Simple Models, Rich Representations: Visual Decoding from Primate Intracortical Neural Signals
Abstract: Understanding how neural activity gives rise to perception is a central challenge in neuroscience. We address the problem of decoding visual information from high-density intracortical recordings in primates, using the THINGS Ventral Stream Spiking Dataset. We systematically evaluate the effects of model architecture, training objectives, and data scaling on decoding performance. Results show that decoding accuracy is mainly driven by modeling temporal dynamics in neural signals, rather than architectural complexity. A simple model combining temporal attention with a shallow MLP achieves up to 70% top-1 image retrieval accuracy, outperforming linear baselines as well as recurrent and convolutional approaches. Scaling analyses reveal predictable diminishing returns with increasing input dimensionality and dataset size. Building on these findings, we design a modular generative decoding pipeline that combines low-resolution latent reconstruction with semantically conditioned diffusion, generating plausible images from 200 ms of brain activity. This framework provides principles for brain-computer interfaces and semantic neural decoding.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores how to “read” what an animal just saw by looking at its brain signals. The researchers recorded tiny electrical spikes from many electrodes inside two monkeys’ visual brain areas while the monkeys looked at thousands of pictures. They then tested different computer models to see which ones could best figure out the picture’s meaning from just 200 milliseconds (one fifth of a second) of brain activity—and even turn that into a realistic-looking image.
What questions did the researchers ask?
To make their work clear and testable, the team focused on four simple questions:
- Does paying attention to the timing of brain spikes matter more than using a very fancy model?
- Which training goal works better: making the predicted numbers match exactly, or just pointing in the same “semantic” direction?
- How much does performance improve if you give the model more data or more brain channels—and when do gains start to slow down?
- Can we build a practical way to generate pictures from brain activity that both look good and stay faithful to what was seen?
How did they study it?
They used a large public dataset where two monkeys looked at 22,000+ natural images (like tools, animals, foods) while electrodes recorded activity from early and higher visual brain areas (V1, V4, IT). Each image showed for 200 ms, and the researchers used that same 200 ms of brain data to decode what the picture was.
Here’s the main idea in everyday terms:
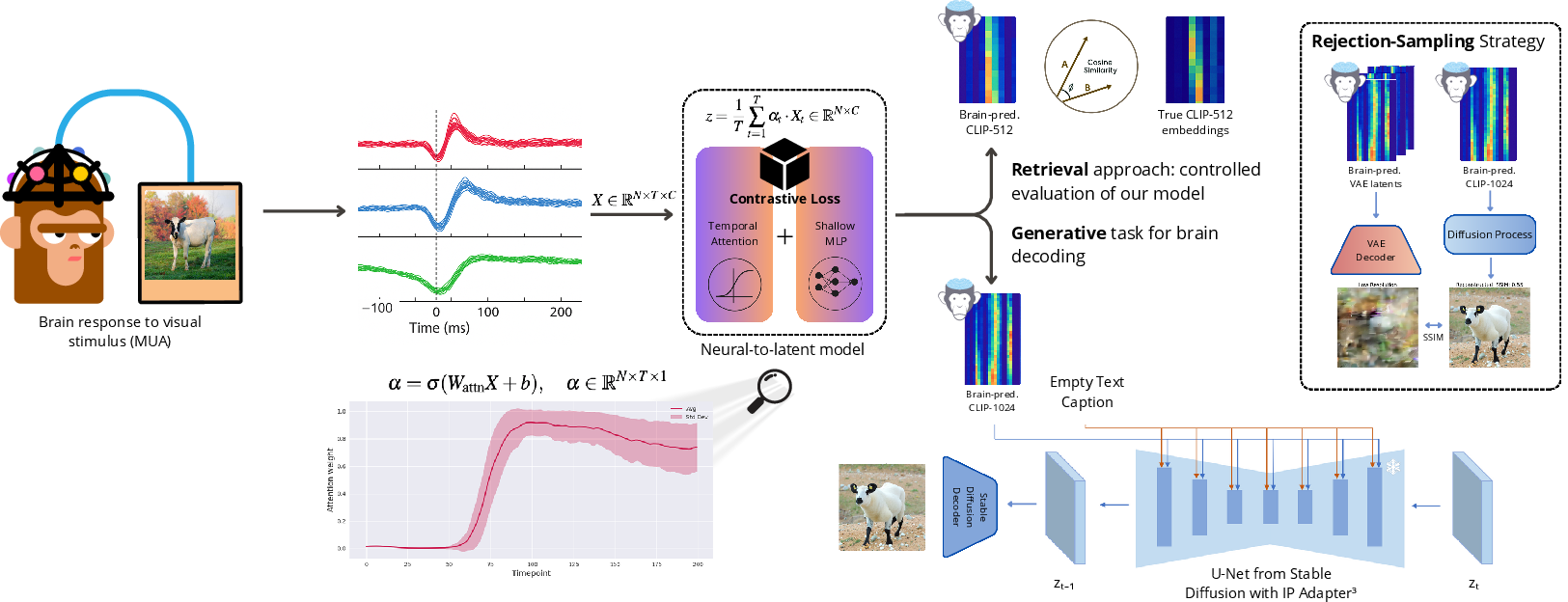
- Turning images into meaning: They used a tool called CLIP (think of it like a “map” that turns any picture into a 512-number “address” that captures what the picture is about—its semantics).
- Turning brain spikes into meaning: Their models learned to turn the monkey’s brain activity into that same kind of 512-number “address.” If the predicted address matches the original image’s address, the model understood the image’s meaning.
- Checking if the model is right: They did “image retrieval.” Imagine a big deck of the test images. For each trial, the model guesses a 512-number address from the brain data, then the system looks for the closest matching image address in the deck. If the top match is the exact image shown, that’s “Top-1” correct. If the correct image is among the best five matches, that’s “Top-5” correct.
- Simple vs. complex models: They compared many model types: simple linear models, small neural networks (MLPs), models that average over time, recurrent/convolutional models that try to capture time patterns, and—most importantly—a simple “temporal attention” model.
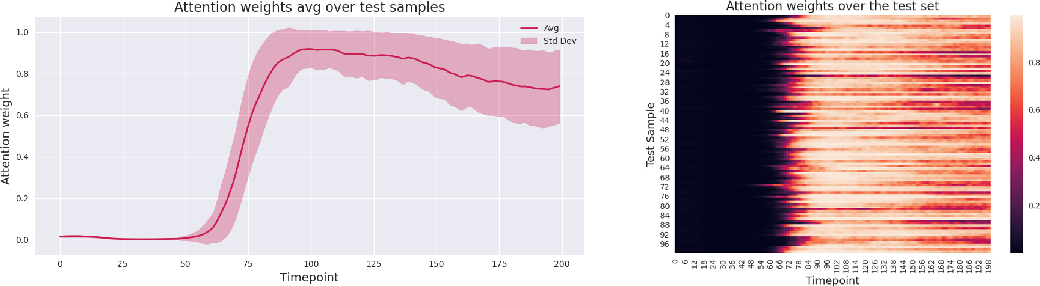
- Temporal attention is like watching a short video (200 ms) and highlighting the most important frames instead of treating every frame equally. This helps the model focus on the moments in time that matter most.
- Training goals: They compared two objectives:
- Mean Squared Error (MSE): match the exact numbers.
- Contrastive learning (cosine/NT-Xent): align directions in semantic space (like saying, “point the arrow the same way,” which matters more for meaning).
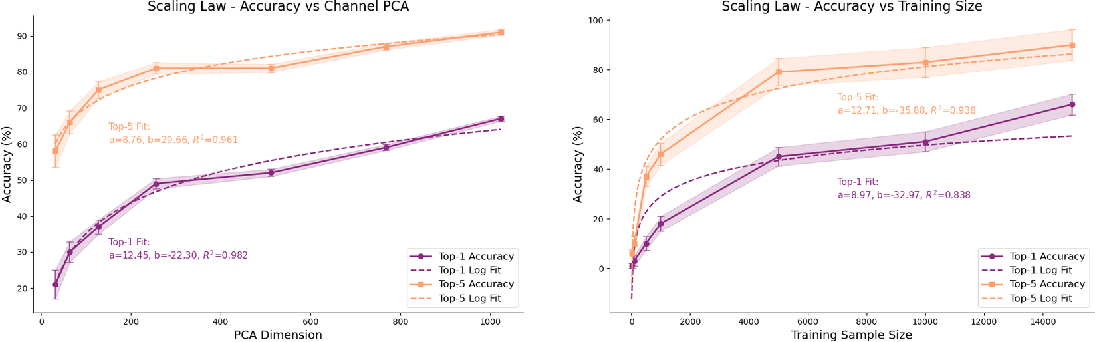
- Scaling tests: They checked what happens when they:
- Reduce the number of brain channels using PCA (like compressing notes into key summaries).
- Change how many training examples the model sees.
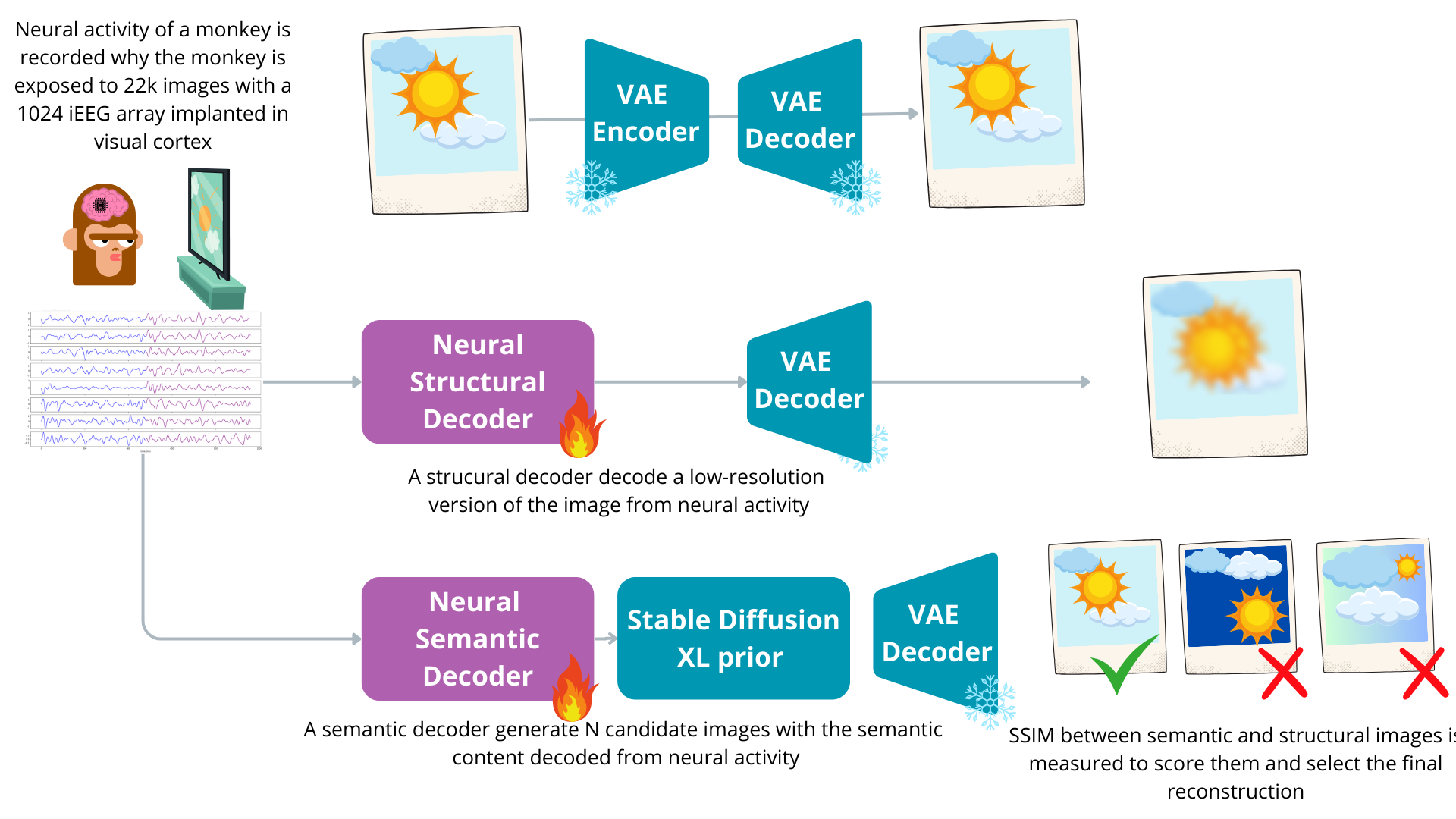
- Generating images: After proving their decoder understands semantics, they added a two-part image generator:
- Structure branch: Predict a low-resolution “preview” of the image (basic shapes and colors) directly from brain signals.
- Semantics branch: Use the predicted semantic “address” to guide a powerful image generator (Stable Diffusion). It creates several candidate images that fit the decoded meaning.
- Then pick the best candidate by comparing each to the low-res preview and choosing the one that matches its structure the best (using a measure called SSIM). This is like writing several drafts and keeping the one that matches your outline.
What did they find?
The main results are easy to summarize:
- Timing matters most: The big performance boost came from modeling time well, not from building bigger, more complicated networks. A simple model that uses temporal attention plus a small neural network beat fancier recurrent and convolutional models.
- Strong accuracy with a simple model: Their best simple model reached about 69–70% Top-1 accuracy and about 94% Top-5 accuracy at identifying the exact image from brain activity in the test set.
- Better training goal: Contrastive learning (matching directions in meaning-space) consistently outperformed MSE (matching numbers exactly). That fits the idea that meaning depends more on direction than on exact scale in these embeddings.
- Scaling laws with diminishing returns:
- More channels (summarized by PCA) help, especially early on, but each extra chunk adds a bit less benefit after a point (around a few hundred components).
- More training examples help a lot at first (hundreds to thousands), then gains slow as you keep adding more data.
- Generating pictures that make sense: The two-branch generator (low-res structure + semantic candidates) produced images that were both plausible and aligned with what was likely seen, using just 200 ms of brain activity.
Why is this important?
- It shows that brain decoding can be both accurate and simple if you focus on the right thing—the timing of spikes.
- It offers practical tips for building better brain-computer interfaces (BCIs): collect more varied examples, capture timing, and use modular designs.
What does this work mean for the future?
This study suggests a clear, practical roadmap for turning brain signals into understandable content:
- Focus on “when” signals carry the most information. Smart timing beats heavy complexity.
- Train models to align meanings, not just match numbers.
- Expect predictable but slowing improvements as you add more data and more channels; this helps plan experiments and hardware.
- Use modular generation pipelines: first decode “what it is” (semantics), then let a generator fill in “how it looks” (appearance), and finally pick the best match. This keeps the system reliable and easier to audit.
In the long run, these ideas could help build better BCIs for communication and assistive technologies. At the same time, they raise important questions about privacy and ethics—reading or reconstructing mental content must be handled with strong protections and consent.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, as actionable directions for future work:
- Quantify the contribution of precise spike timing versus rate codes by systematically varying temporal resolution (e.g., 1 ms vs 5–10 ms bins), adding jitter, and testing cross-temporal interaction models.
- Characterize how informative timepoints relate to known physiological latencies and areas (e.g., V1 ~50–70 ms, IT ~120–170 ms) by aligning attention peaks to onset-responses per region.
- Disentangle area-specific contributions (V1, V4, IT) via systematic ablation, per-area decoders, and learned spatial-temporal attention across arrays to determine which regions drive semantic decoding.
- Evaluate cross-subject generalization: train on one monkey and test on the other; explore alignment methods (Procrustes, shared latent spaces, domain adaptation) to bridge individual differences.
- Test session-to-session robustness and drift: assess whether mappings remain stable across days/sessions and develop calibration or continual-learning strategies to preserve performance.
- Assess single-trial decoding on held-out images without averaging repeats to quantify performance under realistic neural noise conditions.
- Expand retrieval evaluation to larger and harder candidate pools (e.g., thousands to tens of thousands of images) and to images unseen during training to measure open-set generalization.
- Decompose what image attributes are decodable (category, shape, color, texture, pose, background) via controlled stimuli and per-attribute metrics; identify failure modes by content type.
- Compare embedding spaces beyond frozen CLIP (e.g., OpenCLIP variants, self-supervised ViTs, biologically informed embeddings) and test fine-tuning or distillation to align human-trained semantics with primate representations.
- Explore richer objectives beyond MSE and NT-Xent (e.g., triplet loss, InfoNCE with augmented positives/negatives, multi-task classification + regression) and quantify sensitivity to batch size/negative set sizes and temperature.
- Conduct fair, capacity-matched architecture comparisons including transformers (temporal self-attention), point-process models for spike trains, and spatiotemporal graph or cross-channel attention to test whether simple attention is truly optimal.
- Probe cross-channel correlations and population-code structure (e.g., canonical correlation analysis, factor analysis, neural manifolds) to understand whether information lies in coordinated activity rather than per-channel features.
- Investigate the impact of PCA-based dimensionality reduction versus learned projections (e.g., linear probes, hypernetworks, low-rank adapters) and quantify information loss across dimensions.
- Perform scaling analyses on additional axes: temporal window length, pre- vs post-stimulus epochs, channel count ablations, and stimulus diversity to derive more complete scaling laws and exponents.
- Examine robustness to domain shifts (contrast, color inversions, occlusions, clutter) and to common recording perturbations (channel dropout, noise spikes, baseline drifts).
- Clarify MUA preprocessing choices (binning, filtering) and evaluate alternative spike representations (e.g., sorted single units, waveform features, multi-taper rates) for decoding gains.
- Provide quantitative generative metrics beyond SSIM (e.g., FID, LPIPS, CLIPScore-to-ground-truth, category accuracy) and human psychophysics to assess whether reconstructions preserve semantics and reduce priors-driven artifacts.
- Compare structural ranking criteria in rejection sampling (SSIM vs LPIPS vs DINO/ViT features vs learned neural likelihood) and report acceptance rates, compute budgets, and sensitivity to the number of candidates.
- Report and analyze the accuracy of the direct VAE-latent prediction branch (e.g., PSNR/SSIM vs ground-truth low-res images), and compare it against semantic-only generation for complementary strengths.
- Test whether the modular generative pipeline can reconstruct out-of-distribution stimuli (novel categories, scenes, text) and quantify failure/uncertainty handling.
- Measure real-time feasibility: end-to-end latency, throughput, and resource requirements for both retrieval and generation to substantiate BCI claims.
- Investigate whether jointly training encoding and decoding (bi-directional models) improves interpretability and performance, and whether decoded embeddings preserve known invariances (viewpoint, scale).
- Analyze attention and channel weights for anatomical interpretability (retinotopic mapping, receptive field positions, area-specific selectivity), connecting decoder features to cortical organization.
- Examine ethical and privacy aspects empirically (e.g., quantifying identifiability of private stimuli or mental content) and develop technical mitigations (privacy-preserving decoding, uncertainty reporting).
- Release complete training/evaluation protocols (including generative-stage hyperparameters) and perform independent replication on TVSD and other invasive datasets to assess generality.
Practical Applications
Immediate Applications
Below is a concise set of actionable, real-world uses that can be deployed now, grounded in the paper’s findings and modular pipeline.
- Lab-grade semantic visual decoding in primates
- Sectors: Academia (neuroscience, cognitive science), Software/AI
- Tools/Workflow: TVSD dataset; temporal-attention + shallow MLP; frozen CLIP embeddings; contrastive (NT-Xent) training; retrieval-based evaluation (top‑1/top‑5)
- Impact: Enables reliable stimulus identification from 200 ms intracortical activity; establishes a reproducible baseline surpassing linear and recurrent baselines
- Assumptions/Dependencies: High-density invasive recordings (Utah arrays); access to curated image–neural datasets; sufficient compute (GPUs); CLIP alignment to primate vision
- Auditable decoding evaluation via zero-shot retrieval
- Sectors: Academia, ML research, Generative AI industry
- Tools/Workflow: Fixed candidate set; cosine-similarity nearest-neighbor metrics; CLIP-based embeddings; seed-controlled validation
- Impact: Reduces confounds from strong generative priors; standardizes comparability across labs and methods
- Assumptions/Dependencies: Availability of a representative candidate image set; acceptance of retrieval metrics as primary endpoints
- Experimental design optimization using scaling laws
- Sectors: Academia, Funding agencies (policy), BCI hardware companies
- Tools/Workflow: PCA-based dimensionality control; subsampling training trials; log-linear/logarithmic fits; power analyses for trial/channel planning
- Impact: Guides efficient allocation of recording time and hardware density (e.g., prioritizing more trials, planning >256 PCs but expecting diminishing returns)
- Assumptions/Dependencies: Similar scaling behavior holds across subjects and modalities; access to pilot data to fit site-specific curves
- Modular generative decoding demo for methods validation
- Sectors: Academia (methods), Generative AI industry
- Tools/Workflow: Two-branch pipeline—low-res structural latent (VAE) + semantic branch (SDXL via IP-Adapter); rejection sampling ranked by SSIM
- Impact: Produces plausible reconstructions while preserving auditability; supports publications and method comparisons without overclaiming exact pixel fidelity
- Assumptions/Dependencies: Pretrained diffusion priors; careful reporting to avoid conflating generative realism with decoding accuracy
- Temporal attention analysis to interrogate neural dynamics
- Sectors: Academia (systems neuroscience)
- Tools/Workflow: Attention weight heatmaps over 200 ms; interpretable temporal weighting; comparison across areas (V1/V4/IT) and stimuli
- Impact: Identifies informative time intervals; informs stimulus timing protocols and preprocessing strategies
- Assumptions/Dependencies: Stable attention weight patterns across sessions; appropriate normalization/z-scoring
- Baseline benchmarking suite for decoding architectures
- Sectors: Academia, AI tooling vendors
- Tools/Workflow: Side-by-side implementations (linear time-averaged vs time-attention; MLP; LSTM; TCN); unified training and evaluation harness; open-source repo
- Impact: Accelerates model selection; improves reproducibility and fair comparison across studies
- Assumptions/Dependencies: Community uptake; adherence to shared training splits and seeds
- Contrastive training recipe for neural-to-embedding tasks
- Sectors: Academia, ML research, Software
- Tools/Workflow: Cosine-similarity NT-Xent with learnable temperature; frozen embedding targets; small MLP heads
- Impact: Immediate performance gains over MSE across architectures; portable to other modalities (ECoG, EEG, MEG, fMRI) that aim at semantic spaces
- Assumptions/Dependencies: The “direction-is-concept” property of embeddings holds for target space; label leakage avoided
- Ethics and neural privacy education using an auditable pipeline
- Sectors: Policy, Education, Healthcare compliance
- Tools/Workflow: Case-based modules demonstrating retrieval vs generation, audit trails, and consent-sensitive reporting
- Impact: Improves stakeholder literacy in risks/benefits; lays groundwork for responsible protocol design
- Assumptions/Dependencies: Institutional willingness to integrate neuroethics content; engagement with IRBs and legal counsel
Long-Term Applications
These opportunities require further research, cross-species generalization, non-invasive adaptation, scaling, or new regulatory frameworks before routine deployment.
- Calibration and closed-loop control of visual prostheses
- Sectors: Healthcare (neuroprosthetics), BCI industry
- Tools/Workflow: Semantic decoder monitors cortical responses to prosthetic stimulation; adjusts patterns to match intended CLIP-space targets; temporal-attention to filter noise
- Impact: Objective tuning of prosthesis toward recognizable semantic content; faster fitting and better outcomes
- Assumptions/Dependencies: Human intracortical/ECoG access; robust generalization from primate to human; clinical trials and regulatory approval
- Communication BCIs for locked-in patients (semantic-to-image)
- Sectors: Healthcare, Assistive technology, Generative AI
- Tools/Workflow: Neural-to-semantic embeddings for internally generated imagery or conceptual intent; SDXL/IP-Adapter synthesis; rejection sampling for consistency
- Impact: Enables concept-level communication without text; supports richer expression beyond yes/no paradigms
- Assumptions/Dependencies: Decoding of imagery/intention (not just perception); high SNR signals; careful ethical safeguards
- Neuroadaptive AR/VR that responds to decoded scene semantics
- Sectors: XR industry, Gaming, Education
- Tools/Workflow: Real-time semantic decoding to adapt overlays, difficulty, or content; temporal-attention models optimized for non-invasive sensors (EEG/MEG)
- Impact: Personalized, responsive experiences; potential cognitive training benefits
- Assumptions/Dependencies: Sufficient accuracy with non-invasive signals; latency budgets; privacy-safe on-device processing
- Visual diary or “experience capture” systems
- Sectors: Consumer tech, Digital health, Neurolaw/policy
- Tools/Workflow: Continuous semantic decoding with generative reconstruction; encrypted storage; consent-based retrieval
- Impact: Cognitive support (e.g., memory aids), situational recall
- Assumptions/Dependencies: Significant privacy frameworks; risk of misuse; robust generalization beyond passive viewing
- Cross-species and cross-modality semantic decoders
- Sectors: Academia, BCI industry, Software
- Tools/Workflow: Domain adaptation and transfer learning from macaque MUA to human ECoG/EEG/MEG/fMRI; shared embedding spaces with multi-modal alignment
- Impact: Broadens the utility of semantic decoding across labs and clinical contexts
- Assumptions/Dependencies: Alignment between species and modalities; standardized datasets; federated training for privacy
- Clinical diagnostics for visual pathway dysfunction
- Sectors: Healthcare
- Tools/Workflow: Retrieval accuracy and attention-weight signatures as biomarkers (e.g., V1/V4/IT integrity, attentional deficits)
- Impact: Objective assays for visual processing disorders; complements neuroimaging
- Assumptions/Dependencies: Normative baselines; validated correlations with clinical outcomes
- General-purpose “Neural-to-Embedding SDK”
- Sectors: Software/AI platforms
- Tools/Workflow: Modular library implementing temporal attention, contrastive objectives, retrieval evaluation, generative conditioning adapters; plug-ins for popular frameworks
- Impact: Lowers barrier to building auditable decoders; fosters ecosystem of tools and benchmarks
- Assumptions/Dependencies: Sustained open-source maintenance; community standards for datasets and metrics
- BCI hardware roadmapping informed by scaling laws
- Sectors: BCI hardware, Policy/funding
- Tools/Workflow: Use log-linear scaling curves to prioritize trial count and channel density; cost–benefit analyses for array design and data collection regimes
- Impact: More efficient hardware R&D and study design; better ROI for large-scale recordings
- Assumptions/Dependencies: Scaling behavior persists under new tasks and populations; accurate modeling of diminishing returns
- Operating-room or ICU monitoring of cognitive state
- Sectors: Healthcare
- Tools/Workflow: Semantic decoding under anesthesia/sedation to monitor residual perception; alarms for unintended awareness
- Impact: Potential patient safety gains
- Assumptions/Dependencies: Feasible signals in clinical environments; IRB approval; strong ethical guardrails
- Policy frameworks for neural data protection and generative outputs
- Sectors: Policy/regulation, Legal
- Tools/Workflow: Standards for consent, encryption, access control; watermarking/metadata for generative reconstructions; audit logs for retrieval-based evaluations
- Impact: Mitigates risks of surveillance or coercion; supports responsible innovation
- Assumptions/Dependencies: Multistakeholder consensus; enforceable norms across jurisdictions
- Content personalization and measurement of engagement via decoded semantics
- Sectors: Media/advertising, EdTech
- Tools/Workflow: Semantic decoding proxies to adapt content or assess comprehension; deploy only under stringent privacy standards
- Impact: Tailored learning or media experiences
- Assumptions/Dependencies: Non-invasive accuracy sufficient; robust privacy-preserving computation; ethical acceptability
Notes on Feasibility and Dependencies (common across applications)
- Signal quality: Many applications depend on invasive, high-density recordings; translation to non-invasive modalities will reduce accuracy and requires method adaptation.
- Embedding alignment: CLIP and similar spaces are human-optimized; further work is needed to confirm alignment with primate/human neural representations for diverse tasks.
- Generative priors: Diffusion outputs can appear accurate even with weak neural conditioning; maintaining auditability (retrieval metrics, SSIM checks) is crucial.
- Scale and compute: Benefits increase with more trials and channels, but returns diminish; budgeting and access to compute resources matter.
- Ethics and privacy: Neural data are sensitive; IRB approvals, consent protocols, encryption, and strict access controls are mandatory before any clinical or consumer deployment.
Glossary
- Adaptive average pooling: A pooling operation that resizes feature maps to a target size by averaging values, independent of input length. "followed by adaptive average pooling to reduce the temporal dimension."
- Adversarial training: A technique that trains a model alongside a discriminator to encourage realistic outputs. "incorporating adversarial training and VGG feature losses"
- Brain–computer interfaces (BCIs): Systems that translate brain activity into commands for external devices. "as well as emerging brainâcomputer interfaces."
- Classifier-free guidance: A diffusion sampling technique that steers generation without an explicit classifier by mixing conditional and unconditional scores. "using classifier-free guidance."
- CLIP (Contrastive Language–Image Pretraining): A model that maps images and text into a shared embedding space via contrastive learning. "maps neural activity into the CLIP embedding space."
- Contrastive learning: A learning paradigm that brings related pairs closer and pushes unrelated pairs apart in representation space. "contrastive learning"
- Contrastive loss: A loss function optimizing similarity of matched pairs versus mismatched pairs. "The training objective is a contrastive loss based on cosine similarity between predicted and ground-truth embeddings."
- Cosine distance: A distance measure derived from one minus cosine similarity, used to compare vectors by direction. "The cosine distance was used to compute nearest neighbors"
- Cosine similarity: A similarity measure based on the cosine of the angle between vectors, capturing directional alignment. "based on cosine similarity between predicted and ground-truth embeddings."
- Diffusion model: A generative model that synthesizes data by reversing a noise-adding diffusion process. "We use the Stable Diffusion model as the generative backbone"
- ECoG (Electrocorticography): Invasive recording of electrical activity from the cortical surface. "EEG, MEG, fMRI, ECoG, and Utah array recordings"
- GELU activation: A smooth, probabilistic activation function known as Gaussian Error Linear Unit. "GELU activation"
- Generative prior: A pretrained generative model used as a prior to constrain or guide reconstructions. "a frozen generative prior (Stable Diffusion \citep{podell2023sdxl})"
- Inferotemporal cortex (IT): A high-level visual area involved in object recognition. "V1, V4 and IT"
- IP-Adapter: An adapter module enabling diffusion models to be conditioned on image-derived embeddings rather than text. "we incorporate the IP-Adapter module~\citep{ye2023ip} into the diffusion pipeline."
- Intracortical: Referring to signals recorded from within the cerebral cortex. "decoding visual information from high-density intracortical recordings in primates"
- Inverse retinotopic mapping: A learned transformation from cortical signals back to visual field coordinates. "a learned inverse retinotopic mapping module"
- Latent representation: A compressed, learned feature vector or tensor capturing essential information about data. "low-resolution latent representation"
- Log-fit model: A regression using a logarithmic transformation to capture diminishing returns. "as confirmed by a log-fit model"
- LSTM (Long Short-Term Memory): A recurrent neural network architecture designed to capture long-range temporal dependencies. "an LSTM processes the neural sequence over time."
- Multi-unit activity (MUA): Aggregate spiking activity recorded from multiple nearby neurons on a single electrode. "multi-unit activity (MUA)"
- Multilayer perceptron (MLP): A feedforward neural network composed of stacked fully connected layers. "a shallow MLP"
- NT-Xent loss: A temperature-scaled contrastive loss (Normalized Temperature-scaled Cross Entropy) used in representation learning. "a variant of the NT-Xent loss"
- Principal Component Analysis (PCA): A dimensionality reduction technique that projects data into orthogonal components capturing maximal variance. "We applied Principal Component Analysis (PCA) to the MUA signals"
- Recurrent neural networks (RNNs): Sequence models that process inputs over time via recurrent connections. "recurrent neural networks capable of capturing complex nonlinear dynamics."
- Rejection sampling: A sampling method that accepts or rejects candidates based on a criterion to match a target distribution. "rejection sampling guided by a learned neural likelihood"
- Retrieval-based evaluation: An assessment method where predicted embeddings retrieve the correct item from a fixed candidate set. "retrieval-based evaluation offers a more transparent and interpretable benchmark"
- Scaling laws: Empirical relationships describing how performance scales with data or model size, often with diminishing returns. "classic scaling law behavior"
- Sigmoid: A squashing activation function mapping real numbers to (0,1). " is the activation of the sigmoid."
- Single-spike temporal precision: Millisecond-level fidelity capturing timing of individual action potentials. "single-spike temporal precision"
- SSIM (Structural Similarity Index Measure): An image quality metric assessing structural similarity between images. "computing structural similarity (SSIM)"
- Stable Diffusion XL (SDXL): A high-capacity diffusion model for high-resolution image synthesis. "Stable Diffusion XL"
- Temporal attention: A mechanism that assigns weights to timepoints to emphasize informative moments in a sequence. "A simple model combining temporal attention with a shallow MLP"
- Temporal Convolutional Network (TCN): A convolutional architecture for sequence modeling using causal, dilated convolutions. "Temporal Convolutional Network: a model composed of stacked 1D convolutional layers"
- Top-1 Accuracy: The fraction of cases where the highest-ranked prediction matches the ground truth. "Top-1 Accuracy"
- Utah arrays: High-density microelectrode arrays implanted intracortically for recording neural spikes. "15 Utah arrays"
- VAE (Variational Autoencoder): A generative model that learns latent variable representations via variational inference. "a VAE decoder"
- Ventral Stream: The visual processing pathway associated with object recognition and semantics. "THINGS Ventral-Stream Spiking Dataset (TVSD)"
- VGG feature losses: Perceptual losses computed using feature activations from VGG networks to encourage visual fidelity. "VGG feature losses"
- Zero-shot image retrieval: Retrieving images without task-specific training on the target categories, using general-purpose embeddings. "we used zero-shot image retrieval as a proxy"
- Z-scoring: Standardizing data by subtracting the mean and dividing by the standard deviation. "z-scoring each channel"
Collections
Sign up for free to add this paper to one or more collections.

