Post-selection inference for penalized M-estimators via score thinning
Published 20 Jan 2026 in stat.ME | (2601.13514v1)
Abstract: We consider inference for M-estimators after model selection using a sparsity-inducing penalty. While existing methods for this task require bespoke inference procedures, we propose a simpler approach, which relies on two insights: (i) adding and subtracting carefully-constructed noise to a Gaussian random variable with unknown mean and known variance leads to two \emph{independent} Gaussian random variables; and (ii) both the selection event resulting from penalized M-estimation, and the event that a standard (non-selective) confidence interval for an M-estimator covers its target, can be characterized in terms of an approximately normal ``score variable". We combine these insights to show that -- when the noise is chosen carefully -- there is asymptotic independence between the model selected using a noisy penalized M-estimator, and the event that a standard (non-selective) confidence interval on noisy data covers the selected parameter. Therefore, selecting a model via penalized M-estimation (e.g. \verb=glmnet= in \verb=R=) on noisy data, and then conducting \emph{standard} inference on the selected model (e.g. \verb=glm= in \verb=R=) using noisy data, yields valid inference: \emph{no bespoke methods are required}. Our results require independence of the observations, but only weak distributional requirements. We apply the proposed approach to conduct inference on the association between sex and smoking in a social network.
The paper introduces a novel score thinning method that splits the score statistic, ensuring asymptotic independence between selection and inference.
It provides theoretical guarantees for valid post-selection inference, using standard techniques without the need for custom adjustments.
Empirical results across linear, logistic, and network models show improved confidence interval coverage and shorter intervals compared to existing methods.
Post-Selection Inference for Penalized M-Estimators via Score Thinning
Introduction and Context
Inference after model selection remains one of the most persistent and subtle problems in modern statistics, especially when coupled with sparsity-inducing regularization. While the combination of M-estimators with L1 penalties (e.g., Lasso, penalized GLMs) has promoted both interpretability and statistical efficiency, subsequent statistical inference in such adaptively selected models often suffers from invalidity due to the “double dipping” phenomenon—using the data both for selection and for inference. Traditional approaches, including sample-splitting and fully conditional selective inference, either incur substantial loss of power or require bespoke and computationally intensive methodology for each estimator and selection procedure.
This paper proposes a generic, technically elegant, and computationally facile framework for post-selection inference for penalized M-estimators: score thinning. The approach is based on a thinning of the approximately normal score statistic underlying M-estimators, yielding data splits with provable asymptotic conditional independence between selection and inference. This enables post-selection valid inference using standard statistical pipelines—without custom procedures—while requiring only weak assumptions on data distribution and covariance estimation.
Score Thinning: Methodological Insights
The method exploits three core observations formalized as:
1. Asymptotic Normality and Thinning of the Score Statistic:
Let Z^n=nPnℓ˙θ∗ be the averaged score for the true parameter, which under usual conditions is asymptotically normal with mean nμ and covariance Σn. By adding/subtracting properly constructed Gaussian noise W^n∼N(0,Σ^n), the method produces two thinned scores: Z^n(1)=Z^n+γW^n,Z^n(2)=Z^n−γ1W^n
which are approximately (asymptotically) independent and normal with analytically tractable covariances.
2. Selection and Inference as Functions of Independent Thinned Scores:
Selecting the penalized estimator using a "noisy" loss function (i.e., adding the Gaussian noise above) is asymptotically equivalent to making selection based solely on Z^n(1), while post-selection inference (e.g., confidence intervals for selected parameters) is based on Z^n(2). Crucially, these two quantities are independent conditional on asymptotia.
3. Generic Validity via Standard Pipelines:
Given this independence, if selection and inference are performed using these thinned versions of the score, standard confidence intervals and p-values attain their nominal coverage, conditional on the data-dependent selection event. No tailored adjustments to the inference step are necessary; one may use existing inferential routines (e.g., glm after glmnet) directly on the thinned data or penalized estimates.
Theoretical Guarantees
The main technical result establishes that, under weak regularity (independence of observations, asymptotic normality, consistent covariance estimation), the procedure achieves
for contrasts ξ of post-selection estimates θ^ and any selected support E. The coverage holds for arbitrary penalty functions with subgradients forming unions of finitely many convex sets (e.g., Lasso), but also more broadly for any penalty meeting the (mild) sufficient conditions outlined.
Further, for losses affine in Y (including GLMs with canonical links), the method can be implemented by perturbing the observed response vector, obviating direct access to or modifications of optimization internals.
Algorithmic Implementation
The outlined procedures are straightforward and compatible with widely used software:
Draw Gaussian noise matching the estimated covariance.
Perturb either the loss (penalty) or the observed outcomes depending on the model structure.
Apply penalized estimation for selection; fit the model on thinned data for inference.
Plug in standard sandwich variance estimators for interval construction.
Empirical Validation
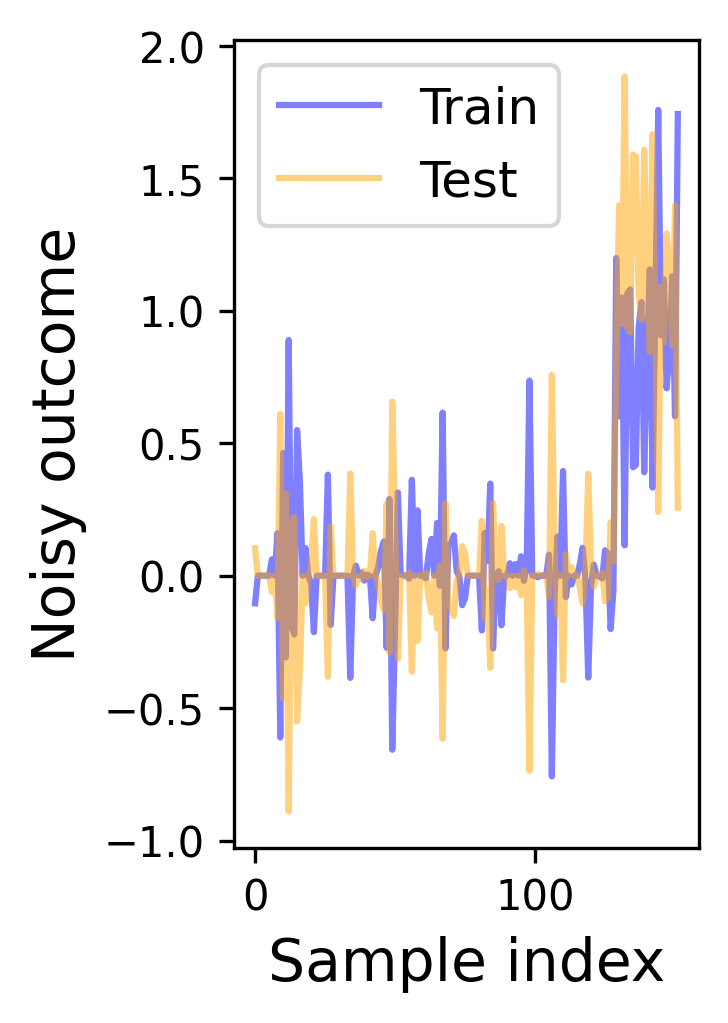
Simulations spanning linear models (with unknown variance), logistic models (non-continuous outcomes), and clustered/heteroscedastic designs validate the methodology:
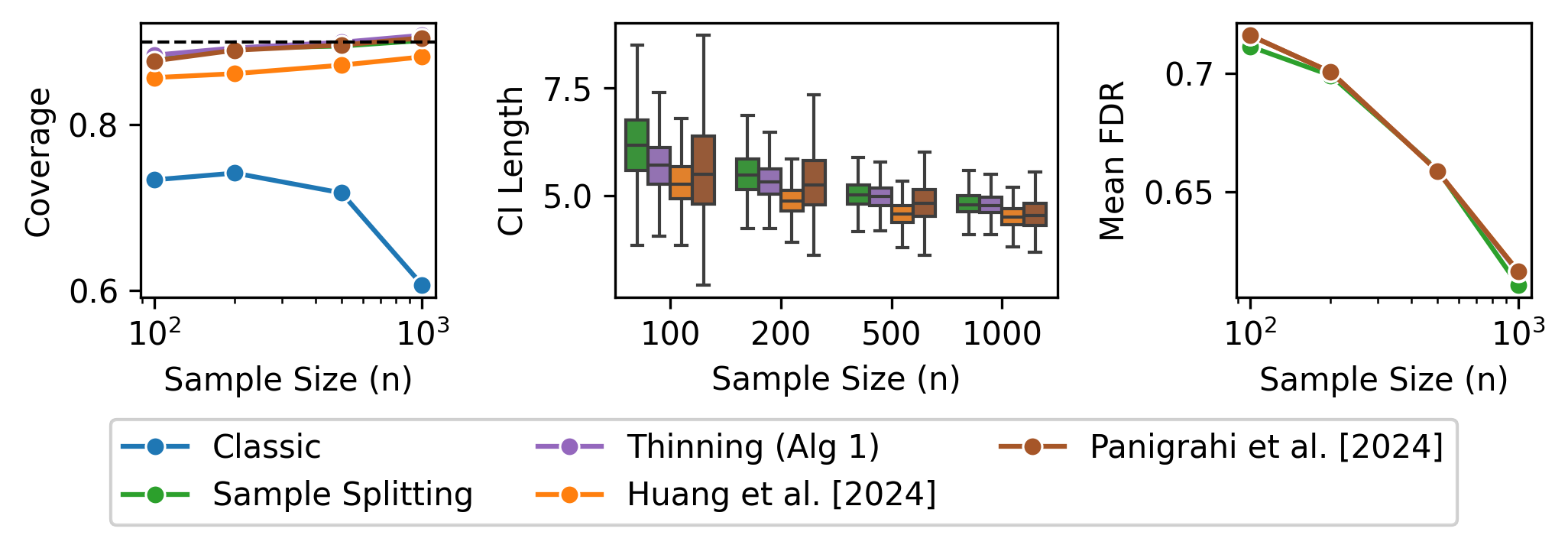
Classical (non-selective) inference after Lasso selection yields significant undercoverage.
Existing approaches requiring conditional likelihoods (e.g., [panigrahi_exact_2024]) control the error, but require bespoke implementations and often perform suboptimally when distributional or inferential targets deviate from their assumptions.
Score thinning attains valid conditional coverage, with intervals typically shorter than sample splitting and quantitatively comparable FDRs.
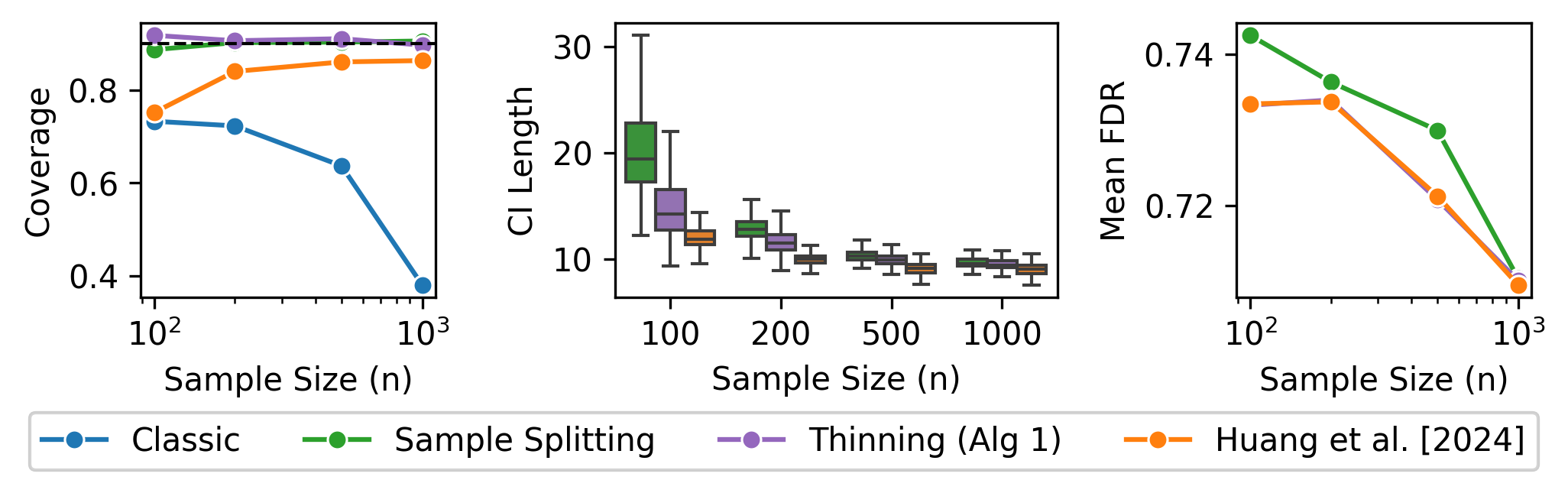
In logistic regression, where existing thinning approaches are inapplicable due to lack of Gaussianity or continuous errors, score thinning continues to achieve targeted coverage.
Figure 1: Score thinning yields proper coverage and narrower intervals than sample splitting in linear models with unknown variance.
Real Data Application
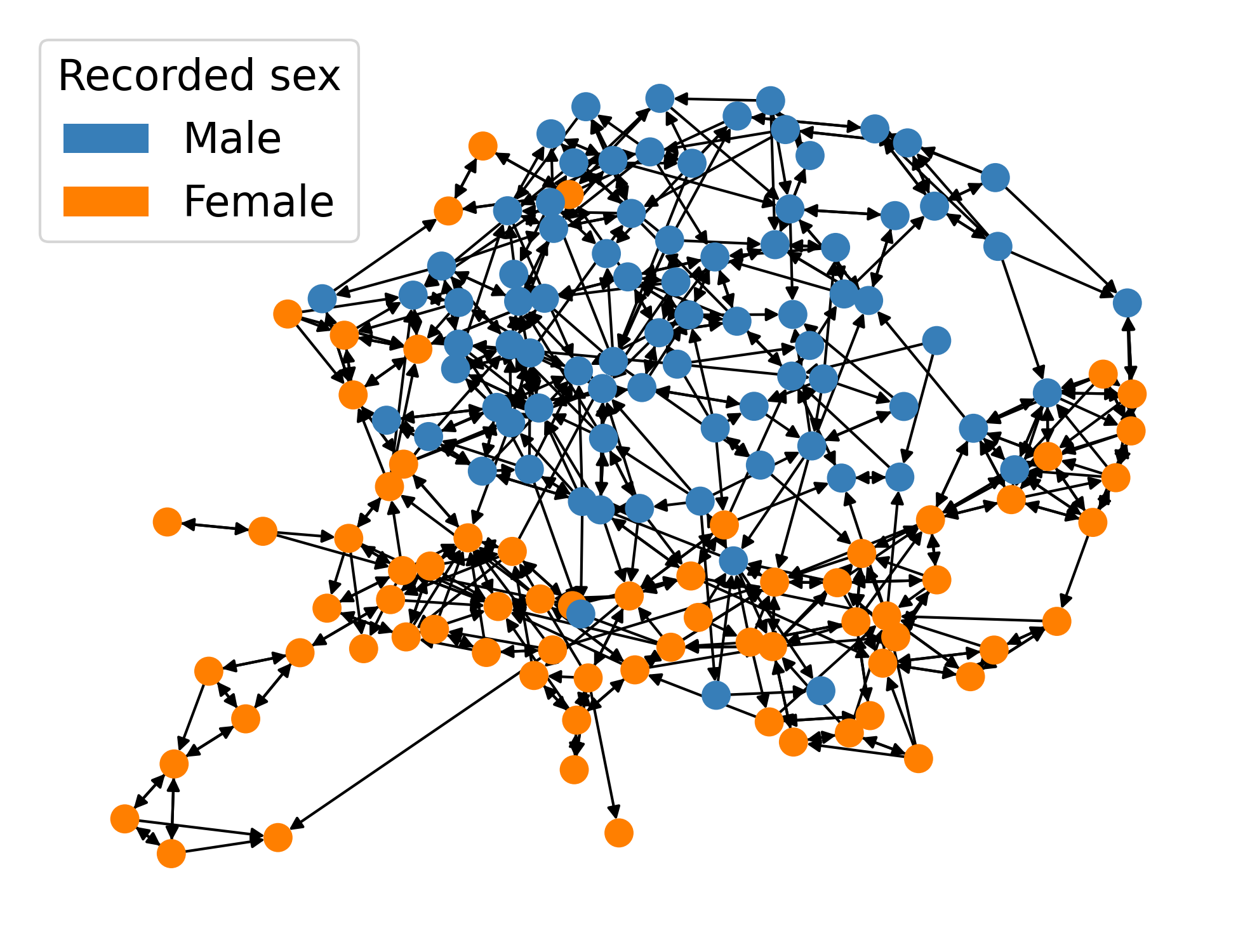
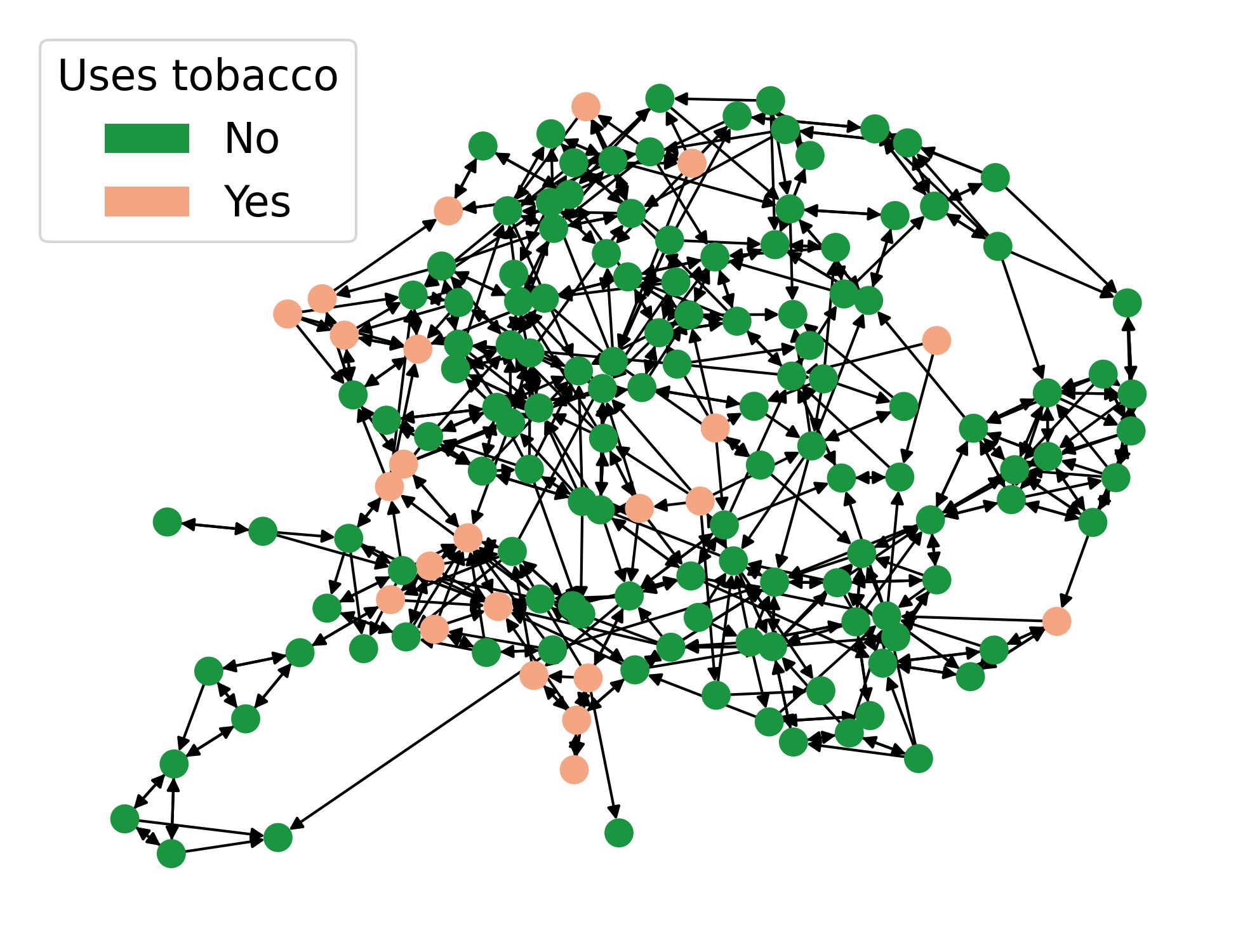
The methodology is demonstrated on network-based regression for social science (e.g., the Teenage Friends and Lifestyle Study). It enables adaptive model selection among a large pool of network-informed covariates (e.g., principal components of social adjacency matrices) and provides valid uncertainty quantification for the effect of interest (e.g., sex on smoking behavior), correctly absorbing the additional uncertainty from the data-driven selection of network features.
Figure 2: Simulation results in logistic regression demonstrate that only score thinning achieves valid post-selection inference among methods not requiring highly restrictive assumptions.
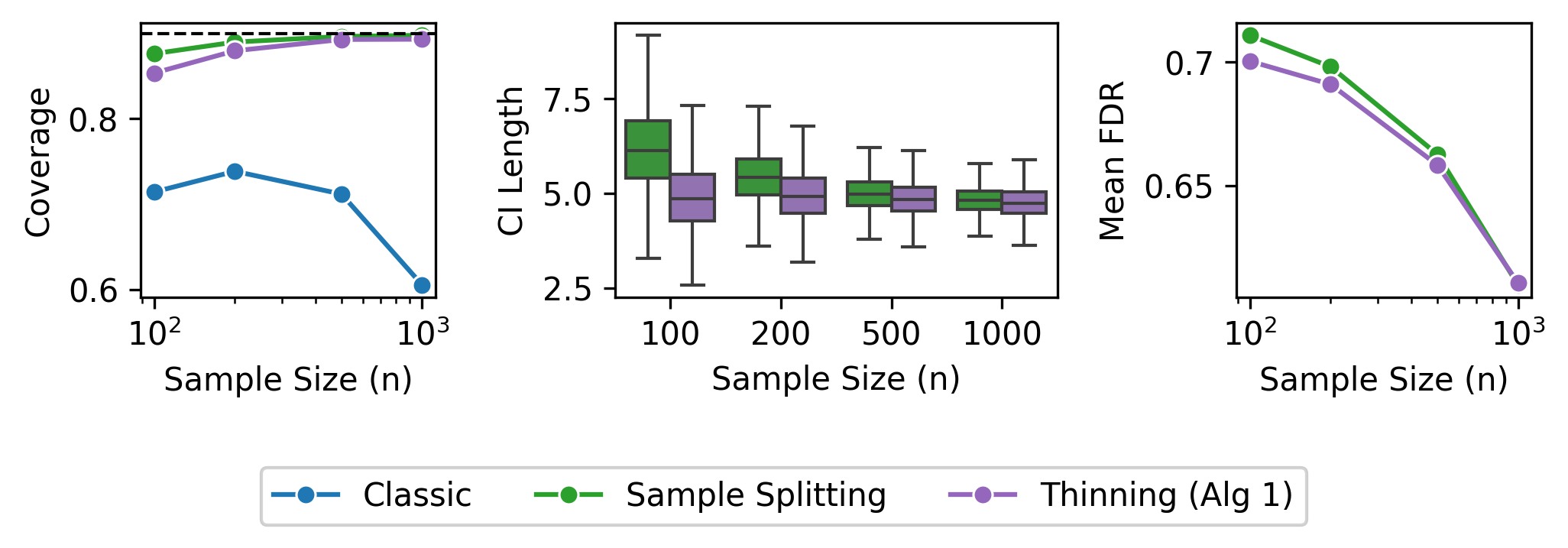
Figure 3: Cluster-dependent designs with equicorrelated non-Gaussian noise show valid inference by score thinning versus severe undercoverage by naive approaches.
Figure 4: Friendship network (left, by sex) and perturbed outcomes (right); thinning ensures inference validity even for adaptively selected principal components in regression context.
Implications and Future Directions
The score thinning paradigm has several substantial implications:
Theoretical: It unifies randomization/stability and sample-splitting ideas, showing that in many practical models, the selection and inference steps are functions of the same normal limit, thus naturally breakable into nearly-independent subquantities suitable for valid post-selection inference.
Practical: Analysts can apply standard penalized modeling frameworks in R, Python, etc., without custom post-selection corrections—simply by introducing proper randomization, followed by off-the-shelf inferential scripts.
Extension: The approach is robust to model misspecification (penalty function, non-Gaussianity, heteroscedasticity), requiring only weak distributional assumptions, and is amenable to generalization (e.g., group lasso, other GLMs, model-based clustering).
Open problems: Extending theoretical guarantees to the p≫n regime and alternative penalties (e.g., group sparse regularizers), as well as optimizing power and minimizing interval width via optimal information splitting, remain important directions.
Conclusion
Score thinning constitutes a fundamental advance in post-selection inference for penalized M-estimators, combining rigorous conditional validity with practical applicability and generality. By leveraging the structure of the score statistic, it removes the need for custom-tailored inferential technology, supporting rapid, reliable, and valid inference workflows for a wide array of high-dimensional model selection paradigms.