Lassoed Forests: Random Forests with Adaptive Lasso Post-selection
Published 10 Nov 2025 in stat.ML and cs.LG | (2511.06698v2)
Abstract: Random forests are a statistical learning technique that use bootstrap aggregation to average high-variance and low-bias trees. Improvements to random forests, such as applying Lasso regression to the tree predictions, have been proposed in order to reduce model bias. However, these changes can sometimes degrade performance (e.g., an increase in mean squared error). In this paper, we show in theory that the relative performance of these two methods, standard and Lasso-weighted random forests, depends on the signal-to-noise ratio. We further propose a unified framework to combine random forests and Lasso selection by applying adaptive weighting and show mathematically that it can strictly outperform the other two methods. We compare the three methods through simulation, including bias-variance decomposition, error estimates evaluation, and variable importance analysis. We also show the versatility of our method by applications to a variety of real-world datasets.
The paper introduces Lassoed Forests, which adaptively balances random forest averaging and lasso post-selection to minimize prediction error.
It employs a convex mixture parameter that optimally weighs unbiased averaging against sparsity-promoting lasso weights, supported by theoretical SNR and MSE analysis.
Empirical results in biomedical applications, including cancer sensitivity and immunotherapy prediction, demonstrate its superior performance compared to standard methods.
Lassoed Forests: An Adaptive Post-selection Method for Random Forests
Overview
This paper introduces the Lassoed Forest, a novel framework that combines random forests (RF) with adaptive Lasso-based post-selection in ensemble prediction. Unlike classic RF averaging or naive Lasso post-selection, Lassoed Forest adaptively learns a convex mixture between unbiased averaging and the sparsity-promoting, individualized weighting of tree outputs. The approach is theoretically justified via bias-variance decomposition and signal-to-noise ratio (SNR) analysis, and its universality is demonstrated through both simulations and real-world biomedical applications.
Background: Random Forests and Lasso Post-selection
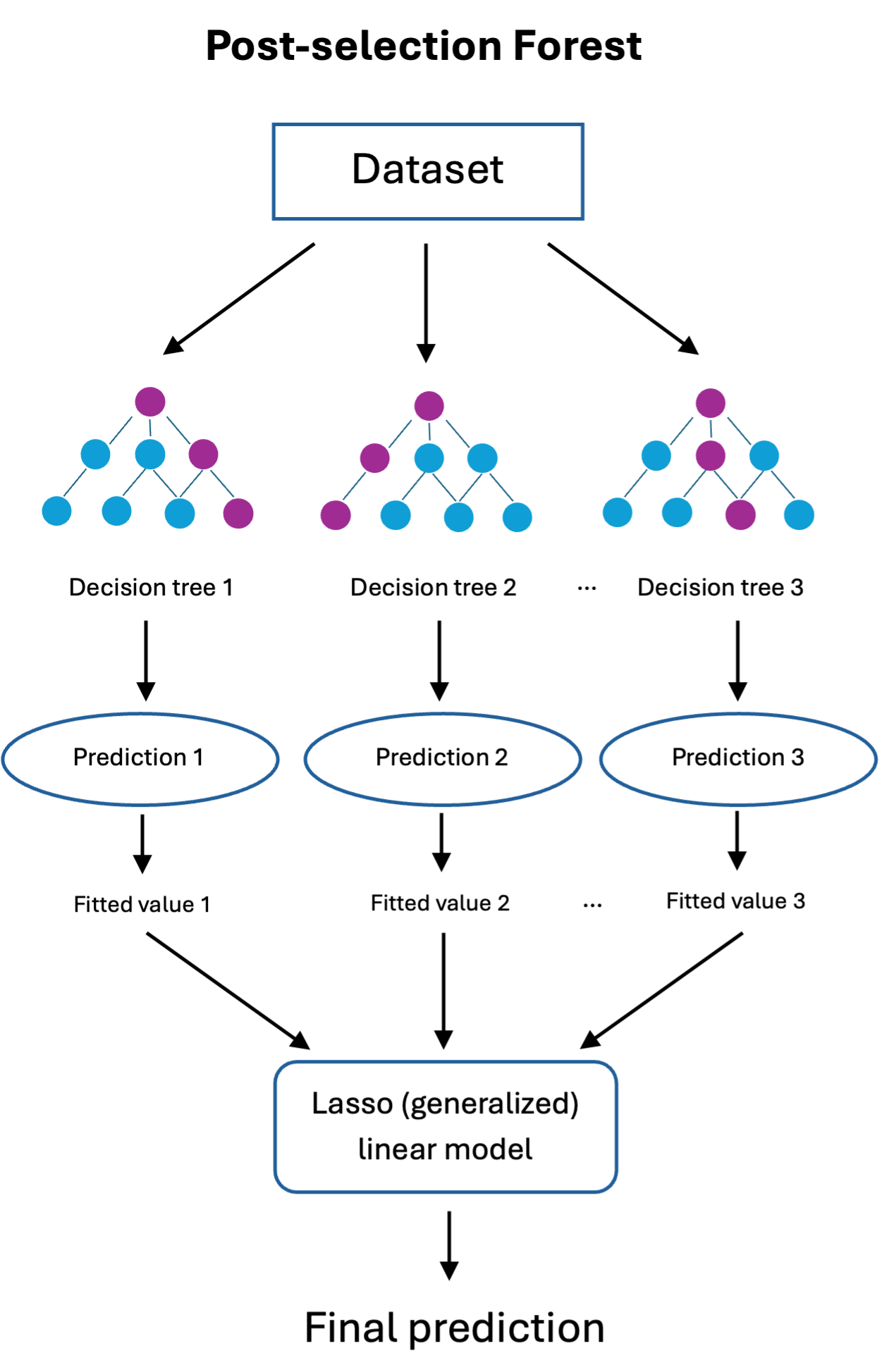
Standard RF mitigates variance by bootstrapping and averaging a large number of high-variance, low-bias trees. However, simple averaging induces redundancy and cannot further decrease bias beyond the function class. Lasso post-selection, as formulated by Wang et al. [wang2021improving], treats each tree's prediction as a feature in an l1-penalized regression, potentially removing poorly predictive trees and assigning sparse weights to the rest:
However, empirical evidence in this paper shows that post-selection may increase prediction error for classification problems or under weak signals, raising the need for data-adaptive weighting.
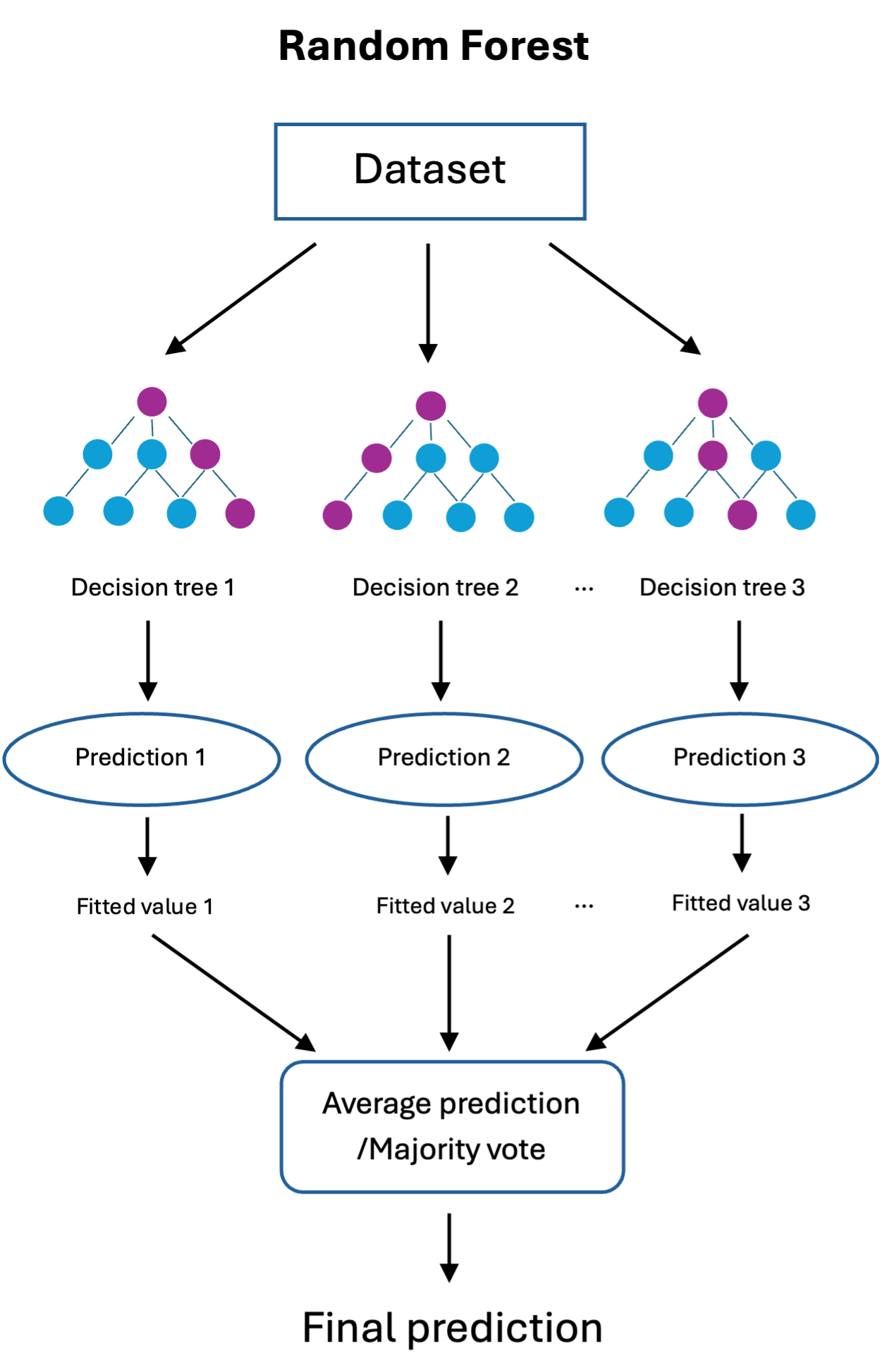
Figure 1: Random Forest is a simple averaging procedure over predictions from all trees in the ensemble.
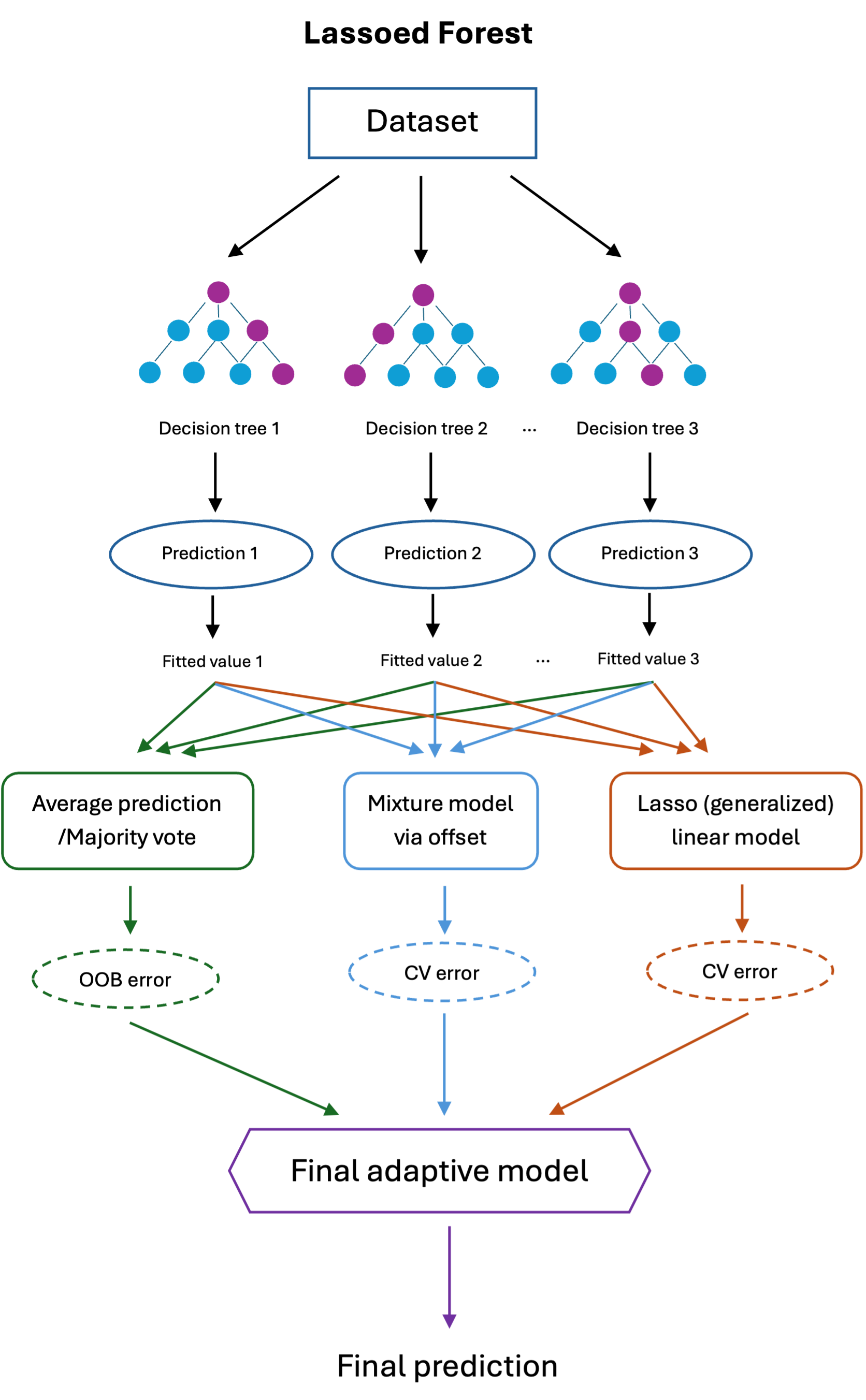
Figure 2: Lassoed Forest adaptively combines averaged and Lasso-weighted predictions, exploiting the strengths of both approaches.
Methodology: Adaptive Convex Mixture
Lassoed Forest generalizes the averaging and post-selection strategies by introducing an adaptive mixture parameter θ in
where Tˉi is the mean out-of-bag prediction. The optimal θ and γ are data-driven, selected to minimize validation error (either cross-validation or out-of-bag).
This framework falls back to pure RF (θ=0) or post-selection (θ=1) as special cases; values in (0,1) yield hybrid predictions, potentially outperforming both benchmarks in terms of mean squared error (MSE) by leveraging the strengths of each.
Theoretical Analysis
Signal-to-noise Ratio Dependency
Under model-agnostic assumptions, the paper proves that the relative efficiency of simple averaging and Lassoed post-selection depends directly on the SNR:
For high SNR: Lassoed post-selection better exploits strong predictors, reducing bias beyond RF averaging.
For low SNR: The variance introduced by Lasso selection outweighs any bias reduction, favoring simple averaging.
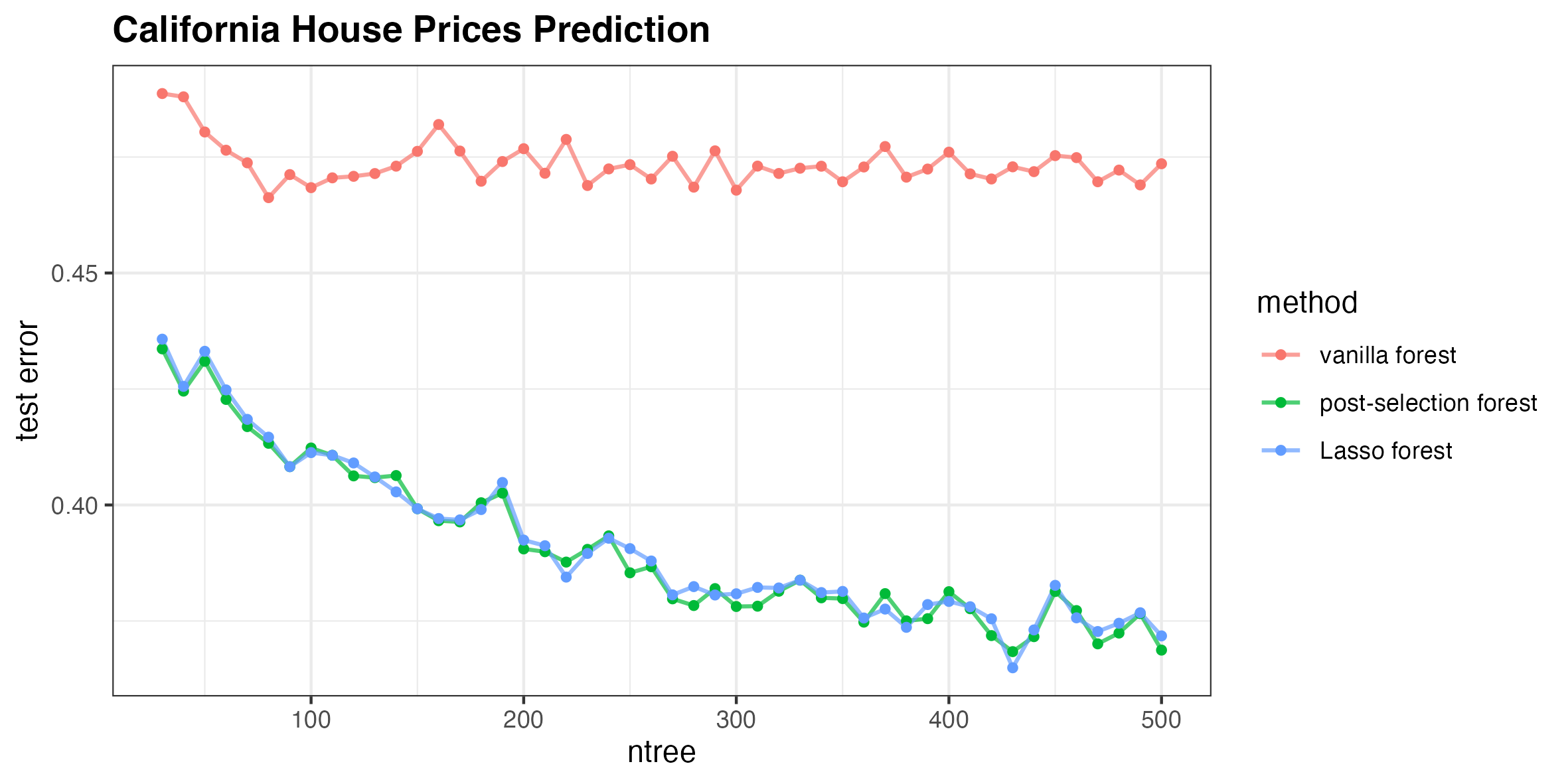
Figure 3: Test error for California house prices prediction shows post-selection outperforming vanilla RF under strong signal conditions.
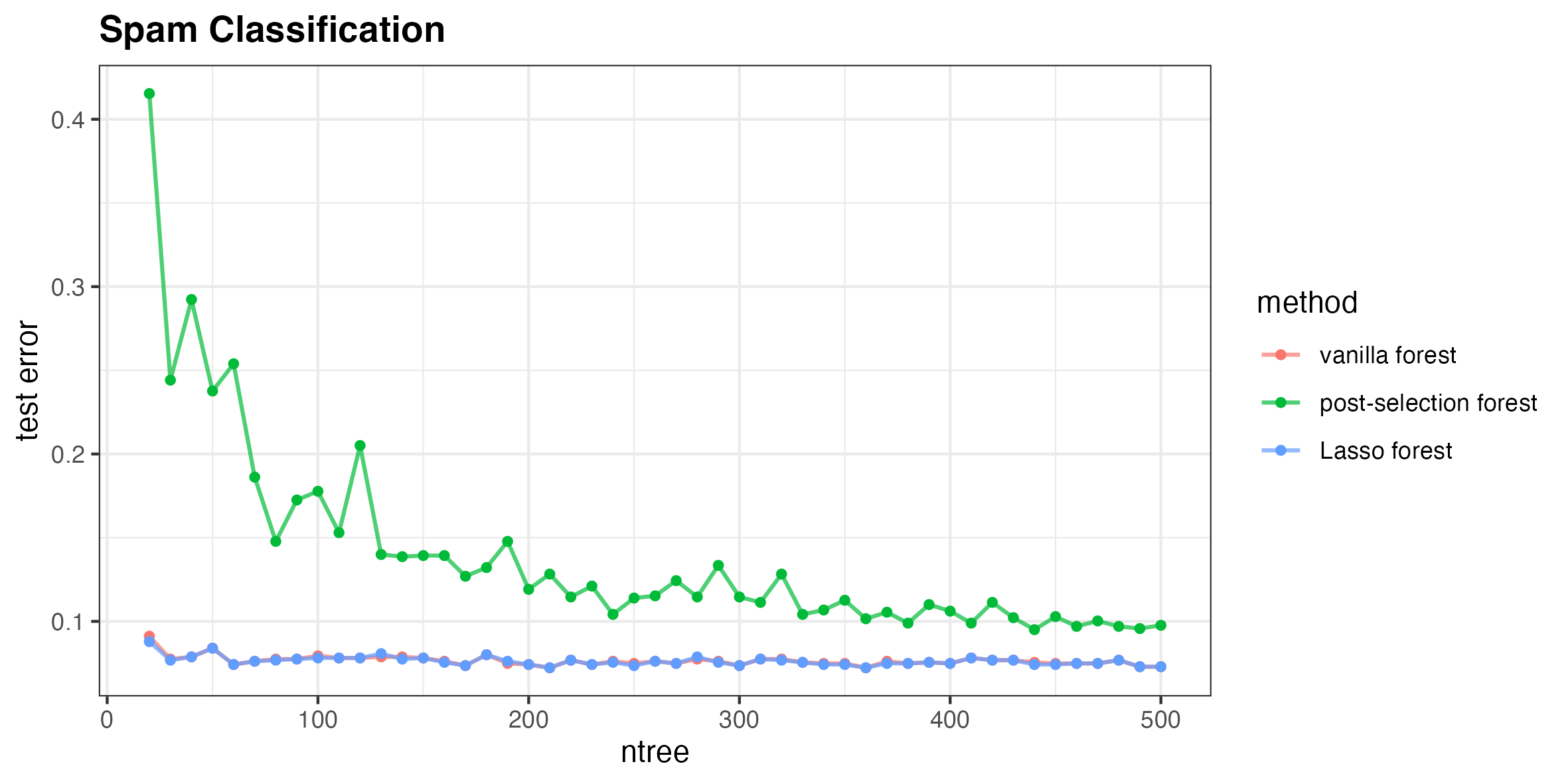
Figure 4: Test error for spam classification where post-selection underperforms vanilla RF, motivating adaptive weighting.
Bias-variance Decomposition
Closed-form expressions in the low-dimensional setting (J+1<N) reveal:
RF averaging retains bias from base learners.
Lassoed regression achieves bias reduction but may suffer from increased variance if J>N or SNR is low.
Adaptive mixture (θ) produces strictly lower MSE than either component method, as the quadratic form resides within the convex hull of their respective errors:
MSEada=(1−θ)2MSERF+θ2MSELasso+ϕ(Σ)
The regularized case (λ>0) is handled via intuition and simulation, showing that Lassoed Forest remains admissible under practical settings.
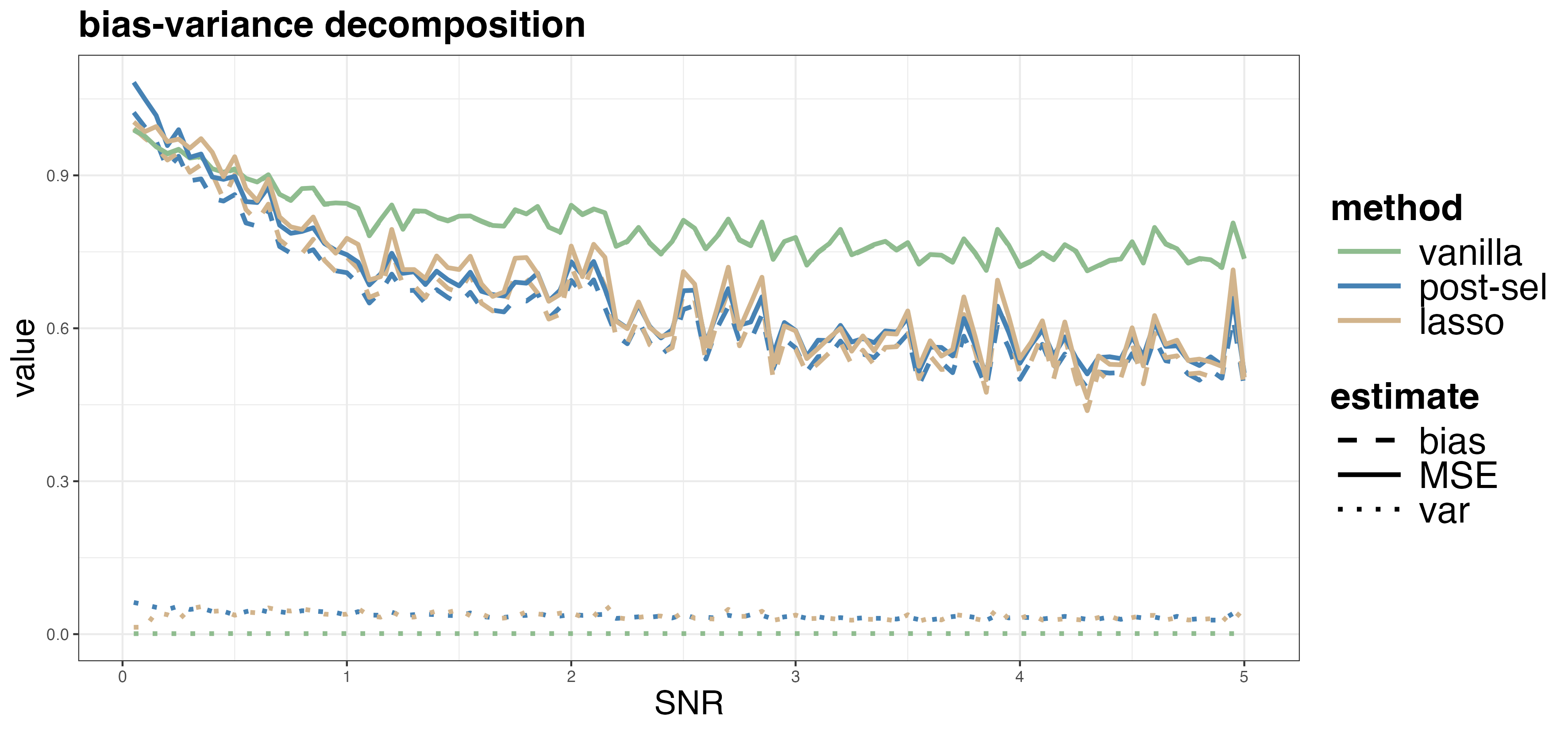
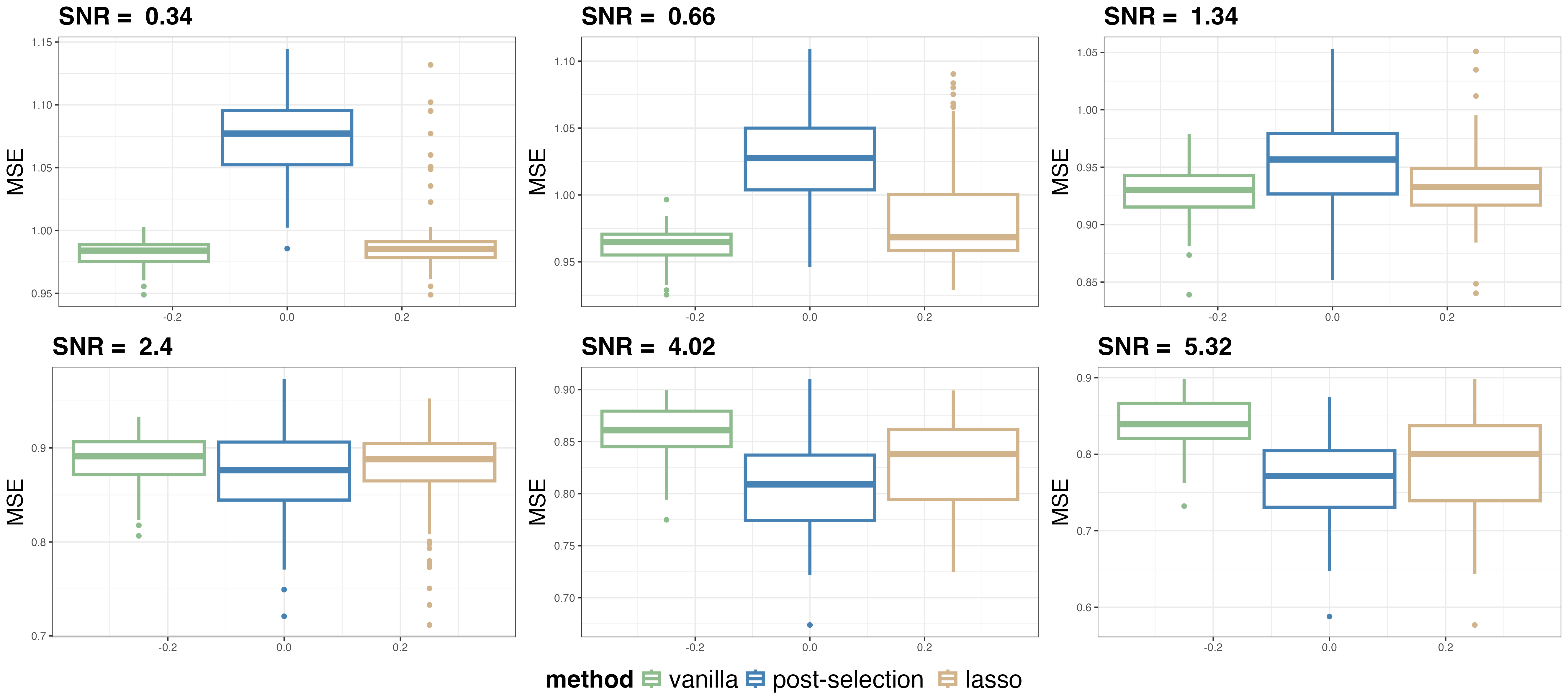
Figure 5: Bias-variance decomposition for polynomial-function-generated data, showing complex interactions as SNR varies.
Simulation Studies
Experiments on polynomial and tree-ensemble synthetic datasets demonstrate the universality of SNR dependency. Key results include:
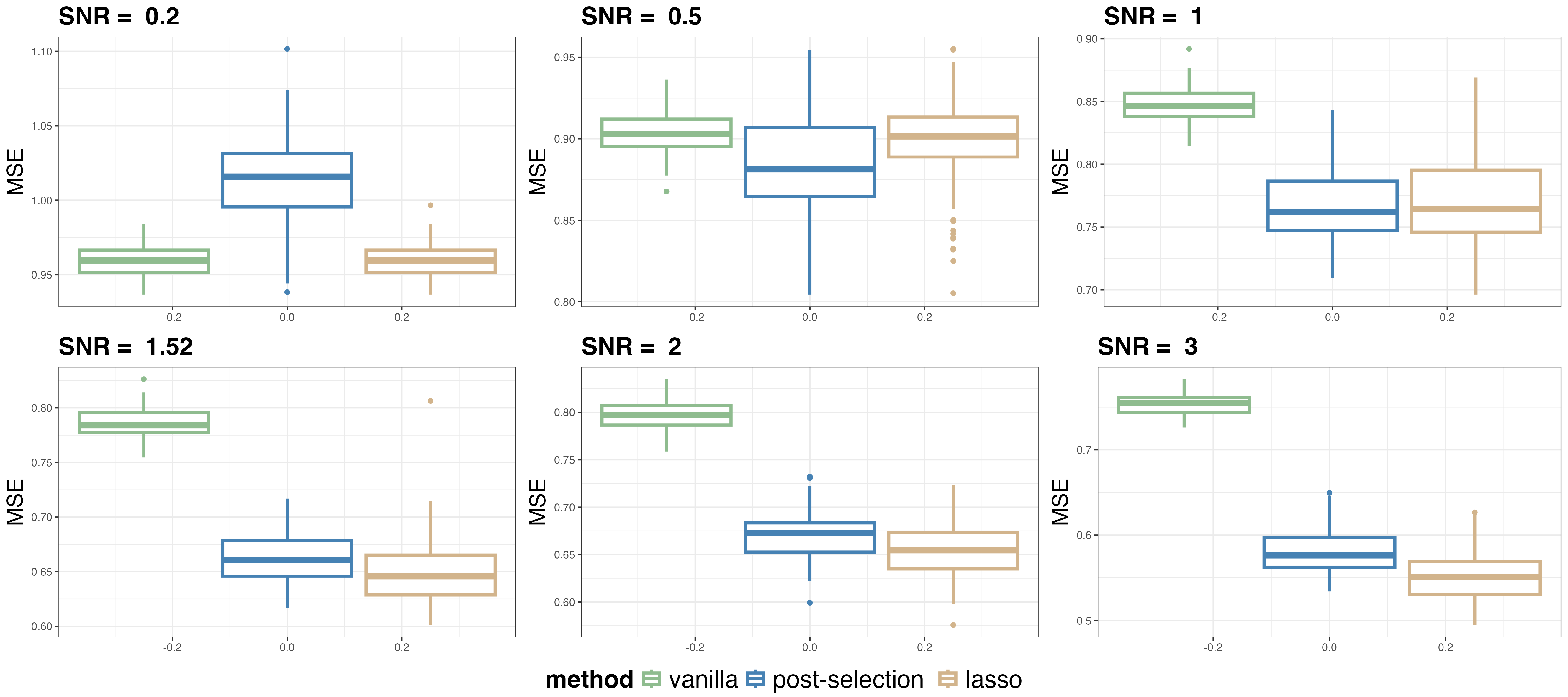
Lassoed Forest matches or exceeds the best of vanilla RF and post-selection across all SNRs.
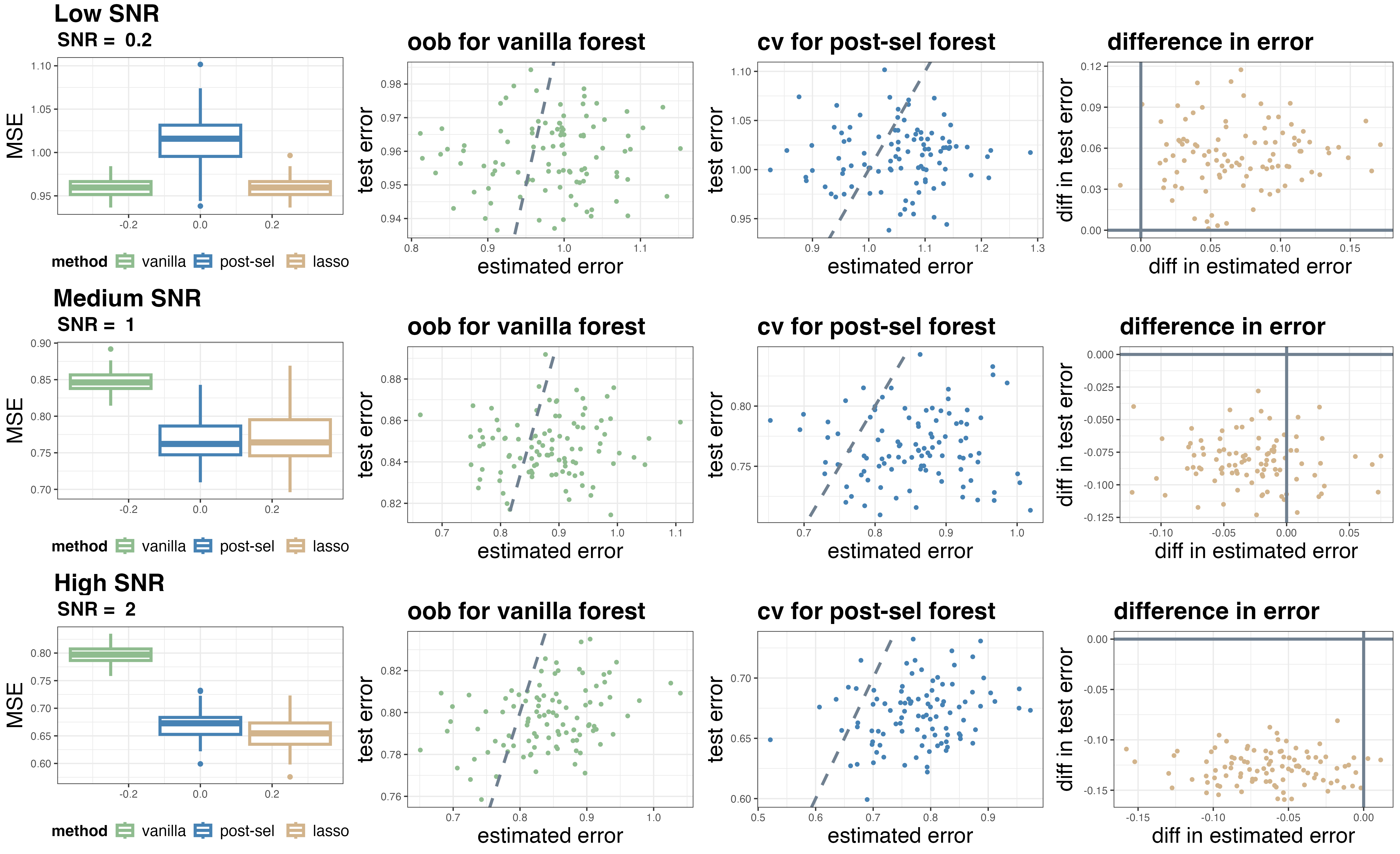
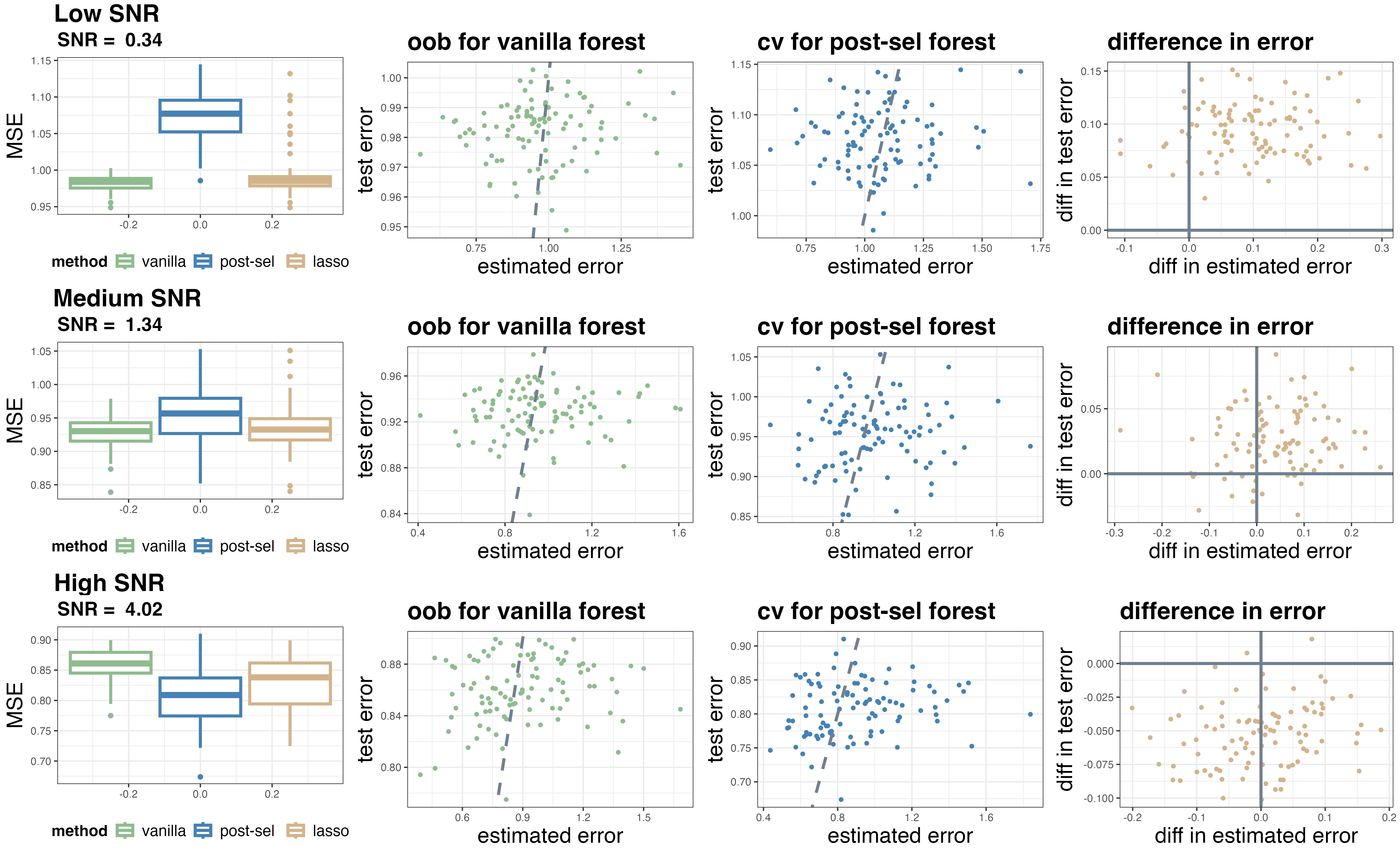
Error estimates (out-of-bag/cross-validation) can be noisy, occasionally impeding optimal weight selection.
Bias decreases with SNR for vanilla RF; variance reduction via post-selection becomes significant with stronger signals.
Figure 6: Mean squared error for polynomial-generating functions highlights SNR-dependent gains from post-selection and Lassoed Forest.
Figure 7: Out-of-bag and cross-validation error estimates track truth well when SNR is extreme, but may err in mid-range.
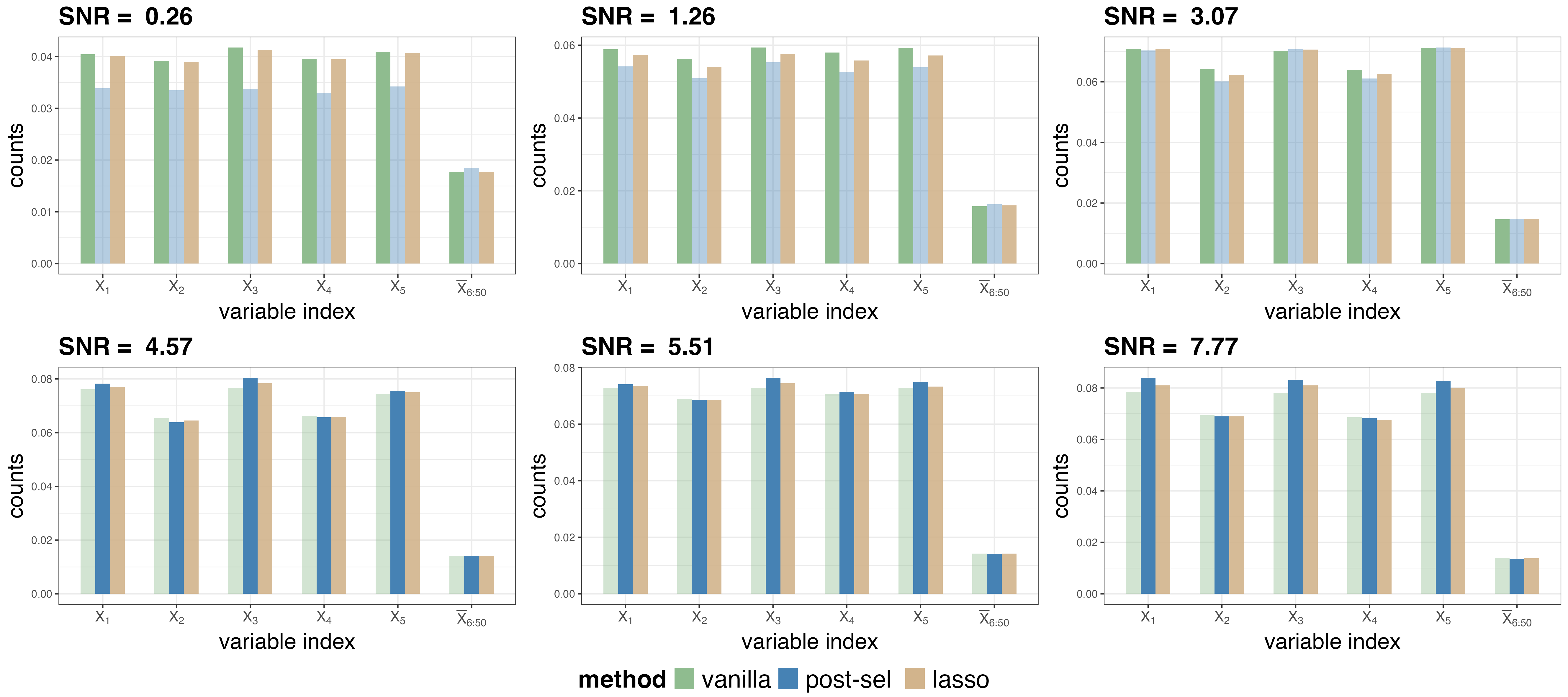
Variable importance analysis shows adaptive selection of predictors in sparse regimes, justifying practical utility for feature selection:
Figure 8: Split counts for variable importance under different SNR, illustrating Lassoed Forest's stability.
Tree-ensemble generating processes reaffirm these findings, with Lassoed Forest robustly straddling benchmarks even as the gap shrinks under near-equal performances.
Figure 9: Mean squared error for tree-ensemble generated data, showing narrow margins between vanilla and post-selection, which Lassoed Forest successfully exploits.
Figure 10: Validation error estimates in tree-ensemble synthetic data remain reasonably aligned with true differences.
Empirical Applications
Cancer Cell Line Sensitivity Regression
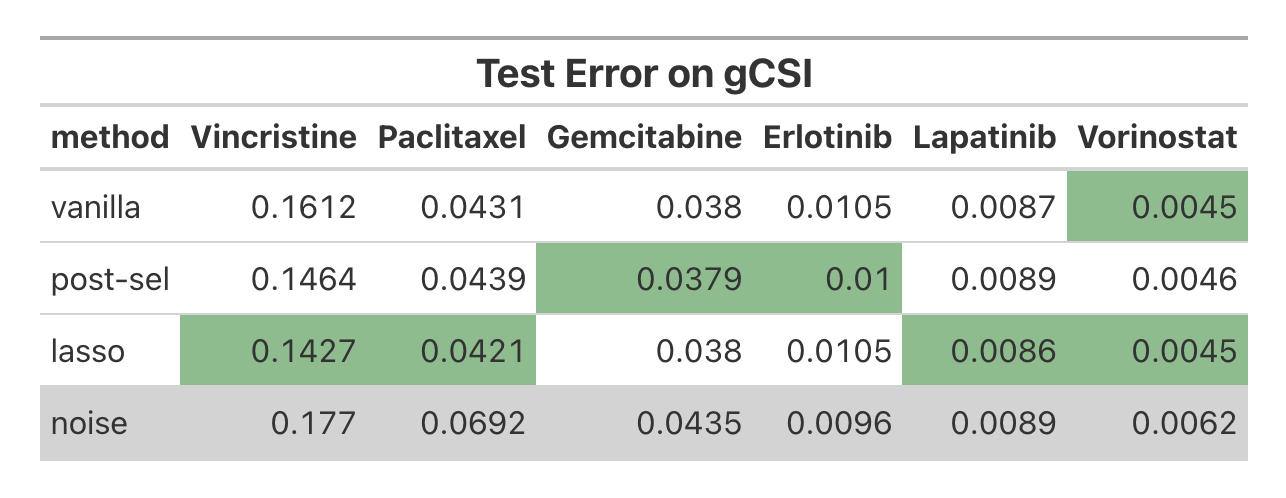
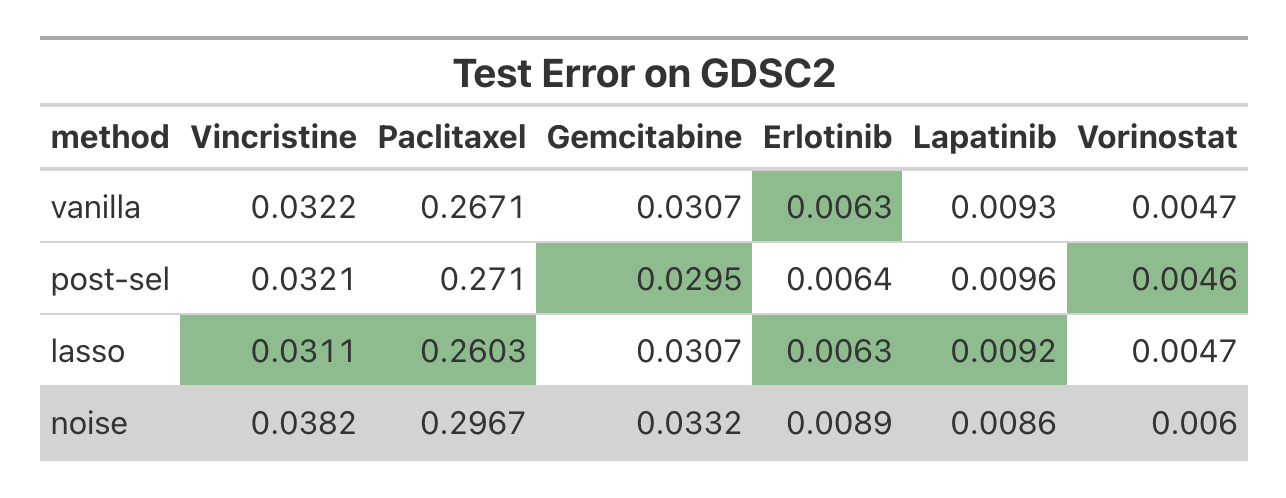
On large-scale pharmacogenomic cell line data (CTRPv2), Lassoed Forest consistently yielded the lowest test error compared to vanilla and Lasso post-selection across numerous drugs. Cross-domain validation on gCSI and GDSC2 further cemented Lassoed Forest as attaining the upper performance bound, highlighting its reliability.
Figure 11: Test error on gCSI, trained on CTRPv2, demonstrates robust generalization of Lassoed Forest.
Figure 12: Test error on GDSC2, trained on CTRPv2, showing state-of-the-art transferability.
Immunotherapy Outcome Prediction
In both survival regression (c-index) and binary classification (error rate) of patient responses to immune checkpoint inhibitors, Lassoed Forest outperformed vanilla RF, post-selection, and generalized linear models, underlining its applicability to multiple problem types.
HIV Drug Resistance
On discrete genotype-phenotype data, post-selection markedly improved over vanilla RF in most drugs, but Lassoed Forest further reduced prediction error, especially where post-selection substantially outperformed vanilla RF.
Implementation and Practical Considerations
Cross-fitting: To avoid overfitting in post-selection, data is split in half, with the first half used for tree training and the second for Lasso fitting.
Selection of θ: Error minimization over a grid (e.g., θ∈{0,0.25,0.5,0.75,1}) based on held-out error is recommended.
Resource Requirements: Comparable to standard RF plus the computational overhead of fitting a single penalized regression over tree outputs.
Scalability: The framework scales with the number of trees and data points, but the splitting and validation stages require sufficient sample size for robust error estimation.
Limitations: Accuracy of error estimates affects optimal weight selection. When vanilla and post-selection performances are close and validation error is noisy, Lassoed Forest may not always select the exact optimum. Theoretical guarantees assume universal approximation and equibiased base learners, which may not strictly hold in real world.
Deployment: Can be readily implemented atop existing RF frameworks (e.g., ranger in R or scikit-learn in Python) with additional post-processing steps for Lasso fitting and adaptive mixture.
Implications and Future Research
The Lassoed Forest approach provides a theoretically justified, practically effective solution to adaptively balancing bias-variance in tree ensembles. It is a direct improvement over classic ensemble averaging and naive post-selection, able to guard against poor performance in either regime and to optimize predictive power for the data at hand.
Potential future research directions include:
Relaxing the expressivity and equibias assumptions in theory, investigating adaptation to non-tree-based learners.
Analytical characterization of bias-variance under high-dimensional Lasso regularization.
Development of more robust error estimators for weight selection, reducing reliance on noisy validation metrics.
Exploration of adaptive mixtures for other ensemble methods (e.g., boosting, stacking).
Conclusion
Lassoed Forests generalize and unify random forest and post-selection approaches, providing an adaptive, data-driven ensemble that achieves strictly lower or equal prediction error. Through thorough theoretical and empirical analysis, this method demonstrates stable and superior performance across regression, classification, and survival tasks, with immediate applicability for high-dimensional, complex datasets in bioinformatics and other domains.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.