Audio Outperforms Text for Visual Decoding
Abstract: Decoding visual semantic representations from human brain activity is a significant challenge. While recent zero-shot decoding approaches have improved performance by leveraging aligned image-text datasets, they overlook a fundamental aspect of human cognition: semantic understanding is inherently anchored in the auditory modality of speech, not text. To address this, our study introduces the first comparative framework for evaluating auditory versus textual semantic modalities in zero-shot visual neural decoding. We propose a novel brain-visual-auditory multimodal alignment model that directly utilizes auditory representations to encapsulate semantics, serving as a substitute for traditional textual descriptors. Our experimental results demonstrate that the auditory modality not only surpasses the textual modality in decoding accuracy but also achieves higher computational efficiency. These findings indicate that auditory semantic representations are more closely aligned with neural activity patterns during visual processing. This work reveals the critical and previously underestimated role of auditory semantics in decoding visual cognition and provides new insights for developing brain-computer interfaces that are more congruent with natural human cognitive mechanisms.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy Explanation of “Audio Outperforms Text for Visual Decoding”
What is this paper about?
This paper asks a simple but important question: If we try to guess what a person is looking at by reading their brain signals, is it better to use spoken language (audio) or written language (text) to help the computer understand the meaning? The authors find that using speech-like audio features helps the computer do a better job than using text.
What did the researchers want to find out?
The study focused on one main idea: our brains evolved to understand language mostly through hearing, not reading. So the researchers wanted to know:
- Is it easier to match brain activity with spoken language information than with written text?
- Does using audio make the computer faster and more accurate at figuring out what someone saw?
How did they test this? (In simple terms)
Think of the system like a team of translators trying to understand a person’s brain:
- One translator listens to brain signals (from EEG, a cap with sensors that records electrical activity).
- One looks at the picture the person saw (image features).
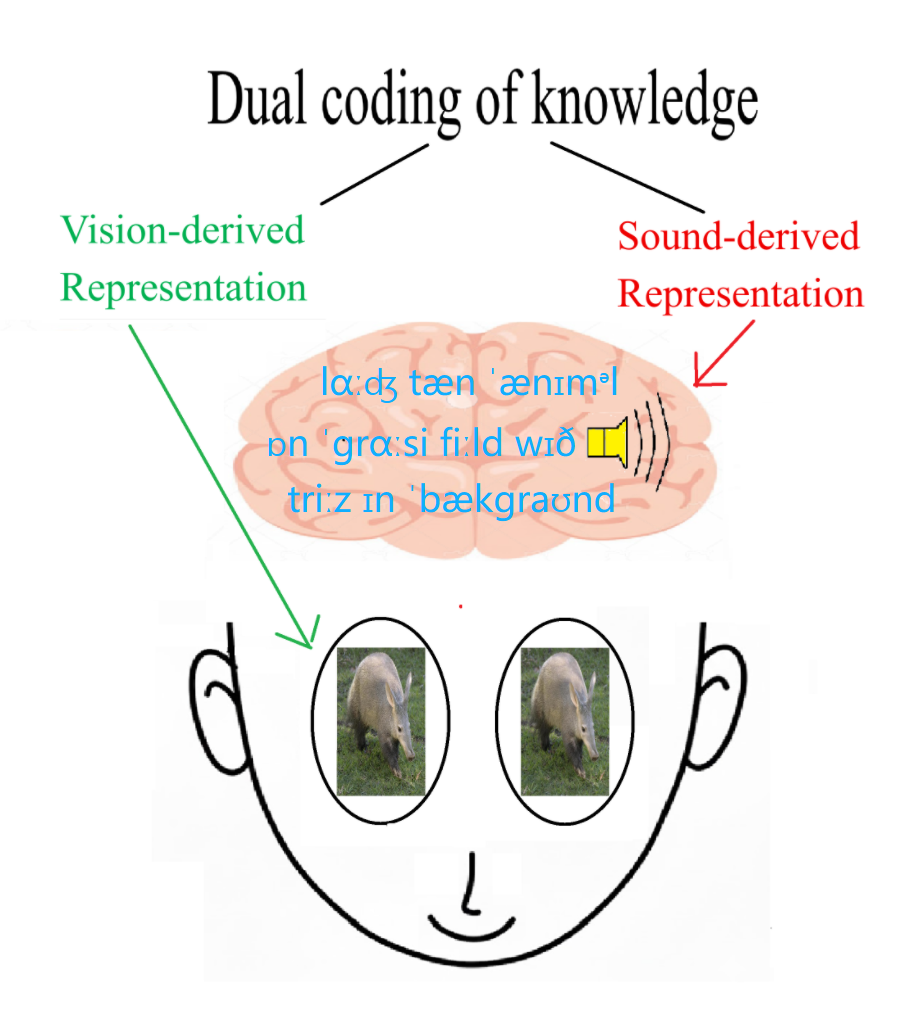
- One listens to language—but here’s the twist: instead of reading text like “a red apple,” the system “listens” to an audio version of that description. The audio features come from a model called CLAP that turns sounds into numbers a computer can use.
They combine all three using a kind of “shared dictionary” called a latent space, learned by a model called a Variational Autoencoder (VAE). Here’s the everyday meaning of the technical tools they used:
- Variational Autoencoder (VAE): Like compressing a big idea into a short code, then reconstructing it. If the code keeps the important meaning across brain, image, and audio, the system learned well.
- Mixture-of-Products-of-Experts (MoPoE): Imagine a committee of experts, each specializing in brain, image, or audio. MoPoE combines their opinions smartly, whether one, two, or all three are present.
- Mutual Information (MI): A way to make sure the shared code keeps the important bits from each source and that different sources agree about what’s going on—like checking that everyone’s telling the same story.
They trained this system on a dataset where:
- People looked at lots of object pictures (like cats, chairs, cars).
- Their brain signals were recorded by EEG.
- Pictures had descriptions that were turned into speech using text-to-speech, then converted into audio features with CLAP.
- Image features came from a brain-inspired vision model (CORnet-S).
After training, they did a “zero-shot” test. That means they asked the system to recognize categories it hadn’t been trained on—like recognizing a new type of object using what it learned before. This is like being able to guess a new animal’s category after seeing similar animals before.
What did they find?
They compared two versions of the system: one using text, and one using audio.
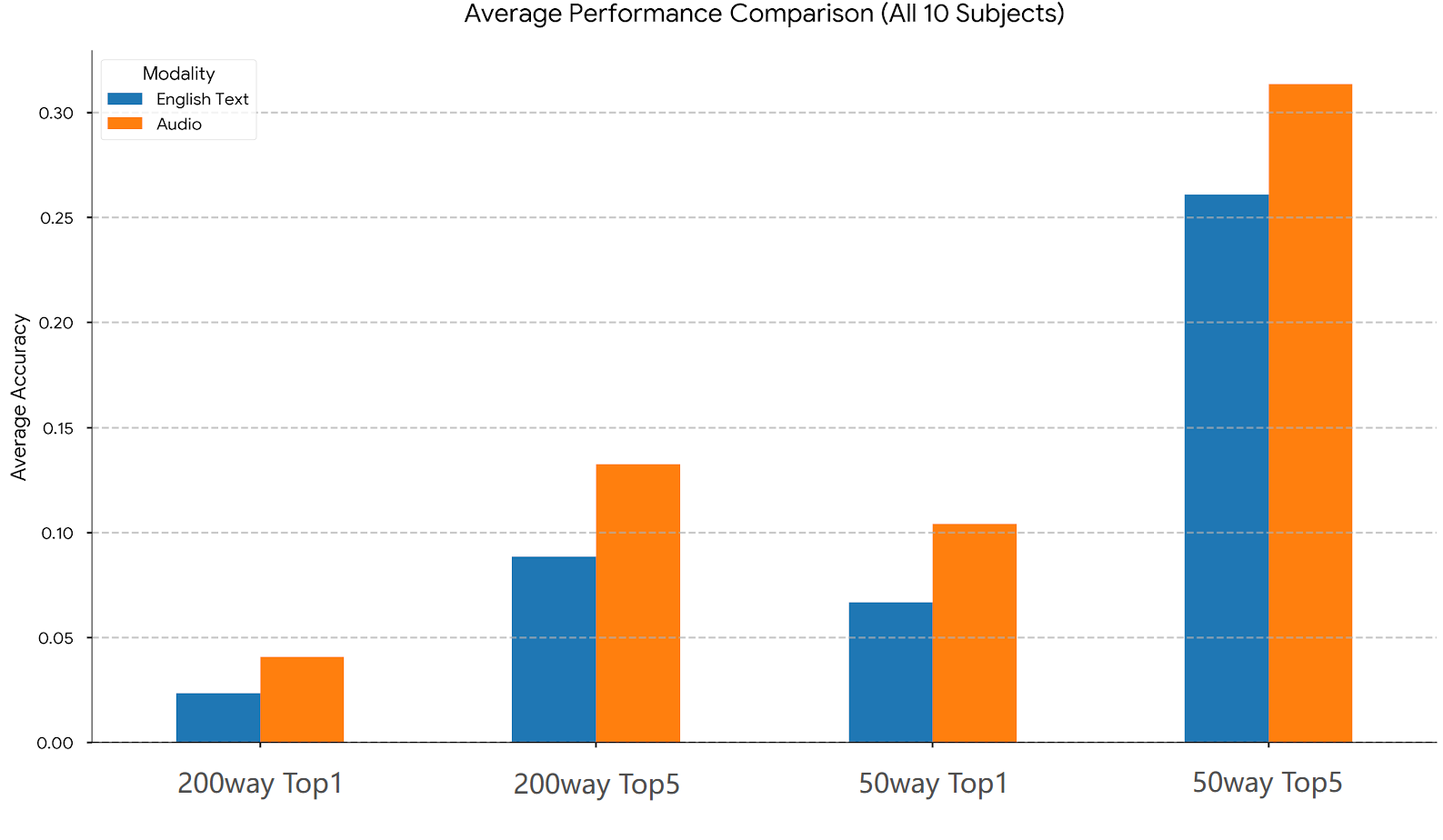
Here are the key results (averaged across 10 people):
- Hard 200-category test (Top-1 accuracy):
- Audio: about 4.1%
- Text: about 2.3%
- Easier 50-category test (Top-1 accuracy):
- Audio: about 10.4%
- Text: about 6.7%
- When the system could guess 5 answers (Top-5 accuracy), audio also beat text in both tests.
Why these numbers matter:
- The tasks are very hard (especially 200 categories with zero-shot learning), so even a few percentage points are a real improvement.
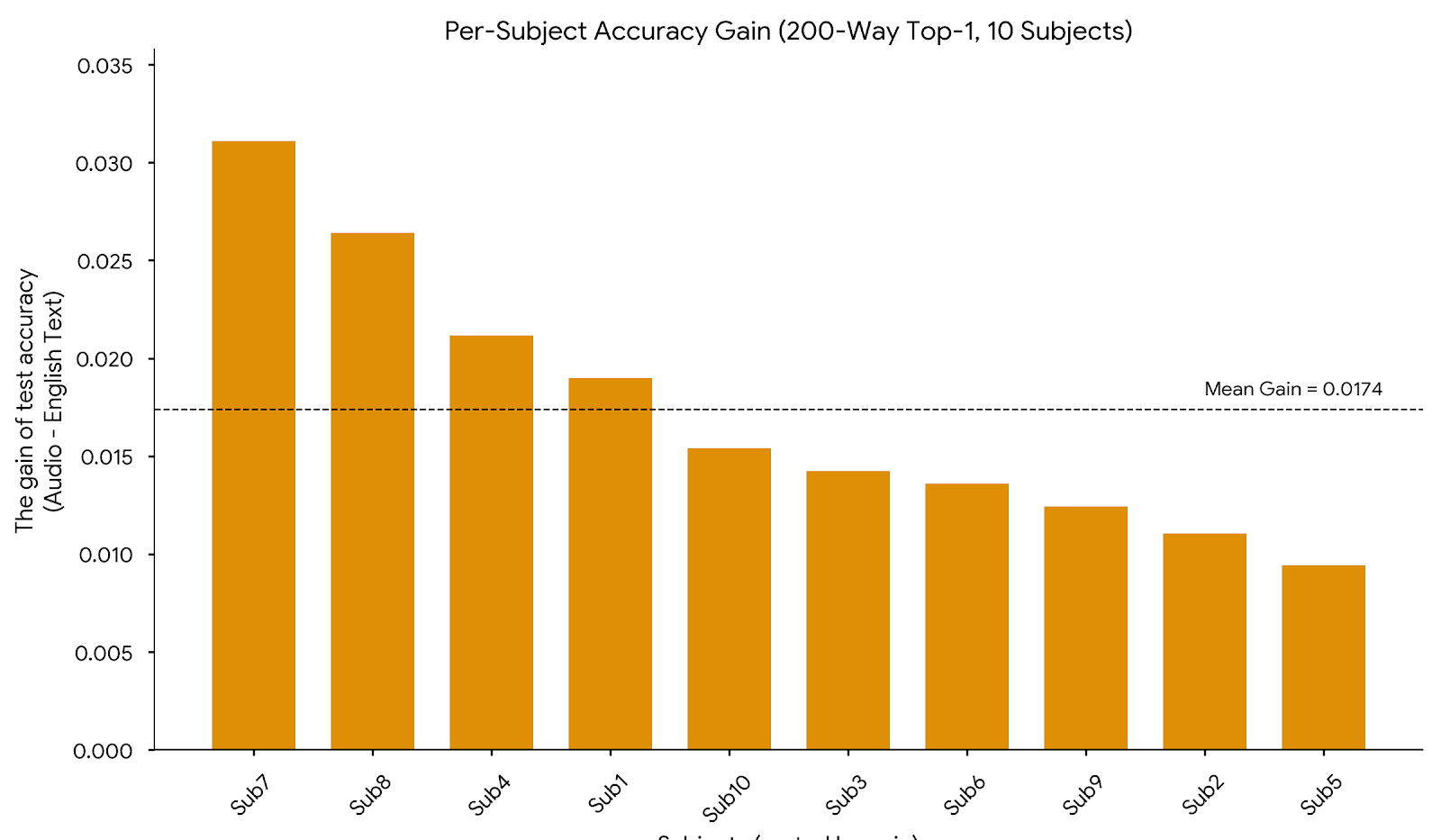
- Audio didn’t just win on average—it outperformed text for all 10 participants, showing the effect is consistent.
Speed and efficiency:
- Training with audio features was faster: about 10.7 hours vs. 17.7 hours for text.
- Audio features were smaller (512 numbers) than text features (768 numbers), which helps speed and memory.
Why is this important?
- It supports how the brain naturally works. We mostly learn and think with spoken language, not just written words. The audio version of language seems to match brain activity better than text does.
- It can make brain-computer interfaces more natural and efficient. Systems that help people communicate or control devices using brain signals may work better if they use speech-like information.
- It suggests a shift in how we build AI that connects to the brain: don’t just use text—use audio to capture the rhythm, tone, and timing that text alone can’t show.
Final thoughts and future impact
This research shows that using speech signals can improve how well computers “read” brain activity about what we see. That could lead to:
- Better tools for people who can’t speak, by decoding intended meanings more accurately.
- More realistic, brain-aligned AI systems that understand humans the way our brains actually process language.
- New directions for science: testing natural human speech, other languages, and combining EEG with brain scans that show where activity happens in the brain.
One note: the audio used here was created by text-to-speech, not real human recordings. Future work with natural speech could make the results even stronger.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps, uncertainties, and unexplored issues left unresolved by the paper, aimed to guide future research.
- No auditory stimuli were presented during EEG recording; the cognitive claim that auditory semantics align more naturally with neural processing is untested without experiments where subjects actually hear speech synchronized with visual stimuli.
- The audio modality was generated via text-to-speech (TTS), but critical details are missing (TTS engine, voice characteristics, prosody, speech rate, normalization, audio duration). It remains unknown whether the observed gains persist with natural human speech and varied prosodic cues.
- The comparison may conflate modality with encoder choice: text uses GPT-Neo embeddings of BLIP captions, while audio uses CLAP. The advantage could be due to encoder pretraining or representation quality rather than modality per se. A controlled comparison using matched families (e.g., CLIP text vs CLAP audio; Sentence-BERT vs Wav2Vec2) and dimension-matched embeddings is needed.
- Statistical rigor is lacking: accuracy differences are reported without confidence intervals, hypothesis tests, or multiple runs with different random seeds. The stability and statistical significance of gains remain unknown.
- Data splitting and zero-shot protocols are insufficiently specified: how 50-way and 200-way classes were selected, whether test classes are strictly unseen during training, and how leakage is avoided are unclear. Release exact splits to ensure comparability.
- Subject selection from THINGS-EEG (10 participants) is unexplained; generalization to the full cohort and other datasets is unknown. Cross-subject training/testing and leave-one-subject-out generalization are not evaluated.
- Only EEG is used; spatial mechanisms of auditory–visual integration cannot be assessed. Multi-modal neuroimaging (MEG for temporal precision; fMRI for spatial resolution) is needed to test whether the auditory modality truly improves neural alignment.
- Temporal dynamics are ignored: CLAP embeddings are static, while EEG is time-resolved. It remains unclear whether time-locked audio features (e.g., phoneme/word-level embeddings over time) better align with EEG dynamics.
- The text and audio both derive from captions; gains could reflect richer descriptive content rather than modality. A control condition using identical content with matched encoders (e.g., CLIP text vs CLAP speech of the same caption) is needed to isolate modality effects.
- No ablation studies: the contributions of MoPoE fusion, intra-/inter-modality mutual information regularizers, latent dimension, and modality combinations (vision-only, text-only, audio-only, text+audio) are not disentangled.
- Equations for MoPoE and MI objectives contain typographical errors/missing brackets, and implementation details (negative sampling strategy, batch construction, temperatures) are omitted, hindering reproducibility.
- Downstream classifier choice may bias results: a single RBF SVM with fixed gamma is used without hyperparameter tuning or comparison to linear models/logistic regression. Robustness across classifiers and proper cross-validation are needed.
- Computational efficiency claims are incomplete: no hardware specs, no parity in implementation, and feature extraction time (BLIP/GPT-Neo vs CLAP) is excluded. Report wall-clock time/FLOPs/memory across all pipeline stages under identical hardware/software.
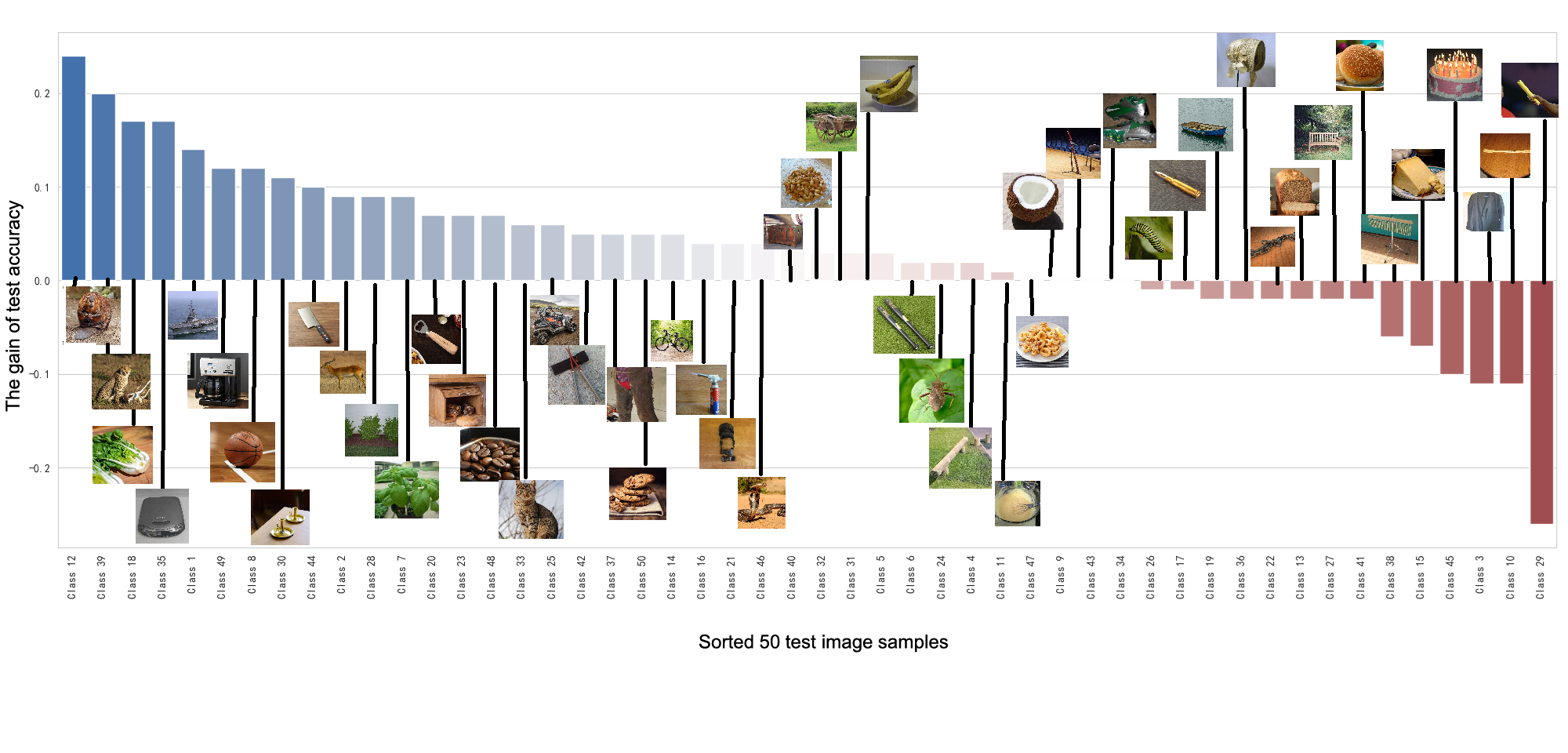
- Per-class and per-feature diagnostics are missing: which categories benefit from audio, and why (e.g., semantic richness, concreteness, acoustic correlates)? Link gains to properties of captions/audio and brain responses via representational analyses.
- Code, generated artifacts, and exact preprocessing pipelines are not released (captions, TTS audio files, feature matrices, splits), preventing independent replication and benchmarking.
- Potential confounds from embedding dimensionality (audio 512 vs text 768) and identical MLP architectures are not controlled; parameter counts and input scaling may affect learning. Use dimension-matched embeddings and normalization controls.
- Multilingual generalization is untested beyond noting English-only limitations; conduct experiments with multiple languages and cross-language transfer to assess whether auditory advantage holds cross-linguistically.
- Lack of direct brain–representation alignment analyses (e.g., RSA, CKA, encoding/decoding models) to quantify the similarity between modality embeddings and neural patterns beyond classification accuracy.
- Robustness to EEG noise, variability in audio quality/length, and preprocessing choices is not assessed; sensitivity analyses and uncertainty quantification are needed.
- Visual feature choice is fixed (CORnet-S); robustness to different vision encoders (ResNet, CLIP vision, self-supervised models) is unexplored.
- Training details (random seeds, early stopping, batch composition, modality-specific normalization, learning rate schedules) are under-specified, limiting reproducibility and fair comparison.
- EEG channel selection (17 channels) lacks rationale and analysis of impact; whether results hold with full-channel data or different channel subsets remains unknown.
- The mapping from THINGS-EEG trials to the reported “16,540 train / 200 test entries” is unclear; sample counts per class, class balance, and trial averaging strategies need clarification to rule out distributional biases.
- No behavioral validation: whether BLIP captions (and their TTS versions) reflect subjects’ perceptions or semantics is unverified; human-generated or ground-truth labels/descriptions could provide a stronger baseline.
- The work is not positioned against state-of-the-art text-based zero-shot neural decoding baselines on THINGS-EEG; without benchmarking to published numbers, the magnitude and novelty of improvements are difficult to assess.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s finding that audio-based semantic representations align better with brain activity than text in zero-shot visual neural decoding.
- Audio-anchored neural decoding baselines for research
- Sectors: academia, software/AI
- What: Swap text embeddings for CLAP-style audio embeddings in current EEG/fMRI/MEG decoding pipelines to improve zero-shot decoding accuracy and reduce training time.
- Potential tools/workflows:
- “Audio-First BraVL” starter repo (PyTorch/MindSpore) with CLAP integration and MoPoE/MI objectives.
- MNE-Python/EEGLAB plug-ins for brain–vision–audio representation alignment.
- Assumptions/dependencies: Availability of aligned brain–image–caption data; CLAP (or similar) model access; subject-specific calibration remains necessary; improvements are most evident on high-class-count tasks but absolute accuracy remains modest.
- Dataset augmentation via caption-to-speech pipelines
- Sectors: academia, software/AI
- What: For existing image–EEG datasets with captions, generate TTS audio tracks and extract CLAP embeddings to create tri-modal resources without new data collection.
- Potential tools/workflows:
- “Caption2CLAP” CLI for batch TTS + CLAP embedding extraction; .mat/.npz exporters for downstream training.
- Assumptions/dependencies: TTS quality affects alignment (natural speech likely better); English-first bias unless multi-language TTS is used.
- Faster and cheaper model training for neuro-AI experiments
- Sectors: academia, software/AI, sustainability
- What: Reduce training time and embedding dimensionality by replacing 768-d text with 512-d audio embeddings, lowering compute cost (~40% reduction reported).
- Potential tools/workflows: CI-ready training recipes; cloud templates highlighting cost/energy savings.
- Assumptions/dependencies: Comparable hardware and identical preprocessing; gains may vary across datasets.
- EEG-to-semantic retrieval demos for HCI prototyping
- Sectors: HCI, software, education (lab demos), neuromarketing (pilot studies)
- What: Real-time or near-real-time demos that map EEG to a shared latent space and retrieve top-k images or categories using audio-anchored semantics.
- Potential tools/workflows:
- “NeuroSearch” demo app (EEG stream → latent z → nearest-neighbor retrieval over CLAP-aligned catalog).
- Assumptions/dependencies: Requires small closed-world vocabularies for practical accuracy; robust EEG preprocessing; not consumer-grade performance yet.
- Cognitive and language research batteries grounded in auditory semantics
- Sectors: healthcare (research), academia
- What: Use auditory-anchored models to probe semantic processing in studies of aphasia, auditory processing disorder, or language development.
- Potential tools/workflows:
- “Auditory-Semantic Alignment Task” kits with standardized stimuli and analysis notebooks.
- Assumptions/dependencies: Institutional IRB approvals; careful interpretation (EEG spatial limits); clinical utility needs validation.
- Course modules and teaching labs on multimodal neural decoding
- Sectors: education
- What: Hands-on labs showing dual coding and grounded cognition with brain–vision–audio models (vs. text).
- Potential tools/workflows: Jupyter tutorials; MindSpore/PyTorch notebooks replicating the paper’s results.
- Assumptions/dependencies: Access to open datasets (e.g., THINGS-EEG) and pre-trained CLAP; moderate GPU.
- Ethics/IRB guidance updates for speech-based semantic embeddings
- Sectors: policy, academia, healthcare research
- What: Update consent templates and data-sharing policies acknowledging that audio-anchored embeddings may expose richer semantic intent than text.
- Potential tools/workflows: Short “IRB addendum” templates; data handling SOPs for audio-derived embeddings.
- Assumptions/dependencies: Institutional acceptance; coordination with data protection officers and legal teams.
Long-Term Applications
These opportunities are plausible but require further research, scaling, and validation (e.g., higher accuracy, generalization beyond English, natural speech corpora, higher-resolution neuroimaging, or clinical trials).
- Speech-centric communication BCIs (“thought-to-speech” assistive tech)
- Sectors: healthcare, assistive technology
- What: Use audio-anchored latent spaces to decode intended visual/semantic content and synthesize speech for patients with severe motor impairment.
- Potential tools/products: “NeuroSpeech” BCI stack (EEG/ECoG → audio semantic embeddings → neural TTS).
- Assumptions/dependencies: Higher decoding accuracy (likely via invasive signals or hybrid EEG+MEG/fMRI), personalization, rigorous clinical validation, regulatory approval (FDA/CE), multilingual support.
- Neuroadaptive AR/VR interfaces
- Sectors: AR/VR, gaming, HCI
- What: Real-time semantic decoding to adapt scenes, guidance overlays, or difficulty based on what users perceive or intend—anchored to audio semantics for more natural control loops.
- Potential tools/products: AR headsets with integrated EEG (or ear-EEG) using on-device audio-semantic decoders; SDKs for neuroadaptive content.
- Assumptions/dependencies: Wearable-grade signal quality, low-latency pipelines, robust cross-subject models, privacy-preserving on-device inference.
- Brain-guided assistive vision systems for the blind/low-vision
- Sectors: healthcare, accessibility
- What: Decode salient visual semantics from neural signals and narrate scenes using speech, reinforcing perception and navigation.
- Potential tools/products: “NeuroNarrate” companion app integrated with smart glasses; audio feedback tuned to user’s semantic focus.
- Assumptions/dependencies: Reliable decoding under naturalistic conditions; safe, interpretable outputs; user studies demonstrating benefit.
- Clinical diagnostics and monitoring of semantic networks
- Sectors: healthcare
- What: Use changes in audio–brain alignment as biomarkers for neurodegenerative disease, TBI, or developmental language disorders.
- Potential tools/products: “Auditory-Semantic Index” as a longitudinal clinical metric; integration into EEG suites.
- Assumptions/dependencies: Large longitudinal cohorts, normative baselines across age/language/culture, correlation with outcomes.
- Multilingual, cross-cultural BCIs
- Sectors: healthcare, global education, accessibility
- What: Language-agnostic auditory semantic frameworks leveraging multilingual CLAP-like models and natural speech corpora.
- Potential tools/products: “Polyglot NeuroAudio” models; cross-lingual calibration protocols.
- Assumptions/dependencies: High-quality multilingual audio–text corpora; culturally diverse neuro datasets; fairness evaluation.
- Robust brain-controlled robotics via audio-anchored commands
- Sectors: robotics, manufacturing, assistive robotics
- What: Map brain signals to a compact set of audio-labeled intents for hands-free robot control in settings where speech/motion are constrained.
- Potential tools/products: “NeuroIntent” control layer for collaborative robots (cobots) with safety gating and confidence thresholds.
- Assumptions/dependencies: Small, task-specific vocabularies; subject calibration; safety certifications; integration with existing HRI stacks.
- Neuroadaptive hearing aids and auditory scene management
- Sectors: healthcare, audio tech
- What: Decode the listener’s semantic focus and enhance target speech or relevant audio streams accordingly.
- Potential tools/products: EEG-equipped hearables with embedded auditory-semantic decoders; integration with beamforming/noise suppression.
- Assumptions/dependencies: Wearable-grade EEG/ear-EEG, real-world robustness, battery constraints, clinical validation.
- Neuromarketing and UX at semantic granularity (with safeguards)
- Sectors: marketing, product design, finance (market research)
- What: Evaluate user perception of visual content via audio-anchored semantic readouts (e.g., category salience, confusion).
- Potential tools/products: “Semantic NeuroInsights” dashboards combining EEG and audio embeddings for creatives/testing.
- Assumptions/dependencies: Strong ethics oversight; small-taxonomy tasks; clear consent and anonymization; reproducibility across subjects.
- Standardization and governance for audio-anchored neurodata
- Sectors: policy, standards bodies
- What: Develop data formats, privacy-preserving protocols, and reporting standards for brain–vision–audio research and products.
- Potential tools/products: Open “NeuroAudio Embedding Standard,” best-practice guidelines, model cards with neuro-specific risk disclosures.
- Assumptions/dependencies: Multi-stakeholder coordination (academia, industry, regulators); alignment with existing privacy laws (GDPR/CCPA/HIIPA).
- End-to-end “Neuro-Semantic Alignment Studio”
- Sectors: software/AI, academia, enterprise R&D
- What: A platform to experiment with different encoders (EEG/MEG/fMRI), audio-LLMs (CLAP, AudioCLIP, Whisper variants), and fusion strategies (MoPoE, contrastive) to optimize brain–semantic alignment for specific tasks.
- Potential tools/products: SaaS/on-prem solution with dataset loaders, training wizards, explainability, and deployment templates.
- Assumptions/dependencies: IP/licensing for pretrained models; scalable compute; standardized benchmarks beyond THINGS-EEG.
Notes on cross-cutting assumptions and dependencies
- Signal quality and modality: EEG offers high temporal but limited spatial resolution; many long-term applications may require higher-resolution signals (MEG/fMRI/ECoG) or multimodal neuroimaging.
- Generalization: Current evidence is strongest in English with TTS-generated audio; natural speech and multilingual corpora are likely to improve alignment but need validation.
- Personalization: Subject-specific calibration is still the norm; domain adaptation/few-shot personalization will be important.
- Accuracy vs. vocabulary size: Reported gains are meaningful but absolute top-1 accuracy is low for 50–200 classes; practical systems should use constrained vocabularies, confidence gating, and human-in-the-loop designs initially.
- Ethics and privacy: Audio-anchored semantics may expose richer intent; robust consent, on-device processing, differential privacy, and transparent model cards are recommended.
- Compute and deployment: Efficiency gains are promising, but real-time, wearable deployment requires additional optimization and power-aware design.
Glossary
- Audio modality: An input channel consisting of audio-derived features used alongside brain and visual data in a multimodal model. Example: "we propose replacing the text modality with an audio modality to capture richer perceptual cues more closely related to brain activity."
- Auditory modality: The sensory channel related to hearing, here used to represent language semantics more naturally than text. Example: "semantic understanding is inherently anchored in the auditory modality of speech, not text."
- Bimodal: Involving two modalities or data types (e.g., vision and text). Example: "For the bimodal (visual-textual) case, used when training on novel class data, this simplifies to:"
- BLIP: A vision–language pretraining model used to generate image captions. Example: "used the BLIP model to generate a training set CSV of 16,540 entries and a test set CSV of 200 entries."
- BLIP-Large: A larger variant of BLIP providing higher-capacity visual–language representations. Example: "the large-scale visual LLM BLIP-Large."
- BraVL: A multimodal brain–vision–language framework for neural decoding. Example: "Our framework is built upon the BraVL \cite{Du2023BraVL} model."
- CLAP: Contrastive Language–Audio Pretraining, a model aligning audio and language in a shared embedding space. Example: "We employ the Contrastive LanguageâAudio Pretraining (CLAP) model (HTSAT-Unfused variant), a large-scale audioâlanguage representation model trained to align auditory and textual semantics in a shared embedding space."
- Cognitive plausibility: The degree to which a model aligns with known human cognitive processes. Example: "text-based brain-LLMs exhibit limited cognitive plausibility, constraining their ecological validity and neural alignment."
- Contrastive audio–LLMs: Models trained to align audio and language through contrastive objectives. Example: "we construct an audio modality based on pretrained contrastive audioâLLMs."
- Contrastive learning: A learning paradigm that pulls together representations of matched pairs and pushes apart mismatched pairs. Example: "Through multimodal contrastive learning and latent semantic alignment, this framework achieves cross-modal mapping from brain signals to natural semantics"
- Contrastive objective: A loss that increases similarity of positive (matched) pairs and decreases similarity of negatives. Example: "This is approximated via a contrastive objective, which maximizes the log-likelihood of matched (\"positive\") samples while minimizing that of mismatched (\"negative\") samples:"
- CORnet-S: A biologically inspired convolutional network aligned with primate ventral visual stream processing. Example: "the CORnet-S model is used to preprocess the images and extract high-level visual representations."
- Dual Coding Theory: A theory positing that cognition uses both verbal and non-verbal (e.g., visual) systems. Example: "In cognitive neuroscience, Dual Coding Theory \cite{paivio1971imagery,clark1991dual} proposes that the neural representation of human concepts relies on the coordinated encoding of vision and language:"
- Dual-stream model of speech processing: A neurobiological model separating dorsal and ventral pathways for speech comprehension and production. Example: "The dual-stream model of speech processing \cite{Hickok2007} suggests that the ventral auditory stream is specialized for directly mapping acoustic speech signals onto semantic representations, bypassing the intermediate symbolic transformations required for reading."
- Ecological validity: The extent to which research findings generalize to real-world conditions. Example: "constraining their ecological validity and neural alignment."
- Electroencephalography (EEG): A neuroimaging method measuring electrical brain activity via scalp electrodes. Example: "electroencephalography (EEG) \cite{Horikawa2017},"
- Embedding space: A vector space where different modalities are mapped for alignment and comparison. Example: "trained to align auditory and textual semantics in a shared embedding space."
- Evidence Lower Bound (ELBO): A variational objective that lower-bounds the log-likelihood in latent-variable models. Example: "For a single modality, the objective is to maximize the Evidence Lower Bound (ELBO):"
- Functional magnetic resonance imaging (fMRI): A neuroimaging technique measuring brain activity via blood oxygenation changes. Example: "functional magnetic resonance imaging (fMRI) \cite{Naselaris2011},"
- Grounded cognition theory: The view that conceptual knowledge is rooted in perceptual and sensorimotor systems. Example: "Moreover, grounded cognition theory \cite{Barsalou2008} argues that conceptual knowledge is rooted in perceptual and sensorimotor experiences rather than abstract symbols."
- Kullback–Leibler (KL) divergence: A measure of divergence between two probability distributions, used as a regularizer in VAEs. Example: "- D_{KL}!\left[q_{\phi}(z|x)\,|\,p(z)\right]"
- Latent space: The lower-dimensional space of hidden variables learned by a generative model. Example: "learn a shared latent space that effectively integrates information from EEG, image, and audio modalities."
- Mixture-of-Products-of-Experts (MoPoE): A multimodal inference scheme combining products of experts across subsets of modalities. Example: "we adopt the Mixture-of-Products-of-Experts (MoPoE) formulation proposed in BraVL \cite{Du2023BraVL} to define the joint posterior distribution"
- Mutual information (MI) regularization: A strategy to encourage shared information between variables/modalities by maximizing MI. Example: "We follow the mutual information regularization strategy of BraVL \cite{Du2023BraVL}, introducing intra- and inter-modality objectives to encourage latent coherence and cross-modal alignment."
- Posterior collapse: A VAE failure mode where the approximate posterior ignores the input and matches the prior. Example: "To prevent posterior collapse, we maximize the MI between the latent code and each individual modality ."
- Power set: The set of all subsets of a given set; here, all combinations of available modalities. Example: "where is the power set of available modalities ."
- Radial Basis Function (RBF) kernel: A kernel function used in SVMs that measures similarity based on distance in feature space. Example: "a Support Vector Machine (SVM) with a Radial Basis Function (RBF) kernel is used."
- Reparameterization trick: A method to enable gradient-based optimization through stochastic nodes in VAEs. Example: "To enable gradient-based optimization through random sampling, the reparameterization trick is used:"
- Support Vector Machine (SVM): A supervised classifier that finds a decision boundary maximizing the margin between classes. Example: "A simple linear Support Vector Machine (SVM) classifier is then trained on these embeddings to predict the object category."
- THINGS-EEG: A large-scale dataset linking EEG responses to images of object categories. Example: "Our experiments are conducted on the THINGS-EEG \cite{gifford2022large}dataset,"
- Top-1 accuracy: The fraction of samples where the top-ranked prediction matches the correct label. Example: "Top-1 Accuracy: This is a strict metric that measures the percentage of test samples for which the single class with the highest predicted probability is the correct class."
- Top-5 accuracy: The fraction of samples where the correct label is among the top five predictions. Example: "Top-5 Accuracy: This metric measures the percentage of test samples for which the true class is among the five classes with the highest predicted probabilities."
- Trimodal: Involving three modalities or data types simultaneously. Example: "thus forming a fully aligned trimodal dataset."
- Variational Autoencoder (VAE): A probabilistic generative model with an encoder–decoder structure trained via variational inference. Example: "we build our model upon the standard Variational Autoencoder (VAE) formulation."
- Ventral auditory stream: A neural pathway mapping speech sounds to semantic representations. Example: "the ventral auditory stream is specialized for directly mapping acoustic speech signals onto semantic representations"
- Ventral visual stream: A cortical pathway associated with object recognition and high-level visual processing. Example: "inspired by the primate ventral visual stream hierarchy"
- Zero-shot classification: Classification of categories not seen during training by leveraging auxiliary semantic information. Example: "we perform a zero-shot classification task."
- Zero-shot neural decoding (ZSND): Inferring semantics from brain activity for unseen categories without category-specific training data. Example: "zero-shot neural decoding (ZSND) has emerged as a research focus in recent years"
Collections
Sign up for free to add this paper to one or more collections.

