Assembling the Mind's Mosaic: Towards EEG Semantic Intent Decoding
Abstract: Enabling natural communication through brain-computer interfaces (BCIs) remains one of the most profound challenges in neuroscience and neurotechnology. While existing frameworks offer partial solutions, they are constrained by oversimplified semantic representations and a lack of interpretability. To overcome these limitations, we introduce Semantic Intent Decoding (SID), a novel framework that translates neural activity into natural language by modeling meaning as a flexible set of compositional semantic units. SID is built on three core principles: semantic compositionality, continuity and expandability of semantic space, and fidelity in reconstruction. We present BrainMosaic, a deep learning architecture implementing SID. BrainMosaic decodes multiple semantic units from EEG/SEEG signals using set matching and then reconstructs coherent sentences through semantic-guided reconstruction. This approach moves beyond traditional pipelines that rely on fixed-class classification or unconstrained generation, enabling a more interpretable and expressive communication paradigm. Extensive experiments on multilingual EEG and clinical SEEG datasets demonstrate that SID and BrainMosaic offer substantial advantages over existing frameworks, paving the way for natural and effective BCI-mediated communication.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Assembling the Mind’s Mosaic: Towards EEG Semantic Intent Decoding”
Overview
This paper is about helping people communicate using their brain activity, especially if they cannot speak. The authors build a system that reads brain signals (EEG/SEEG) and turns them into natural sentences. Their main idea is to treat meaning like a mosaic made of small pieces, called “semantic units” (like keywords), and then use those pieces to rebuild full sentences.
EEG means recording brain activity with sensors on the scalp. SEEG records similar activity from electrodes placed inside the brain in a clinical setting.
Objectives and Research Questions
The paper asks three simple questions:
- Can we think of what someone wants to say (their “intent”) as a set of key meaning pieces instead of one big label or a full sentence all at once?
- If we decode meaning into a “continuous space” (like a map where related ideas are near each other), does it work better and scale to new words?
- If we force the final sentence to use the decoded meaning pieces, do we get more accurate and understandable results than just letting a model write freely?
Methods and Approach
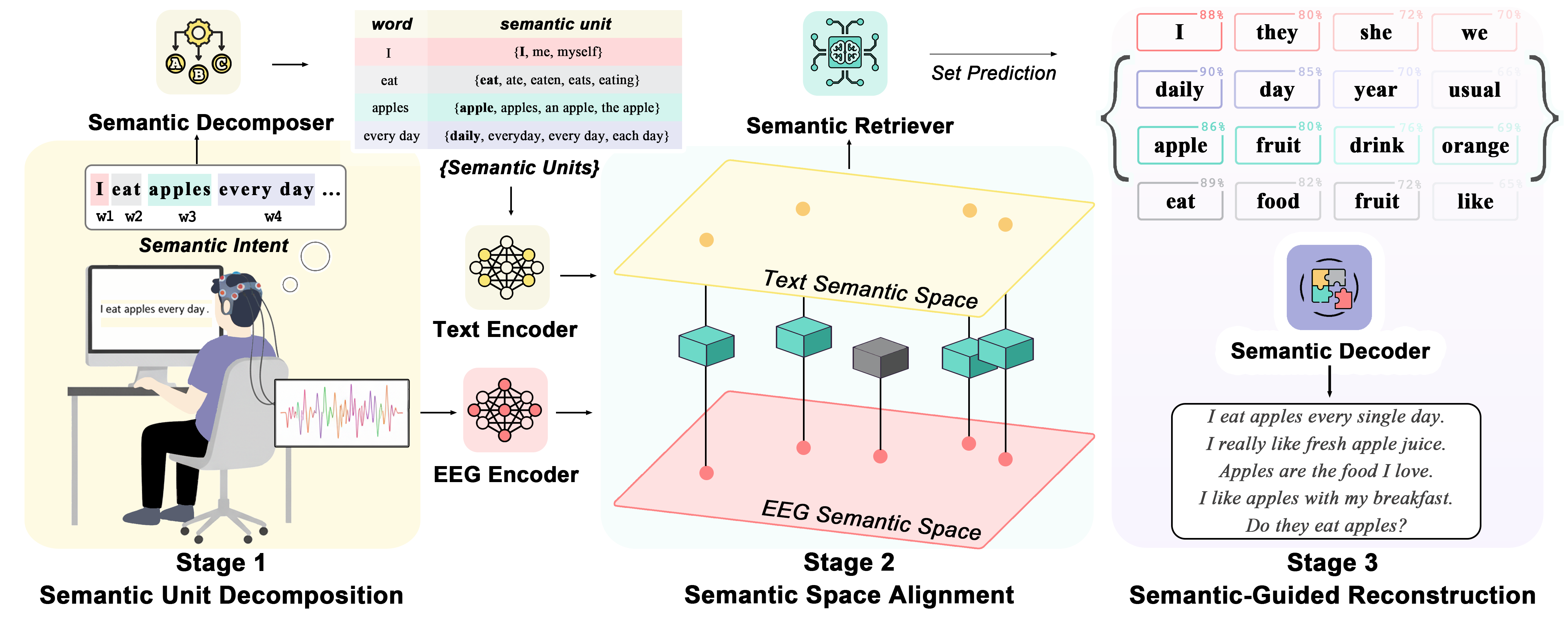
The authors propose a framework called Semantic Intent Decoding (SID) and a model named BrainMosaic. Think of it like building a sentence from Lego bricks:
- Key idea: “Semantic units” are the small meaning bricks—simple words or concepts like “I,” “eat,” “apple,” “daily.” Together they describe intent without worrying about word order at first.
The pipeline has three main steps:
- Semantic Decomposer: It looks at the EEG/SEEG signals and tries to pull out several semantic units (the bricks). Instead of predicting a single label, it predicts a variable number of units. Imagine matching slots to the correct bricks, like assigning each empty spot in a puzzle to the right piece.
- Semantic Retriever: It places those units into a continuous “semantic space,” which is like a map where similar ideas are closer together. This helps the system find the best-matching words even if the exact word wasn’t seen before. Think of a “word galaxy” where “apple” is near “fruit,” and “eat” is near “chew.”
- Semantic Decoder: Finally, it uses a LLM (an AI writer) to take the selected units plus some global hints (tone, sentence type) and form a fluent sentence. Importantly, the writer is guided and must use those meaning bricks so it doesn’t wander off-topic.
Technical terms explained simply:
- Set matching: A careful way to pair predicted slots with the right meaning units, even if we don’t know the exact number ahead of time.
- Continuous semantic space: A map where words are dots, and distance shows how similar they are. Close dots = similar meaning.
- Fidelity: Making sure the final sentence uses the decoded meaning units and is grammatical and sensible.
Main Findings and Why They Are Important
- Modeling intent as sets of semantic units works: BrainMosaic did much better than methods that either pick one label or try to directly write a sentence without using meaning pieces. This means breaking intent into small parts makes decoding clearer and more accurate.
- Continuous space helps generalization: Because similar words are near each other, BrainMosaic can handle new or rare words by choosing close neighbors. As the vocabulary grows (even to tens of thousands of words), performance stays strong rather than collapsing. This is important for real life, where people use lots of different words.
- Constrained generation improves fidelity: When the LLM is told, “Use these meaning units,” the final sentences are more faithful to what the person intended than free, unconstrained generation. This also makes the system more interpretable—you can see the intermediate units and understand why the sentence was produced.
- Each component matters: Removing any of the three parts (set-based decomposition, continuous space retrieval, or the guided LLM) hurts performance. This shows the design is balanced and each part is essential.
The authors tested on multiple datasets in different languages (Chinese and English), including a clinical SEEG dataset. Across these, BrainMosaic consistently outperformed baseline methods on both concept-level measures (catching the right meaning units) and sentence-level measures (how close the generated sentence is to the true meaning).
Implications and Potential Impact
This work moves brain–computer interfaces toward natural, flexible communication. Instead of forcing a person’s thoughts into fixed categories or relying on a black-box generator, BrainMosaic:
- Gives interpretable middle steps (semantic units), so doctors and researchers can check what it decoded.
- Works across languages and can grow to new words, making it more practical in the real world.
- Helps people with speech impairments express themselves more accurately and naturally.
In the future, this approach could lead to better assistive devices, deeper understanding of how the brain represents meaning, and more trustworthy AI systems that collaborate with neuroscience to restore communication.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to guide future research directions.
- Cross-subject generalization remains untested: performance is reported only in-subject; no evaluation of training on one participant and testing on unseen participants, or of subject-invariant representations/adaptation strategies.
- Cross-modality transfer is unexplored: there is no analysis of whether a model trained on EEG can generalize to SEEG (or vice versa), or whether joint training improves robustness.
- Real-time, closed-loop feasibility is unknown: latency, throughput, stability under streaming input, and responsiveness in an online BCI setting are not measured.
- Robustness to common EEG artifacts is not characterized: sensitivity to eye blinks, muscle activity, motion, and environmental noise (and the efficacy of artifact mitigation) are not reported.
- The clinical SEEG dataset is single-participant and non-releasable: generalizability to broader patient populations and conditions is unclear; reproducibility is constrained without access to similar data.
- Task diversity is limited: decoding is evaluated on sentence reading and an imagined-speech memory task; free-form spontaneous thought, conversational intent, and multi-turn discourse decoding are not assessed.
- Handling of complex syntax and long-form content is unverified: the set-based, permutation-invariant intent representation may break for sentences where word order and structure are essential; scalability to multi-clause and hierarchical syntax is not quantified.
- Fixed upper bound K on semantic units may constrain expressivity: there is no study of sensitivity to K, dynamic cardinality estimation, or hierarchical/variable-sized intent representations for complex utterances.
- Ground-truth semantic unit definition and annotation are under-specified: how units are segmented (e.g., words, lemmas, multiword expressions) in Chinese and English, and how polysemy and phrase-level meaning are handled, is not rigorously described.
- Polysemy and sense disambiguation are not addressed: retrieval into a continuous space may select the wrong sense in the absence of rich context; the impact of sense ambiguity on decoding fidelity is not measured.
- Open-vocabulary evaluation focuses on frequent words: performance on rare terms, named entities, domain-specific jargon, and multiword expressions (collocations/idioms) remains unknown.
- Semantic coverage and mandatory-unit adherence are not enforced: reconstruction via LLM prompts lacks hard lexical constraints; there is no metric reporting whether generated sentences include and respect all high-confidence decoded units.
- LLM-induced hallucinations and style drift are unquantified: how often the decoder introduces concepts not present in the retrieved units or deviates in tone/register from the ground truth is not measured.
- Dependence on text embedding models is only partially probed: results hinge on specific embedding spaces (e.g., doubao); systematic cross-encoder comparisons, multilingual spaces, and sensitivity analyses are limited.
- Choice and design of prompts for the LLM are not systematically evaluated: the effect of prompt format, constraints, and decoding strategies (e.g., lexically constrained generation) on fidelity and coherence is not studied.
- Embedding-based metrics may not fully capture communicative success: SRS/MUS/UMA depend on text encoders; human comprehension ratings, clinical utility assessments, and user studies are missing.
- Metric calibration and thresholds are underspecified: how similarity thresholds (e.g., UMA’s τ) are chosen, calibrated per language/corpus, and affect conclusions is not explored.
- Neurobiological interpretability is limited: beyond aggregate performance, there is no rigorous mapping between decoded units and specific cortical regions/networks or time–frequency features; RSA or causal perturbation studies are absent.
- Training data efficiency is not quantified: learning curves, minimal data requirements per subject, and benefits of pretraining/transfer are not reported.
- Domain/task shifts are not analyzed: performance under changes in stimulus modality (audio vs text), attention levels, cognitive load, or mental states (fatigue, stress) is unknown.
- Integration with speech decoding is unexplored: combined phonetic–semantic approaches (e.g., for imagined or overt speech) and their potential synergies are not evaluated.
- Confidence calibration and uncertainty estimates are missing: reliability of slot activity probabilities, impact on filtering decisions, and methods to abstain or defer when uncertain are not studied.
- Error typology and impact on communication are not provided: the paper lacks a fine-grained analysis of semantic drift types, omissions, intrusions, and their practical consequences for end users.
- Cross-lingual and bilingual decoding remains open: unified multilingual semantic spaces, handling of code-switching, and transfer across languages are not demonstrated.
- Ethical and safety considerations for deployment are not detailed: risks of misinterpretation, consent in continuous monitoring, and safeguards to prevent unintended inference or misuse are not addressed beyond general IRB compliance.
Practical Applications
Immediate Applications
Below are applications that can be deployed or piloted now with existing EEG/SEEG setups, the released codebase, and standard clinical/research workflows.
- Clinical communication aid for implanted patients (SEEG) — Sectors: healthcare, assistive technology — Tools/workflows: bedside “semantic intent” communicator for sentence-level outputs during clinical monitoring; clinician dashboard that shows decoded semantic units and confidence; audit logs for interpretability — Assumptions/dependencies: invasive SEEG availability; per-patient calibration with paired sentence data; IRB/ethics approval; on-prem compute for privacy; LLM with constrained prompting
- Research-grade EEG intent-to-text prototypes in controlled settings — Sectors: academia, assistive technology, HCI — Tools/workflows: lab prototypes for sentence reconstruction from noninvasive EEG in controlled, time-locked tasks (reading/imagined speech); stimulus-locked experiment scripts; open-vocabulary retrieval using BrainMosaic — Assumptions/dependencies: research-grade EEG, low-artifact recording, paired EEG–text datasets; per-subject training; limited vocabulary/tasks to ensure SNR
- Neuropsychological assessment of semantic processing — Sectors: healthcare (neuropsychology), academia — Tools/workflows: task batteries that quantify unit-level comprehension using UMA/MUS/SRS; longitudinal tracking of semantic unit recovery in aphasia; patient-specific semantic maps — Assumptions/dependencies: validated task designs; subject-specific baselines; collaboration with clinicians; careful interpretation to avoid over-claiming diagnostic specificity
- Personalized rehabilitation and neurofeedback for language disorders — Sectors: healthcare, digital therapeutics — Tools/workflows: therapy sessions that visualize decoded semantic units and global attributes (tone, sentence type) to guide exercises; feedback loops that reward correct semantic unit activation — Assumptions/dependencies: therapist-in-the-loop; closed-set or constrained open-vocabulary targets; safety/efficacy evaluation; per-subject calibration
- Command-and-control pilots via compositional intent — Sectors: smart home, robotics, accessibility software — Tools/workflows: small-vocabulary, open-set command mapping (e.g., {lights, on, living room}); rule-based LLM prompts that enforce decoded unit constraints; fallback confirmations — Assumptions/dependencies: controlled environment; low-latency EEG pipeline; robust artifact rejection; task-specific, per-user training; safety interlocks
- Human–robot interaction prototypes with semantic slots — Sectors: robotics, manufacturing labs — Tools/workflows: intent-to-action translation using decoded unit sets (agent, verb, object, location) to parameterize task planners; simulation-to-lab demos — Assumptions/dependencies: limited task grammar; deterministic planners; per-user training; strong safety guardrails and confirmations
- Cross-lingual BCI research workflows — Sectors: academia, language technology — Tools/workflows: multilingual datasets leveraging shared continuous semantic space; cross-language sentence reconstruction (e.g., decode in Chinese, reconstruct in English) via LLM prompting — Assumptions/dependencies: language-specific embedding models; balanced, paired datasets; rigorous evaluation for fidelity and bias
- ML tooling for open-vocabulary set prediction and evaluation — Sectors: software/AI — Tools/workflows: reusable “set-matching in continuous space” layer (DETR-style bipartite matching) for open-vocabulary multi-label tasks; standardized metrics (UMA/MUS/SRS) packages — Assumptions/dependencies: high-quality text embeddings; careful thresholding and calibration; documentation and benchmarks
Long-Term Applications
These require further research, scaling, clinical validation, or productization (e.g., real-time performance, cross-subject generalization, consumer-grade hardware).
- Everyday noninvasive thought-to-text for speech-impaired users — Sectors: healthcare, assistive technology — Tools/products: wearable EEG “semantic keyboard” with co-adaptive training; mobile app for messaging and note-taking — Assumptions/dependencies: high-SNR consumer EEG, robust cross-session stability, minimal calibration, regulatory approval, payor reimbursement
- Silent speech interface for AR/VR and mobile — Sectors: AR/VR, productivity software — Tools/products: hands-free texting/search/composing; “intent-to-UI” control via semantic units; privacy-preserving on-device decoding — Assumptions/dependencies: ergonomic sensors integrated into headsets; real-time decoding; strong privacy guarantees; content safety
- Home-use neuroprosthetic communication for locked-in syndrome — Sectors: healthcare, medical devices — Tools/products: implant-based (or hybrid) systems enabling continuous open-vocabulary communication, with remote clinical monitoring — Assumptions/dependencies: long-term implant safety, robustness to home environments, clinical trials, reimbursement pathways, caregiver training
- Generalizable cross-subject decoders and low-shot personalization — Sectors: software/AI, healthcare — Tools/products: foundation neurosemantic models pre-trained on multi-site datasets; rapid per-user adaptation (<10 minutes) — Assumptions/dependencies: large, diverse, ethically collected datasets; harmonized preprocessing; domain adaptation methods
- Cognitive and developmental diagnostics from semantic representations — Sectors: healthcare, public health — Tools/products: biomarkers for early semantic deficits (e.g., MCI, developmental language disorder); risk stratification dashboards — Assumptions/dependencies: longitudinal cohorts; outcome-linked validation; fairness analysis; regulatory clearance
- Adaptive education and tutoring driven by semantic comprehension signals — Sectors: education technology — Tools/products: reading companions that detect misunderstanding (inferred missing units) and adapt content in real time; L2 tutoring that targets specific semantic units — Assumptions/dependencies: classroom-safe, noninvasive hardware; consent and data governance; robust models for children; effectiveness studies
- Intent-based control of assistive robots for activities of daily living — Sectors: robotics, eldercare — Tools/products: semantic-slot interfaces to plan multi-step tasks (e.g., {water, bring, kitchen}); shared autonomy with confirmations — Assumptions/dependencies: reliable decoding in dynamic settings; safe task planning; liability frameworks; user training
- Multimodal neurointerfaces (EEG + EMG + eye-tracking) for robust intent decoding — Sectors: assistive tech, HCI — Tools/products: sensor fusion stacks that boost accuracy/latency; co-adaptive decoders — Assumptions/dependencies: sensor integration; power management; calibration UX; privacy-preserving fusion
- Enterprise and industrial hands-free computing in constrained environments — Sectors: manufacturing, healthcare (surgery), defense — Tools/products: semantic command layers for sterile/cleanroom workflows; secure on-prem deployment with audit trails (decoded unit logs) — Assumptions/dependencies: environment-specific validation; safety certifications; workforce training; strong privacy controls
- Cross-lingual “decode once, express anywhere” — Sectors: language services, accessibility — Tools/products: decode semantic intent in user’s native language and generate in target language; multilingual conversational agents — Assumptions/dependencies: robust multilingual embeddings; LLM translation safety; bias mitigation; user supervision
- Standards, regulation, and privacy-preserving infrastructure for brain data — Sectors: policy, cybersecurity, healthcare — Tools/products: auditability via intermediate semantic units; standardized clinical benchmarks (UMA/MUS/SRS); on-device/edge inference; encrypted embeddings and consent management — Assumptions/dependencies: multi-stakeholder consensus; regulatory frameworks for “mental privacy”; certification processes
- Consumer-grade “neurotyping” for productivity and creativity — Sectors: productivity software, creative tools — Tools/products: intent-driven drafting assistants that assemble outlines from decoded semantic units; meeting note generation from covert intent cues — Assumptions/dependencies: high-SNR consumer sensors; user acceptance and clear consent; accuracy and latency suitable for everyday use
Notes on feasibility and dependencies across applications
- Data and personalization: Current performance is primarily in-subject; scalable cross-subject generalization and low-shot adaptation are active research needs.
- Signals and hardware: SEEG yields high SNR but is invasive; consumer-grade EEG presents noise and motion artifacts—signal processing and sensor design are pivotal.
- Real-time constraints: Latency-sensitive use cases require optimized pipelines, on-device or edge inference, and efficient LLM prompting/decoding.
- Safety and interpretability: The semantic-unit layer supports auditing and guardrails; high-stakes deployments should log units, probabilities, and constraints applied to generation.
- Ethics and governance: Strict consent, data minimization, and privacy-preserving design (encrypted embeddings, local processing) are essential; clinical applications require regulatory approval and rigorous validation.
- Language/LLM dependencies: Availability of reliable, multilingual embeddings and controllable LLMs (with constrained prompts) impacts output fidelity and safety.
Glossary
- Aphasia: A language disorder caused by brain damage that impairs speaking, understanding, reading, or writing. "Conditions such as aphasia and locked-in syndrome can sever an individual’s ability to speak or write, isolating them from even the simplest forms of interaction."
- BERTScore-F1: An embedding-based metric that measures semantic similarity between generated and reference texts using contextualized representations. "We also report the BERTScore-F1~\citep{bert-score} as a sentence-level reference metric."
- Bipartite matching: An optimization procedure that pairs predicted elements with ground-truth targets one-to-one, often used to train set prediction models. "Inspired by set-based object detection frameworks such as DETR~\citep{carion2020end}, we adopt a bipartite matching formulation to handle the variable and unordered nature of semantic units."
- Brain–Computer Interface (BCI): A system that translates brain activity into actionable outputs, enabling communication or control without muscular movement. "Enabling natural communication through brain–computer interfaces (BCIs) remains one of the most profound challenges in neuroscience and neurotechnology."
- Concept Decoding: A paradigm that aims to infer the intended meaning of an utterance directly from neural signals. "Concept Decoding seeks to directly extract the intended meaning of an utterance from neural activity~\citep{zhang2024chisco}."
- Continuous semantic space: A vector space where meanings are represented as embeddings with graded similarity, allowing smooth generalization and open-set retrieval. "maps neural signals into a continuous semantic space, providing an interpretable link between concept-level representations and natural language generation."
- Contrastive objectives: Training losses that pull semantically related representations together and push unrelated ones apart in embedding space. "Trained with multi-stage contrastive objectives on massive corpora, they yield a stable manifold in which vector proximity reliably tracks semantic affinity."
- Electroencephalography (EEG): A noninvasive method that records electrical activity of the brain via scalp electrodes. "BCIs, recording neural activity via scalp or intracranial electroencephalography (EEG), offer a promising pathway to bypass these physical barriers by translating brain signals directly into language."
- End-to-end decoding: Directly mapping inputs (e.g., neural signals) to outputs (e.g., text) without explicit intermediate representations or constraints. "Enforcing these constraints yields simultaneously interpretable and intelligible interpretations, circumventing the idiosyncratic errors common in unconstrained end-to-end decoding~\citep{duan2023dewave}."
- Hungarian objective: A training objective derived from the Hungarian algorithm that enforces optimal one-to-one matching between predictions and targets. "The overall retriever loss combines the Hungarian objective of token-level matching with global-level supervision."
- LLMs: Deep neural networks trained on large corpora to perform advanced language understanding and generation. "a more recent direction seeks to enhance expressive capacity by mapping neural signals directly into the latent representation space of LLMs~\citep{shams2025neuro2semantic,lu2025eeg2text,duan2023dewave}."
- Locked-in syndrome: A condition where a person is conscious and cognitively intact but unable to move or communicate verbally due to paralysis. "Conditions such as aphasia and locked-in syndrome can sever an individual’s ability to speak or write, isolating them from even the simplest forms of interaction."
- Long Short-Term Memory (LSTM): A recurrent neural network architecture designed to capture long-range dependencies via gated memory cells. "Seq-Decode replaces the set-matching stage with an LSTM-based sequential decoder, while keeping the same ModernTCN encoder and LLM."
- Mean Unit Similarity (MUS): A metric that averages embedding similarities between predicted and reference semantic units to assess soft alignment quality. "Mean Unit Similarity (MUS) complements this with a soft measure of alignment by averaging unit-wise similarities, capturing graded improvements even when predictions fall close to the threshold."
- Out-of-vocabulary (OOV): Words or concepts not present in the training vocabulary that challenge generalization in decoding systems. "tests whether the continuous semantic space enables effective handling of out-of-vocabulary (OOV) words."
- Permutation invariance: A property where the output does not depend on the order of inputs, essential for modeling sets of semantic units. "BrainMosaic achieves both permutation invariance and bounded cardinality as required by Principle~\ref{ppl:representation}"
- Phoneme-level reconstruction: Decoding speech by inferring sequences of phonemes, the smallest units of sound in language. "limits its cross-linguistic generalizability by depending on phoneme-level reconstruction~\citep{dronkers2017language}."
- Semantic control network: A brain system that supports flexible, context-sensitive retrieval and manipulation of semantic information. "supported by the brain’s semantic control network for flexible, context-sensitive retrieval~\citep{JEFFERIES2013611}."
- Semantic Decomposer: A model component that transforms neural signals into a set of core semantic units for downstream alignment and reconstruction. "Semantic Decomposer: Decomposing Neural Signals into Semantic Units"
- Semantic Intent Decoding (SID): A framework that represents intended meaning as a set of compositional semantic units and reconstructs natural language from neural activity. "We introduce Semantic Intent Decoding (SID), a novel framework that translates neural activity into natural language by modeling meaning as a flexible set of compositional semantic units."
- Semantic Retriever: A module that aligns predicted semantic units with an open, continuous linguistic embedding space. "Semantic Retriever: Aligning Semantic Units with Continuous Space"
- Sentence Reconstruction Similarity (SRS): An embedding-based metric that measures how semantically close a generated sentence is to the reference sentence. "Sentence Reconstruction Similarity (SRS) evaluates sentence-level semantic fidelity by comparing the embedding of the generated sentence $\hat{\mathbf{s}$ with that of the reference "
- Set matching: Assigning predicted set elements to target elements to handle variable-sized, unordered outputs during decoding. "BrainMosaic decodes multiple semantic units from EEG/SEEG signals using set matching and then reconstructs coherent sentences through semantic-guided reconstruction."
- Speech Decoding: A paradigm that reconstructs overt or imagined speech from neural activity in motor-related regions. "Speech Decoding aims to reconstruct overt or imagined speech from motor-related cortical areas."
- Stereo-EEG (SEEG): An invasive recording technique that uses implanted electrodes to measure deep brain activity with high spatial resolution. "a private clinical Stereo-EEG (SEEG) dataset"
- Unit Matching Accuracy (UMA): A hard-accuracy metric counting a predicted unit as correct only if its embedding similarity surpasses a threshold. "Unit Matching Accuracy (UMA) reflects hard correctness at the concept level: a predicted unit $\hat{\mathbf{z}_i$ is counted as correct only when its similarity to the gold unit exceeds a predefined threshold ."
Collections
Sign up for free to add this paper to one or more collections.

