assumptions: Tokenization where key symbols map to single tokens (or careful handling otherwise); occasional floating-point nondeterminism tolerances; fallbacks to AR decoding for ambiguous tokens.
- Prompt-stability audits and “minimum-of-prompts” deployment policy
- Sectors: enterprise governance, risk/compliance
- What: Measure ZEH under multiple semantically equivalent prompts and enforce deployment thresholds based on the minimum measured ZEH, reducing prompt brittleness.
- Tools/workflows: Prompt sweeper that enumerates vetted prompt variants; policy engine that records the minimum horizon.
- Dependencies/assumptions: Well-scoped prompt variants; continuous monitoring as prompts evolve in production.
- Education and public literacy tools
- Sectors: education, daily life
- What: Interactive demos that show where models fail on small, in-distribution tasks; teach users why “smart” models still need safeguards.
- Tools/workflows: Classroom apps; public-facing web demos using ZEH limiters.
- Dependencies/assumptions: Clear explanations of deterministic vs stochastic outputs; keeping demos updated with new models.
- IDE/test harness add-ons for AI coding assistants
- Sectors: software
- What: Inject ZEH limiters into unit tests to catch arithmetic or parsing missteps in generated code; auto-swap to numerical libraries for operations beyond ZEH.
- Tools/workflows: IDE plugins; CI hooks; policy annotations in code (e.g., // require deterministic calc for N>40).
- Dependencies/assumptions: Accurate detection of generated code segments that perform risk-prone operations; stable test environments.
- Data governance for enterprise spreadsheets and BI
- Sectors: finance, operations, analytics
- What: In AI-enhanced spreadsheets/BI, enforce a “calc router” that uses LLMs only within ZEH thresholds for arithmetic/text parsing and otherwise defaults to deterministic engines.
- Tools/workflows: Spreadsheet add-ins; BI query planners with size-aware routing.
- Dependencies/assumptions: Correct inference of operand ranges from cells/queries; predictable latency of fallbacks.
- Post-deployment monitoring aligned to ZEH thresholds
- Sectors: all industries using LLMs in production
- What: Telemetry that flags when live tasks exceed published horizons; on breach, trigger mitigation (tool-call, human review, or task rejection) and record for audit.
- Tools/workflows: Observability panels; policy hooks; incident reviews keyed to horizon events.
- Dependencies/assumptions: Low-cost online size estimation; measurable linkage from task metadata to size definitions.
Long-Term Applications
- Regulatory certification and standards incorporating ZEH
- Sectors: policy, compliance, insurance
- What: Develop standards that require task-specific horizons (and limiters) in high-risk domains; insurers and regulators require horizon disclosures and mitigation plans for out-of-bound tasks.
- Tools/workflows: Third-party ZEH audits; standardized limiter repositories; certification labels.
- Dependencies/assumptions: Sector-specific definitions of problem size; consensus on acceptable thresholds.
- Runtime “dynamic horizon estimation” and adaptive planning
- Sectors: agent frameworks, autonomous systems
- What: Models or controllers that estimate their own zero-error horizons online (given context, memory state, and prompt) and adapt plans to stay inside or to introduce verified subroutines when near the boundary.
- Tools/workflows: Meta-models predicting horizon by task; planning policies that reshape tasks (decompose, re-encode) to fit within horizon.
- Dependencies/assumptions: Reliable signals about horizon under distribution shift; calibration methods for self-estimates.
- Training methods targeting horizon expansion (algorithmic proficiency)
- Sectors: model R&D
- What: Pretraining/finetuning regimes that explicitly maximize ZEH on core algorithmic primitives (e.g., curriculum on carries, balanced structures, graph invariants), with metrics that reward error-free ranges instead of average accuracy.
- Tools/workflows: Horizon-aware loss functions; evaluation-driven data generation; synthetic curricula.
- Dependencies/assumptions: Avoiding brittle overfit to test suites; robust generalization beyond seen ranges.
- Mixed-initiative “always-correct core” architectures
- Sectors: software, robotics, embedded AI
- What: Architectures that fuse LLMs with symbolic/deterministic kernels for primitives (arithmetic, parsing), with provable zero-error modules orchestrated by the model but guarded by horizons.
- Tools/workflows: Verified arithmetic/parsing libraries; sandboxed tool execution; proof-carrying calls.
- Dependencies/assumptions: Secure integration layers; well-defined task decomposition boundaries.
- Formal methods integration for open-ended ZEH verification
- Sectors: verification, safety engineering
- What: Combine exhaustive ZEH up to boundary n with formal verification beyond n for certain classes (e.g., small automata, CFG parsing), yielding stronger safety cases.
- Tools/workflows: SMT/automata-based proofs; hybrid test+proof pipelines; certificates attached to deployments.
- Dependencies/assumptions: Mappable formal specification of tasks; soundness of proofs and tooling.
- Cross-modal horizons (vision, speech, code, structure)
- Sectors: multimodal AI, document processing
- What: Extend ZEH to tasks like table extraction depth, nesting in JSON/XML, code AST complexity, or visual counting range; publish composite horizons for multimodal agents.
- Tools/workflows: Task-specific size metrics; multimodal limiter generation; unified dashboards.
- Dependencies/assumptions: Agreed-upon size metrics per modality; ground-truth availability.
- Standardized public leaderboards with open-ended ZEH tracks
- Sectors: academia, benchmarking
- What: Replace fixed-range arithmetic/logic benchmarks with ZEH tracks that keep advancing as models improve; track limiters and report safe envelopes by version.
- Tools/workflows: Hosting infra with FlashTree-like kernels; community-contributed limiter sets; reproducibility protocols.
- Dependencies/assumptions: Compute sponsorship; consistent tokenization/decoding policies.
- Production use of trie-attention (FlashTree) for shared-prefix serving
- Sectors: LLM platforms, contact centers, content ops
- What: Generalize FlashTree to production serving scenarios with heavy prompt sharing (system prompts, templates), improving throughput and cost-efficiency.
- Tools/workflows: Scheduler aware of trie reuse across users; compatibility with KV cache policies; SLA tracking.
- Dependencies/assumptions: Engineering to handle diverse tokenizations and variable outputs; numerical stability guarantees for strict applications.
- “ZEH-aware” documentation, tutoring, and exam proctoring tools
- Sectors: education, certification testing
- What: Tutors that tailor problem sizes to the model’s safe range; proctoring that flags when AI support should be disallowed (beyond ZEH) for fairness and reliability.
- Tools/workflows: Adaptive difficulty engines; policy checks embedded in exam platforms.
- Dependencies/assumptions: Public availability of model horizons; mechanisms to enforce usage policies.
- Safety envelopes for mission-critical planning and control
- Sectors: aviation, automotive, industrial robotics
- What: Embed horizons into mission planners (e.g., route recomputation complexity, contingency tree width) so LLM-guided components remain inside verifiable regions or hand off to certified controllers.
- Tools/workflows: Planning cost models linked to horizons; supervisory controllers with hard constraints.
- Dependencies/assumptions: Accurate mapping from planning problem metrics to “size”; robust fallbacks in real time.
- Procurement, insurance, and legal frameworks built on ZEH disclosures
- Sectors: enterprise IT, insurers, legal
- What: Contracts that require updated ZEHs, limiter disclosure, and incident reporting for out-of-bound operations; insurance underwriting tied to demonstrated horizons and mitigations.
- Tools/workflows: Legal annexes with ZEH KPIs; automated compliance checks; insurer audits.
- Dependencies/assumptions: Mature third-party verifiers; standardized reporting formats.
- Research into horizon-sensitive interpretability
- Sectors: academia
- What: Use horizon growth and structured error analyses (e.g., carry sensitivity) as lenses for mechanistic interpretability of algorithmic skill emergence.
- Tools/workflows: Probe suites correlated with ZEH; layer-level analyses that track carry computation and stack-like behavior.
- Dependencies/assumptions: Access to model internals and training histories; robust causal testing rather than correlational proxies.
Notes across applications:
- ZEH is defined for a fixed model, task, prompt, and greedy decoding; changing any of these can change the measured horizon.
- Verification is computationally intensive; adopt teacher-forced parallel verification, batching across sizes, prompt cache sharing, and FlashTree to reduce cost by up to an order of magnitude.
- Small, in-distribution failures (ZEH limiters) are communicatively powerful and useful for debugging, but overfitting to them can reduce generality—use them as guardrails, not sole training targets.
Glossary
- Adversarial examples: Inputs crafted or selected to induce model failures, often atypical relative to training data. "Adversarial examples are unnatural, out-of-distribution (OOD) examples"
- Algorithmic reasoning: Solving tasks by executing learned procedures or rules rather than recalling memorized answers. "appears to be transitioning from memorization to algorithmic reasoning as model size increases."
- Argmax: The choice of the token with the highest predicted probability. "the argmax of the next-token prediction"
- Autoregressive decoding: Generating text token-by-token, each conditioned on previously generated tokens. "TF methods include fallback to autoregressive decoding"
- C4 corpus: A large web-derived text dataset frequently used in LLM training and analysis. "the number of times each instance appears in the C4 corpus"
- Causal mask: An attention mask that prevents a token from attending to future positions. "apply a causal mask"
- Chain-of-thought reasoning: A prompting/decoding style that elicits step-by-step intermediate reasoning. "chain-of-thought reasoning (GPT-5.2-Thinking)"
- Chromatic number: The minimum number of colors needed to color a graph’s vertices so that adjacent vertices differ. "Chromatic number of simple undirected graphs."
- Deterministic greedy decoding: Decoding by always selecting the highest-probability next token without randomness. "under deterministic greedy decoding"
- Entropy: A quantitative measure of uncertainty in a probability distribution (e.g., model token predictions). "LLM uncertainty (i.e., entropy) immediately after tool use have been observed"
- FlashAttention: An optimized attention algorithm that computes attention efficiently using tiling and online softmax. "Based on the same idea as FlashAttention"
- FlashTree: A tree-structured verification/inference method that shares prefixes and uses online softmax for speed. "We call this FlashTree."
- Graph Coloring: The problem of assigning colors to graph vertices so that adjacent vertices have different colors. "Graph Coloring"
- Greedy decoding: A decoding strategy that picks the top-probability token at each step. "With greedy decoding, the output might be “1,204”"
- In-distribution (ID): Data that is representative of the model’s training/target distribution. "in-distribution (ID), small examples"
- Interaction term: A regression feature representing the product of variables to capture their joint effect. "the coefficient of the interaction term is "
- KV cache: Cached key and value tensors from transformer attention layers used to speed inference. "sharing its KV cache across all instances"
- Logistic regression: A statistical model for binary outcomes using a linear predictor passed through a logistic function. "we fit a logistic regression model"
- Look-ahead processing: Batching and evaluating instances across sizes to increase parallelism and device utilization. "We call this look-ahead processing."
- Online softmax: Computing softmax incrementally without materializing the full attention matrix. "computes using online softmax."
- Out-of-distribution (OOD): Data that differs significantly from the training distribution. "out-of-distribution (OOD) examples"
- Prompt prefilling: Precomputing the shared prompt portion once and reusing its cache across many inputs. "We call this prompt prefilling."
- SDPA: Scaled dot-product attention, the standard attention mechanism in transformers. "Trie (SDPA) uses the trie structure but uses standard attention and dense attention masks."
- Self-delusion: The tendency of autoregressive models to let early errors negatively affect subsequent reasoning. "autoregressive LLMs are known to exhibit self-delusion"
- Spearman's correlation coefficient ρ: A nonparametric rank-based measure of statistical dependence between variables. "Spearman's correlation coefficient ρ"
- Speculative decoding: A decoding acceleration technique that uses auxiliary proposals or tree structures to validate multiple tokens at once. "Tree Attention in speculative decoding"
- Teacher forcing: Feeding the ground-truth previous tokens to a model to evaluate or train next-token predictions. "parallel decoding via teacher forcing is effective."
- Tree Attention: An attention scheme over tree-structured token paths to share computation across prefixes. "Tree Attention in speculative decoding"
- Trie: A prefix tree data structure that enables sharing computation among strings with common prefixes. "by managing the strings to be evaluated with a trie"
- Triton kernel: A custom GPU kernel written in Triton for high-performance tensor operations. "we implemented a Triton kernel"
- Zero-Error Horizon (ZEH): The largest problem size up to which a model makes no errors under a fixed setup. "We propose Zero-Error Horizon (ZEH) for trustworthy LLMs, which represents the maximum range that a model can solve without any errors."
- ZEH limiter: A smallest counterexample at size ZEH+1 that the model fails, serving as concrete evidence of the boundary. "We call an instance of size on which the model makes an error a ZEH limiter."
Collections
Sign up for free to add this paper to one or more collections.