- The paper develops a robust semiparametric estimation methodology using influence-function-based estimators to identify and estimate the average treatment effect in the Napkin graph.
- The paper presents one-step, estimating equation, and TMLE approaches that exploit Verma constraints to overcome challenges posed by latent confounding and M-bias.
- The paper validates the methodology with simulations and Finnish Life Course data, demonstrating efficiency gains and practical applicability in complex causal inference settings.
Causal Inference with the "Napkin Graph": Robust Semiparametric Estimation Under Complex Latent Structures
Introduction
The "Napkin graph"—a canonical DAG structure discussed by Pearl—poses substantial challenges for causal identification in the presence of unmeasured confounding and complex pathologies such as M-bias. Standard identification strategies (back-door, front-door, primal fixability) do not suffice under this structure, while the observed data distribution admits no ordinary conditional independences. Instead, identification rests on exploiting a Verma constraint—a generalized independence imposed by the latent DAG structure.
This paper presents a rigorous semiparametric framework for identification and estimation of the average treatment effect (ATE) in the Napkin graph. It develops nonparametric and semiparametric estimators—most notably one-step, estimating equation (EE), and targeted maximum likelihood estimators (TMLE)—supported by formal asymptotic efficiency results, robustness analyses under machine learning-based nuisance estimation, and empirical validation with both synthetic simulations and real-world data.
Graphical and Model-theoretic Foundations
The Napkin graph integrates classical motifs—M-bias, instrumental variables, and both back-door and front-door components—but requires a uniquely tailored identification argument. It is characterized by the following features:
- Latent confounding simultaneously affecting treatment, outcome, and intermediate pre-treatment variables.
- Collider structure (M-bias): Conditioning on W or its descendants (e.g., Z) induces dependence between treatment and outcome, violating back-door conditions.
- Non-applicability of front-door and primal fixability criteria: No observed mediators exist to mediate between X and Y in an unconfounded manner, and treatment/outcome are not in separate districts.
This setting is diagrammatically represented by Figure 1a, and admits no identifying independences in P(O). However, upon intervention on Z, a latent structure yields a Verma constraint (conditional independence in a post-interventional distribution), which forms the basis of identification.
(Figure 1)
Figure 1: (a) The Napkin DAG structure. (b) Generalization with measured confounders. (c) Post-intervention graph under do(Z=z∗).
The paper formalizes identification by expressing the counterfactual mean E(Yx0) as a ratio of two g-formulas, which are functionals of the observed data distribution:
ψx0(P;z∗)=∫p(x0∣z∗,w)p(w)dw∫yp(y∣x0,z∗,w)p(x0∣z∗,w)p(w)dw
This functional is invariant in z∗ due to the Verma constraint, with the trapdoor variable Z serving as a generalized instrument. For continuous Z, a weighted integral version is provided, supporting influence-function-based inference.
Semiparametric Estimation: Influence-Function-Based Methods
Nuisance Parameters
Estimation relies on:
- μ(x,z,w): outcome regression E(Y∣X=x,Z=z,W=w),
- π(x∣z,w): treatment mechanism,
- fZ(z∣w): conditional density of Z,
- pW(w): empirical marginal of W.
Cross-fitting and nonparametric regression (e.g., Super Learner ensembles, kernel methods) are proposed for nuisance parameterization.
Estimator Classes
Plug-in
Direct substitution of estimated nuisances into the identifying functional, but requires all nuisances at oP(n−1/2) rates for asymptotic linearity.
One-step and Estimating Equation (EE)
Corrects plug-in bias by adding the empirical mean of the efficient influence function (EIF), or by solving Pn[EIF]=0. These estimators achieve double robustness and only require oP(n−1/4) for the propensity and oP(1) for either the outcome regression or fZ for consistency.
Targeted Minimum Loss-Based Estimation (TMLE)
Constructs a sequence of targeted updates to outcome and treatment nuisances, minimizing empirical first-order bias while delivering plug-in calculability. Iterated targeting (within/across nuisances) ensures that the EIF is centered up to oP(n−1/2).
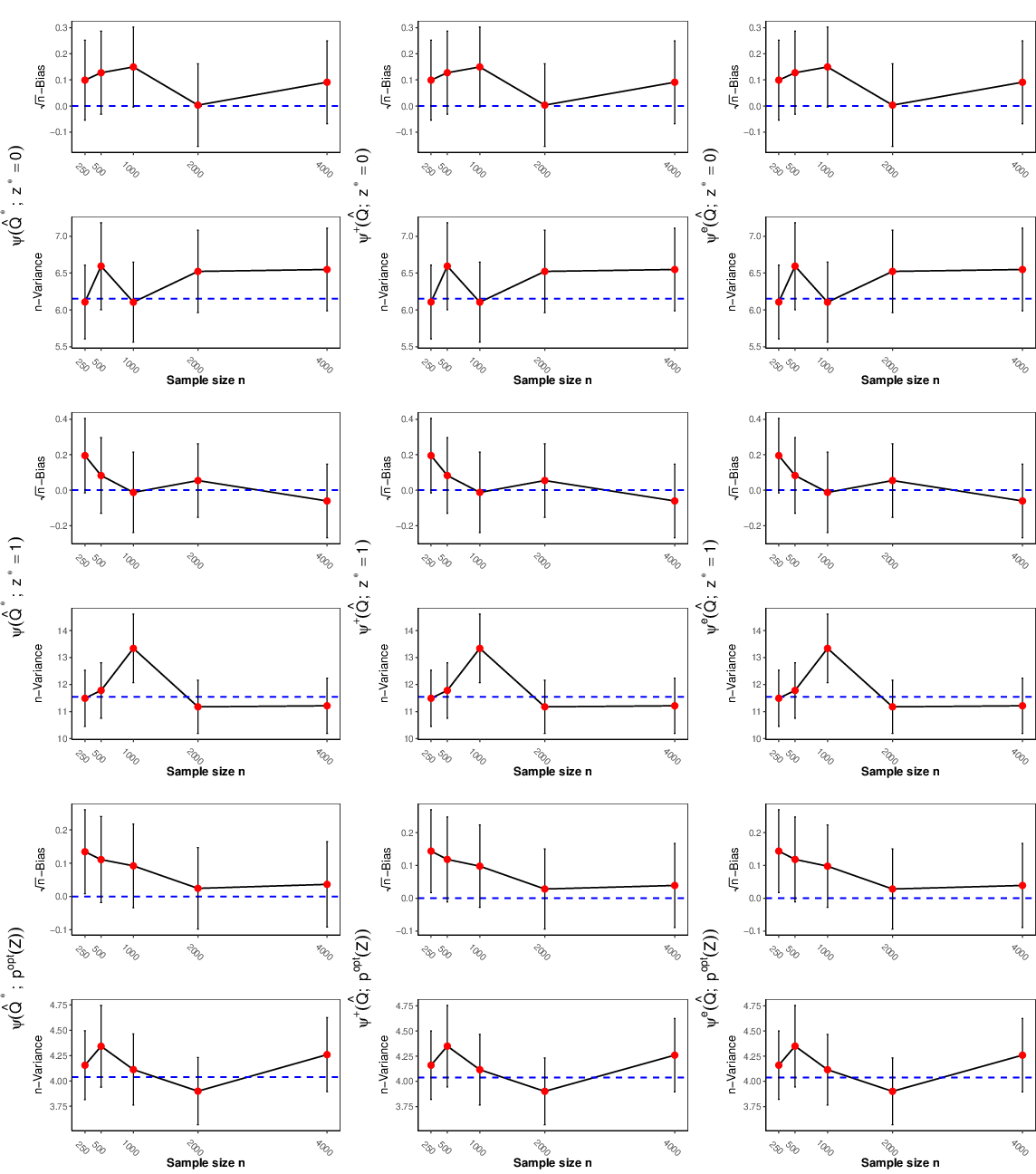
Figure 2: Simulation results showing the asymptotic linearity of TMLE, one-step, and EE estimators under binary Z for the Napkin model, with respect to sample size.
Theoretical Guarantees and Robustness
The paper provides a formal expansion for the estimator error: ψ^x0−ψx0=PnΦx0(Q)+R2(Q^,Q)
with R2 a second-order remainder. Analyses reveal doubly robust behavior, i.e., consistency and root-n-asymptotic normality is retained if either (μ,π) or fZ are estimated consistently with only mild rate requirements.
Strong results are demonstrated:
- Continuous Z: Requires ∣∣π^−π∣∣=oP(n−1/4), ∣∣μ^−μ∣∣=oP(1) or ∣∣f^Z−fZ∣∣=oP(1)
- Discrete Z: Only product rate condition ∣∣f^Z−fZ∣∣⋅∣∣μ^−μ∣∣=oP(n−1/2) is needed; double robustness is explicit.
Efficiency Improvements via Verma Constraints
A key contribution is exploiting the Verma constraint for improved estimator efficiency. The identification functional is invariant in z∗, but the variance of its EIF can be minimized by an optimal convex combination over z∗ selections (discrete Z), or by optimizing the weighting distribution for continuous Z. Substantial variance reductions are documented in simulation (up to ∼3x for binary Z), substantiating the practical benefit of respecting latent structure-imposed constraints.
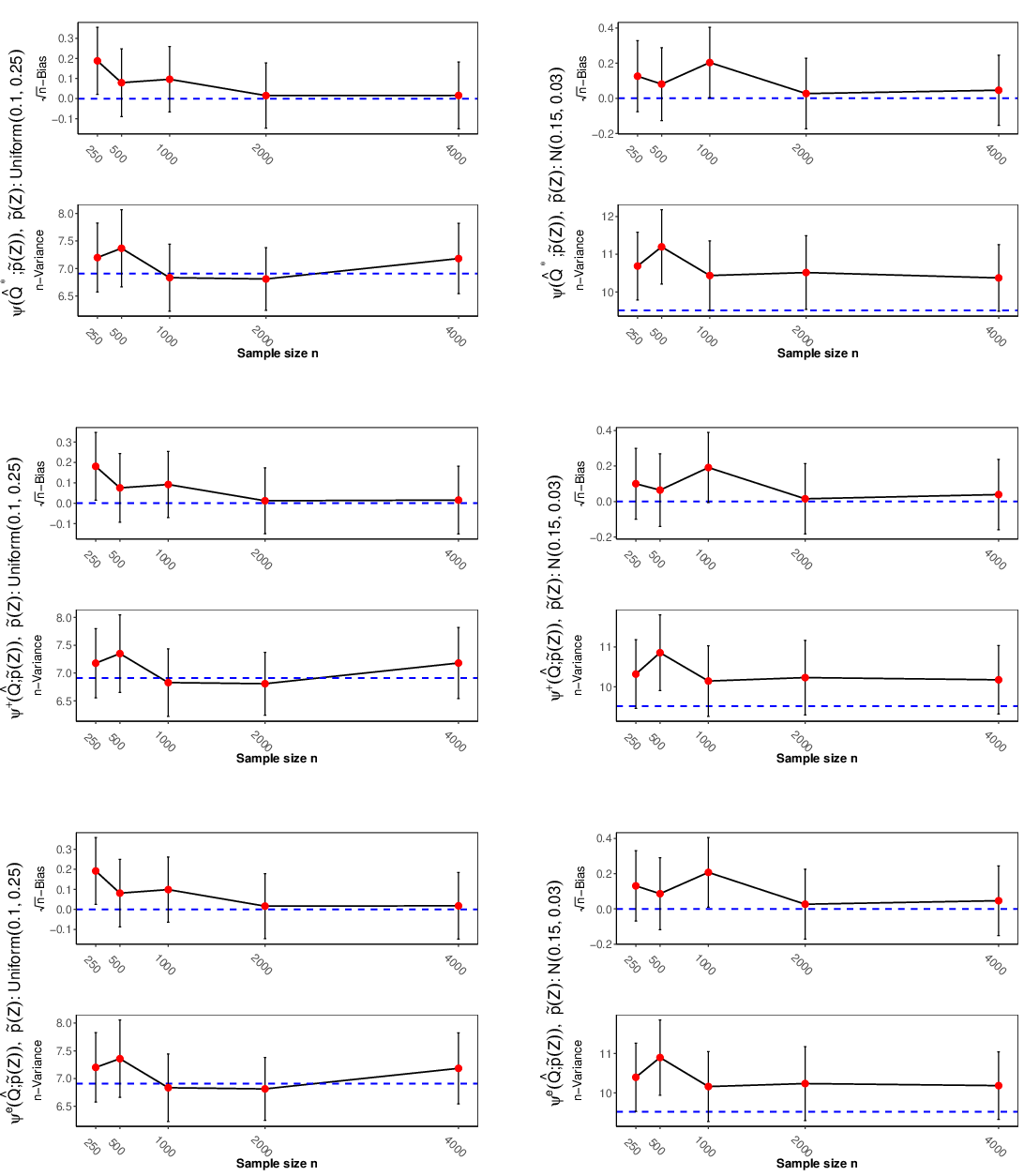
Figure 3: Simulation results for continuous Z—demonstrating that judicious choice of weighting density in the identifying functional yields substantial efficiency gains for TMLE, one-step, and estimating equation estimators.
Empirical Validation
Simulations across regimes—varied sample size, overlap conditions, and degree of nuisance model misspecification—clearly illustrate the theoretical robustness of the IF-based estimators. TMLE displays particularly favorable performance under weak overlap. Cross-fitting is shown to mitigate bias with complex nuisance regression (e.g., random forests). Flexible learners (Super Learner, random forests) outperform simple parametric models when functional forms are misspecified.
Application: Finnish Life Course Data
Applying the framework to the Finnish Life Course 1971–2002 cohort, the authors estimate the causal effect of educational attainment on income, adjusting for comprehensive confounding (covariate set: SES, GPA, ITPA, sex) in the Napkin setting. Point estimates and valid CIs are obtained by TMLE, one-step, and EE estimators; all methods consistently indicate positive causal effects, corroborating previous findings while operating in a more hostile identification regime.
Implications and Future Directions
Methodologically, the work generalizes semiparametric efficiency and robust causal estimation to a latent DAG regime where identification arises from Verma constraints, not d-separation. Practically, it enables valid causal effect estimation under M-bias/IV/“trapdoor” pathologies, applicable to numerous biomedical, social, and policy settings.
Theoretically, a crucial open problem is the characterization and construction of semiparametric efficient influence functions for models with Verma constraints—connecting graphical model latent structure with empirical process theory. Future research will broaden these tools to general classes of nonstandard hidden-variable graphs and develop general testing procedures for model checking and goodness-of-fit under such constraints.
Conclusion
This paper delivers a rigorous, operational framework for causal effect estimation under the Napkin graph, combining nonparametric identification, influence-function-based robust estimation, and variance-efficient exploitation of Verma constraints. The provided R package "napkincausal" renders these advanced methods immediately accessible. The approach sets a methodological benchmark for semiparametric estimation in DAGs with hidden variables that transcend traditional adjustment paradigms.