- The paper introduces MARA, a framework that employs dynamic multi-agent refinement to enhance factuality, personalization, and coherence in conversational systems.
- MARA uses a planner agent to adaptively select and sequence specialized agents for fact-checking, persona alignment, and discourse coherence.
- Experimental results demonstrate that MARA significantly outperforms single-agent and static multi-agent approaches on benchmarks like PersonaChat and FoCus.
Adaptive Multi-Agent Response Refinement in Conversational Systems
Overview and Motivation
The paper introduces MARA (Multi-Agent Refinement with Adaptive agent selection), a modular framework to improve response quality in LLM-driven conversational systems by employing multiple specialized agents for post-generation refinement. The approach is motivated by the limited efficacy of single-agent self-refinement: previous work demonstrates that an LLM refining its own output tends to amplify initial biases and struggles to holistically address complex criteria such as factuality, personalization, and discourse-level coherence. MARA decomposes response assessment and revision across three dedicated agents—fact-checking, persona alignment, and coherence—coordinated dynamically according to conversational context via a planner agent.
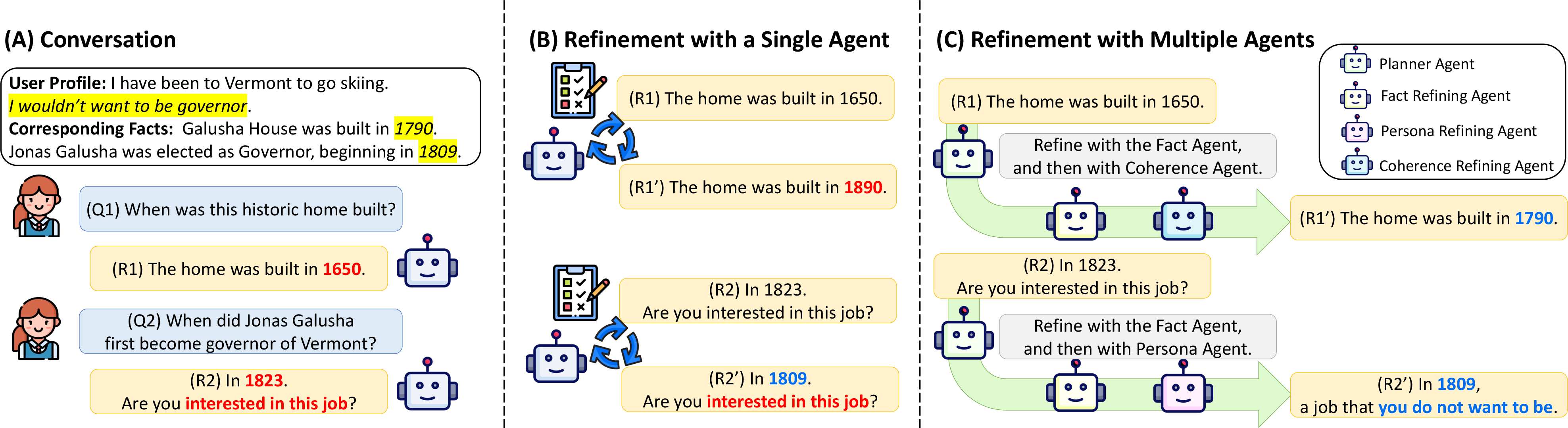
Figure 1: Illustration of single-agent failure modes and the modular collaborative refinement process in MARA, showing agent specialization and dynamic sequencing.
Methodology
Let ri denote the response to user query qi, generated by an LLM conditioned on preceding context. In MARA, an initial response is subjected to a secondary pipeline involving:
- Fact-Refining Agent (Afact): Ensures factual grounding, mitigates hallucinations, and verifies explicit knowledge requirements.
- Persona-Refining Agent (Apersona): Aligns responses with user profiles, preferences, and conversational style.
- Coherence-Refining Agent (Acoherence): Enforces logical and discourse consistency spanning multi-turn exchanges.
Each agent is an unsupervised LLM instance, prompted with role-specific instructions. The refining process may follow either simultaneous or sequential collaboration strategies:
- Simultaneous Aggregation: All agents independently refine the response in parallel, feeding their outputs to a "finalizer" agent.
- Static Sequencing: Agents operate in a predetermined order (e.g., Afact→Acoherence→Apersona), each building on the previous outcome.
- Dynamic Sequencing (MARA): A planner agent (Aplanner) analyzes the query and initial output, then adaptively selects relevant agents and their optimal order, with stepwise justifications informing each refinement stage.
The planner’s decisions are conditioned on the specific requirements per conversational turn, allowing different queries (even in the same conversation) to invoke tailored refinement strategies.
Implementation
- Base LLM: Claude Sonnet 3 or 3.5 (supporting evaluation with GPT-4o-mini, LLaMA 3.1 8B/70B for cross-model validation).
- Modular prompts: Each agent instantiated with templates detailing its responsibilities and evaluation criteria.
- Planner agent: Receives the query, conversation history, and initial response, then outputs agent selection and order, accompanied by rationale for each step.
Experimental Results
Comprehensive evaluations are conducted on datasets representing distinct conversational demands:
- PersonaChat: User persona alignment.
- INSCIT: Fact grounding via Wikipedia context.
- FoCus: Joint persona and knowledge requirements.
MARA consistently outperforms both single-agent (Self-Refine, SPP) and alternative multi-agent (LLMvLLM, MADR, MultiDebate) baselines across coherence, groundedness, naturalness, and engagingness metrics, as measured by G-Eval and further validated through human annotation:
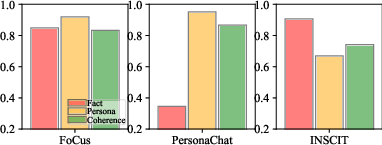
- FoCus: MARA achieves 74.51 overall score compared to 60.47 (SPP, single-agent) and 54.81 (MultiDebate, multi-agent).
- PersonaChat: MARA’s overall score is 62.00, significantly higher than Self-Refine (58.41) and MADR (23.21).
- Human ratings show especially strong alignment between G-Eval and engagingness but less correlation for "naturalness," reflecting metric limitations in modeling conversational subtlety.
Ablation studies further demonstrate:
Discussion
Trade-Offs and Resource Implications
- Computational Overhead: The multi-agent approach increases model invocation frequency, with the planner's design and agent specialization driving efficiency. Optimization (smarter planner, lightweight agents) is suggested for scalable deployment.
- Model Specialization: Assigning distinct LLMs with strengths in factuality or discourse coherence further enhances composite performance beyond single-model setups.
- Robustness: MARA generalizes across underlying LLM architectures and scales to domain-specific contexts (e.g., Ubuntu Dialogue Corpus), augmenting outputs even for already powerful models.
Limitations
- The planner currently relies on unsupervised LLM induction. Performance could be further enhanced by supervised fine-tuning on agent selection/orchestration data.
- G-Eval’s limitations necessitate broader evaluation—including metrics for social bias, safety, and user engagement beyond standardized quality components.
Implications and Future Directions
The explicit division of revision responsibilities among specialized agents enables modular system design, yielding enhanced explainability, fine-grained control, and potential for plug-and-play incorporation of external tools (e.g., RAG). This paradigm is extensible to scenarios demanding not only factual and persona alignment but also safety, style adaptation, and domain-specific requirements. Further improvements in orchestration algorithms (planner agent) and agent specialization (fine-tuned or tool-augmented LLMs) are anticipated to drive practical deployment for real-world conversational AI systems.
Case Studies
Included qualitative analyses highlight MARA's strengths: In contrast to SPP or MADR, which may fail to recognize context, hallucinate facts, or miss alignment with user interests, MARA delivers responses that integrate precise factual details and evoke user engagement through tailored follow-up questions and personalized narrative, while maintaining strict coherence across turns.
Conclusion
Adaptive Multi-Agent Response Refinement establishes a robust framework for conversational LLMs to generate quality-controlled, contextually aware, and personalized outputs. Modular agent specialization and dynamic planning yield substantial improvements over monolithic and static multi-agent approaches. The findings strongly support the utility of MARA for systems requiring nuanced conversational quality and open avenues for scalable multi-agent orchestration, tighter integration of domain-specific modules, and research into supervised planner optimization.