- The paper introduces DARA, a dual-phase framework that combines few-shot in-context learning with RL fine-tuning to optimize sequential budget allocations in online advertising.
- It decomposes decision-making into a heuristic initialization phase and a fine-grained optimizer phase, leading to significantly reduced marginal ROI variance compared to baseline models.
- The GRPO-Adaptive algorithm enhances numerical precision and stability, ensuring robust performance in real-time bidding environments with limited data.
Dual-Phase RL-Finetuned LLMs for Few-Shot Budget Allocation in Online Advertising
Introduction
The problem of optimally allocating advertising budgets across multiple time periods in real-time bidding (RTB) environments entails maximizing cumulative advertiser value subject to budget constraints, under highly dynamic and data-limited conditions. Existing approaches based on RL or LLMs are limited by either sample inefficiency, poor adaptability in few-shot settings, or lack of numerical precision in structured optimization. The paper "DARA: Few-shot Budget Allocation in Online Advertising via In-Context Decision Making with RL-Finetuned LLMs" (2601.14711) introduces DARA—a Dual-phase Adaptive Reasoning and Allocation framework—addressing these limitations through a novel decomposition of the planning process and a synergistic combination of few-shot in-context learning and RL-driven optimization.
The core challenge is formulated as a sequential decision problem with delayed rewards and non-stationary dynamics. Budget allocation vectors bt across T periods are optimized to maximize the sum of expected returns vt(bt), under the constraint ∑tbt=B, with each vt assumed strictly increasing and concave. The optimality condition at solution enforces equal marginal ROI across periods. Practically, this is approximated by minimizing marginal ROI variance.
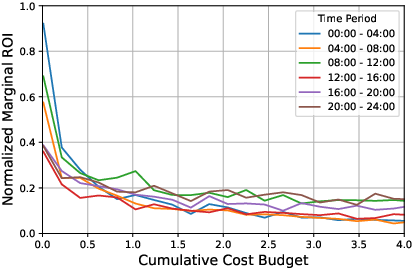
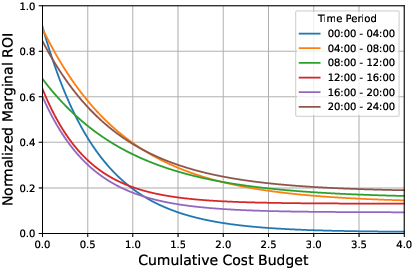
Figure 1: Empirical marginal ROI curves in the real-world data environment characterize the allocation-reward tradeoff inherent in online advertising platforms.
The study leverages both enterprise-scale, real-world environments and synthetic polynomial function-based simulators, supporting robust benchmarking and systematic testing of the capacity to generalize under different regimes.
Dual-Phase Cooperative Agent Architectural Design
Single-stage LLM architectures are empirically shown to be insufficient for tasks requiring simultaneous generalization and fine-grained adaptation. DARA introduces a dual-phase paradigm:
- Few-shot Reasoner: Utilizes structured in-context prompts encoding historical episode data to generate initial allocation heuristics. This agent leverages the LLM’s inductive priors and compositional reasoning for rapid few-shot adaptation.
- Fine-grained Optimizer: Refines the preliminary allocation iteratively, exploiting feedback-driven optimization and marginal ROI signals from recent episodes. This agent updates allocations within a sliding window, focusing on local numerical optimization and reward balancing.
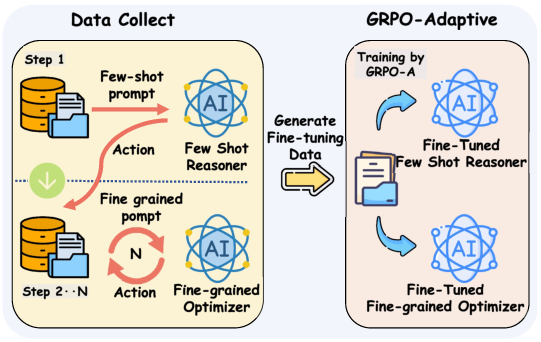
Figure 2: The DARA training workflow illustrates the separation of strategic initialization and subsequent fine-grained feedback-based adaptation.
This separation of concerns enables both rapid cold-start generalization and precise, numerically sensitive adjustment in evolving online markets.
RL Fine-tuning: GRPO-Adaptive Algorithm
To address LLMs' limitations in numerical precision and reasoning, the paper introduces GRPO-Adaptive—an extension of GRPO that periodically refreshes the reference policy used in KL regularization. Instead of a static anchor, the baseline is updated every M steps, coupling adaptability and stability in the optimization landscape.
The loss function integrates clipped advantage-weighted PPO-style optimization with dynamic KL regularization. This mechanism suppresses policy drift while allowing progressive improvement:
LGRPO-A(θ)=−Ladv(θ)+βDKL[πθ∥πref]
Reward design incorporates environment reward for marginal ROI balancing, constraint penalties for action validity, and bonus shaping for adaptive refinement based on prior performance. Controlled multi-environment sampling procedures in training prevent overfitting and promote robust generalization.
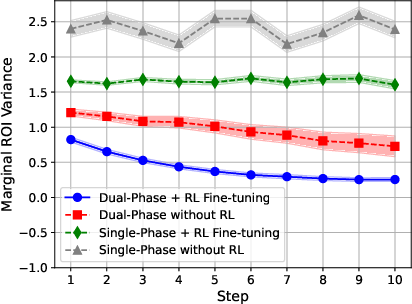
The framework is evaluated against several baselines, including ABPlanner', HiBid', Q-MCKP, DPO, and GPT-4o. Across all experiments, DARA demonstrates consistently lower marginal ROI variance than alternatives, indicating superior allocation stability and balanced exploitation of budget resources.
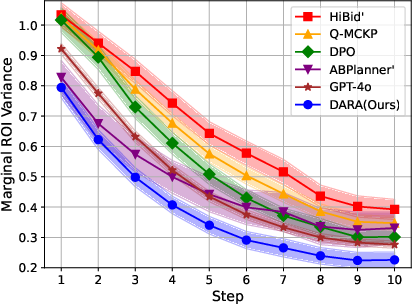
Figure 3: DARA achieves substantial reductions in marginal ROI variance, outperforming all baseline algorithms in dynamic online budget allocation.
Ablation studies decompose performance gains:
Sensitivity analyses show robustness across temporal granularities (number of budget periods) and demonstrate the critical role of KL reference update frequency: intermediate refresh intervals (e.g., M=60) maximize stability and convergence rates, while static or excessively frequent updates lead to degraded or unstable performance.
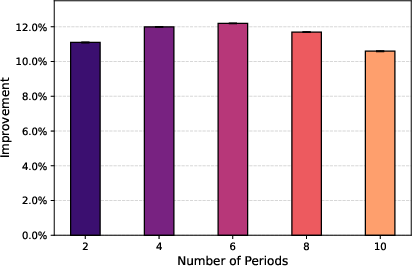
Figure 5: DARA consistently outperforms the strongest baseline across different temporal granularity settings, with improvements observed in all configurations.
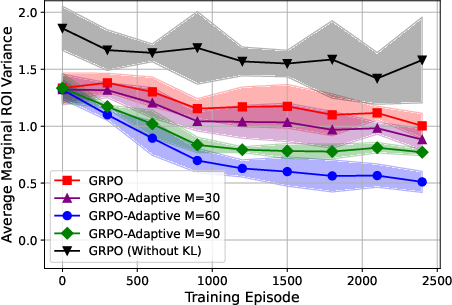
Figure 6: KL reference refresh frequency modulates training stability; periodic updates enable more adaptive and aligned policy optimization.
Implications and Future Directions
The DARA framework offers a modular approach for online budget allocation in scenarios dominated by few-shot conditions, diverse advertiser goals, and volatile environments. The explicit task decomposition into reasoning and adaptation agents aligns well with heterogeneous cognitive demands. RL fine-tuning with dynamic baseline regularization provides a path for overcoming LLM limitations in structured optimization and feedback integration.
Practically, DARA’s architecture is deployable in large-scale online advertising systems, enabling interpretability, sample-efficient adaptation, and stability under evolving auction conditions. Theoretically, the framework opens inquiry into broader multi-agent LLM ensembles, reinforcement learning for decision-theoretic symbolic reasoning, and advanced regularization schemes for policy alignment.
Future work may extend these paradigms to cross-channel, multi-agent budget optimization, adversarial scenarios, and increased interaction between human-in-the-loop feedback and automated model refinement, as RLHF and LLM capabilities further mature.
Conclusion
"DARA: Few-shot Budget Allocation in Online Advertising via In-Context Decision Making with RL-Finetuned LLMs" presents a dual-phase hybrid architecture that robustly balances few-shot generalization with fine-grained numerical optimization. The GRPO-Adaptive RL fine-tuning strategy effectively stabilizes learning trajectories while driving continual policy improvement. The empirical results substantiate strong claims on variance reduction and adaptation. This work represents a critical step toward integrating structured RL objectives with LLM reasoning for decision optimization in realistic, low-data industrial domains.