- The paper presents DWPP, a novel pure pursuit method that explicitly incorporates velocity and acceleration limits in command computation.
- It uses an O(1) analytical approach to determine the feasible command within a dynamic window, ensuring zero constraint violations and enhanced path tracking.
- Experimental results on AGVs show that DWPP reduces tracking error and overshoot, especially on sharp turns, offering a robust alternative to conventional methods.
Dynamic Window Pure Pursuit: An Explicitly Feasible Pure Pursuit Path Tracking Paradigm
Introduction and Motivation
Path tracking remains foundational in mobile robot navigation, particularly for AGVs and service robots operating in semi-structured indoor environments. Pure pursuit (PP) and its variants are widely adopted due to their computational efficiency and ease of integration, notably as local planners in frameworks like ROS~2 Nav2. However, a persistent issue with conventional PP, as well as more advanced variants like adaptive pure pursuit (APP) and regulated pure pursuit (RPP), is the lack of explicit adherence to physical velocity and acceleration constraints during command computation. This deficiency leads to a misalignment between planned and executed robot motions, elevating risks of tracking error, path overshoot, and complications in controller stability analysis.
The paper "DWPP: Dynamic Window Pure Pursuit Considering Velocity and Acceleration Constraints" (2601.15006) introduces the Dynamic Window Pure Pursuit (DWPP) method, expressly reformulating command velocity calculation in pure pursuit to directly incorporate and respect velocity and acceleration bounds. This approach fundamentally bridges the abstraction gap between the kinematic planner and the true closed-loop embodiment, both theoretically and in practical mobile robot deployments.
Methodological Advancements: Explicit Feasibility in the v--ω Space
DWPP decomposes the path tracking task into a three-stage process: (1) construction of the dynamically feasible command window through current velocity and actionability limits; (2) regulation of this feasible space using trajectory-aware heuristics (from RPP); and (3) analytical selection of the optimal command point that closely aligns with the path-following condition in the v--ω plane.
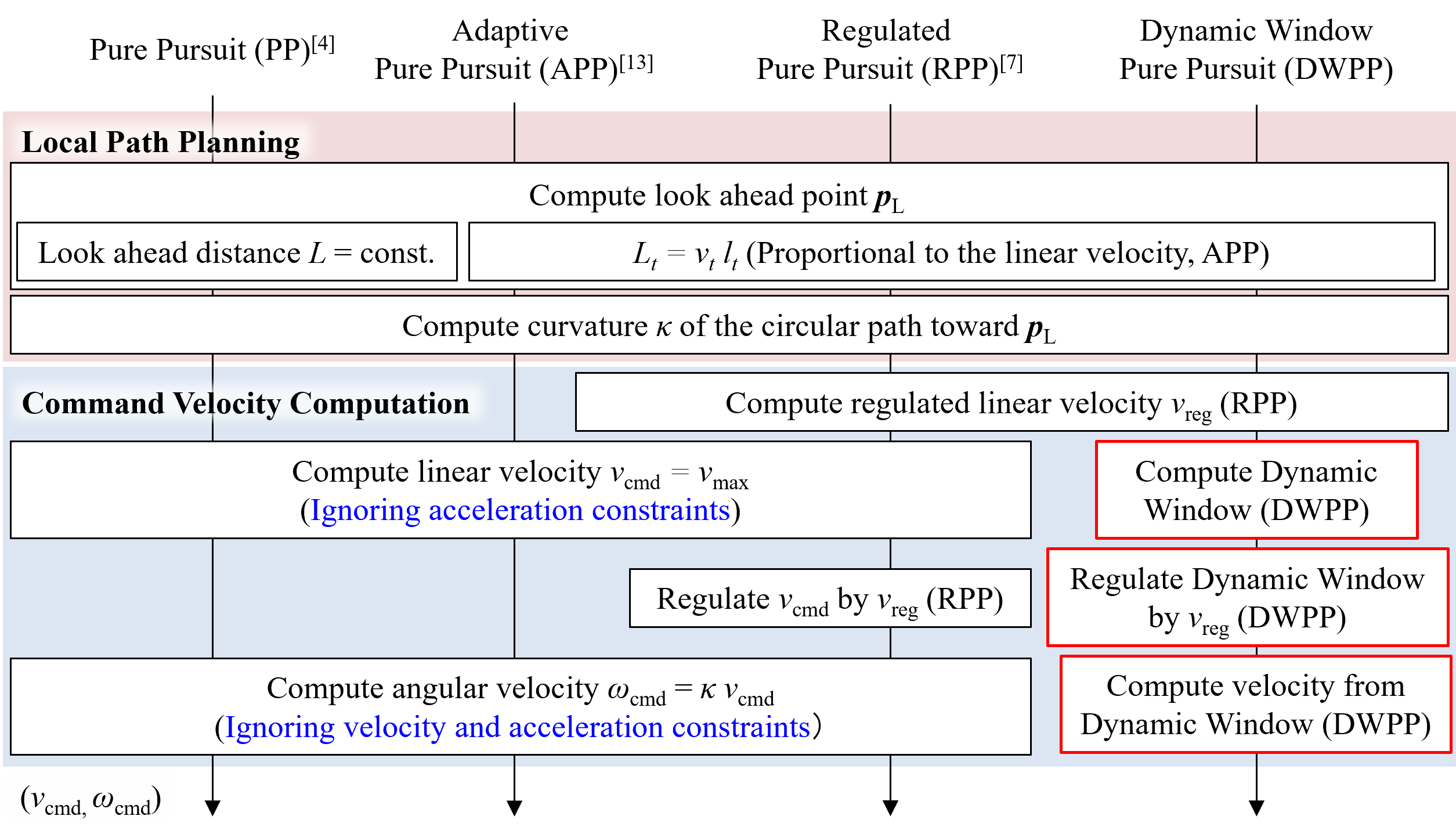
Figure 1: Processing flow comparison between conventional pure pursuit variants and DWPP, highlighting the integrated consideration of robot constraints prior to selecting control actions.
The geometric relationship underlying pure pursuit is retained, in which control action is ideally defined by the line ω=κv connecting the robot's instantaneous pose and its lookahead target, parameterized via curvature κ. Unlike prior methods that may later saturate or clip velocity commands, DWPP confines its selection to the subset of this line guaranteed to be available for the next timestep.
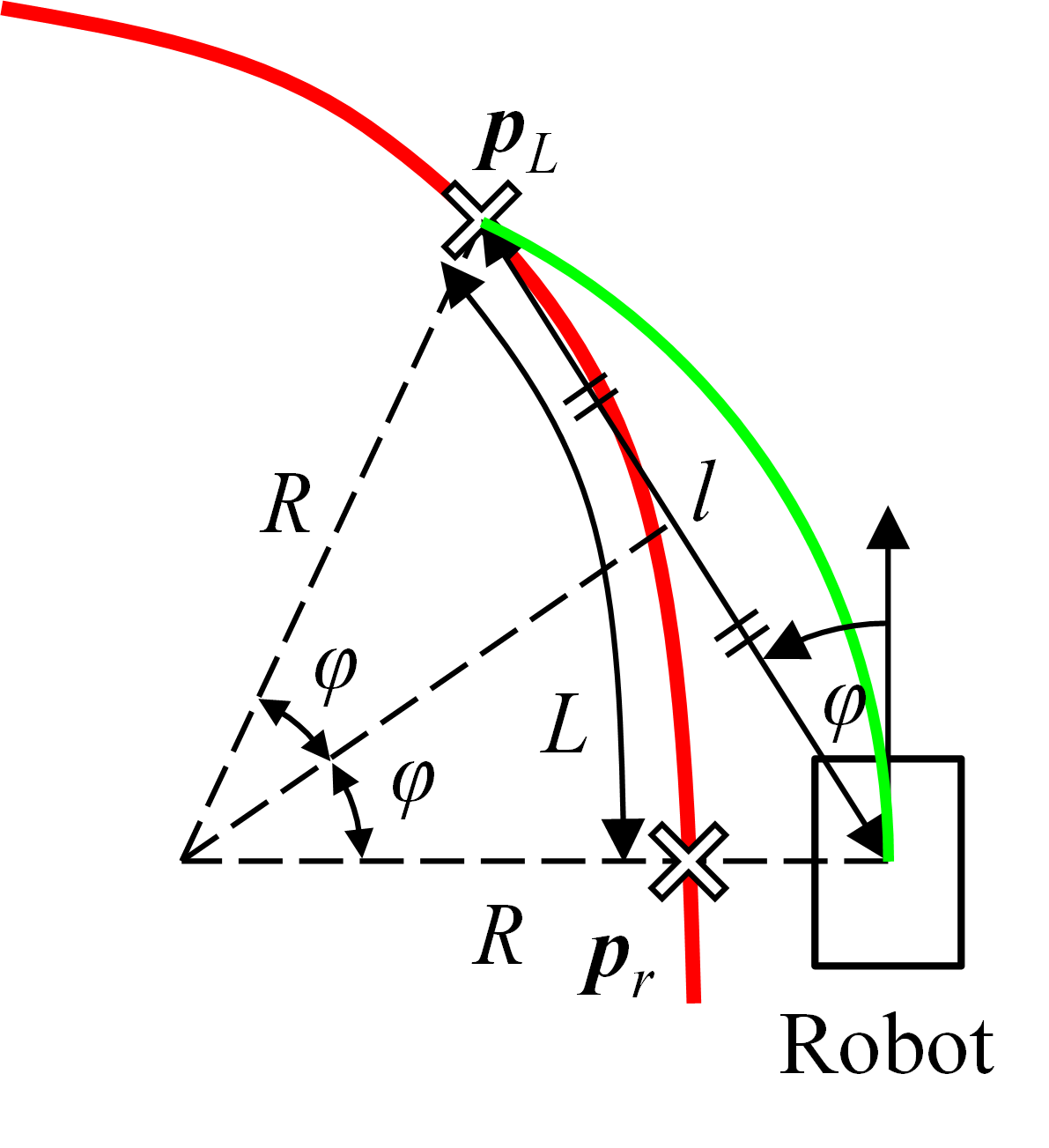
Figure 2: Geometric relationship among robot position, reference path, and lookahead point in pure pursuit.
In implementation, DWPP achieves O(1) computational complexity: it analytically solves for the intersection points between the line ω=κv and the rectangular dynamic window specified by (vmin,vmax,ωmin,ωmax). If intersections exist, it chooses the candidate maximizing v as a secondary criterion; if not, the nearest vertex of the dynamic window is selected.
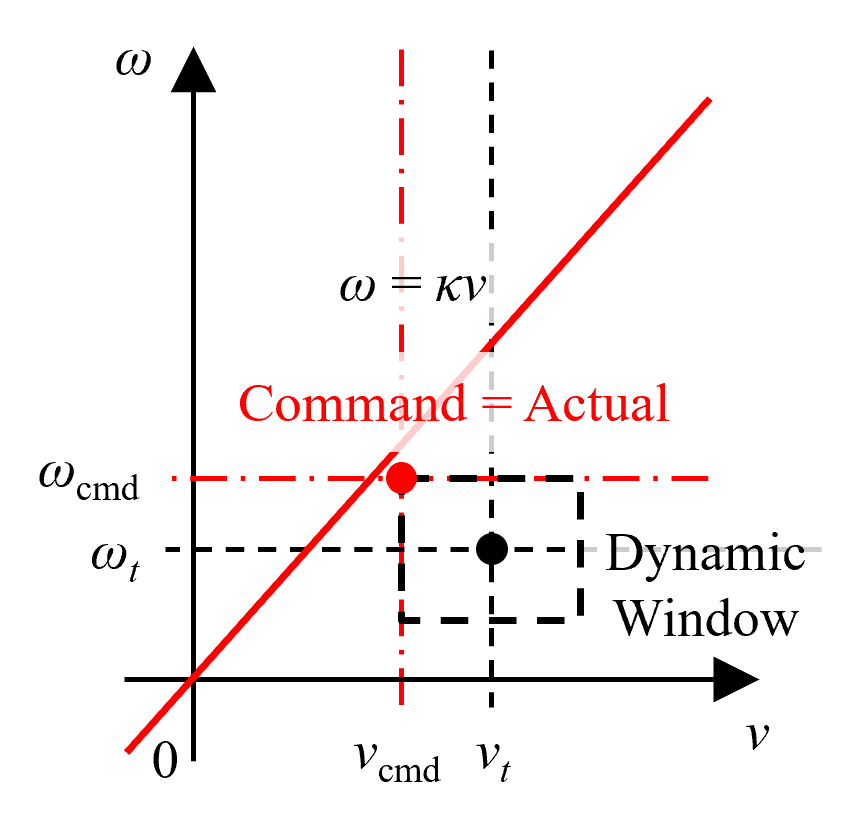
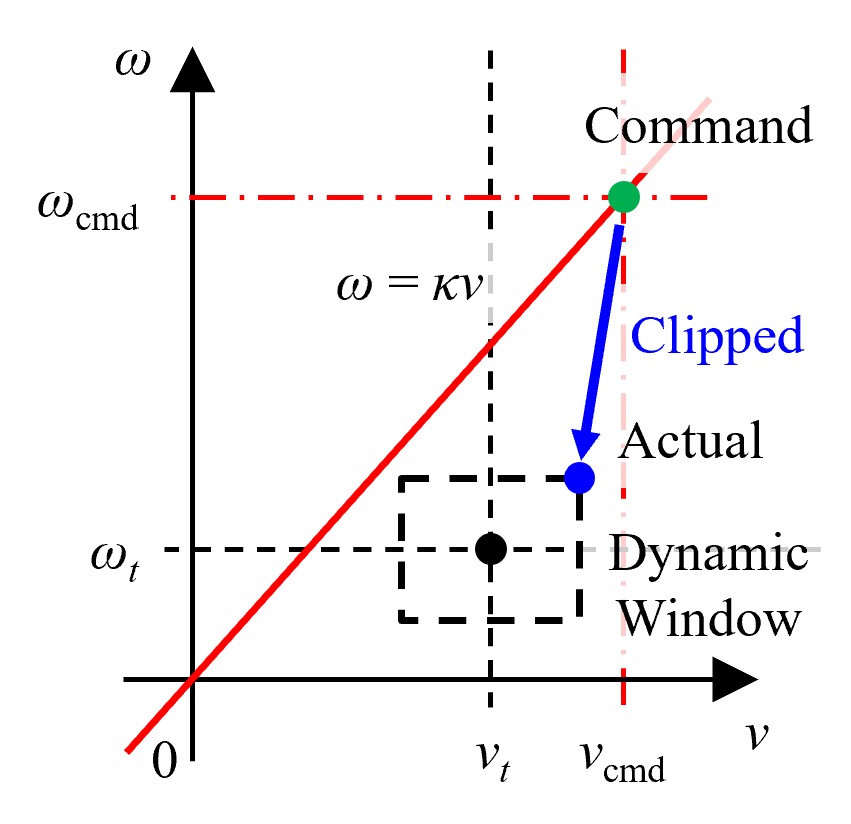
Figure 3: Visualization of DWPP’s command velocity computation in the v--ω space, guaranteeing selection within velocity/acceleration limits.
This guarantees that the issued control command is always both optimal (in the sense of path tracking given current constraints) and feasible (in the sense of robot actuation).
The experimental section validates DWPP on a real AGV platform (WHILL Model CR) within the Nav2 navigation stack, benchmarking against PP, APP, and RPP over three synthetic reference paths with increasing turn acuteness (45∘, 90∘, 135∘).

Figure 4: AGV platform employed in the experimental trials.

Figure 5: Structured environment for quantitative path-tracking assessment.
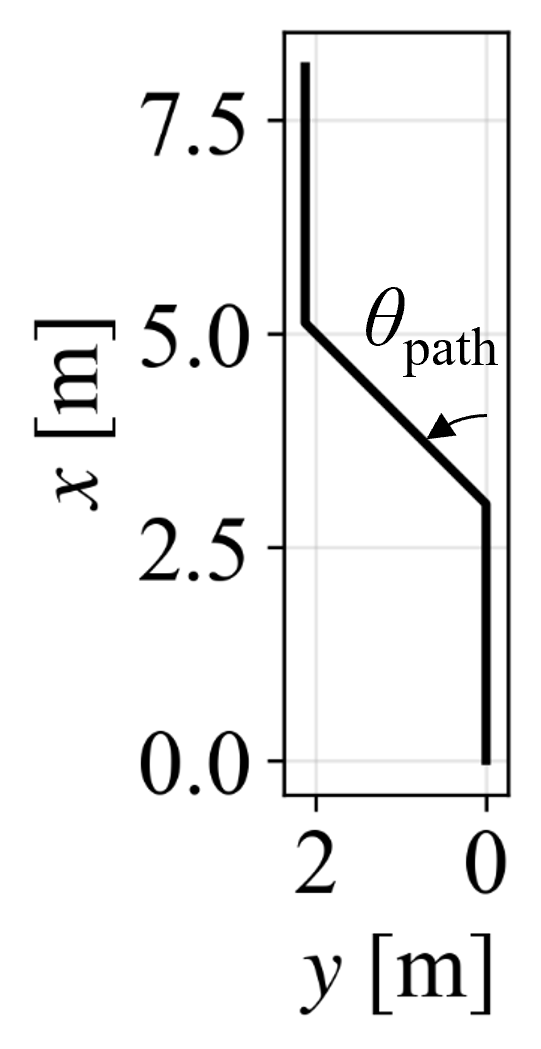
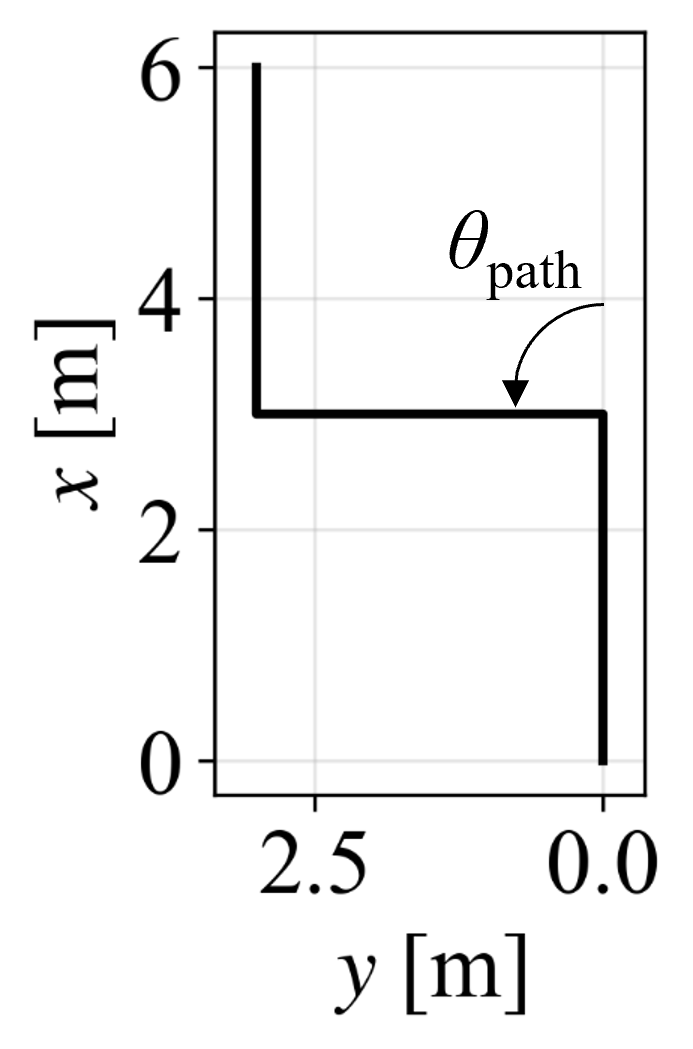
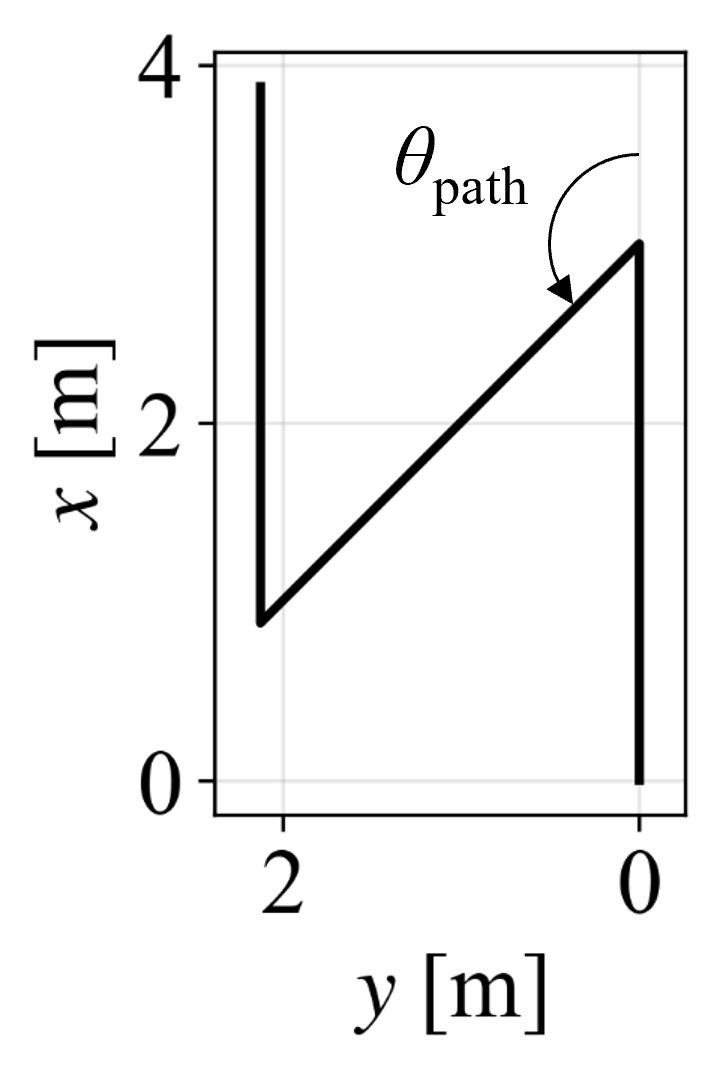
Figure 6: Example path with 45∘ corner used in tracking experiments.
Performance metrics include mean and maximum cross-track error, travel time, and—most critically—violation ratios for both velocity and acceleration constraints.
Core Numerical Results
DWPP exhibits zero constraint violations for all scenarios, while conventional methods exhibit violation rates escalating with increasing path acuteness (up to 55% for PP on Path C). Mean and maximum path-tracking errors are minimized with DWPP—e.g., for the most acute path, DWPP achieves 0.03m mean tracking error compared to RPP’s 0.05m, APP’s 0.14m, and PP’s 0.20m. DWPP also achieves the lowest maximum cross-track error on all paths.

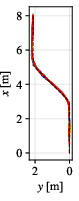

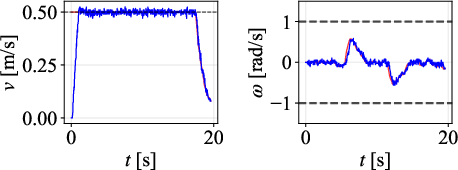
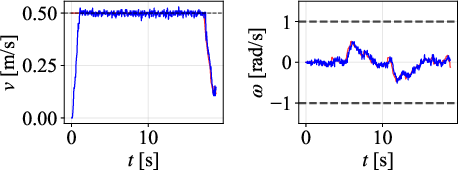
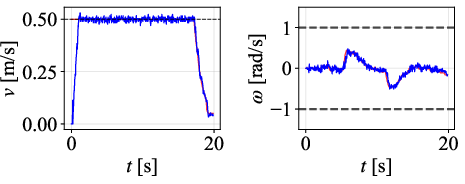
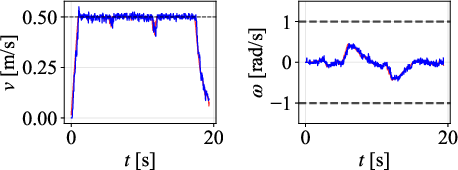
Figure 7: Tracked paths for each controller on 45∘ path; DWPP demonstrates smallest deviations and no overshoot.
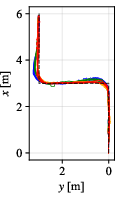
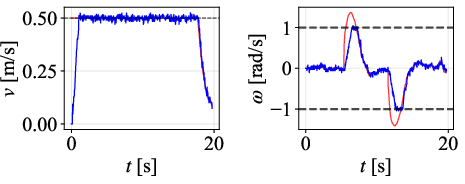
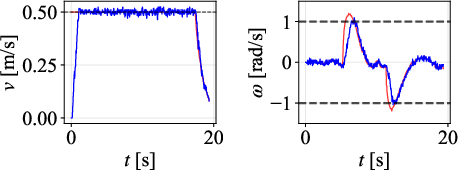
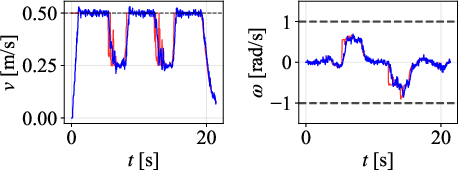
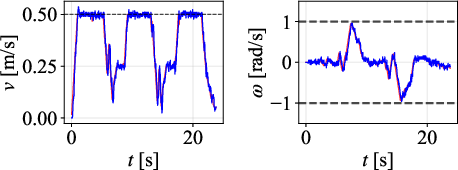
Figure 8: Path comparison on 90∘ scenario, illustrating increasing divergence for methods that neglect constraints.
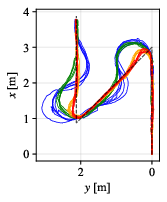
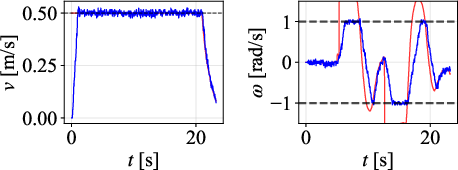
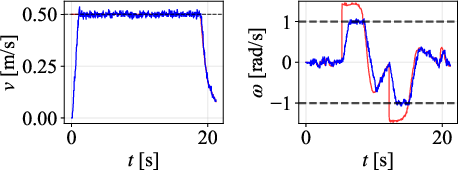
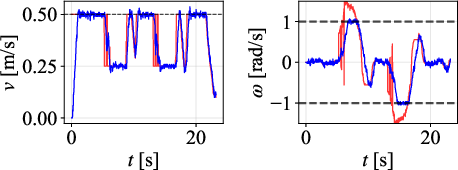
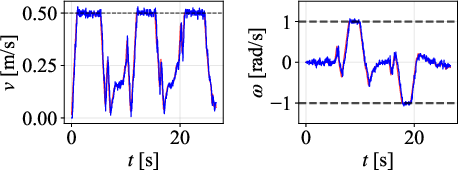
Figure 9: Path comparison on 135∘ scenario, with DWPP maintaining tight adherence even on aggressive corners.
Velocity profiles further validate that only DWPP commands match realized robot velocities, while others exhibit actuator-enforced saturation and temporal desynchronization.
In exchange, DWPP incurs slightly increased travel times (e.g., 26.1s versus 23.8s for RPP in Path C), reflecting necessary speed reductions at sharp turns to ensure feasible and safe robot operation.
Lookahead Distance Trade-off
A dedicated simulation study manipulating the lookahead parameter in DWPP highlights the standard trade-off: decreasing lookahead reduces tracking error but increases travel time, while increased lookahead achieves the opposite. This empirically quantifies the impact of parameter selection, providing practical insights for system integrators.
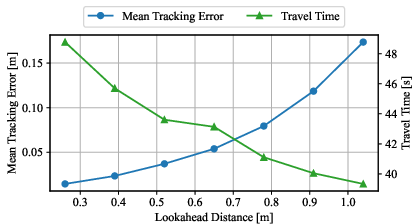
Figure 10: Trade-off curve between mean tracking error and travel time as the DWPP lookahead distance is varied.

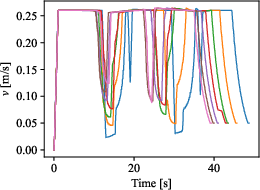
Figure 11: Tracked paths at various lookahead distances, showing increased corner-cutting and error with larger lookaheads.

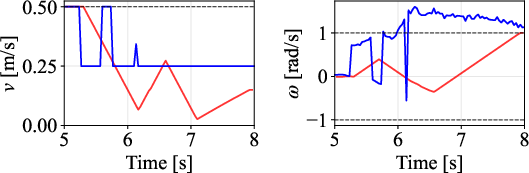
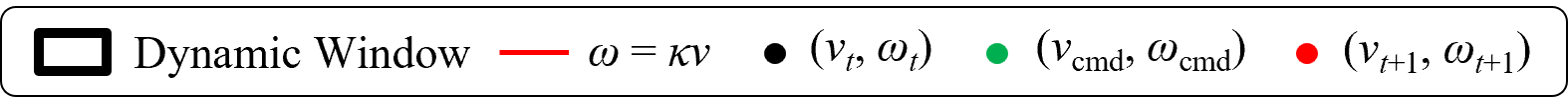
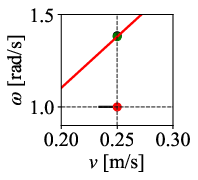
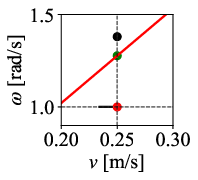
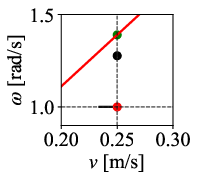
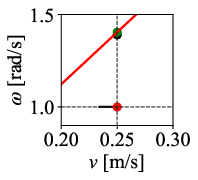
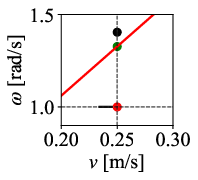
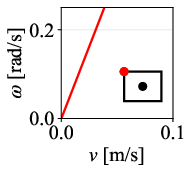
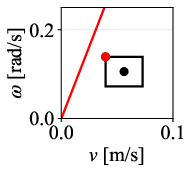
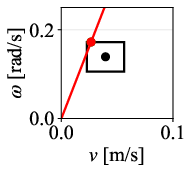
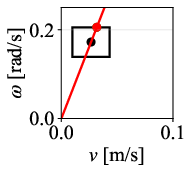
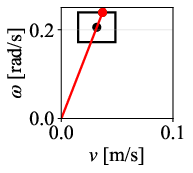
Figure 12: Command velocity time profiles for RPP and DWPP during a sharp turn; DWPP adaptively decelerates and re-accelerates to maintain strict feasibility.
Discussion: Theoretical and Practical Implications
DWPP ensures that every command is physically executable while analytically optimally aligning with the geometric principles of pure pursuit. This makes it uniquely suited for high-precision tasks, safety-critical AGV use, and deployments where real-world limits on aggressive maneuvers (e.g., passenger comfort or cargo safety) matter.
From a theoretical standpoint, the paper demonstrates that DWPP inherits the stability guarantees of pure pursuit for quasi-static conditions, but further improves stability margins on sharp-curvature paths by appropriately reducing the minimum required lookahead—an emergent property from the explicit deceleration.
Comparison with the dynamic window approach (DWA) for path tracking is also instructive: whereas DWA samples a discretized command set and runs expensive forward simulations (O(NM) complexity), DWPP directly computes the true optimum within the continuous feasible region (O(1) complexity).
Further, DWPP obviates the need for complex, manually tuned deceleration heuristics, as it intrinsically incorporates all available acceleration budget. Nevertheless, hybridization or additional heuristics can be re-integrated if more domain-specific behaviors are desired.
Conclusion
DWPP offers a fundamentally sound, analytically optimal, and practically robust pure pursuit algorithm that entirely removes the historical disconnect between planned and physically attainable velocities in mobile robot path tracking. Experimental and simulation results confirm its capability to minimize both constraint violations and tracking error, albeit at the expense of modest increases in traversal time on sharp paths—a trade-off that can be controlled via parameterization.
DWPP is currently integrated into the ROS~2 Nav2 stack, making its adoption trivial for a wide swath of service and research robots.
The most promising directions for future research include autonomous, context-sensitive lookahead tuning, integration of online learning for performance optimization, and extension to scenarios with dynamic obstacles where DWA traditionally excels. The explicit, constraint-aware methodology of DWPP provides a strong foundation for these advancements.

