Rerank Before You Reason: Analyzing Reranking Tradeoffs through Effective Token Cost in Deep Search Agents
Abstract: Deep research agents rely on iterative retrieval and reasoning to answer complex queries, but scaling test-time computation raises significant efficiency concerns. We study how to allocate reasoning budget in deep search pipelines, focusing on the role of listwise reranking. Using the BrowseComp-Plus benchmark, we analyze tradeoffs between model scale, reasoning effort, reranking depth, and total token cost via a novel effective token cost (ETC) metric. Our results show that reranking consistently improves retrieval and end-to-end accuracy, and that moderate reranking often yields larger gains than increasing search-time reasoning, achieving comparable accuracy at substantially lower cost. All our code is available at https://github.com/texttron/BrowseComp-Plus.git
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how to make “deep research agents” faster and cheaper without hurting their accuracy. These agents use LLMs to solve hard questions by searching for information in steps, reading documents, and reasoning across them. The authors focus on a simple idea: before the agent reasons a lot, first “rerank” the search results to pick better documents to read. They also introduce an easy way to estimate cost called Effective Token Cost (ETC), which treats different kinds of model “reading/writing” as having different prices.
What questions did the researchers ask?
They had three main questions:
- If we sort (rerank) more of the search results up front, does the agent answer better in the end?
- Is it more cost-effective to spend extra “thinking” (reasoning) during search, or to spend that effort on smarter reranking first?
- How can we fairly measure the true cost of all this (including hardware, speed, and API pricing), not just count raw tokens?
How did they study it?
They use a controlled lab-style benchmark called BrowseComp-Plus. Instead of using a live web search engine (which can be unpredictable), they use a fixed, human-verified set of documents. This lets them cleanly test different strategies.
Here’s the basic setup, in everyday terms:
- Imagine you have to answer 830 tough questions.
- For each question, a search tool retrieves many candidate documents.
- Only a handful (the top 5) get passed to the LLM agent to read and think about.
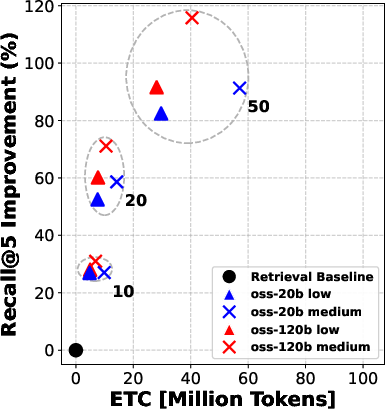
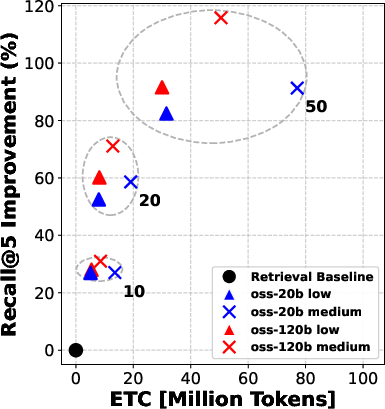
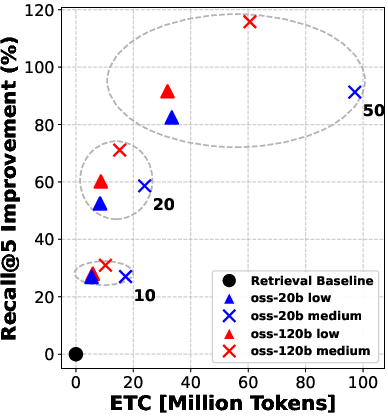
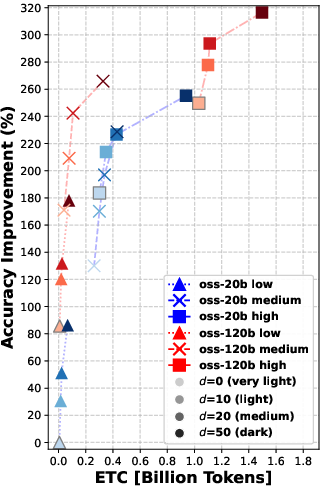
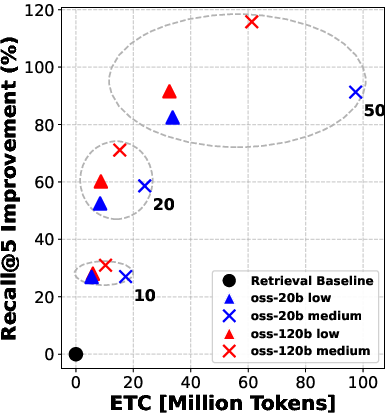
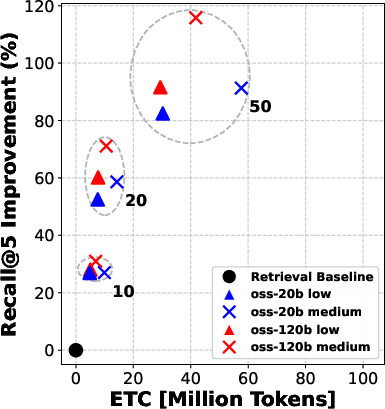
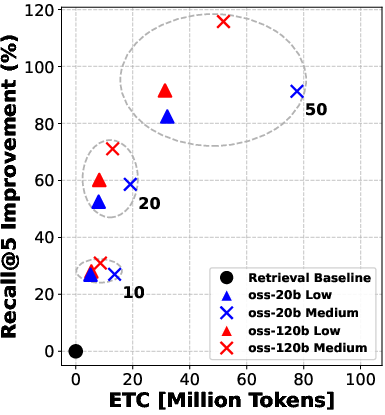
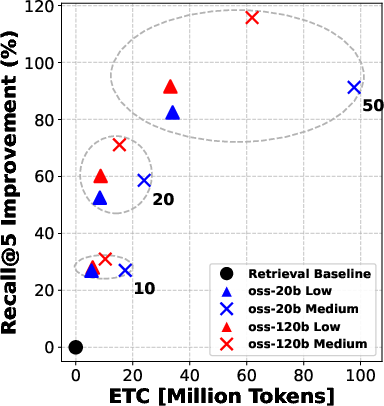
- The twist: before choosing those 5, the system can “rerank” the top 10, 20, or 50 candidates—like asking a smart assistant to sort the most promising documents first so the agent reads better ones.
They try two model sizes (a “smaller” model and a “bigger” model) and three “reasoning efforts” (low, medium, high), which roughly mean how much the model is allowed to think and write during each step.
Key terms explained:
- Reranking: You already have a list of search results. Reranking is like asking a smart friend to re-order them so the most relevant ones rise to the top.
- Tokens: Think of tokens as tiny pieces of text (parts of words). Models “read” input tokens and “write” output tokens. More tokens = more time/money.
- Effective Token Cost (ETC): Not all tokens cost the same in practice. Cached inputs (reused parts of past prompts) are cheaper; outputs (what the model writes as it “thinks”) are often slower and pricier. ETC is a weighted score that treats:
- non-cached input tokens as regular price,
- cached input tokens as discounted,
- output tokens as more expensive.
In a simple formula:
Here, α is a discount (e.g., 0.1 means cached input is 90% cheaper), and β is a markup (e.g., 3, 5, or 7 times more for outputs). This helps compare different setups fairly, whether on your own hardware or a paid API.
They measure:
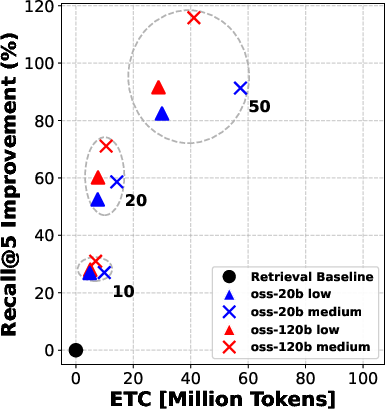
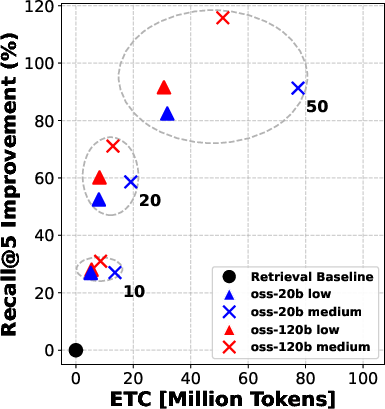
- Retrieval quality (how good the top documents are) with metrics like Recall and NDCG (think: “did we put the right stuff at the top?”).
- End-to-end accuracy (did the agent answer correctly?), plus how many search calls it needed and how well-calibrated its confidence was.
What did they find?
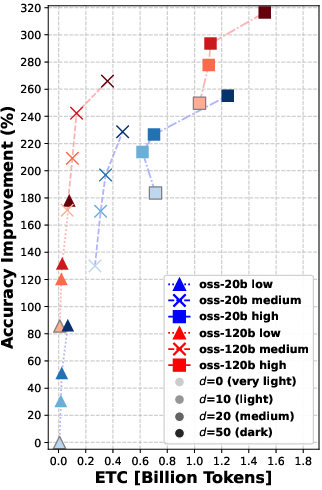
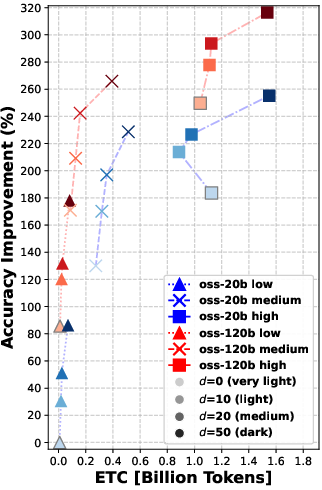
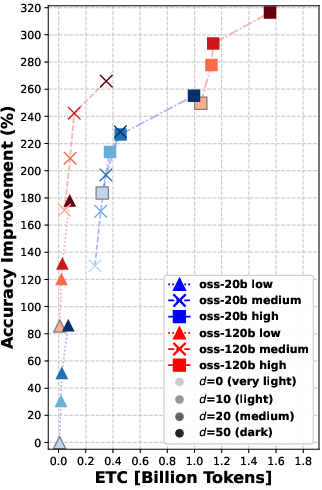
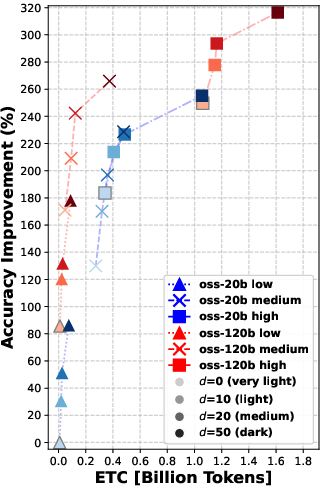
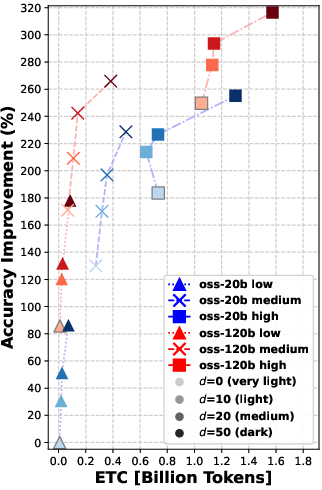
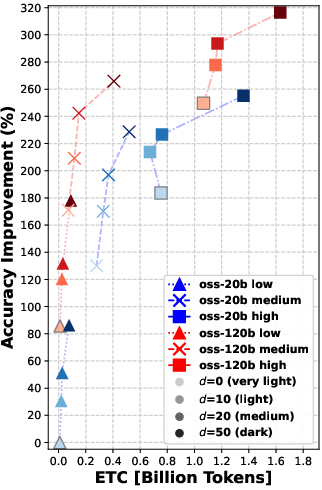
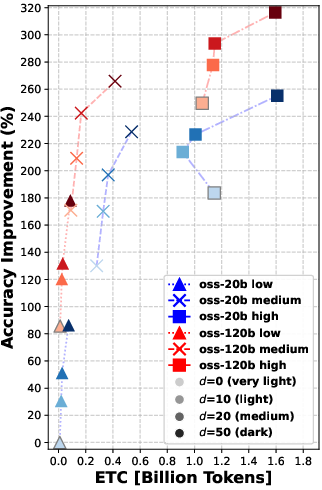
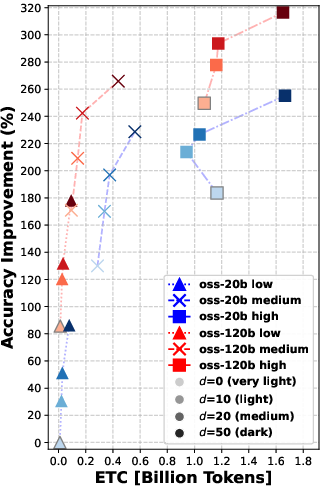
Overall message: Rerank before you reason.
More specifically:
- Reranking consistently improved the quality of documents that the agent read. Better documents in, better answers out.
- Even “moderate” reranking (e.g., looking at the top 10 or 20 results before picking the final 5) often helped more than simply letting the agent “think harder” during search.
- In many cases, doing moderate reranking achieved similar answer accuracy to heavy reasoning—at much lower cost (lower ETC).
- Using a larger model helps, but smarter reranking can let a smaller model with thoughtful settings catch up in retrieval quality.
- Pushing reranking too far (e.g., from 20 to 50 candidates) gives smaller extra gains—so there are diminishing returns if you go too deep.
- Reranking didn’t change how many times the agent had to search; it mainly made each search turn more useful by feeding in better evidence.
- Reranking also slightly reduced “calibration error” (how well the agent’s confidence matches reality), but the benefit got smaller as reranking grew deeper.
Why this matters:
- Output tokens (the model’s “thinking”) are expensive. Reranking uses mainly input tokens and a bit of reasoning, so it can be a cheaper way to boost performance.
- With ETC, you can tune α and β to reflect your setup (cached inputs cheaper, outputs pricier) and pick the most cost-effective mix.
What’s the impact?
If you’re building a research assistant or any multi-step search system:
- Spend some budget on reranking early, so the agent reads better documents.
- Don’t automatically crank up the agent’s “thinking” at search time; moderate reranking often gives you more accuracy per dollar.
- Use a cost measure like ETC that matches your real-world environment (on-prem hardware vs. API pricing). This helps you choose when to invest in reranking depth versus reasoning effort.
In short, a smart “sort first, think second” strategy makes deep research agents more accurate for less cost—and helps scale them to bigger workloads without breaking the bank.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Generalization to live web search: Results are derived on a fixed, human-verified corpus; it is unclear how reranking impacts effectiveness, latency variance, and robustness under noisy, dynamic web APIs (e.g., duplicates, spam, stale pages, variable API quality).
- Retriever dependence: All experiments use qwen3-embedding-8b; the extent to which reranking gains and token-cost tradeoffs hold across other retrievers (e.g., BM25, ColBERT/Jina-ColBERT, DPR, hybrid dense–sparse) remains untested.
- LLM family dependence: Both search and reranking rely on the same OpenAI oss-20b/oss-120b families; the benefits and costs with different LLM families (open-source vs. proprietary, smaller distilled models, multilingual models) are not evaluated.
- Reranker training vs. zero-shot: Reranking is zero-shot with prompt-based listwise ranking; whether supervised/fine-tuned rerankers or distillation into smaller models can match accuracy at lower ETC is unknown.
- Reranking prompt design: The sensitivity of reranking quality and cost to prompt wording, list formatting, and reasoning styles (e.g., chain-of-thought vs. brief rationales) has not been systematically ablated.
- Fixed top-k to the agent: The pipeline always passes top-5 evidence to the search agent; the optimal k (and its dynamic selection per query) for accuracy–cost tradeoffs remains unexplored.
- Fixed document truncation: Every candidate document is truncated to 512 tokens; the impact of chunk size, chunking strategy (overlap, summarization, selective passages), and adaptive truncation on retrieval/accuracy and ETC is unknown.
- Sliding-window reranking merging policy: For d=50, sliding windows with stride 10 are used; the effect of different window sizes, strides, and cross-window aggregation/merging strategies on ranking quality and cost is not analyzed.
- Listwise vs. pairwise pointwise ranking: Only listwise reranking is studied; comparisons with pairwise or pointwise LLM reranking (and combinations thereof) could alter the cost–effectiveness frontier.
- Variable-depth reranking: Reranking depth d is fixed globally; a learned policy to choose d per query (or early-stop reranking when confidence is high) could improve ETC but is not explored.
- Reranking-time reasoning gating: The study suggests “low reasoning” is generally best, but does not investigate per-query gating to detect when heavier reranker reasoning is warranted.
- Agent behavior coupling: The paper reports little change in the number of search calls with reranking; deeper analysis of how reranking influences query decomposition, step planning, and termination decisions is missing.
- Per-query difficulty stratification: Results are averaged across 830 queries; stratifying by difficulty (e.g., hop count, evidence dispersion) to see when reranking helps most is not provided.
- Error type analysis: Beyond Accuracy, Recall, and Calibration Error, the paper does not analyze failure modes (e.g., missing evidence, misaggregation, hallucinations) to target specific improvements.
- LLM-as-a-judge reliability: Accuracy is judged by oss-120b with five repetitions; sensitivity to judge model choice, prompt, and adjudication protocol (and human cross-checks) remains uncertain.
- Calibration mechanisms: Reranking reduces calibration error, but no explicit calibration method (e.g., post-hoc calibration, confidence training) is studied to explain or amplify these gains.
- ETC parameter calibration: The Effective Token Cost weights (α, β) are proxies; mapping ETC to measured TPS, wall-clock latency, and actual dollar costs (per GPU/API tier) is not validated across diverse infrastructures.
- ETC sensitivity and optimization: A principled sensitivity analysis linking α and β to different caching regimes, output rates, and concurrency levels—and an optimization procedure for selecting budgets per deployment—are absent.
- Latency and throughput metrics: The study focuses on token cost; wall-clock latency, throughput under concurrency, cold-start effects, and GPU utilization are not reported, limiting operational guidance.
- Caching strategies: Only implicit prefix reuse is modeled; the impact of specific caching architectures (prompt cache granularity, KV reuse, cache hit rates) on ETC and accuracy is not tested.
- History management: Context is retained with automatic truncation; the interactions between explicit history compression/summarization policies and reranking depth on both accuracy and ETC are unexplored.
- Dynamic budget allocation: There is no mechanism to adaptively allocate compute between reranking and search reasoning per query (e.g., bandits/RL), despite clear tradeoffs demonstrated.
- Top-100 one-shot vs. multi-turn realism: One-shot reranking evaluations use top-100 candidates and evidence documents as relevance; alignment of these findings with multi-turn, evolving queries (and with gold-answer relevance) needs deeper validation.
- Robustness to adversarial/noisy corpora: The effect of reranking on resilience to adversarial passages, boilerplate, or heavy redundancy is unknown.
- Cross-lingual and domain generalization: The benchmark settings are monolingual and single-domain; performance and cost tradeoffs in multilingual or domain-specific corpora (e.g., medical, legal) are not assessed.
- Safety and citation quality: Whether reranking reduces unsupported claims, improves citation precision/coverage, and mitigates hallucination in final answers is unmeasured.
- Energy and environmental cost: ETC abstracts hardware differences; energy consumption, carbon footprint, and eco-efficiency under different pipeline configurations are not reported.
- Reproducibility across hardware: Inference runs on A6000 and H200 GPUs with separate devices for search/reranking; how conclusions change under co-located workloads, memory constraints, or different GPU classes is unclear.
- Interaction with other efficiency techniques: The paper references prompt caching and AgentDiet but does not test joint integration (e.g., trajectory reduction plus reranking) to measure combined gains.
- Policy learning for reranking depth and k: Learning policies to jointly choose reranking depth d and evidence set size k conditioned on query/evidence features is an open direction.
- Public benchmarks beyond BrowseComp-Plus: Validation on other deep-research benchmarks (e.g., variants of BrowseComp, task-specific multi-hop datasets) is needed to confirm external validity.
Practical Applications
Overview
This paper analyzes how to allocate test-time computation in deep research agents by introducing an Effective Token Cost (ETC) metric and systematically evaluating listwise reranking across model sizes, reasoning budgets, and depths. Core findings show that adding a reranking stage consistently improves retrieval quality, reduces calibration error, and yields comparable or better end-to-end accuracy than increasing the agent’s reasoning budget—often at substantially lower token cost. These insights translate into concrete, cost-aware design patterns for RAG and agentic search systems and suggest new efficiency-focused tools and policies.
Immediate Applications
The following applications can be deployed now using existing tooling (e.g., RankLLM, vLLM, BrowseComp-Plus codebase) and common LLM APIs or on-prem models.
- Cost-optimized enterprise RAG and agentic search pipelines — Software/Enterprise IT
- Use listwise LLM reranking to pre-filter retrieved candidates to the top-5 before agent reasoning; adopt moderate reranking depth (d ≈ 10–20) with low reranker reasoning and reserve higher reasoning for the search agent only when needed.
- Potential workflow: retrieve top-100 via a dense retriever; rerank top-d with sliding windows; pass top-5 to agent; monitor ETC to tune α (cache discount) and β (output premium).
- Tools: RankLLM, vLLM, qwen3-embedding or similar dense retrievers, KV/prompt caching.
- Assumptions/Dependencies: access to a vector store; support for caching; fixed or reasonably stable corpora; availability of LLMs with sufficient context lengths.
- Customer support and knowledge base assistants — Software/Customer Support
- Reduce token spend and improve answer reliability by reranking at d=10–20 before handing context to the assistant; expect lower calibration error (more consistent confidence).
- Tools: RankLLM integration in helpdesk platforms; ETC dashboards for cost tracking.
- Assumptions/Dependencies: domain-specific retriever quality; consistent document truncation strategy (e.g., 512 tokens).
- Legal, compliance, and financial due diligence — Legal/Finance
- Improve retrieval fidelity and reduce hallucinations in multi-document analyses by inserting listwise reranking and limiting agent context to the highest-quality evidence.
- Tools: reranking plug-ins for e-discovery platforms; ETC-based budget gates; LLM-as-a-judge for QA spot checks.
- Assumptions/Dependencies: curated corpora or high-quality retrievers; auditability requirements for confidence and calibration.
- Healthcare literature and clinical guideline review — Healthcare
- Pre-filter large candidate sets from medical databases with LLM rerankers to reduce reasoning tokens while maintaining accuracy; use ETC to budget compute on shared hospital infrastructure.
- Tools: pipeline orchestration with reranking modules; caching to lower prefill cost.
- Assumptions/Dependencies: expert oversight; compliance constraints; validated retriever coverage.
- Research group benchmarking and methods courses — Academia/Education
- Use ETC as a teaching and evaluation metric for efficiency–effectiveness tradeoffs; reproduce BrowseComp-Plus experiments and extend to local datasets for lab projects.
- Tools: public codebase (BrowseComp-Plus), vLLM; RankLLM; LLM-as-a-judge prompts.
- Assumptions/Dependencies: reproducible judging; clear documentation of α and β choices.
- MLOps cost and performance observability — Software/MLOps
- Add ETC to monitoring dashboards to track token spend across non-cached input, cached input, and output tokens; allocate budgets toward reranking (cheap gains) vs. agent reasoning (expensive gains).
- Tools: ETC counters; TPS-aware metrics; per-stage token accounting.
- Assumptions/Dependencies: token-level telemetry; separation of reranking and search agents on distinct GPUs to avoid KV-cache interference.
- Search and knowledge management systems — Search/Enterprise KM
- Ship listwise LLM reranking as a standard stage (window size ~20 with sliding windows for d=50); default to d=10–20 with low reasoning for best cost–benefit.
- Tools: RankLLM adapters for vector DB vendors; retriever+rerranker bundles.
- Assumptions/Dependencies: sustained retrieval latency budgets; controllable context growth.
- Personal research assistants and browser extensions — Consumer Software/Daily Life
- Rerank page summaries or search results before passing a compact evidence set to the assistant, lowering compute bills on API usage.
- Tools: browser plugins; ETC-based usage controls; small local rerankers.
- Assumptions/Dependencies: access to summaries/snippets; API pricing tiers that reward caching.
- Public-sector procurement guidelines for AI services — Policy
- Encourage vendors to report ETC and calibration error; prioritize solutions that use reranking to reduce output-token-heavy reasoning and carbon footprint.
- Tools: procurement templates; reporting standards (ETC, calibration, search calls).
- Assumptions/Dependencies: compliance with transparency requirements; availability of energy/cost reporting.
Long-Term Applications
These applications are feasible but require further research, scaling, integration with live search, or productization.
- Adaptive ETC-aware orchestration — Software/MLOps
- Agents that dynamically tune reranking depth (d), choose reranker model size, and adjust reasoning budgets in response to live ETC signals and accuracy targets.
- Potential products: auto-tuning controllers; cost-aware schedulers; policy engines.
- Assumptions/Dependencies: reliable online evaluation; feedback loops; multi-objective optimization.
- Hybrid model allocation (small reranker + large reasoner) — Software/AI Platforms
- Systematically pair lightweight rerankers with stronger search agents for optimal cost–effectiveness; learn routing policies across domains.
- Potential products: orchestrators that benchmark pairings per workload.
- Assumptions/Dependencies: cross-model quality stability; domain transferability.
- Variable-sized evidence selection via learned relevance assessors — Software/IR
- Replace fixed top-d with dynamic, learned filters that de-duplicate context and select just-enough evidence before reasoning, improving both efficiency and accuracy.
- Potential products: relevance assessors integrated with retrievers; context compaction layers.
- Assumptions/Dependencies: robust training signals; avoidance of over-filtering; domain-specific tuning.
- Live web search generalization and API integration — Search/Software
- Validate reranking and ETC tradeoffs on volatile web content and heterogeneous APIs; develop standardized evaluation harnesses.
- Potential products: web agent benchmarks; API cost simulators aligned with ETC.
- Assumptions/Dependencies: access to search APIs; quota limits; content drift handling.
- History compression and summarization modules — Software/NLP
- Combine reranking with explicit message history compression to further reduce tokens in deep multi-turn interactions without harming accuracy.
- Potential products: history compressors; summary caches integrated with ETC accounting.
- Assumptions/Dependencies: stable summarization quality; low memory regressions.
- Distilled rerankers and specialized small models — Software/ML Research
- Distill listwise reranking skill into compact models for on-device or edge deployments, preserving most gains at lower cost.
- Potential products: 100–500M reranker checkpoints; SDKs for vector DBs.
- Assumptions/Dependencies: high-quality distillation datasets; robust zero-shot behavior.
- Carbon-aware and price-aware agent scheduling — Energy/Policy/Cloud
- Use ETC (and regional carbon intensity) to time-shift heavy decoding workloads and prefer reranking-heavy configurations in high-price/high-carbon windows.
- Potential products: carbon-aware schedulers; sustainability SLAs using ETC.
- Assumptions/Dependencies: access to real-time energy and pricing data; orchestration across regions.
- Standardized pricing and transparency for LLM providers — Policy/Cloud
- Encourage tiered pricing that clearly differentiates cached vs. non-cached inputs and output premiums; require ETC-style disclosures for fair comparisons.
- Potential outcomes: procurement standards; regulator guidance; benchmark reporting.
- Assumptions/Dependencies: provider cooperation; interoperability of metrics.
- Domain-specific co-pilots for finance, biotech, and law — Finance/Healthcare/Legal
- Productize cost-aware deep research pipelines with reranking defaults, dynamic budgets, and calibration tracking for high-stakes domains.
- Potential products: diligence co-pilots; clinical literature triage assistants; case law search co-pilots.
- Assumptions/Dependencies: domain corpora; validation workflows; human-in-the-loop review.
- Vendor integrations in vector databases and search platforms — Software/IR
- Native support for listwise LLM reranking (windowed ranking, sliding stride, ETC counters) as first-class features.
- Potential products: “LLM reranker” modules; ETC analytics in DB consoles.
- Assumptions/Dependencies: performance guarantees; customer education on α/β tuning.
Cross-cutting assumptions and constraints
- Results are derived from a fixed, human-verified corpus (BrowseComp-Plus); performance may differ with live web content and external APIs.
- Same model family used for search and reranking in experiments; mixed-model strategies need further validation.
- LLM-as-a-judge was used for accuracy; operational deployments may prefer human audits or task-specific metrics.
- Benefits depend on effective caching (α) and decoding costs (β); platform differences (local vs. API) affect ETC calibration.
- Context management (e.g., truncation at 512 tokens per document; 128k maximum conversation length) influences both costs and effectiveness.
Glossary
- Agentic search: A search paradigm where an LLM iteratively issues queries and reasons over retrieved evidence. "LLMs perform agentic search by iteratively generating queries and invoking a retrieval tool."
- Auto-regressive decoding: The token-by-token generation process in LLMs that is computationally intensive and slower than prefill. "the resource-intensive auto-regressive decoding phase."
- Caching discount (α): The ETC weight that discounts the cost of cached input tokens relative to non-cached tokens. "by adjusting the caching discount ()"
- Calibration Error: A metric that measures the mismatch between a model’s confidence and its correctness. "which reports Accuracy (measured using an LLM-as-a-judge), Recall, the number of Search Calls, and Calibration Error"
- Effective Token Cost (ETC): A metric combining non-cached input, discounted cached input, and weighted output tokens to compare efficiency–effectiveness tradeoffs. "we introduce a novel, simple and realistic Effective Token Cost (ETC) metric"
- KV-cache: A cache of key/value attention states used to speed up generation and improve throughput. "to avoid KV-cache and throughput interference."
- Listwise reranking: A ranking approach that jointly orders a set of retrieved candidates in one step, often improving retrieval quality. "we analyze listwise reranking~\cite{rankgpt, rankllm} in deep search"
- LLM-as-a-judge: An evaluation method where an LLM is prompted to assess answer correctness. "Accuracy (measured using an LLM-as-a-judge)"
- Multi-hop queries: Questions requiring multiple retrieval and reasoning steps across different pieces of evidence. "answer complex, multi-hop queries"
- NDCG@k: Normalized Discounted Cumulative Gain at cutoff k, a ranking metric that rewards placing relevant items near the top. "We assess retrieval effectiveness using Recall@5, Recall@10, NDCG@5, and NDCG@10."
- Output premium (β): The ETC weight that increases the relative cost contribution of generated (output) tokens. "and the output premium ()"
- Prefill: The initial inference phase where input tokens are processed before generation, typically faster than decoding. "α models the efficiency of prefix reuse during prefill"
- Prefix reuse: Reusing shared prompt prefixes across steps to reduce repeated computation and input token cost. "Techniques such as prompt caching and prefix reuse reduce input costs"
- Prompt caching: Storing and reusing processed prompt tokens to reduce latency and token cost. "Techniques such as prompt caching~\cite{gim2024prompt} and prefix reuse reduce input costs"
- Recall@k: The fraction of relevant items found within the top-k retrieved results. "Recall@5, Recall@10"
- Reranking depth: The number of top retrieved candidates considered in the reranking stage. "with reranking depth of "
- Retrieval-Augmented Generation (RAG): A framework where external documents are retrieved to condition and improve generation. "single-round retrieval-augmented generation (RAG)"
- Sliding-window strategy: Processing long candidate lists by reranking in overlapping windows to handle larger d. "for , a sliding-window strategy with a stride of 10 is used."
- Tokens per second (TPS): A throughput measure of how quickly tokens are processed or generated. "tokens per second (TPS)"
- vLLM: A high-throughput LLM serving engine optimized for efficient inference. "All inference is performed using vLLM (v0.13.0)"
- Zero-shot: Using a model without task-specific examples or fine-tuning for the task. "zero-shot listwise rerankers"
Collections
Sign up for free to add this paper to one or more collections.

